2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
https://blog.csdn.net/weixin_37519752/article/details/138728036
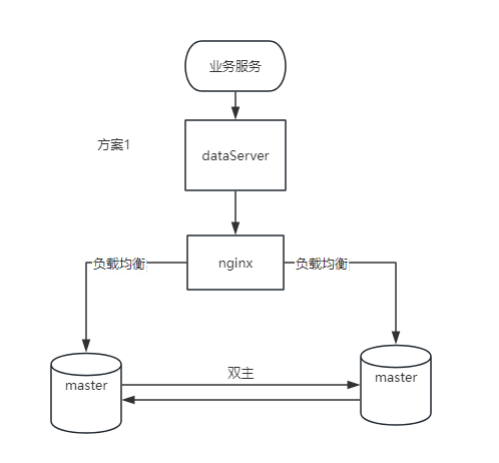
1. Advantages
Write scalability: Both nodes can process write operations, which improves the scalability of write operations.
High availability: When any node fails, another node can continue to provide services, including write operations.
Failover: No complex failover mechanisms are required as both nodes are active.
2. Disadvantages
Data consistency: Complex conflict detection and resolution mechanisms are required to maintain data consistency.
Network requirements: There are high requirements for network stability and latency, because real-time synchronization between nodes is sensitive to network quality.
Additional overhead: additional network and disk I/O overhead caused by real-time synchronization.
3. Applicable scenarios
Distributed applications: Applications that require write capabilities in different geographical locations.
High write load: Scenarios where the write load needs to be dispersed to improve performance.
Real-time data requirements: Applications that need to synchronize data across multiple nodes in real time.
One master and one slave, or one master and multiple slaves MySQL 5.7 and above versions support
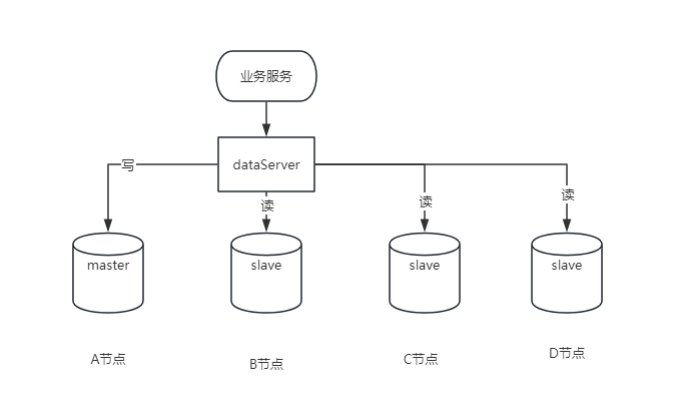
1. Advantages
Data redundancy: provides hot backup of data, reducing the risk of data loss.
Performance improvement: One master and multiple slaves, different users read from different databases, performance improvement.
Scalability: When traffic increases, you can easily add slave servers without affecting system usage.
Load balancing: One master and multiple slaves is equivalent to sharing the host tasks and performing load balancing.
2. Disadvantages
Data delay: Since replication is asynchronous, there is a risk of data replication delay.
Increased complexity: Increased system complexity requires more maintenance and management.
Additional resource consumption: Additional hardware resources are required to deploy slave servers.
Write performance impact: All write operations are performed on the primary server, which may become a performance bottleneck.
3. Applicable scenarios
Read-write separation: Applicable to scenarios where read operations far outnumber write operations.
Data backup: used for real-time data backup to prevent data loss.
High availability requirements: Critical applications that need to ensure service continuity
1. Use indexes
Indexes are the key to efficient querying of data in a table. In MySQL, you can use B-Tree indexes or hash indexes to speed up query operations.
Example:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. Optimize query statements
Optimizing queries can improve MySQL performance. You can use appropriate query statements, indexes, and cache mechanisms to reduce query execution time, avoid full table scans and unnecessary data operations.
Example:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. Cache optimization
MySQL's cache mechanism can improve query performance. By properly setting the query cache and system cache, you can reduce disk IO operations and speed up query execution. Use MySQL's query cache, InnoDB's buffer pool, etc.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. Partition and table
When the amount of data is very large, you can consider using partitions and sharding to improve query performance. Partitioning divides the data into multiple smaller logical parts, each of which can be independently queried and maintained. And sharding is to split a large table into multiple small tables, each of which stores a part of the data.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. Parameter Tuning
https://blog.51cto.com/u_12196/6967500
https://blog.51cto.com/u_13259/6936668
6. Connection pool management
Connection pool is a technology for managing database connections, which can effectively reduce the overhead of creating and destroying connections. In a high-concurrency environment, the connection pool can create a certain number of connections in advance and save them in the connection pool. When a new request comes, it can get a connection from the connection pool without having to recreate the connection every time. This can greatly improve the concurrent processing capability.
7. Hardware optimization:
Use high-performance hardware devices, such as high-speed CPU, large-capacity memory, and high-speed disk, to improve the processing power of the database

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.
