2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
https://blog.csdn.net/weixin_37519752/article/details/138728036
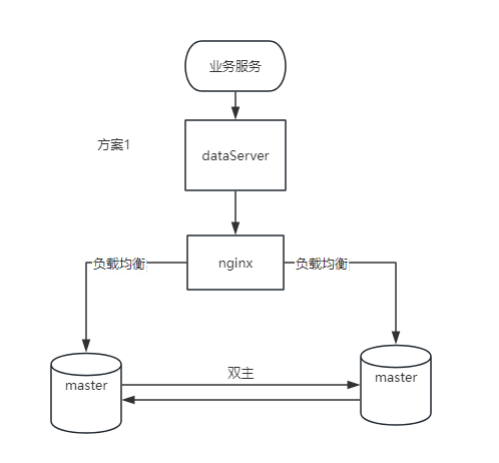
1. Avantages
Évolutivité d’écriture : les deux nœuds peuvent gérer les opérations d’écriture, améliorant ainsi l’évolutivité des opérations d’écriture.
Haute disponibilité : si un nœud tombe en panne, l'autre nœud peut toujours continuer à fournir des services, y compris des opérations d'écriture.
Basculement : aucun mécanisme de basculement complexe n'est requis car les deux nœuds sont actifs.
2. Inconvénients
Cohérence des données : des mécanismes complexes de détection et de résolution des conflits sont nécessaires pour maintenir la cohérence des données.
Exigences du réseau : les exigences en matière de stabilité et de latence du réseau sont élevées, car la synchronisation en temps réel entre les nœuds est sensible à la qualité du réseau.
Surcharge supplémentaire : surcharge supplémentaire d’E/S réseau et disque causée par la synchronisation en temps réel.
3. Scénarios applicables
Applications distribuées : applications qui nécessitent des capacités d'écriture dans différents emplacements géographiques.
Charge d'écriture élevée : scénarios dans lesquels la charge d'écriture doit être répartie pour améliorer les performances.
Exigences en matière de données en temps réel : applications qui nécessitent une synchronisation en temps réel des données sur plusieurs nœuds.
Un maître et un esclave, ou un maître et plusieurs esclaves pris en charge par mysql5.7 ou supérieur
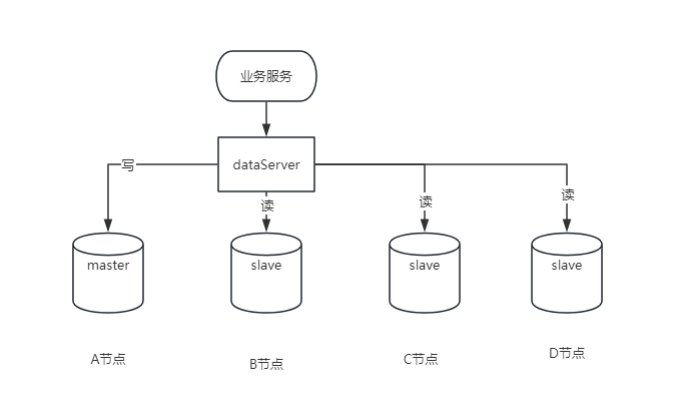
1. Avantages
Redondance des données : fournit une sauvegarde à chaud des données, réduisant ainsi le risque de perte de données.
Amélioration des performances : un maître et plusieurs esclaves, différents utilisateurs lisent à partir de différentes bases de données et les performances sont améliorées.
Évolutivité : lorsque le trafic augmente, des serveurs esclaves peuvent être facilement ajoutés sans affecter l'utilisation du système.
Équilibrage de charge : un maître et plusieurs esclaves équivalent au partage des tâches de l'hôte et à l'équilibrage de charge.
2. Inconvénients
Latence des données : la réplication étant asynchrone, il existe un risque de latence de réplication des données.
Complexité accrue : la complexité accrue du système nécessite davantage de maintenance et de gestion.
Consommation de ressources supplémentaires : des ressources matérielles supplémentaires sont nécessaires pour déployer des serveurs esclaves.
Impact sur les performances d'écriture : toutes les opérations d'écriture sont effectuées sur le serveur maître et peuvent devenir un goulot d'étranglement des performances.
3. Scénarios applicables
Séparation de lecture et d'écriture : convient aux scénarios dans lesquels il y a beaucoup plus d'opérations de lecture que d'opérations d'écriture.
Sauvegarde des données : utilisé pour la sauvegarde des données en temps réel afin d'éviter toute perte de données.
Exigences de haute disponibilité : applications critiques qui doivent assurer la continuité du service
1. Utiliser l'index
Les index sont essentiels à l’interrogation efficace des données dans les tables.Dans MySQL, vous pouvez utiliser l'index B-Tree ou l'index de hachage pour accélérer les opérations de requête
Exemple:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. Optimiser les instructions de requête
L'optimisation des requêtes peut améliorer les performances de MySQL.Le temps d'exécution des requêtes peut être réduit grâce à des instructions de requête, des index et des mécanismes de mise en cache appropriés, et les analyses de tables complètes et les opérations de données inutiles peuvent être évitées.
Exemple:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. Optimisation du cache
Le mécanisme de mise en cache de MySQL peut améliorer les performances des requêtes. En définissant correctement le cache de requêtes et le cache système, vous pouvez réduire les opérations d'E/S disque et accélérer l'exécution des requêtes.Utilisez le cache de requêtes de MySQL, le pool de tampons d'InnoDB, etc.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. Table de partition
Lorsque la quantité de données est très importante, vous pouvez envisager d'utiliser des partitions et des tables pour améliorer les performances des requêtes. Le partitionnement divise les données en parties logiques plus petites, dont chacune peut être interrogée et gérée indépendamment. Le fractionnement de table consiste à diviser une grande table en plusieurs petites tables, et chaque petite table stocke une partie des données.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. Réglage des paramètres
https://blog.51cto.com/u_12196/6967500
https://blog.51cto.com/u_13259/6936668
6. Gestion du pool de connexions
Le pooling de connexions est une technologie de gestion des connexions aux bases de données qui peut réduire efficacement le coût de création et de destruction des connexions. Dans un environnement à forte concurrence, le pool de connexions peut créer un certain nombre de connexions à l'avance et les enregistrer dans le pool de connexions. Lorsqu'une nouvelle demande arrive, la connexion peut être obtenue à partir du pool de connexions sans qu'il soit nécessaire de recréer la connexion à chaque fois. Cela peut grandement améliorer les capacités de traitement simultané.
7. Optimisation du matériel :
Utilisez des périphériques matériels hautes performances, tels qu'un processeur haute vitesse, une mémoire de grande capacité et un disque haute vitesse, pour améliorer les capacités de traitement des bases de données.

Il se consacre à la recherche technologique depuis plus de trente ans, maîtrise divers langages tels que java, linux, javascript, php, css, etc., et a apporté de nombreuses contributions dans le domaine de l'open source. une station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
