le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Italiano: https://blog.csdn.net/weixin_37519752/article/details/138728036
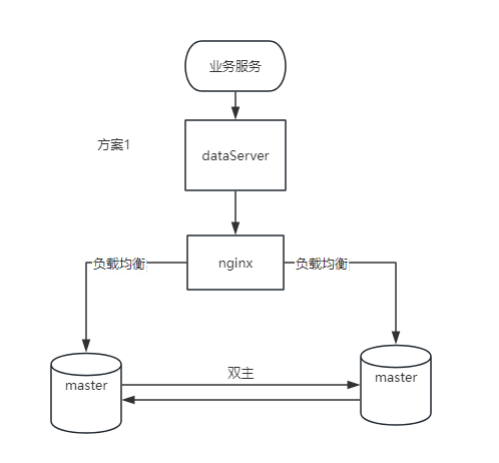
1. Vantaggi
Scalabilità di scrittura: entrambi i nodi possono gestire operazioni di scrittura, migliorando la scalabilità delle operazioni di scrittura.
Disponibilità elevata: se un nodo si guasta, l'altro nodo può comunque continuare a fornire servizi, comprese le operazioni di scrittura.
Failover: non è richiesto alcun meccanismo di failover complesso poiché entrambi i nodi sono attivi.
2. Svantaggi
Coerenza dei dati: per mantenere la coerenza dei dati sono necessari complessi meccanismi di rilevamento e risoluzione dei conflitti.
Requisiti di rete: esistono requisiti elevati per la stabilità e la latenza della rete, poiché la sincronizzazione in tempo reale tra i nodi è sensibile alla qualità della rete.
Overhead aggiuntivo: sovraccarico I/O aggiuntivo della rete e del disco causato dalla sincronizzazione in tempo reale.
3. Scenari applicabili
Applicazioni distribuite: applicazioni che richiedono capacità di scrittura in diverse posizioni geografiche.
Carico di scrittura elevato: scenari in cui è necessario distribuire il carico di scrittura per migliorare le prestazioni.
Requisiti dei dati in tempo reale: applicazioni che richiedono la sincronizzazione in tempo reale dei dati su più nodi.
Un master e uno slave, oppure un master e più slave supportati da mysql5.7 o successivo
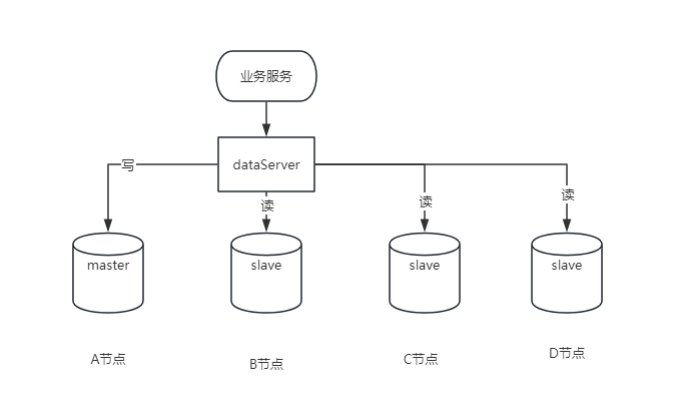
1. Vantaggi
Ridondanza dei dati: fornisce il backup a caldo dei dati, riducendo il rischio di perdita di dati.
Miglioramento delle prestazioni: un master e più slave, utenti diversi leggono da database diversi e le prestazioni sono migliorate.
Scalabilità: quando il traffico aumenta, è possibile aggiungere facilmente server slave senza influire sull'utilizzo del sistema.
Bilanciamento del carico: un master e più slave equivalgono alla condivisione delle attività dell'host e all'esecuzione del bilanciamento del carico.
2. Svantaggi
Latenza dei dati: poiché la replica è asincrona, esiste il rischio di latenza della replica dei dati.
Maggiore complessità: una maggiore complessità del sistema richiede maggiore manutenzione e gestione.
Consumo di risorse aggiuntive: sono necessarie risorse hardware aggiuntive per distribuire i server slave.
Impatto sulle prestazioni di scrittura: tutte le operazioni di scrittura vengono eseguite sul server master e potrebbero diventare un collo di bottiglia delle prestazioni.
3. Scenari applicabili
Separazione di lettura e scrittura: adatta per scenari in cui sono presenti molte più operazioni di lettura che di scrittura.
Backup dei dati: utilizzato per il backup dei dati in tempo reale per prevenirne la perdita.
Requisiti di alta disponibilità: applicazioni critiche che devono garantire la continuità del servizio
1. Usa l'indice
Gli indici sono fondamentali per eseguire query efficienti sui dati nelle tabelle.In MySQL, puoi utilizzare l'indice B-Tree o l'indice hash per velocizzare le operazioni di query
Esempio:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. Ottimizza le dichiarazioni di query
L'ottimizzazione delle query può migliorare le prestazioni di MySQL.Il tempo di esecuzione delle query può essere ridotto attraverso istruzioni di query, indici e meccanismi di memorizzazione nella cache appropriati ed è possibile evitare scansioni complete di tabelle e operazioni sui dati non necessarie.
Esempio:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. Ottimizzazione della cache
Il meccanismo di memorizzazione nella cache di MySQL può migliorare le prestazioni delle query. Impostando in modo appropriato la cache delle query e la cache di sistema, è possibile ridurre le operazioni di I/O del disco e velocizzare l'esecuzione delle query.Utilizza la cache delle query di MySQL, il pool di buffer di InnoDB, ecc.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. Tabella delle partizioni
Quando la quantità di dati è molto elevata, puoi prendere in considerazione l'utilizzo di partizioni e tabelle per migliorare le prestazioni delle query. Il partizionamento divide i dati in parti logiche più piccole, ciascuna delle quali può essere interrogata e gestita in modo indipendente. La suddivisione della tabella consiste nel dividere una tabella di grandi dimensioni in più tabelle piccole e ciascuna tabella piccola memorizza una parte dei dati.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. Regolazione dei parametri
Italiano: https://blog.51cto.com/u_12196/6967500
Italiano: https://blog.51cto.com/u_13259/6936668
6. Gestione del pool di connessioni
Il pooling delle connessioni è una tecnologia per la gestione delle connessioni al database che può ridurre efficacemente i costi di creazione e distruzione delle connessioni. In un ambiente ad alta concorrenza, il pool di connessioni può creare un certo numero di connessioni in anticipo e salvarle nel pool di connessioni. Quando arriva una nuova richiesta, la connessione può essere ottenuta dal pool di connessioni senza la necessità di ricrearla ogni volta. Ciò può migliorare notevolmente le capacità di elaborazione simultanea.
7. Ottimizzazione dell'hardware:
Utilizzare dispositivi hardware ad alte prestazioni, come CPU ad alta velocità, memoria di grande capacità e disco ad alta velocità, per migliorare le capacità di elaborazione del database

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]