моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Знаете ли вы кластеры MySQL? Понимаете ли вы процесс репликации master-slave? Как вы справляетесь с огромными объемами данных? Эта статья посвящена представлению вопросов на собеседовании, и я желаю, чтобы каждый программист смог принять участие в этом! ! !
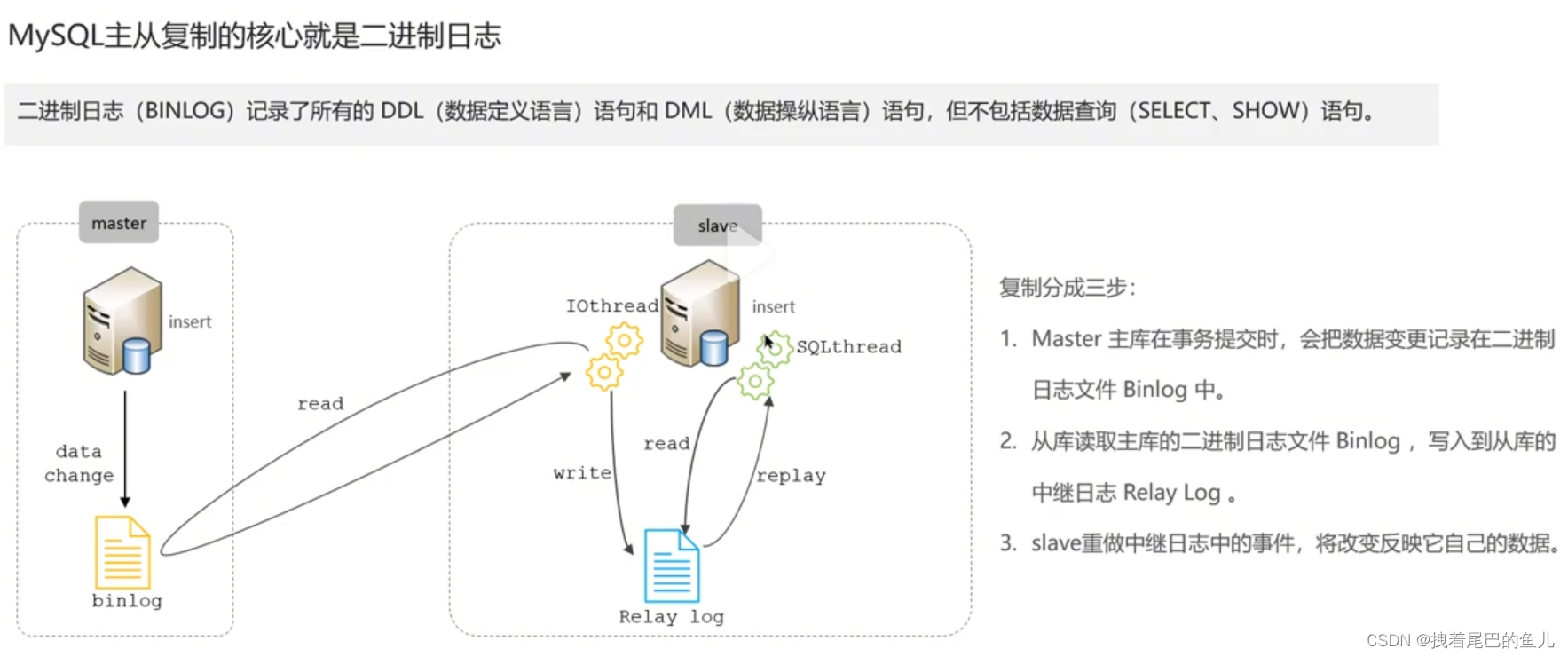
В онлайн-среде мы обычно развертываем экземпляр Mysql с 1 главным и 1 подчиненным устройством или с 1 главным устройством с несколькими подчиненными устройствами для достижения высокой доступности Mysql и разделения чтения и записи. Синхронизация главного и подчиненного устройств Mysql выполняется через журналы binlog.
По поводу построения мастер-подчиненного кластера Mysql вы можете обратиться к статье блоггера ниже.
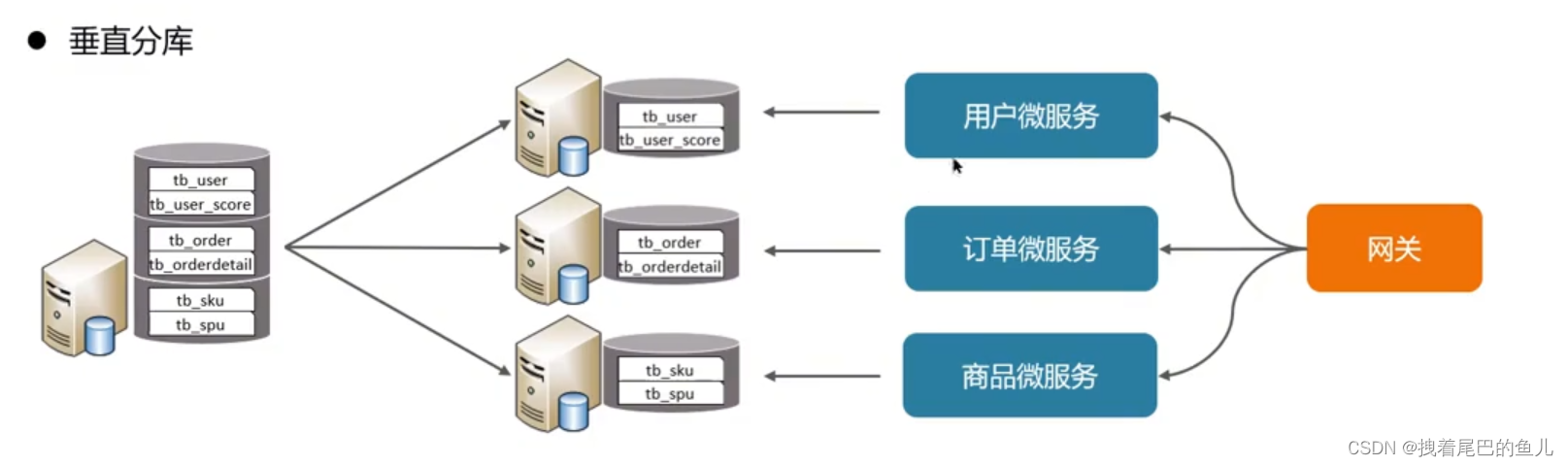
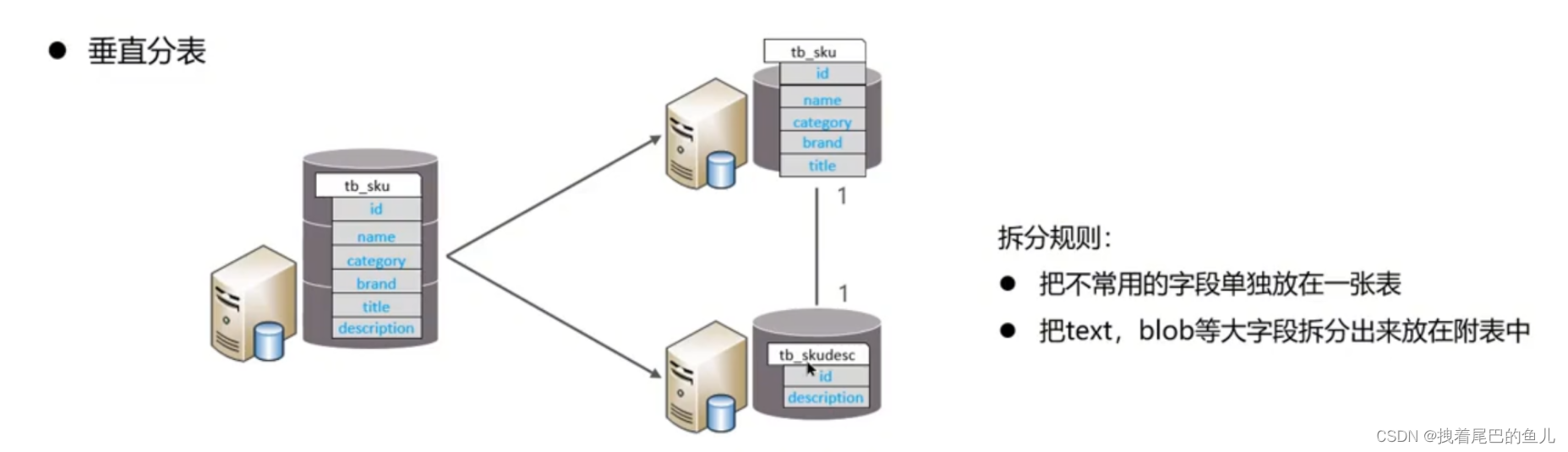
В качестве хранилища реляционных данных MySQL будет иметь проблемы с производительностью, когда объем данных одной таблицы превысит 30 миллионов. Аналогичным образом, клиентское соединение и параллелизм, поддерживаемые одним экземпляром MySQL, имеют определенные узкие места. рассмотрите возможность использования технологии подбазы данных и подтаблицы для реализации.
Например, современные микросервисы разделены по вертикали. Каждый модуль микросервиса может быть подключен к собственному экземпляру базы данных Mysql. Его особенностью является то, что он основан на таблицах и разделяет разные таблицы на разные библиотеки в зависимости от бизнеса. и расширять данные на разных уровнях, увеличивая количество подключений к диску I0 и объемам данных при высокой степени параллелизма;
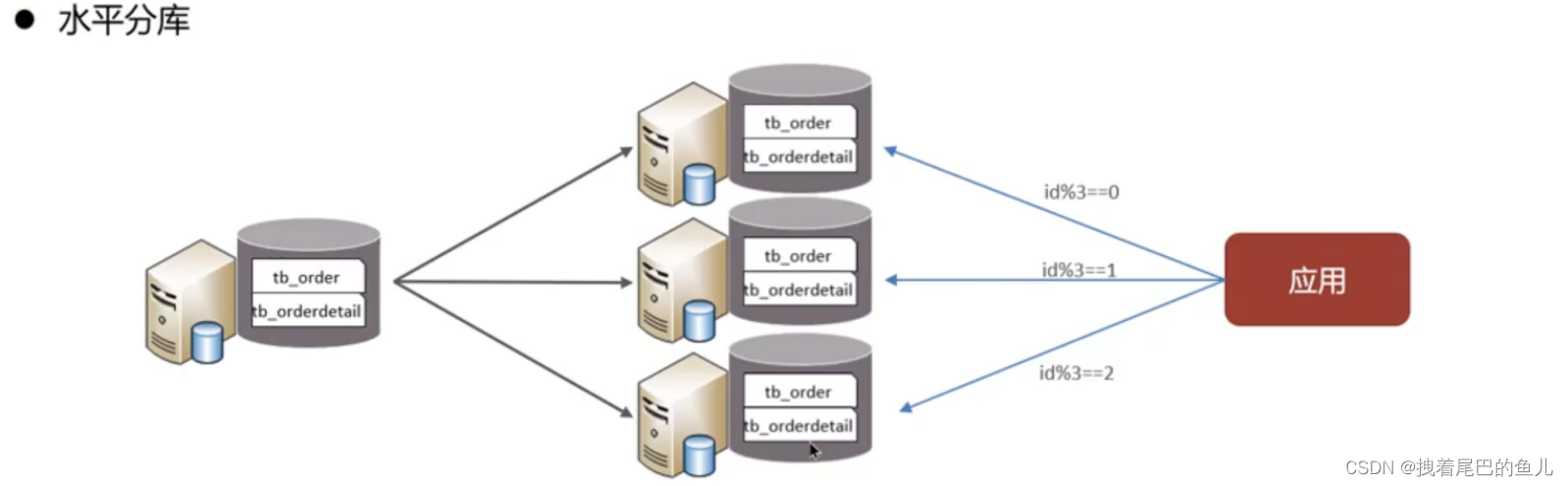
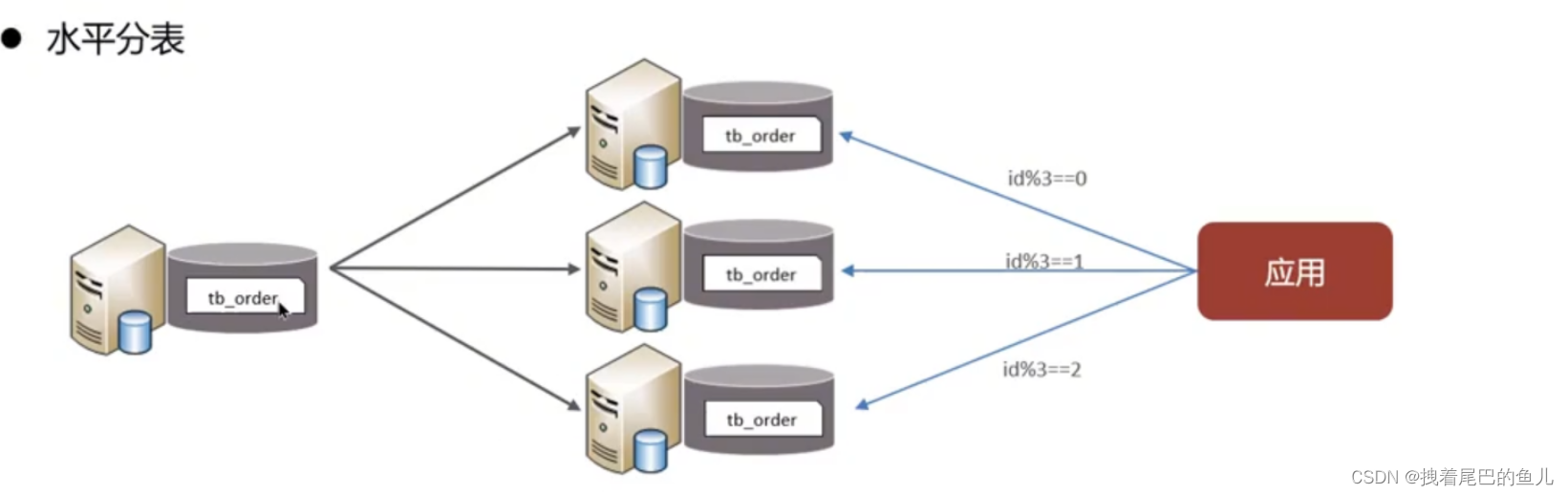
В зависимости от полей разные поля разбиваются на разные таблицы в соответствии с атрибутами полей.Это можно сделать: разделить «горячие» и «холодные» данные; уменьшить конкуренцию за переходы ввода-вывода, и две таблицы не будут влиять друг на друга.
Разделите данные из одной библиотеки на несколько библиотек. Это решает проблему узкого места в производительности, связанную с большим количеством отдельных библиотек и высокой степенью параллелизма, а также повышает стабильность и доступность системы.
Разделите данные одной таблицы на несколько таблиц (могут находиться в одной библиотеке). Оптимизируйте проблемы с производительностью, вызванные чрезмерным объемом данных в одной таблице, избегайте конфликтов ввода-вывода и уменьшайте вероятность блокировок таблиц;
Мы установили экземпляры базы данных для разных предприятий в Spring-Boot, управляемые Spring-Cloud, и выполнили вертикальное секционирование. Чтобы справиться с хранением больших объемов данных, наш проект также использует промежуточное программное обеспечение Mycat для разделения баз данных и таблиц.
Установка Mycat и интеграция Spring-boot:
После разделения базы данных на таблицы, поскольку данные будут храниться в нескольких таблицах в нескольких базах данных, будут возникать распределенные транзакции с распределенными глобальными идентификаторами, настройками правил маршрутизации и проблемами подкачки между узлами;
В этой статье рассматриваются некоторые вопросы интервью о кластерах, подбазах данных и таблицах Mysql.

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com