minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
https://blog.csdn.net/weixin_37519752/article/details/138728036
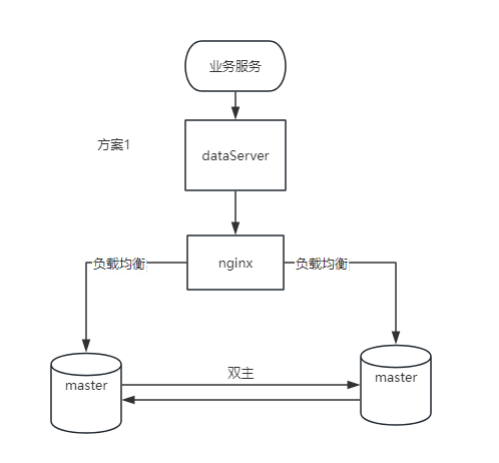
1. Vantagens
Escalabilidade de gravação: Ambos os nós podem lidar com operações de gravação, melhorando a escalabilidade das operações de gravação.
Alta disponibilidade: se algum nó falhar, o outro nó ainda poderá continuar a fornecer serviços, incluindo operações de gravação.
Failover: Nenhum mecanismo complexo de failover é necessário, pois ambos os nós estão ativos.
2. Desvantagens
Consistência de dados: Mecanismos complexos de detecção e resolução de conflitos são necessários para manter a consistência dos dados.
Requisitos de rede: Existem altos requisitos de estabilidade e latência da rede, porque a sincronização em tempo real entre nós é sensível à qualidade da rede.
Sobrecarga adicional: sobrecarga adicional de E/S de rede e disco causada pela sincronização em tempo real.
3. Cenários aplicáveis
Aplicativos distribuídos: aplicativos que exigem recursos de gravação em diferentes localizações geográficas.
Alta carga de gravação: cenários em que a carga de gravação precisa ser distribuída para melhorar o desempenho.
Requisitos de dados em tempo real: Aplicativos que exigem sincronização de dados em tempo real em vários nós.
Um mestre e um escravo, ou um mestre e vários escravos suportados por mysql5.7 ou superior
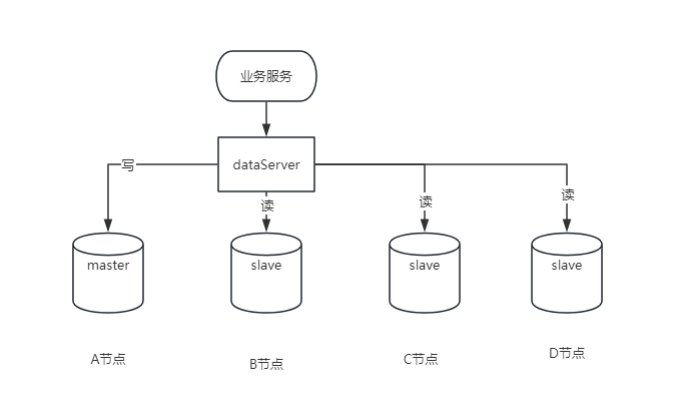
1. Vantagens
Redundância de dados: Fornece backup dinâmico de dados, reduzindo o risco de perda de dados.
Melhoria de desempenho: Um mestre e vários escravos, diferentes usuários leem de diferentes bancos de dados e o desempenho é melhorado.
Escalabilidade: Quando o tráfego aumenta, os servidores escravos podem ser facilmente adicionados sem afetar o uso do sistema.
Balanceamento de carga: Um mestre e vários escravos equivalem a compartilhar as tarefas do host e realizar o balanceamento de carga.
2. Desvantagens
Latência de dados: como a replicação é assíncrona, existe o risco de latência na replicação de dados.
Maior complexidade: O aumento da complexidade do sistema requer mais manutenção e gerenciamento.
Consumo de recursos adicionais: São necessários recursos de hardware adicionais para implantar servidores escravos.
Impacto no desempenho de gravação: Todas as operações de gravação são executadas no servidor mestre e podem se tornar um gargalo de desempenho.
3. Cenários aplicáveis
Separação de leitura e gravação: adequada para cenários onde há muito mais operações de leitura do que operações de gravação.
Backup de dados: usado para backup de dados em tempo real para evitar perda de dados.
Requisitos de alta disponibilidade: aplicações críticas que precisam garantir a continuidade do serviço
1. Use índice
Os índices são essenciais para a consulta eficiente de dados em tabelas.No MySQL, você pode usar o índice B-Tree ou índice hash para acelerar as operações de consulta
Exemplo:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. Otimize as instruções de consulta
A otimização de consultas pode melhorar o desempenho do MySQL.O tempo de execução de consultas pode ser reduzido por meio de instruções de consulta, índices e mecanismos de cache apropriados, e verificações completas de tabelas e operações de dados desnecessárias podem ser evitadas.
Exemplo:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. Otimização de cache
O mecanismo de cache do MySQL pode melhorar o desempenho da consulta. Ao definir adequadamente o cache de consulta e o cache do sistema, você pode reduzir as operações de E/S do disco e acelerar a execução da consulta.Use o cache de consulta do MySQL, o buffer pool do InnoDB, etc.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. Tabela de partição
Quando a quantidade de dados for muito grande, considere usar partições e tabelas para melhorar o desempenho da consulta. O particionamento divide os dados em partes lógicas menores, cada uma das quais pode ser consultada e mantida de forma independente. A divisão de tabelas consiste em dividir uma tabela grande em várias tabelas pequenas, e cada tabela pequena armazena uma parte dos dados.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. Ajuste de parâmetros
https://blog.51cto.com/u_12196/6967500
https://blog.51cto.com/u_13259/6936668
6. Gerenciamento do pool de conexões
O pool de conexões é uma tecnologia para gerenciar conexões de banco de dados que pode efetivamente reduzir o custo de criação e destruição de conexões. Em um ambiente de alta simultaneidade, o pool de conexões pode criar um certo número de conexões antecipadamente e salvá-las no pool de conexões. Quando uma nova solicitação chega, a conexão pode ser obtida do pool de conexões sem a necessidade de recriar a conexão todas as vezes. Isso pode melhorar muito os recursos de processamento simultâneo.
7. Otimização de hardware:
Use dispositivos de hardware de alto desempenho, como CPU de alta velocidade, memória de grande capacidade e disco de alta velocidade, para melhorar os recursos de processamento de banco de dados

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]