Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
https://blog.csdn.net/weixin_37519752/article/details/138728036
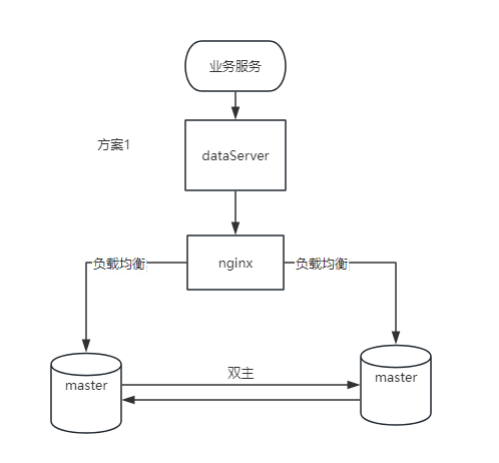
1. Ventajas
Escalabilidad de escritura: ambos nodos pueden manejar operaciones de escritura, mejorando la escalabilidad de las operaciones de escritura.
Alta disponibilidad: si algún nodo falla, el otro nodo aún puede continuar brindando servicios, incluidas operaciones de escritura.
Conmutación por error: no se requiere ningún mecanismo de conmutación por error complejo ya que ambos nodos están activos.
2. Desventajas
Coherencia de los datos: se requieren mecanismos complejos de detección y resolución de conflictos para mantener la coherencia de los datos.
Requisitos de red: existen altos requisitos para la estabilidad y latencia de la red, porque la sincronización en tiempo real entre nodos es sensible a la calidad de la red.
Gastos generales adicionales: gastos adicionales de E/S de red y disco causados por la sincronización en tiempo real.
3. Escenarios aplicables
Aplicaciones distribuidas: aplicaciones que requieren capacidades de escritura en diferentes ubicaciones geográficas.
Alta carga de escritura: escenarios en los que la carga de escritura debe distribuirse para mejorar el rendimiento.
Requisitos de datos en tiempo real: aplicaciones que requieren sincronización de datos en tiempo real en múltiples nodos.
Un maestro y un esclavo, o un maestro y varios esclavos compatibles con mysql5.7 o superior
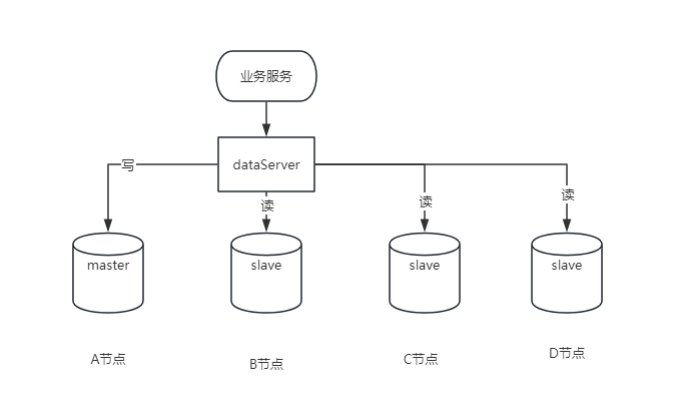
1. Ventajas
Redundancia de datos: proporciona una copia de seguridad de los datos en caliente, lo que reduce el riesgo de pérdida de datos.
Mejora del rendimiento: un maestro y varios esclavos, diferentes usuarios leen desde diferentes bases de datos y se mejora el rendimiento.
Escalabilidad: cuando el tráfico aumenta, los servidores esclavos se pueden agregar fácilmente sin afectar el uso del sistema.
Equilibrio de carga: un maestro y varios esclavos equivalen a compartir las tareas del host y realizar el equilibrio de carga.
2. Desventajas
Latencia de datos: dado que la replicación es asincrónica, existe el riesgo de que se produzca latencia en la replicación de datos.
Mayor complejidad: la mayor complejidad del sistema requiere más mantenimiento y gestión.
Consumo de recursos adicionales: se requieren recursos de hardware adicionales para implementar servidores esclavos.
Impacto en el rendimiento de escritura: todas las operaciones de escritura se realizan en el servidor maestro y pueden convertirse en un cuello de botella en el rendimiento.
3. Escenarios aplicables
Separación de lectura y escritura: adecuada para escenarios donde hay muchas más operaciones de lectura que de escritura.
Copia de seguridad de datos: se utiliza para realizar copias de seguridad de datos en tiempo real para evitar la pérdida de datos.
Requisitos de alta disponibilidad: aplicaciones críticas que necesitan garantizar la continuidad del servicio
1. Usar índice
Los índices son clave para la consulta eficiente de datos en tablas.En MySQL, puede utilizar el índice B-Tree o el índice hash para acelerar las operaciones de consulta
Ejemplo:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. Optimice las declaraciones de consulta
La optimización de las consultas puede mejorar el rendimiento de MySQL.El tiempo de ejecución de consultas se puede reducir mediante declaraciones de consulta, índices y mecanismos de almacenamiento en caché adecuados, y se pueden evitar escaneos completos de tablas y operaciones de datos innecesarias.
Ejemplo:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. Optimización de caché
El mecanismo de almacenamiento en caché de MySQL puede mejorar el rendimiento de las consultas. Al configurar adecuadamente la caché de consultas y la caché del sistema, puede reducir las operaciones de E/S del disco y acelerar la ejecución de consultas.Utilice el caché de consultas de MySQL, el grupo de búfer de InnoDB, etc.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. tabla de particiones
Cuando la cantidad de datos es muy grande, puede considerar el uso de particiones y tablas para mejorar el rendimiento de las consultas. La partición divide los datos en partes lógicas más pequeñas, cada una de las cuales se puede consultar y mantener de forma independiente. La división de tablas consiste en dividir una tabla grande en varias tablas pequeñas, y cada tabla pequeña almacena una parte de los datos.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. Ajuste de parámetros
https://blog.51cto.com/u_12196/6967500
https://blog.51cto.com/u_13259/6936668
6. Gestión del grupo de conexiones
La agrupación de conexiones es una tecnología para administrar conexiones de bases de datos que puede reducir efectivamente el costo de crear y destruir conexiones. En un entorno de alta concurrencia, el grupo de conexiones puede crear una cierta cantidad de conexiones por adelantado y guardarlas en el grupo de conexiones. Cuando llega una nueva solicitud, la conexión se puede obtener del grupo de conexiones sin necesidad de volver a crear la conexión cada vez. Esto puede mejorar enormemente las capacidades de procesamiento concurrente.
7. Optimización de hardware:
Utilice dispositivos de hardware de alto rendimiento, como CPU de alta velocidad, memoria de gran capacidad y disco de alta velocidad, para mejorar las capacidades de procesamiento de bases de datos.

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]