
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
안녕 친구들! 오늘은 스택의 데이터 구조를 함께 배워볼까요?

스택: 고정된 끝에서만 삽입 및 삭제 작업을 허용하는 특수 선형 목록입니다. 데이터 삽입 및 삭제 작업이 들어가는 쪽 끝을 스택의 맨 위, 다른 쪽 끝을 스택의 맨 아래라고 합니다.스택의 데이터 요소는 다음을 준수합니다.LIFO (후입선출) 원칙. 양고기 케밥을 먹는 것과 같다고 상상할 수 있습니다.먼저 올려보세요양고기 조각이 눌려져 있어요맨 아래,마지막 하나양고기 조각이 들어있어요상단에의.

스택 푸시: 스택 삽입 작업을 푸시/푸시/푸시라고 합니다.스택의 맨 위에서 데이터 삽입。
팝(Pop): 스택의 삭제 작업을 팝핑(popping)이라고 합니다.나가는 데이터도 스택의 맨 위에 있습니다.。
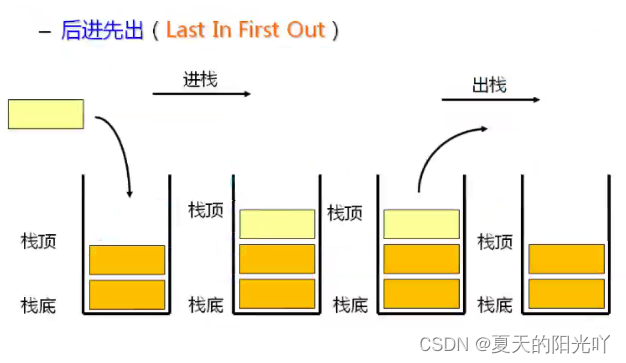
스택은 일반적으로 배열을 사용하여 스택을 구현하거나 연결된 목록을 사용하여 스택을 구현하는 방식으로 구현할 수 있습니다.배열 구조스택을 구현하는 것이 더 간단하고 효율적입니다.
이전 시퀀스 테이블의 추가, 삭제, 수정 및 쿼리 인터페이스를 구현하기 때문에(데이터 구조 시퀀스 테이블) 배열의 구조를 사용하여 끝에서부터 삽입하고 삭제하는 것이 매우 편리하므로 스택 구현에서는 배열의 끝을 스택의 상단으로, 헤드를 스택의 하단으로 정의합니다. 스택.
시퀀스 목록과 마찬가지로 스택은 고정 길이 정적 스택 또는 동적으로 증가하는 스택으로 설계될 수 있습니다.고정 길이 스택은 한계가 크고 실제로 실용적이지 않기 때문에 주로 지원을 구현합니다.동적으로 성장하는 스택。
이전 시퀀스 목록/연결 목록 인터페이스 구현과 마찬가지로 먼저 헤더 파일 "Stack.h"와 두 개의 소스 파일 "Stack.c" 및 "Test.c"를 만듭니다.
| 스택.h | 스택 정의, 헤더 파일 참조 및 인터페이스 함수 선언 |
| 스택.c | 인터페이스 기능 구현 |
| 테스트.c | 각 기능 테스트 |
먼저 "Stack.h"의 전체 코드를 보여드리겠습니다. 2개의 소스 파일에서 "Stack.h"를 인용하는 것을 잊지 마세요.
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
그 중 "top"의 의미는 초기값에 의해 결정되는데, 이에 대해서는 아래에서 자세히 설명한다. 다음으로 인터페이스 구현을 시작합니다.
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
이해를 돕기 위해 구조의 상단을 대략 배열의 첨자로 이해합니다.스택을 초기화할 때 top을 0으로 초기화하면 스택에 데이터가 없고, top은 스택의 최상위 데이터의 다음 위치를 가리킨다.

top을 -1로 초기화하면 top은 스택의 최상위 데이터 위치를 가리킵니다. 여기서는 요소를 추가하고 삭제하는 것이 편리하므로 0으로 초기화하는 것이 좋습니다.
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
스택과 시퀀스 테이블의 차이가 있기 때문에 직접 순회하여 인쇄할 수 없으므로 스택에 있는 요소를 인쇄하려면 StackEmpty 함수와 나중에 설명할 StackPop 함수를 사용해야 합니다. .
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
이것이 이전 어설션의 StackEmpty를 추가해야 하는 이유입니다.논리 부정 연산자그 이유는 스택이 비어 있으면 StackEmpty가 true를 반환하고, false를 부정하면 스택에 요소가 있음을 증명할 수 있기 때문입니다.
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
모든 인터페이스가 완료된 후 Test.c에서 코드를 테스트해 보겠습니다.
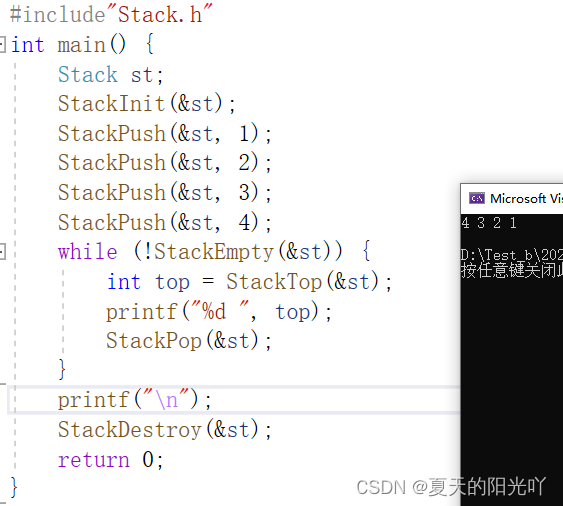
좀 더 테스트해 보겠습니다.
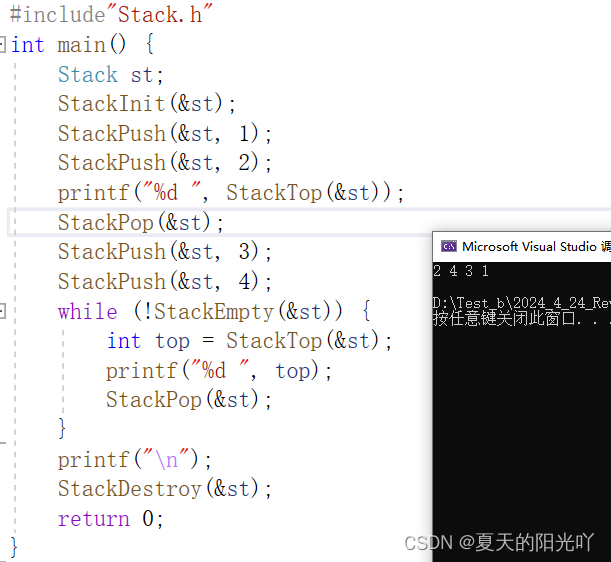
전혀 문제 없습니다. 스택 인터페이스 구현을 완료한 것을 축하합니다. 다음은 "Stack.c" 파일의 전체 코드입니다.
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. 스택에 대한 다음 설명 중 올바른 것은 무엇입니까 ( )
A. 스택은 "선입 선출" 데이터 구조입니다.
B. 스택은 연결된 목록이나 순차 목록을 사용하여 구현할 수 있습니다.
C. 스택은 스택의 맨 아래에만 데이터를 삽입할 수 있습니다.
D. 스택은 데이터를 삭제할 수 없습니다.
정답: 비
오류: 스택은 후입선출(Last In First Out) 데이터 구조이고 큐는 선입선출(FIFO) 방식입니다.
B가 맞습니다. 시퀀스 목록과 연결 목록 모두 스택을 구현하는 데 사용할 수 있지만 스택은 시퀀스 목록의 거세된 버전으로 간주되므로 시퀀스 목록이 일반적으로 사용됩니다. 시퀀스 테이블의 꼬리 삽입 및 꼬리 삭제 작업만 가능합니다. Tail 삭제 및 Tail 삭제는 요소 이동이 필요하지 않고 매우 효율적이므로 일반적으로 순차 테이블을 사용하여 구현됩니다.
C 오류: 스택은 스택 상단에서만 입력 삽입 및 삭제 작업을 수행할 수 있습니다.
D 오류: 스택에 푸시 및 팝 작업이 있습니다. 팝은 스택에서 요소를 삭제하는 것입니다.
2. 스택의 푸시 시퀀스는 ABCDE이고, 불가능한 팝 시퀀스는 ( )입니다.
A.ABCDE
B.EDCBA
다. DCEBA
디.ECDBA
정답: 디
E가 먼저 나오면 ABCDE가 모두 스택에 푸시되었다는 의미입니다. E가 스택에서 팝된 후 스택의 최상위 요소는 D입니다. 다시 팝되면 C가 아닌 D여야 합니다. .
그러므로 D를 선택해야 한다.
3. 순차 스택과 비교하여 체인 스택의 확실한 장점은 다음과 같습니다.
A. 삽입 작업이 더 편리합니다.
B. 삭제 작업이 더 편리해졌습니다.
C. 스택에 밀어넣을 때 확장이 필요하지 않습니다.
정답: 씨
오류 A. 체인 스택의 경우 일반적으로 헤드 삽입 또는 헤드 삭제 작업이 필요한 반면, 순차 스택은 일반적으로 테일 삽입 및 테일 삭제 작업을 수행합니다. 연결 리스트의 작업은 순차 테이블보다 복잡하므로 스택을 구현하기 위해 순차 구조를 사용하는 것이 더 간단합니다.
B가 틀렸습니다. 그 이유는 A를 참조하세요.
C가 맞습니다. 스택이 체인 구조로 구현되면 스택에 푸시할 때마다 연결 목록의 헤드에 노드를 삽입하는 것과 같습니다.
4. 스택을 사용하여 대기열을 구현하는 방법에 대한 다음 설명 중 잘못된 것은 무엇입니까? ( )
A. 스택 시뮬레이션을 사용하여 큐를 구현하면 두 개의 스택을 사용할 수 있습니다. 하나의 스택은 큐에 들어가는 것을 시뮬레이션하고, 하나의 스택은 큐에서 나가는 것을 시뮬레이션합니다.
B. 대기열에서 제거할 때마다 한 스택의 모든 요소를 다른 스택으로 가져온 다음 팝아웃해야 합니다.
C. 큐에 들어갈 때 큐에 들어가는 것을 시뮬레이션하는 스택에 요소를 직접 저장하십시오.
D. 큐 작업의 시간 복잡도는 O(1)입니다.
정답: 비
옵션 B에서는 하나의 스택이 대기열 제거를 시뮬레이션하고, 하나의 스택이 대기열 제거 시 시뮬레이션된 대기열 제거 스택의 최상위 요소가 직접 팝업됩니다. 아니요. . 매번 요소를 가져와야하므로 잘못된 것입니다.
옵션 A에서는 스택과 큐의 특성이 반대입니다. 스택은 큐를 구현할 수 없습니다.
옵션 C에서는 하나의 스택이 대기열에 들어가는 것을 시뮬레이션하고, 다른 하나의 스택이 대기열에서 나가는 것을 시뮬레이션합니다. 대기열에 들어갈 때 요소는 대기열에 들어가는 것을 시뮬레이션하는 스택에 직접 저장됩니다.
옵션 D에서 큐잉은 요소를 스택에 넣는 것을 의미하므로 시간 복잡도는 O(1)입니다.
오늘 우리는 스택의 데이터 구조에 대해 배웠습니다. 연결 리스트보다 훨씬 간단하지 않나요? 하하하하하, 이 글이 친구들에게 도움이 되었으면 좋겠습니다!!!
빌다좋아요와 즐겨찾기, 팔로우!!!
다들 감사 해요! ! !


그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com