2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Hei ystävät Opitaanko pinon tietorakenne tänään!

Pino: Erityinen lineaarinen luettelo, joka sallii lisäys- ja poistotoiminnot vain kiinteässä päässä. Tietojen lisäys- ja poistotoimintoihin siirtyvää päätä kutsutaan pinon yläosaksi ja toista päätä pinon alaosaksi.Pinon tietoelementit noudattavatLIFO (Last In First Out) -periaate. Voimme kuvitella sen kuin lampaanlihakebabin syömistä,Laita se ensinLampaanpalat painetaan sisäänpohja,viimeinenLampaanpalat ovat sisälläPäällä/.

Pinon työntäminen: Pinon lisäystoimintoa kutsutaan push/push/push.Lisää tiedot pinon yläosasta。
Pop: Pinon poistotoimintoa kutsutaan poppingiksi.Lähtevät tiedot ovat myös pinon päällä。
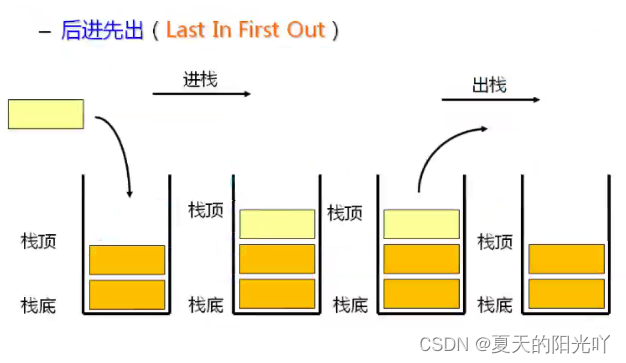
Pino voidaan yleensä toteuttaa käyttämällä taulukkoa pinon toteuttamiseen tai käyttämällä linkitettyä listaa, kumpi on suhteellisesti parempitaulukon rakennePinon toteuttaminen on yksinkertaisempaa ja tehokkaampaa.
Koska toteutettaessa edellisen sekvenssitaulukon lisäys-, poisto-, muokkaus- ja kyselyliittymää (tietorakenteen järjestystaulukko) Meillä on erittäin kätevää käyttää taulukon rakennetta lopusta lisäämiseen ja poistamiseen, joten pinon toteutuksessa määritämme taulukon pään pinon yläpääksi ja pään alareunaksi. pino.
Pino, kuten sekvenssiluettelo, voidaan suunnitella kiinteäpituiseksi staattiseksi pinoksi tai dynaamisesti kasvavaksi pinoksi.Koska kiinteäpituisella pinolla on suuria rajoituksia ja se ei ole käytännössä käytännöllinen, toteutamme pääasiassa tukeaDynaamisesti kasvava pino。
Kuten edellisessä sekvenssiluettelon/linkitettyjen luetteloiden käyttöliittymän toteutuksessa, luomme ensin otsikkotiedoston "Stack.h" ja kaksi lähdetiedostoa "Stack.c" ja "Test.c".
| Pino.h | Pinon määritelmä, otsikkotiedoston viittaus ja käyttöliittymäfunktion ilmoitus |
| Stack.c | Käyttöliittymätoimintojen toteutus |
| Test.c | Testaa jokaista toimintoa |
Näytä ensin "Stack.h":n täydellinen koodi, älä unohda lainata "Stack.h" kahdessa lähdetiedostossa
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
Niiden joukossa "yläosan" merkitys määräytyy alkuarvon perusteella, joka selitetään yksityiskohtaisesti alla. Seuraavaksi aloitamme käyttöliittymän toteuttamisen.
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
Ymmärtämisen helpottamiseksi ymmärrämme noin rakenteen yläosan taulukon alaindeksinä.Jos alustamme alkuun 0 pinoa alustaessa, pinossa ei ole dataa, ja top osoittaa pinon ylimmän datan seuraavaan kohtaan.

Jos alustamme top arvoon -1, top osoittaa pinon ylimmän datan sijaintiin. Meidän on parempi alustaa se arvoon 0, koska se on kätevää lisätä elementtejä ja poistaa elementtejä.
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
Koska pinon ja sekvenssitaulukon välillä on ero, emme voi suoraan kulkea läpi ja tulostaa. Siksi, jos haluamme tulostaa pinon elementit, meidän on käytettävä StackEmpty- ja StackPop-funktiota, joista keskustellaan myöhemmin. .
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
Tästä syystä edellisen väitteen StackEmpty on lisättävälooginen negatiivinen operaattoriSyynä on se, että jos pino on tyhjä, StackEmpty palauttaa true, ja false-negataatio voi todistaa, että pinossa on elementtejä.
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
Kun kaikki liitännät ovat valmiit, testataan koodi Test.c:ssä:
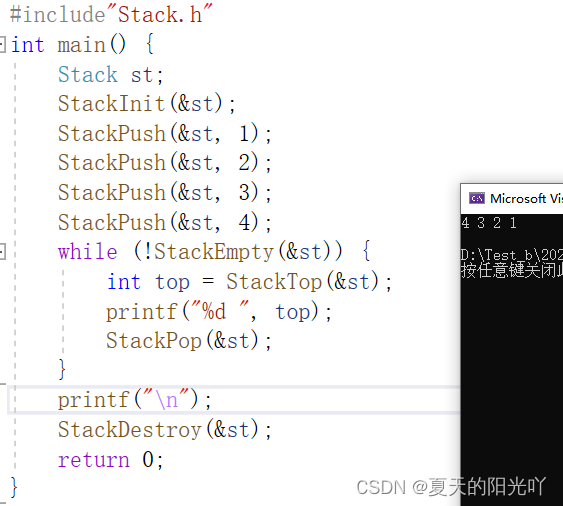
Testataanpa vielä:
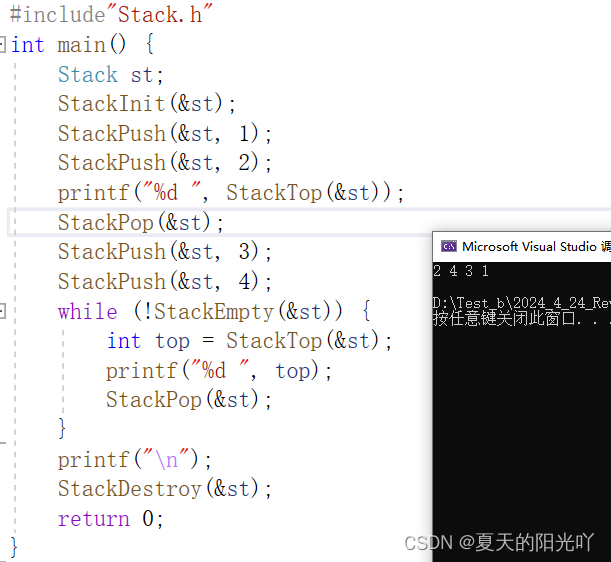
Ei ongelmia. Onnittelut pinon käyttöliittymän toteuttamisesta. Seuraava on "Stack.c"-tiedoston täydellinen koodi:
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. Mikä seuraavista pinoa koskevista väitteistä on oikein ( )
V. Pino on "first in first out" -tietorakenne
B. Pino voidaan toteuttaa käyttämällä linkitettyä listaa tai sekvenssilistaa
C. Pino voi lisätä tietoja vain pinon alaosaan
D. Pino ei voi poistaa tietoja
oikea vastaus: B
Virhe A: Pino on viimeinen sisään ensimmäinen ulos -tietorakenne, ja jono on ensimmäinen sisään, ensimmäinen ulos.
B on oikein: Sekä sekvenssiluetteloita että linkitettyjä listoja voidaan käyttää pinojen toteuttamiseen, mutta sekvenssiluetteloita käytetään yleensä, koska pinoa pidetään sekvenssiluettelon kastroituna versiona. Vain sekvenssitaulukon tail-lisäys- ja hännänpoistotoiminnot ovat Käytetään, ja sekvenssitaulukon hännän lisäys ja hännän poistaminen eivät vaadi liikkuvia elementtejä ja ovat erittäin tehokkaita, joten ne toteutetaan yleensä peräkkäisten taulukoiden avulla.
C-virhe: Pino voi suorittaa syötteen lisäys- ja poistotoiminnot vain pinon päällä
D-virhe: Pinossa on push- ja pop-toimintoja, joilla poistetaan elementti pinosta.
2. Pinon push-sekvenssi on ABCDE ja mahdoton pop-sekvenssi on ( )
A.ABCDE
B.EDCBA
C.DCEBA
D.ECDBA
oikea vastaus: D
Jos E tulee ulos ensin, se tarkoittaa, että ABCDE on kaikki työnnetty pinoon Kun E on ponnahtanut pinosta, pinon ylin elementti on D. Jos se ponnahtaa ulos, sen pitäisi olla D, ei C. .
Siksi D tulisi valita
3. Peräkkäiseen pinoon verrattuna ketjupinon ilmeiset edut ovat ( )
A. Asennustoiminto on kätevämpää
B. Poistaminen on kätevämpää
C. Laajentamista ei tarvita pinoon työnnettäessä
oikea vastaus: C
Virhe A. Jos se on linkitetty pino, se vaatii yleensä pään lisäys- tai poistotoiminnot, kun taas peräkkäinen pino suorittaa yleensä tail-lisäys- ja tail-poistotoiminnot. Linkitetyn listan toiminta on monimutkaisempaa kuin peräkkäisen taulukon yksinkertaisempaa käyttää peräkkäistä rakennetta pinon toteuttamiseen.
B on väärässä, katso A:sta syy.
C on oikein Kun pino on toteutettu ketjurakenteessa, jokainen painaminen pinoon vastaa solmun lisäämistä linkitetyn listan päähän.
4. Mikä seuraavista väittämistä pinojen käyttämisestä jonojen toteuttamiseen on virheellinen ( )
A. Pinosimulaatiolla jonon toteuttamiseen voidaan käyttää kahta pinoa, joista yksi simuloi jonoon siirtymistä ja yksi pino simuloi jonosta poistumista.
B. Joka kerta kun poistat jonosta, sinun on tuotava kaikki yhden pinon elementit toiseen pinoon ja poistettava se sitten.
C. Kun astut jonoon, tallenna elementit suoraan pinoon, joka simuloi jonoon siirtymistä.
D. Jonotoiminnon aikamonimutkaisuus on O(1)
oikea vastaus: B
Vaihtoehdossa B yksi pino simuloi jonon purkamista Elementit on tuotava joka kerta, joten se on virhe
Vaihtoehdossa A pinojen ja jonojen ominaisuudet ovat päinvastaiset. Pino ei voi toteuttaa jonoa.
Vaihtoehdossa C yksi pino simuloi jonoon siirtymistä ja yksi pino jonosta poistumista.
Vaihtoehdossa D jonottaminen tarkoittaa elementtien asettamista pinoon, joten aikamonimutkaisuus on O(1)
Tänään opimme pinon tietorakenteesta, eikö se ole paljon yksinkertaisempaa kuin linkitetty luettelo, toivottavasti tästä artikkelista on apua ystävilleni!
kerjätäTykkää, suosikki ja seuraa!!!
Kiitos kaikille! ! !


Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten

