le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Conosci i cluster MySQL? Comprendi il processo di replica master-slave Come gestisci enormi quantità di dati? Questo articolo si concentra sull'introduzione delle domande dell'intervista e mi auguro che ogni programmatore possa partecipare! ! !
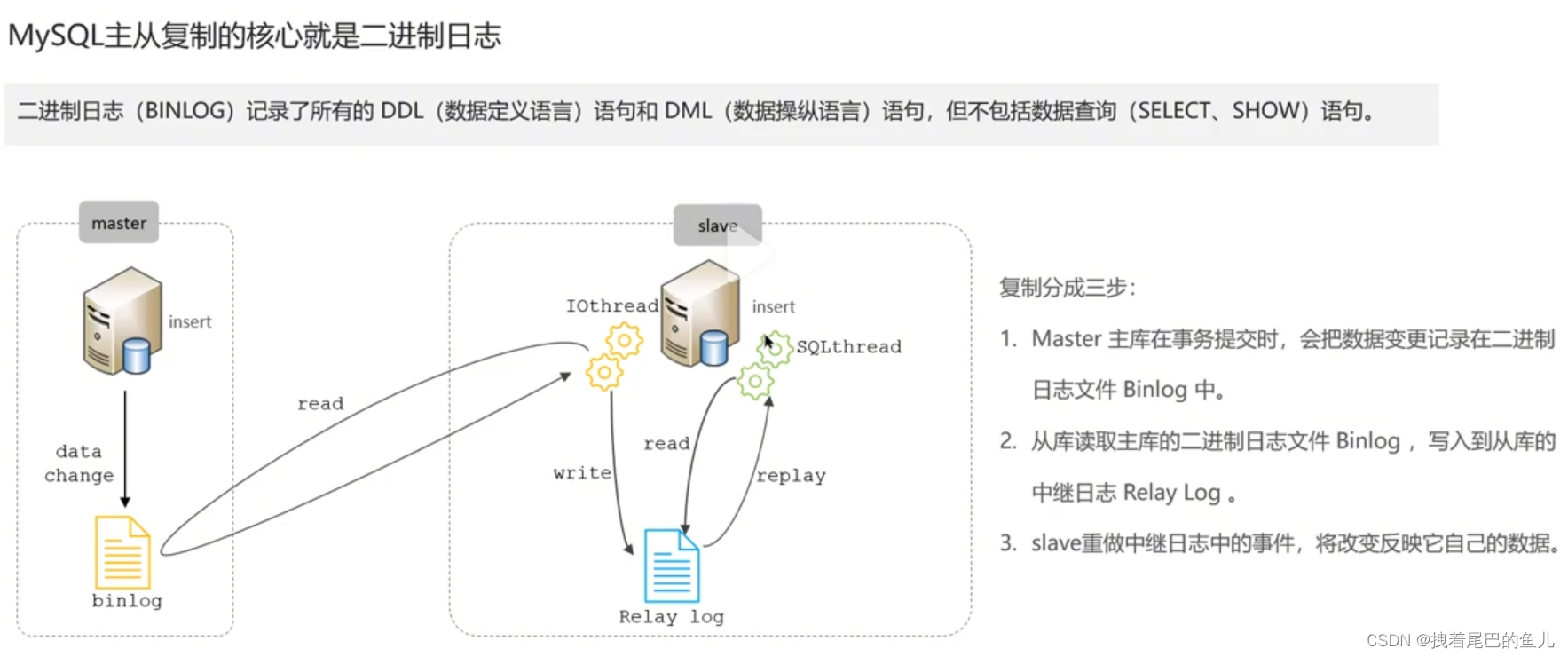
Nell'ambiente online, generalmente distribuiamo un'istanza Mysql con 1 master e 1 slave, o 1 master con più slave, per ottenere l'elevata disponibilità di Mysql e la separazione lettura-scrittura Mysql master-slave viene eseguita tramite log binlog.
Per quanto riguarda la costruzione del cluster Mysql master-slave potete fare riferimento all'articolo qui sotto del blogger
Come archiviazione di dati relazionali, MySQL avrà un collo di bottiglia nelle prestazioni quando il volume di dati di una singola tabella supera i 30 milioni. Allo stesso modo, la connessione client e la concorrenza supportate da una singola istanza MySQL presentano alcuni colli di bottiglia. In questo momento, il sistema ne ha bisogno prendere in considerazione l'utilizzo della tecnologia del sottodatabase e della sottotabella da implementare.
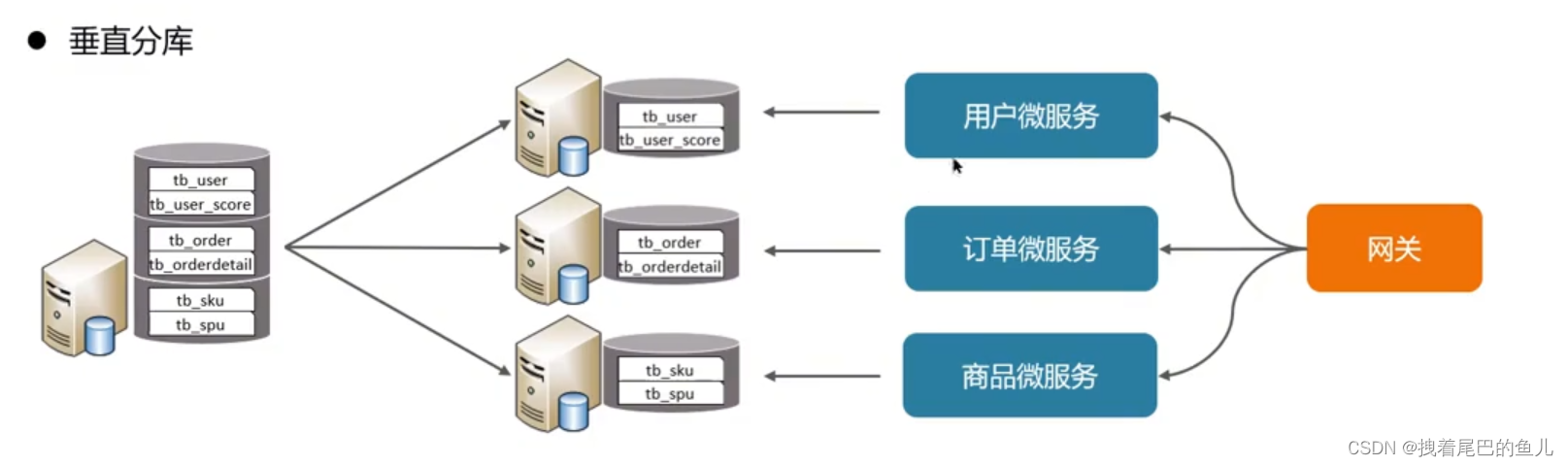
Ad esempio, i microservizi di oggi sono stati suddivisi verticalmente. Ogni modulo di microservizi può essere collegato alla propria istanza del database Mysql. La sua caratteristica è che si basa su tabelle e divide diverse tabelle in diverse librerie a seconda dell'attività. ed espandere i dati a diversi livelli; aumentare l'I0 del disco e le connessioni del volume di dati in condizioni di concorrenza elevata;
In base ai campi, i diversi campi vengono suddivisi in diverse tabelle in base agli attributi del campo.Si può fare: separare i dati caldi e freddi; ridurre la concorrenza nella transizione IO e le due tabelle non si influenzano a vicenda.
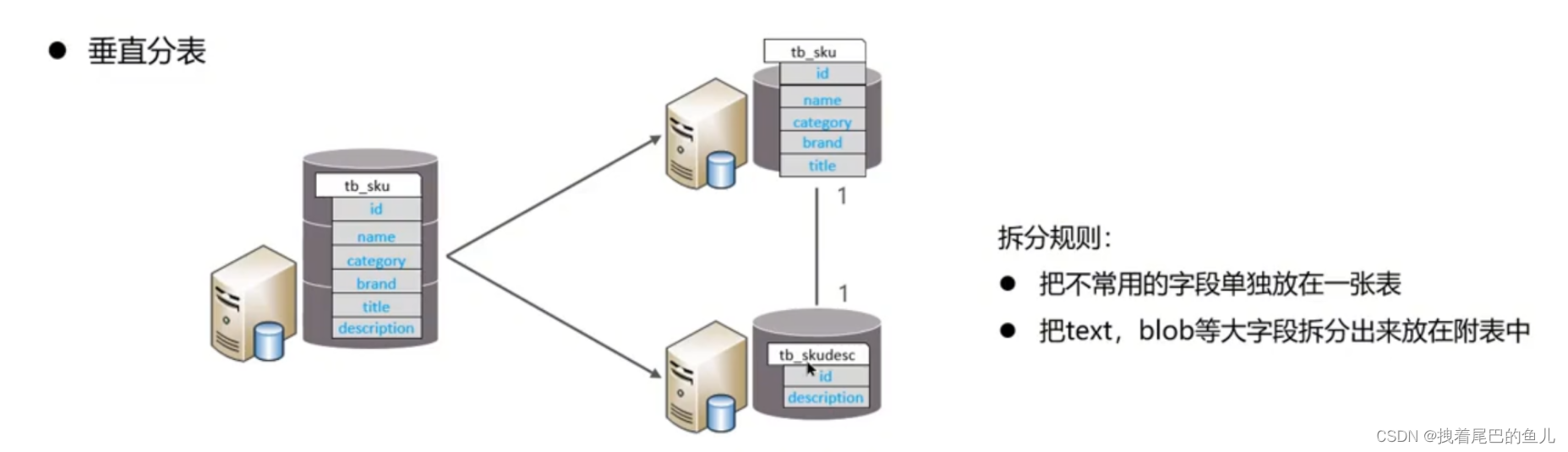
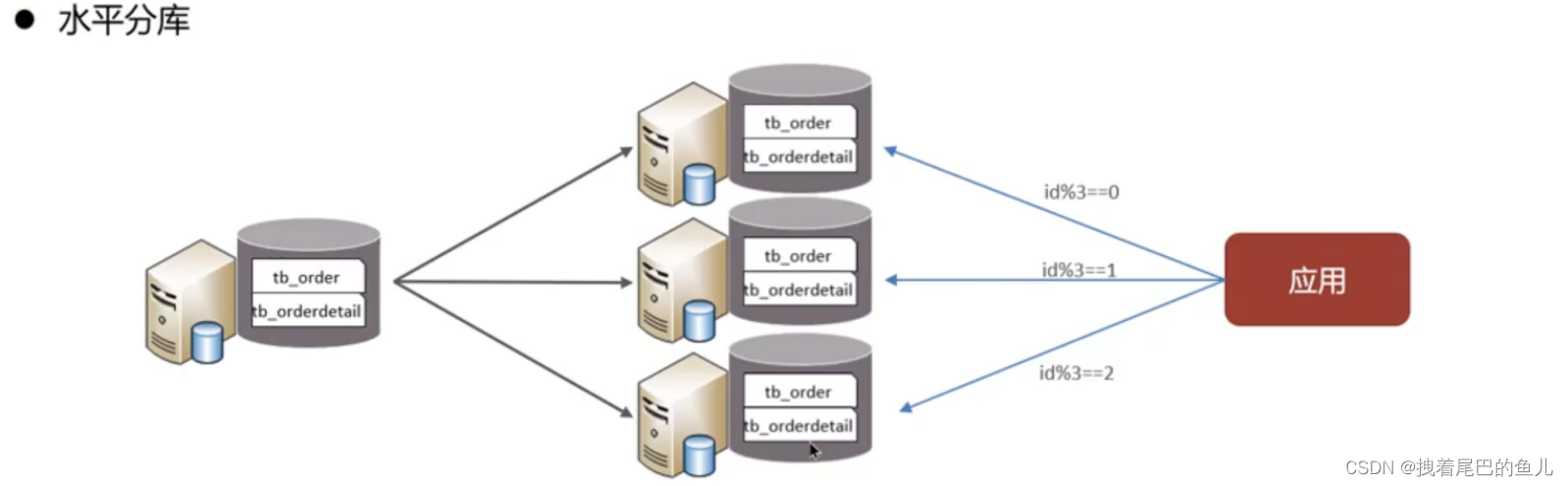
Dividere i dati da una libreria in più librerie. Risolve il problema del collo di bottiglia delle prestazioni dovuto al gran numero di singole librerie e all'elevata concorrenza e migliora la stabilità e la disponibilità del sistema.
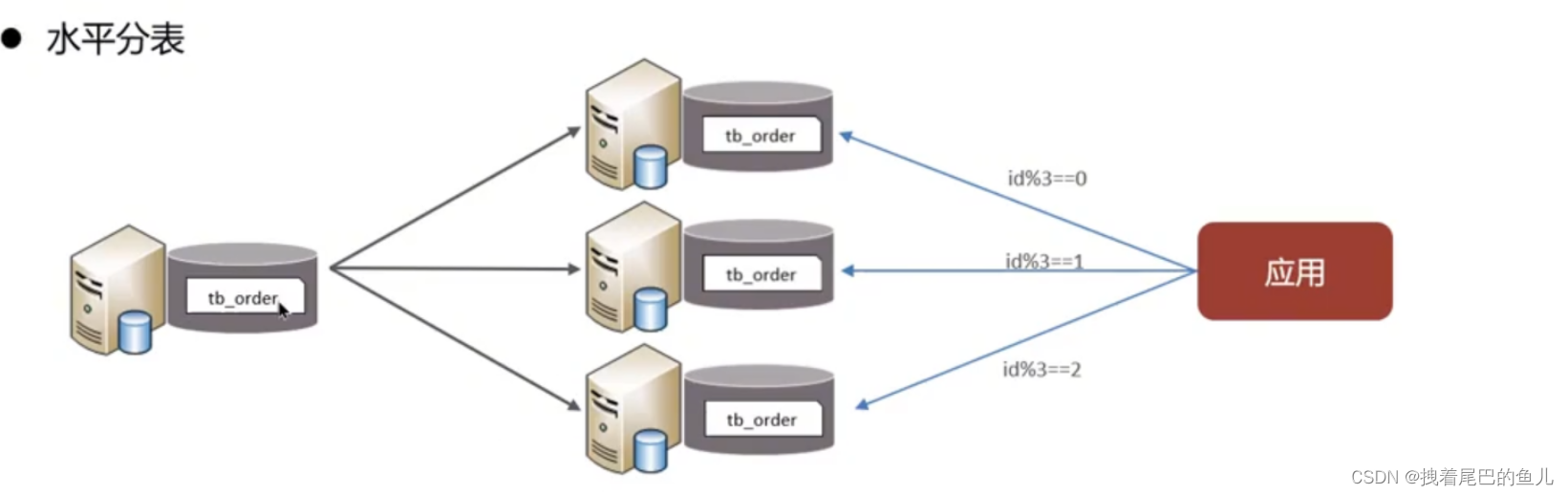
Dividere i dati di una tabella in più tabelle (possono trovarsi nella stessa libreria). Ottimizzare i problemi di prestazioni causati da un volume eccessivo di dati in una singola tabella; evitare conflitti di I/O e ridurre la probabilità di blocchi della tabella;
Abbiamo creato istanze di database in base a diverse aziende in spring-boot gestite da spring-cloud e realizzato il partizionamento verticale. Per far fronte all'archiviazione di enormi quantità di dati, il nostro progetto utilizza anche il middleware Mycat per dividere database e tabelle.
Installazione di Mycat e integrazione Spring-boot:
Dopo che il database è stato diviso in tabelle, poiché i dati verranno archiviati in più tabelle in più database, si verificheranno transazioni distribuite, ID globali distribuiti, impostazioni delle regole di routing e problemi di paging tra nodi;
Questo articolo risolve alcune domande dell'intervista sui cluster MySQL, sui database secondari e sulle tabelle.

Si dedica alla ricerca tecnologica da più di trent'anni, è esperto in vari linguaggi come java, linux, javascript, php, css, ecc., e ha apportato numerosi contributi nel campo dell'open source una stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro. Tutti la controllano

Posta[email protected]