2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
https://blog.csdn.net/weixin_37519752/article/details/138728036
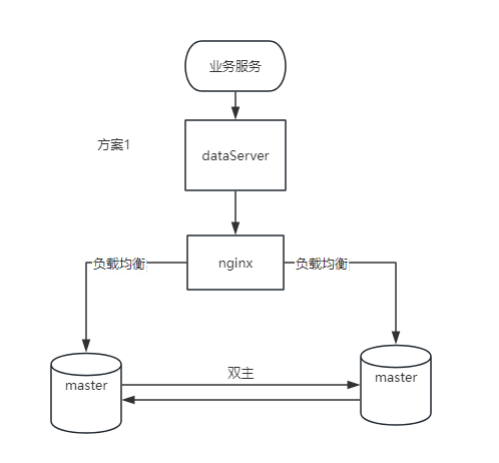
1. Vorteile
Schreibskalierbarkeit: Beide Knoten können Schreibvorgänge verarbeiten, wodurch die Skalierbarkeit von Schreibvorgängen verbessert wird.
Hohe Verfügbarkeit: Wenn ein Knoten ausfällt, kann der andere Knoten weiterhin Dienste bereitstellen, einschließlich Schreibvorgängen.
Failover: Es ist kein komplexer Failover-Mechanismus erforderlich, da beide Knoten aktiv sind.
2. Nachteile
Datenkonsistenz: Um die Datenkonsistenz aufrechtzuerhalten, sind komplexe Mechanismen zur Konflikterkennung und -lösung erforderlich.
Netzwerkanforderungen: Es bestehen hohe Anforderungen an Netzwerkstabilität und Latenz, da die Echtzeitsynchronisation zwischen Knoten empfindlich auf die Netzwerkqualität reagiert.
Zusätzlicher Overhead: Zusätzlicher Netzwerk- und Festplatten-E/A-Overhead durch Echtzeitsynchronisierung.
3. Anwendbare Szenarien
Verteilte Anwendungen: Anwendungen, die Schreibfunktionen an verschiedenen geografischen Standorten erfordern.
Hohe Schreiblast: Szenarien, in denen die Schreiblast verteilt werden muss, um die Leistung zu verbessern.
Anforderungen an Echtzeitdaten: Anwendungen, die eine Echtzeitsynchronisierung von Daten auf mehreren Knoten erfordern.
Ein Master und ein Slave oder ein Master und mehrere Slaves, die von mysql5.7 oder höher unterstützt werden
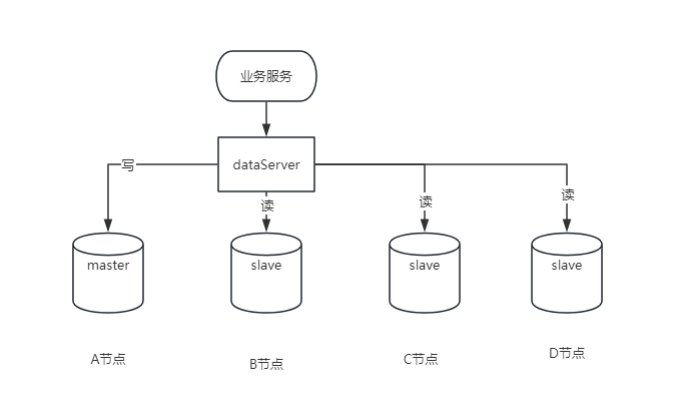
1. Vorteile
Datenredundanz: Bietet Hot-Backup von Daten und reduziert so das Risiko von Datenverlusten.
Leistungsverbesserung: Ein Master und mehrere Slaves, verschiedene Benutzer lesen aus verschiedenen Datenbanken und die Leistung wird verbessert.
Skalierbarkeit: Wenn der Datenverkehr zunimmt, können Slave-Server einfach hinzugefügt werden, ohne die Systemnutzung zu beeinträchtigen.
Lastausgleich: Ein Master und mehrere Slaves entsprechen der Aufteilung der Host-Aufgaben und der Durchführung des Lastausgleichs.
2. Nachteile
Datenlatenz: Da die Replikation asynchron erfolgt, besteht das Risiko einer Datenreplikationslatenz.
Erhöhte Komplexität: Erhöhte Systemkomplexität erfordert mehr Wartung und Verwaltung.
Zusätzlicher Ressourcenverbrauch: Für die Bereitstellung von Slave-Servern sind zusätzliche Hardwareressourcen erforderlich.
Auswirkungen auf die Schreibleistung: Alle Schreibvorgänge werden auf dem Masterserver ausgeführt und können zu einem Leistungsengpass führen.
3. Anwendbare Szenarien
Lese- und Schreibtrennung: Geeignet für Szenarien, in denen weit mehr Lesevorgänge als Schreibvorgänge stattfinden.
Datensicherung: Wird zur Echtzeitsicherung von Daten verwendet, um Datenverlust zu verhindern.
Hochverfügbarkeitsanforderungen: kritische Anwendungen, die die Servicekontinuität gewährleisten müssen
1. Index verwenden
Indizes sind der Schlüssel zur effizienten Abfrage von Daten in Tabellen.In MySQL können Sie den B-Tree-Index oder den Hash-Index verwenden, um Abfragevorgänge zu beschleunigen
Beispiel:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. Abfrageanweisungen optimieren
Durch die Optimierung von Abfragen kann die Leistung von MySQL verbessert werden.Die Ausführungszeit von Abfragen kann durch geeignete Abfrageanweisungen, Indizes und Caching-Mechanismen verkürzt und vollständige Tabellenscans sowie unnötige Datenoperationen vermieden werden.
Beispiel:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. Cache-Optimierung
Der Caching-Mechanismus von MySQL kann die Abfrageleistung verbessern. Durch die entsprechende Einstellung des Abfragecaches und des Systemcaches können Sie Festplatten-E/A-Vorgänge reduzieren und die Abfrageausführung beschleunigen.Verwenden Sie den Abfragecache von MySQL, den Pufferpool von InnoDB usw.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. Partitionstabelle
Wenn die Datenmenge sehr groß ist, können Sie die Verwendung von Partitionen und Tabellen in Betracht ziehen, um die Abfrageleistung zu verbessern. Durch die Partitionierung werden Daten in kleinere logische Teile unterteilt, die jeweils unabhängig abgefragt und verwaltet werden können. Bei der Tabellenaufteilung wird eine große Tabelle in mehrere kleine Tabellen aufgeteilt, und jede kleine Tabelle speichert einen Teil der Daten.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. Parameteroptimierung
https://blog.51cto.com/u_12196/6967500
https://blog.51cto.com/u_13259/6936668
6. Verbindungspoolverwaltung
Verbindungspooling ist eine Technologie zur Verwaltung von Datenbankverbindungen, mit der die Kosten für das Erstellen und Zerstören von Verbindungen effektiv gesenkt werden können. In einer Umgebung mit hoher Parallelität kann der Verbindungspool im Voraus eine bestimmte Anzahl von Verbindungen erstellen und diese im Verbindungspool speichern. Wenn eine neue Anfrage eingeht, kann die Verbindung aus dem Verbindungspool abgerufen werden, ohne dass die Verbindung jedes Mal neu erstellt werden muss. Dadurch können die Möglichkeiten der gleichzeitigen Verarbeitung erheblich verbessert werden.
7. Hardware-Optimierung:
Verwenden Sie leistungsstarke Hardwaregeräte wie Hochgeschwindigkeits-CPU, Speicher mit großer Kapazität und Hochgeschwindigkeitsfestplatte, um die Datenbankverarbeitungsfunktionen zu verbessern

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
