2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Do you know MySQL clusters? Do you understand the process of master-slave replication? How do you deal with massive amounts of data? This article focuses on introducing interview questions, and I wish every programmer can land a job!!!
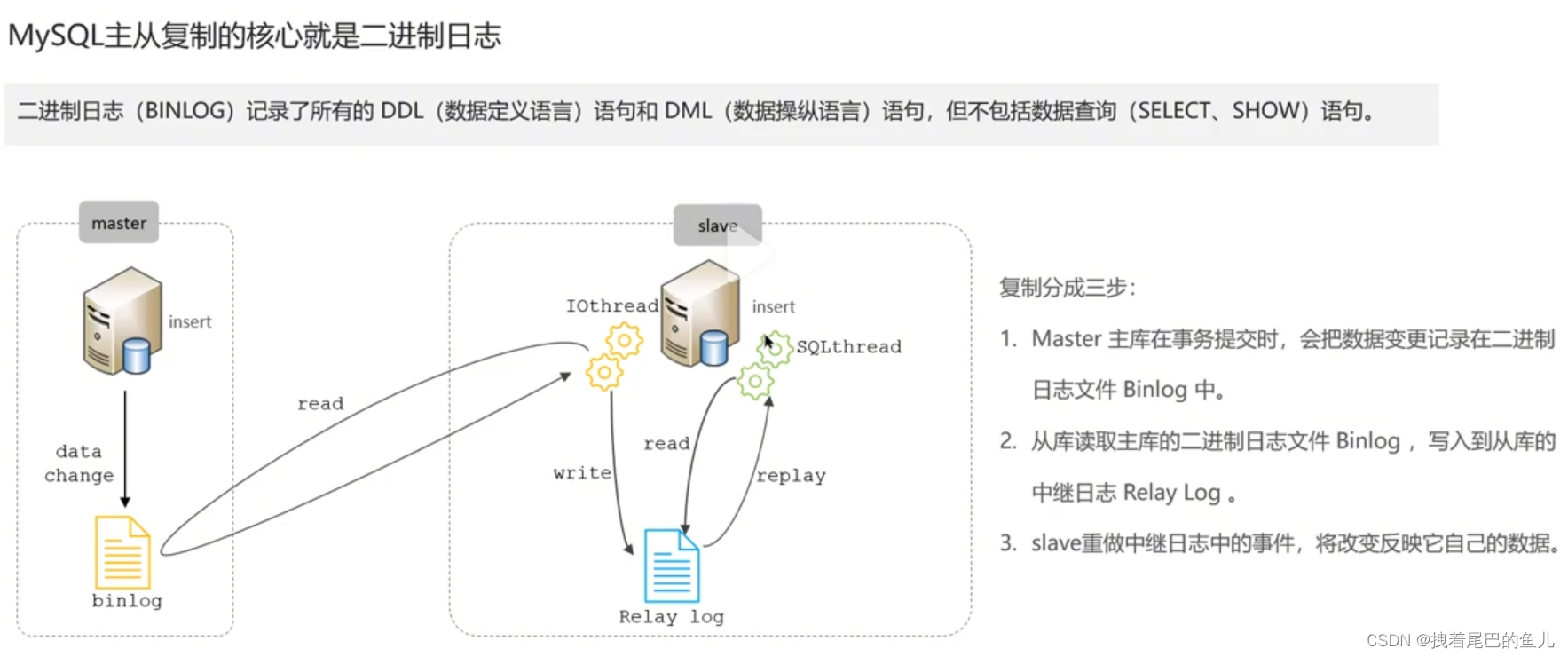
In the online environment, we usually deploy 1 master and 1 slave, or 1 master and multiple slaves MySQL instance to achieve high availability and read-write separation of MySQL; MySQL master-slave synchronization is performed through binlog logs.
For the construction of MySQL master-slave cluster, please refer to the following article by the blogger
As a relational data storage system, Mysql will encounter performance bottlenecks when the data volume of a single table exceeds 30 million. Similarly, the number of client connections and concurrency supported by a single instance of MySQL has certain bottlenecks. At this time, the system needs to consider using the technology of sharding libraries and tables to achieve this.
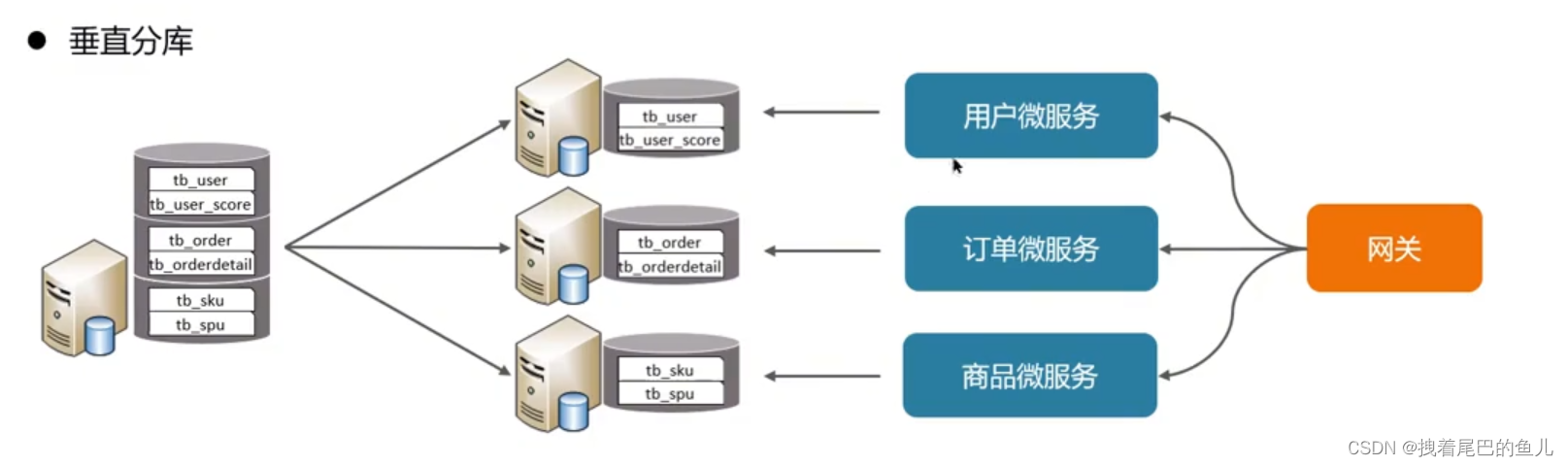
For example, microservices have been vertically split. Each microservice module may be connected to its own Mysql database instance. Its characteristics are based on tables. Different tables are split into different databases according to the business. Data is hierarchically managed, maintained, monitored, and expanded according to the business. Under high concurrency, the disk I0 and data volume connection number are increased.
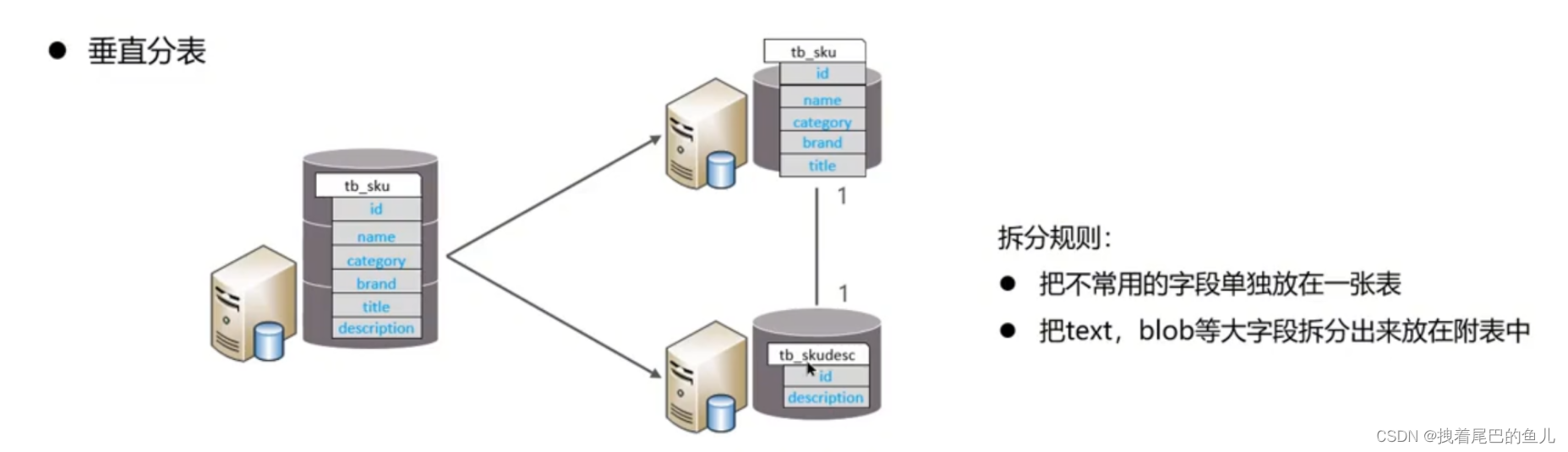
Based on the fields, different fields are split into different tables according to the field attributes. This can achieve: separation of hot and cold data; reduce IO transition contention, and the two tables do not affect each other
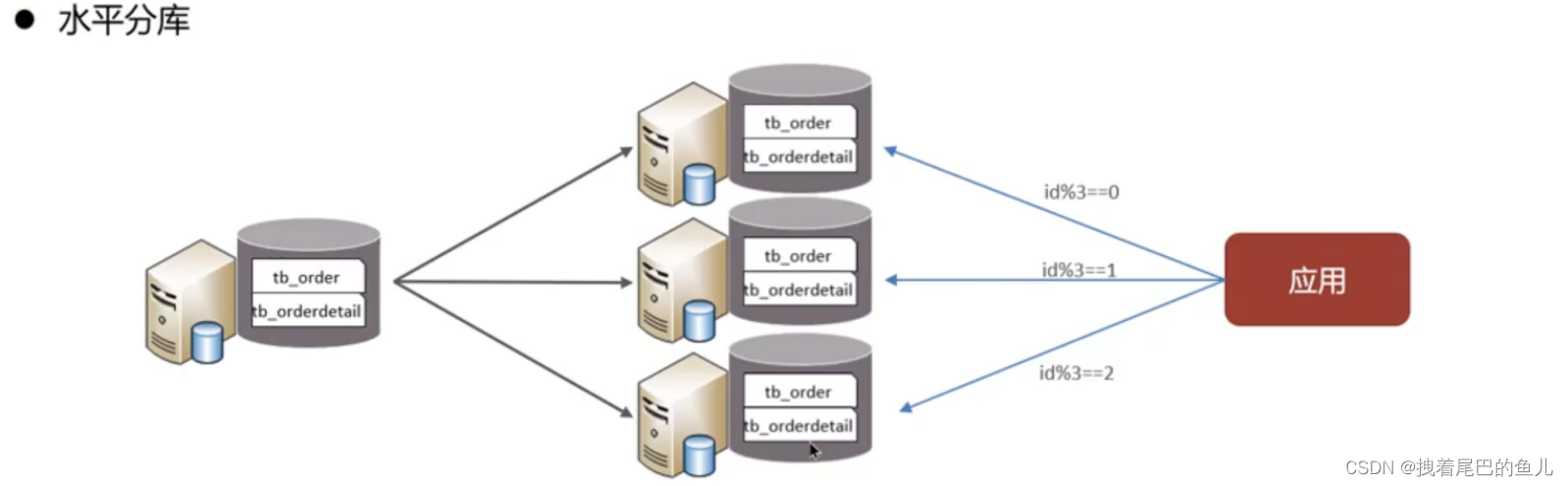
Split the data of a database into multiple databases. This solves the performance bottleneck problem of large number and high concurrency in a single database and improves the stability and availability of the system.
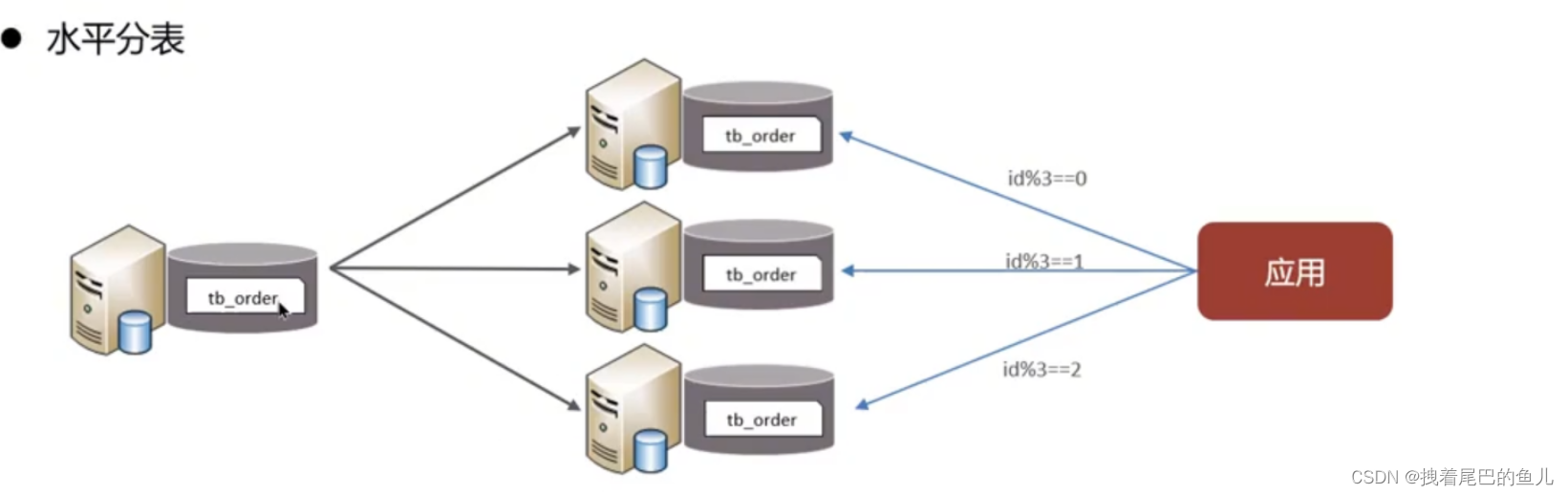
Split the data of a table into multiple tables (can be in the same database). Optimize the performance issues caused by excessive data volume in a single table; avoid IO contention and reduce the chance of locking the table;
We set up database instances according to different businesses in spring-boot managed by spring-cloud, and performed vertical partitioning. In order to cope with the storage of massive data, our project also used Mycat middleware to partition the database and tables.
Mycat installation and Spring-boot integration:
After the database and table are divided, because the data will be stored in multiple tables of multiple databases, distributed transactions will be encountered; distributed global ID, routing rule settings, and cross-node paging issues;
This article sorts out some interview questions about MySQL cluster and sharding.

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.