2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Kennen Sie MySQL-Cluster? Verstehen Sie den Master-Slave-Replikationsprozess? Dieser Artikel konzentriert sich auf die Vorstellung der Interviewfragen, und ich wünsche mir, dass jeder Programmierer mitmacht! ! !
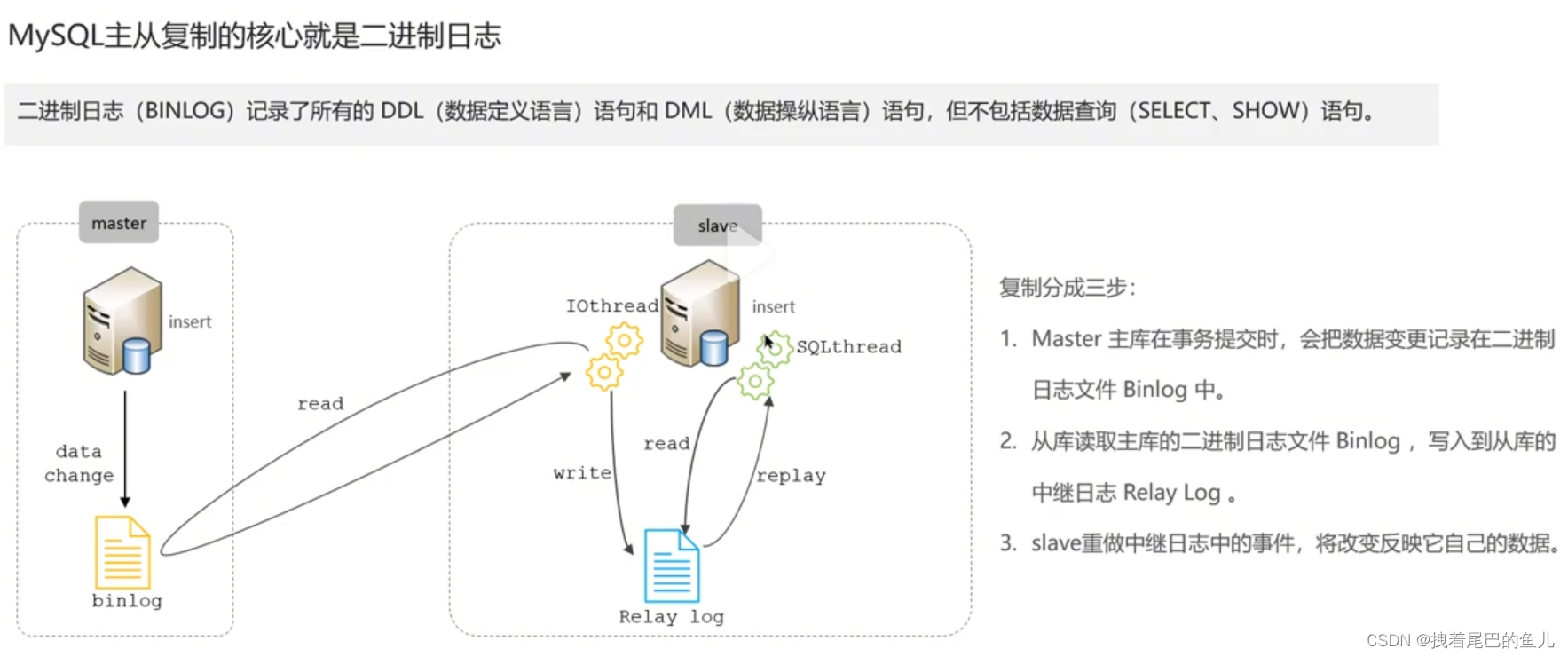
In der Online-Umgebung stellen wir im Allgemeinen eine MySQL-Instanz mit 1 Master und 1 Slave oder 1 Master mit mehreren Slaves bereit, um eine hohe MySQL-Verfügbarkeit zu erreichen, und die Lese-/Schreibtrennung erfolgt über Binlog-Protokolle.
Informationen zum Aufbau des MySQL-Master-Slave-Clusters finden Sie im folgenden Artikel des Bloggers
Als Speicher für relationale Daten weist MySQL einen Leistungsengpass auf, wenn das Datenvolumen einer einzelnen Tabelle 30 Millionen überschreitet. Ebenso weisen die von einer einzelnen MySQL-Instanz unterstützten Clientverbindungen und Parallelität zu bestimmten Engpässen auf Erwägen Sie die Verwendung der Technologie der Unterdatenbank und Untertabelle zur Implementierung.
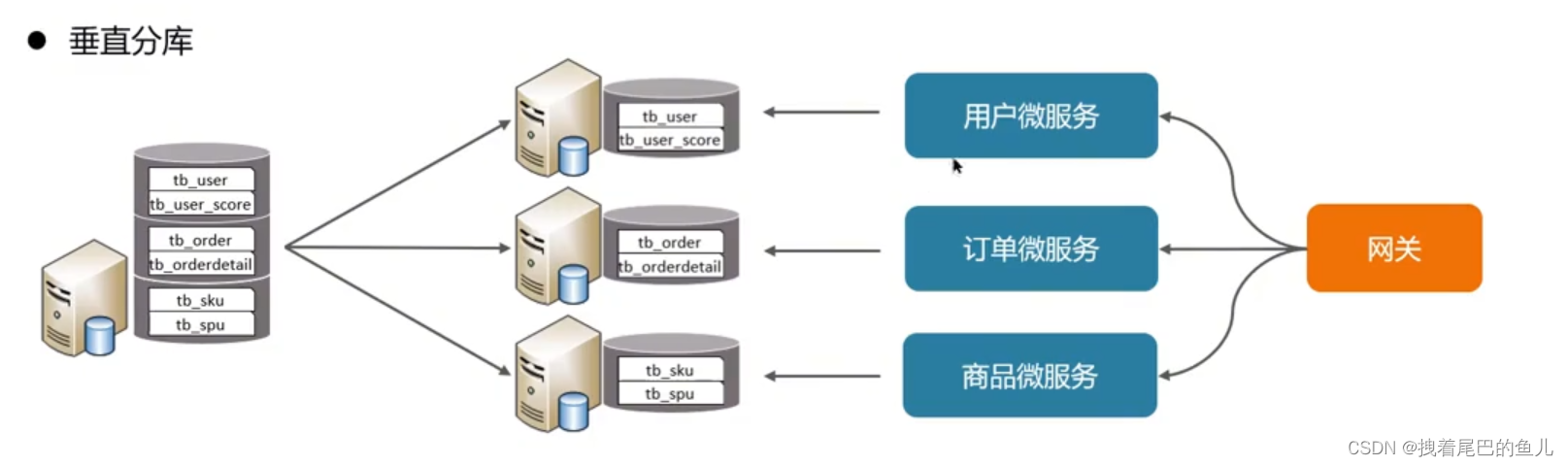
Heutige Microservices sind beispielsweise vertikal aufgeteilt. Jedes Microservice-Modul kann mit einer eigenen MySQL-Datenbankinstanz verbunden werden. Seine Besonderheit besteht darin, dass es je nach Geschäft verschiedene Tabellen in verschiedene Bibliotheken aufteilt. und Daten auf verschiedenen Ebenen erweitern; Festplatten-I0 und Datenvolumenverbindungen bei hoher Parallelität erhöhen;
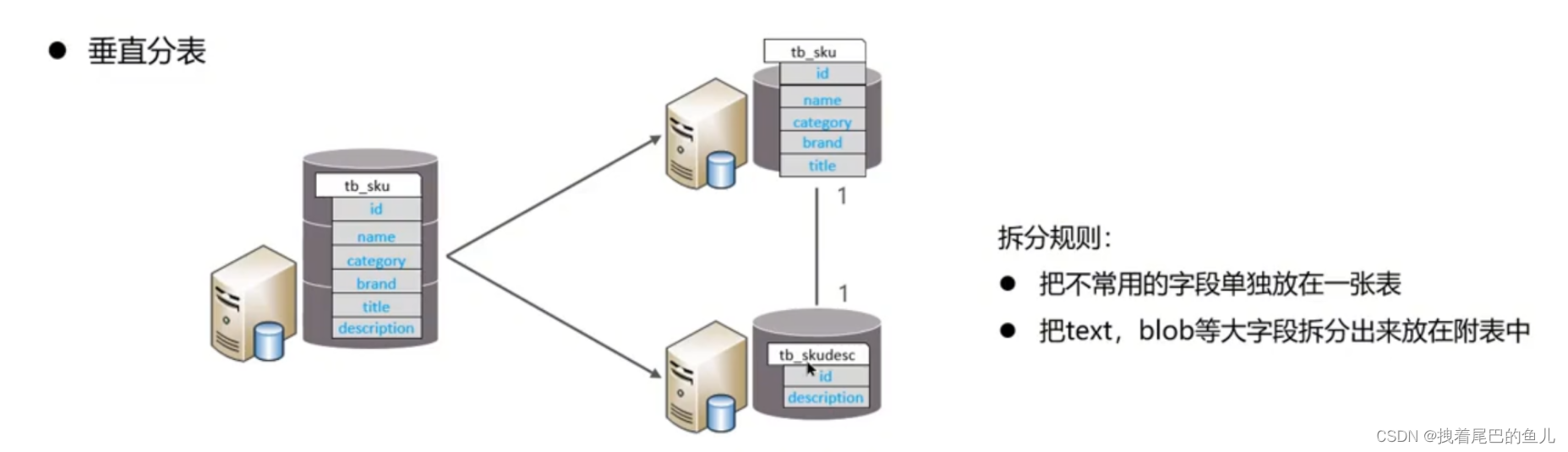
Basierend auf den Feldern werden verschiedene Felder entsprechend den Feldattributen in verschiedene Tabellen aufgeteilt.Dies ist möglich: Trennen Sie heiße und kalte Daten, reduzieren Sie den Wettbewerb beim E/A-Übergang, und die beiden Tabellen beeinflussen sich nicht gegenseitig.
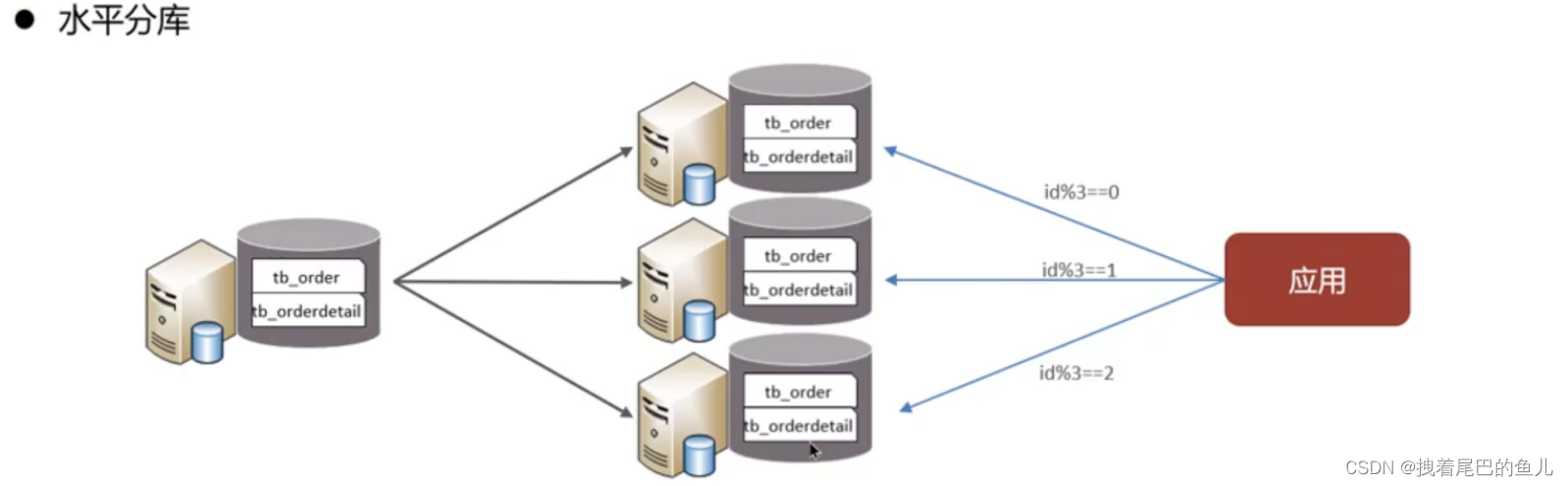
Teilen Sie Daten aus einer Bibliothek in mehrere Bibliotheken auf. Es löst das Leistungsengpassproblem einer großen Anzahl einzelner Bibliotheken und hoher Parallelität und verbessert die Stabilität und Verfügbarkeit des Systems.
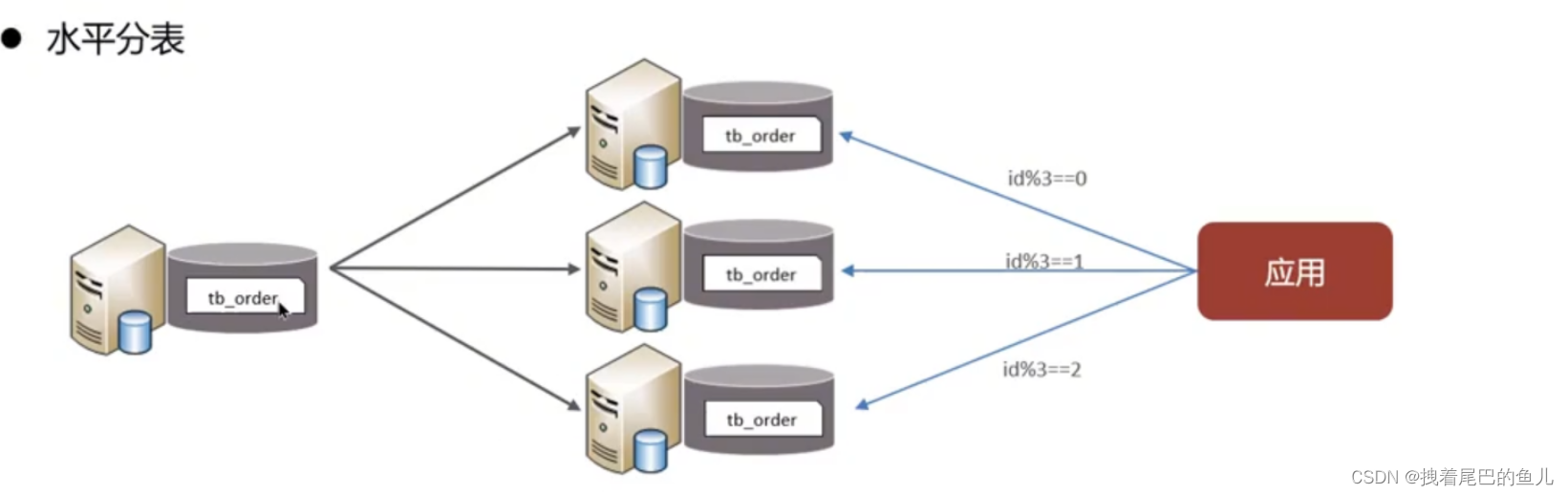
Teilen Sie die Daten einer Tabelle in mehrere Tabellen auf (können sich in derselben Bibliothek befinden). Optimieren Sie Leistungsprobleme, die durch übermäßiges Datenvolumen in einer einzelnen Tabelle verursacht werden. Vermeiden Sie E/A-Konflikte und verringern Sie die Wahrscheinlichkeit von Tabellensperren.
Wir haben Datenbankinstanzen für verschiedene Unternehmen in Spring-Boot eingerichtet, die von Spring-Cloud verwaltet werden, und eine vertikale Partitionierung durchgeführt. Um die Speicherung großer Datenmengen zu bewältigen, verwendet unser Projekt auch die Mycat-Middleware zur Aufteilung von Datenbanken und Tabellen.
Mycat-Installation und Spring-Boot-Integration:
Nachdem die Datenbank in Tabellen unterteilt wurde, treten verteilte Transaktionen, Routing-Regeleinstellungen und knotenübergreifende Paging-Probleme auf, da die Daten in mehreren Tabellen in mehreren Datenbanken gespeichert werden.
In diesem Artikel werden einige Interviewfragen zu MySQL-Clustern, Unterdatenbanken und Tabellen beantwortet.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen