내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
https://blog.csdn.net/weixin_37519752/article/details/138728036
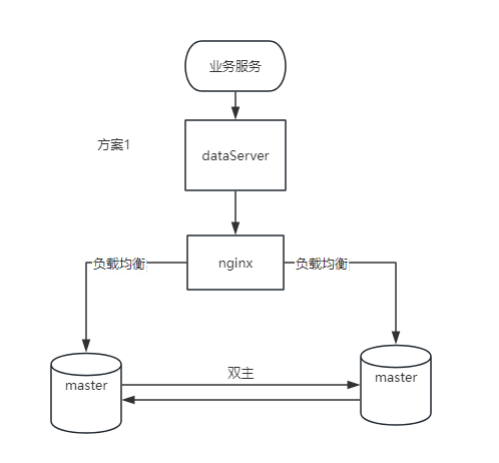
1. 장점
쓰기 확장성: 두 노드 모두 쓰기 작업을 처리할 수 있으므로 쓰기 작업의 확장성이 향상됩니다.
고가용성: 노드 하나에 장애가 발생하더라도 다른 노드는 계속해서 쓰기 작업을 포함한 서비스를 제공할 수 있습니다.
장애 조치: 두 노드가 모두 활성화되어 있으므로 복잡한 장애 조치 메커니즘이 필요하지 않습니다.
2. 단점
데이터 일관성: 데이터 일관성을 유지하려면 복잡한 충돌 감지 및 해결 메커니즘이 필요합니다.
네트워크 요구 사항: 노드 간 실시간 동기화는 네트워크 품질에 민감하기 때문에 네트워크 안정성 및 대기 시간에 대한 요구 사항이 높습니다.
추가 오버헤드: 실시간 동기화로 인해 발생하는 추가 네트워크 및 디스크 I/O 오버헤드입니다.
3. 적용 가능한 시나리오
분산 애플리케이션: 다양한 지리적 위치에서 쓰기 기능이 필요한 애플리케이션입니다.
높은 쓰기 로드: 성능 향상을 위해 쓰기 로드를 분산시켜야 하는 시나리오입니다.
실시간 데이터 요구 사항: 여러 노드에서 데이터의 실시간 동기화가 필요한 애플리케이션입니다.
하나의 마스터와 하나의 슬레이브, 또는 하나의 마스터와 여러 슬레이브가 mysql5.7 이상에서 지원됩니다.
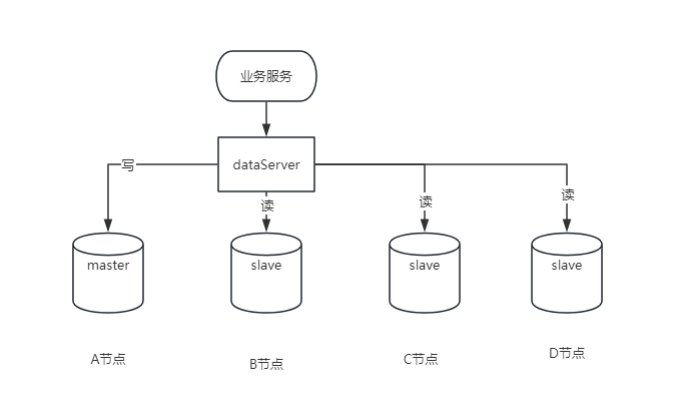
1. 장점
데이터 중복성: 데이터의 핫 백업을 제공하여 데이터 손실 위험을 줄입니다.
성능 개선: 하나의 마스터와 여러 슬레이브, 다양한 사용자가 서로 다른 데이터베이스에서 읽기 및 성능이 향상되었습니다.
확장성: 트래픽이 증가하면 시스템 사용에 영향을 주지 않고 슬레이브 서버를 쉽게 추가할 수 있습니다.
로드 밸런싱: 하나의 마스터와 여러 슬레이브는 호스트 작업을 공유하고 로드 밸런싱을 수행하는 것과 같습니다.
2. 단점
데이터 대기 시간: 복제가 비동기식이므로 데이터 복제 대기 시간이 발생할 위험이 있습니다.
복잡성 증가: 시스템 복잡성이 증가하면 더 많은 유지 관리 및 관리가 필요합니다.
추가 리소스 소비: 슬레이브 서버를 배포하려면 추가 하드웨어 리소스가 필요합니다.
쓰기 성능 영향: 모든 쓰기 작업은 마스터 서버에서 수행되며 성능 병목 현상이 발생할 수 있습니다.
3. 적용 가능한 시나리오
읽기 및 쓰기 분리: 쓰기 작업보다 읽기 작업이 훨씬 많은 시나리오에 적합합니다.
데이터 백업: 데이터 손실을 방지하기 위해 데이터를 실시간 백업하는 데 사용됩니다.
고가용성 요구 사항: 서비스 연속성을 보장해야 하는 중요한 애플리케이션
1. 인덱스를 활용하라
인덱스는 테이블의 데이터를 효율적으로 쿼리하는 데 핵심입니다.MySQL에서는 B-Tree 인덱스 또는 해시 인덱스를 사용하여 쿼리 작업 속도를 높일 수 있습니다.
예:
CREATE INDEX index_name ON table_name (column1, column2, ...);
2. 쿼리문 최적화
쿼리를 최적화하면 MySQL 성능이 향상될 수 있습니다.적절한 쿼리문, 인덱스 및 캐싱 메커니즘을 통해 쿼리 실행 시간을 단축할 수 있으며 전체 테이블 스캔 및 불필요한 데이터 작업을 피할 수 있습니다.
예:
# 通过使用索引和合适的查询语句
SELECT * FROM table_name WHERE column1 = "value" AND column2 = "value";
# 避免使用通配符查询,可以使用索引来加速查询
SELECT * FROM table_name WHERE column1 LIKE "value%";
# 避免在查询条件中使用函数,函数会导致索引失效
SELECT * FROM table_name WHERE DATE(column1) > "2021-01-01";
3. 캐시 최적화
MySQL의 캐싱 메커니즘은 쿼리 성능을 향상시킬 수 있습니다. 쿼리 캐시와 시스템 캐시를 적절하게 설정하면 디스크 IO 작업을 줄이고 쿼리 실행 속도를 높일 수 있습니다.MySQL의 쿼리 캐시, InnoDB의 버퍼 풀 등을 사용합니다.
# 启用查询缓存
query_cache_type = 1
query_cache_size = 64M
4. 파티션 테이블
데이터 양이 매우 큰 경우 파티션과 테이블을 사용하여 쿼리 성능을 향상시키는 것을 고려할 수 있습니다. 파티셔닝은 데이터를 더 작은 논리적 부분으로 나누며 각 부분은 독립적으로 쿼리하고 유지 관리할 수 있습니다. 테이블 분할은 큰 테이블을 여러 개의 작은 테이블로 분할하는 것이며 각 작은 테이블은 데이터의 일부를 저장합니다.
# 分区
CREATE TABLE table_name (
...
)
PARTITION BY RANGE (column_name) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
)
# 分表
CREATE TABLE table_name (
...
)
PARTITION BY HASH (column_name) PARTITIONS 4;
5. 매개변수 튜닝
https://blog.51cto.com/u_12196/6967500
https://blog.51cto.com/u_13259/6936668
6. Connection Pool 관리
연결 풀링(Connection Pooling)은 연결을 생성하고 삭제하는 데 드는 비용을 효과적으로 줄일 수 있는 데이터베이스 연결 관리 기술입니다. 동시성이 높은 환경에서는 연결 풀이 미리 일정 개수의 연결을 생성해 연결 풀에 저장할 수 있습니다. 새로운 요청이 들어오면 매번 연결을 다시 생성할 필요 없이 연결 풀에서 연결을 얻을 수 있습니다. 이는 동시 처리 기능을 크게 향상시킬 수 있습니다.
7. 하드웨어 최적화:
고속 CPU, 대용량 메모리, 고속 디스크 등 고성능 하드웨어 장치를 활용해 데이터베이스 처리 능력 향상

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com