minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Você conhece clusters MySQL? Você entende o processo de replicação mestre-escravo? Este artigo se concentra na introdução das perguntas da entrevista, e desejo que todos os programadores possam participar! ! !
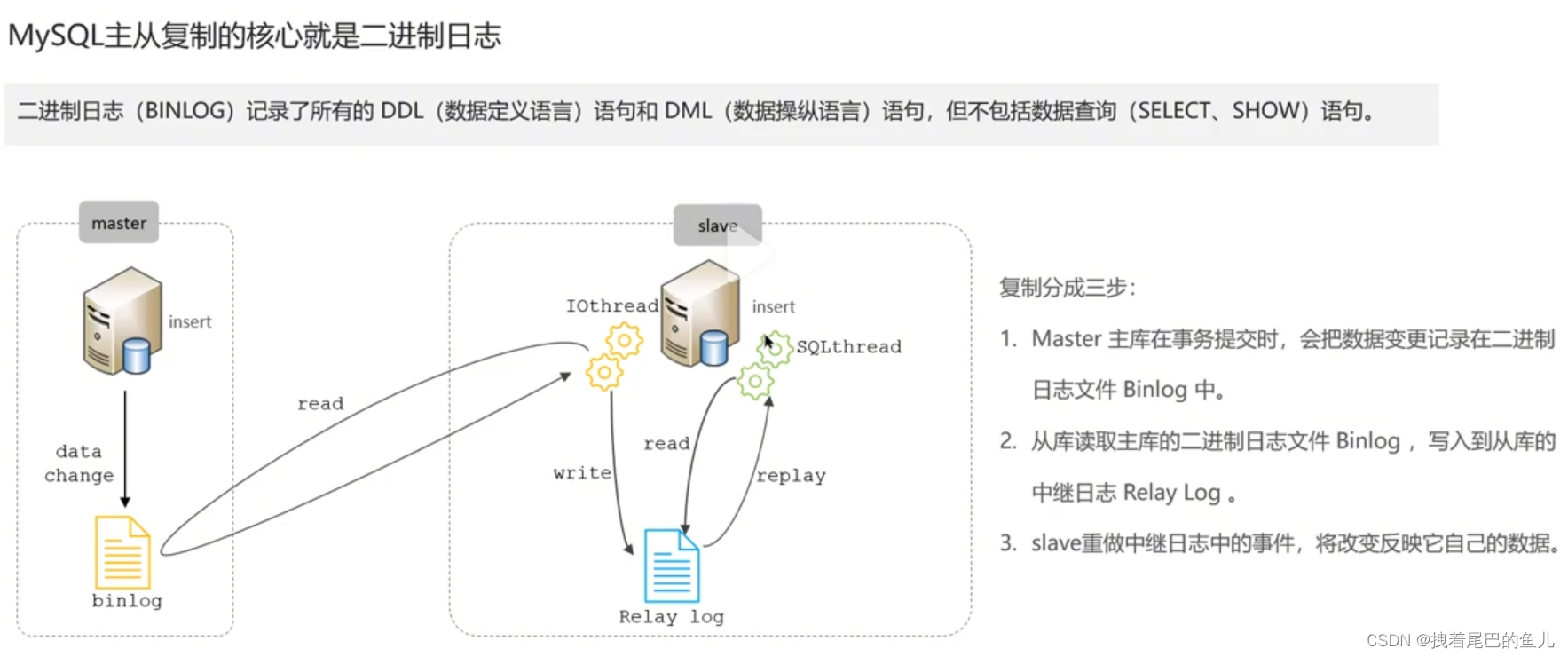
No ambiente online, geralmente implantamos uma instância Mysql com 1 mestre e 1 escravo, ou 1 mestre com vários escravos, para obter alta disponibilidade do Mysql e separação de leitura e gravação do Mysql mestre-escravo é realizada por meio de logs binários;
Em relação à construção do cluster mestre-escravo Mysql, você pode consultar o artigo abaixo do blogueiro
Como armazenamento de dados relacionais, o MySQL terá um gargalo de desempenho quando o volume de dados de uma única tabela exceder 30 milhões. Da mesma forma, a conexão do cliente e a simultaneidade suportadas por uma única instância do MySQL apresentam certos gargalos. considere usar a tecnologia de subbanco de dados e subtabela para implementar.
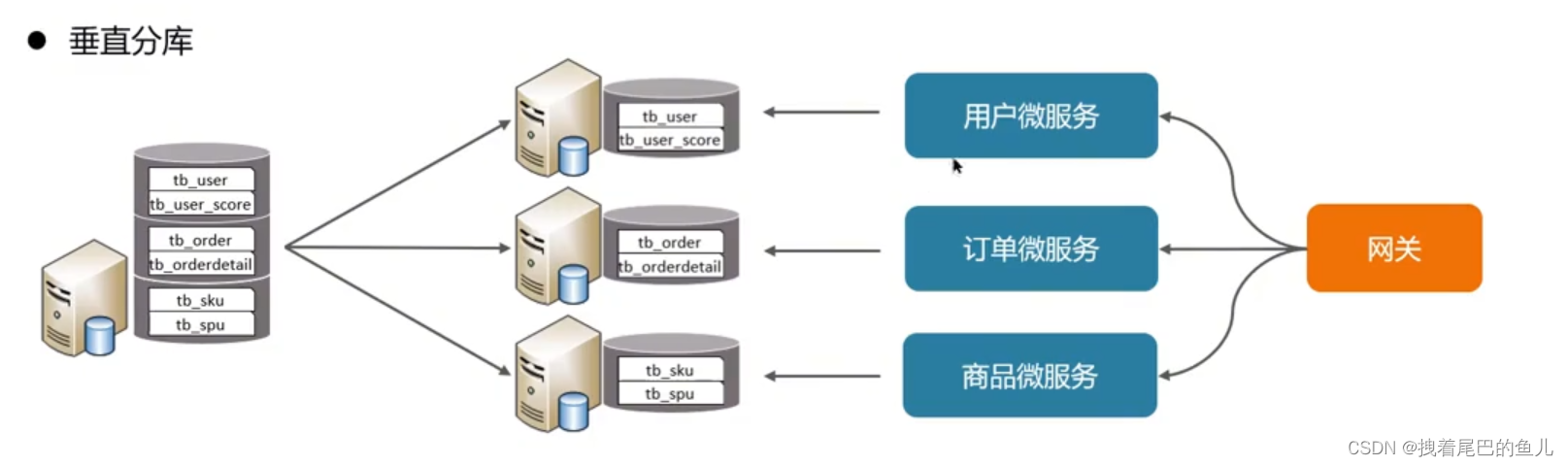
Por exemplo, os microsserviços atuais foram divididos verticalmente. Cada módulo de microsserviço pode ser conectado à sua própria instância de banco de dados Mysql. Sua característica é que ele é baseado em tabelas e divide diferentes tabelas em diferentes bibliotecas de acordo com o negócio. e expandir dados em diferentes níveis; aumentar conexões de disco I0 e volume de dados sob alta simultaneidade;
Com base nos campos, diferentes campos são divididos em diferentes tabelas de acordo com os atributos do campo.Isso pode ser feito: separar dados quentes e frios; reduzir a competição de transição de IO e as duas tabelas não afetarem uma à outra.
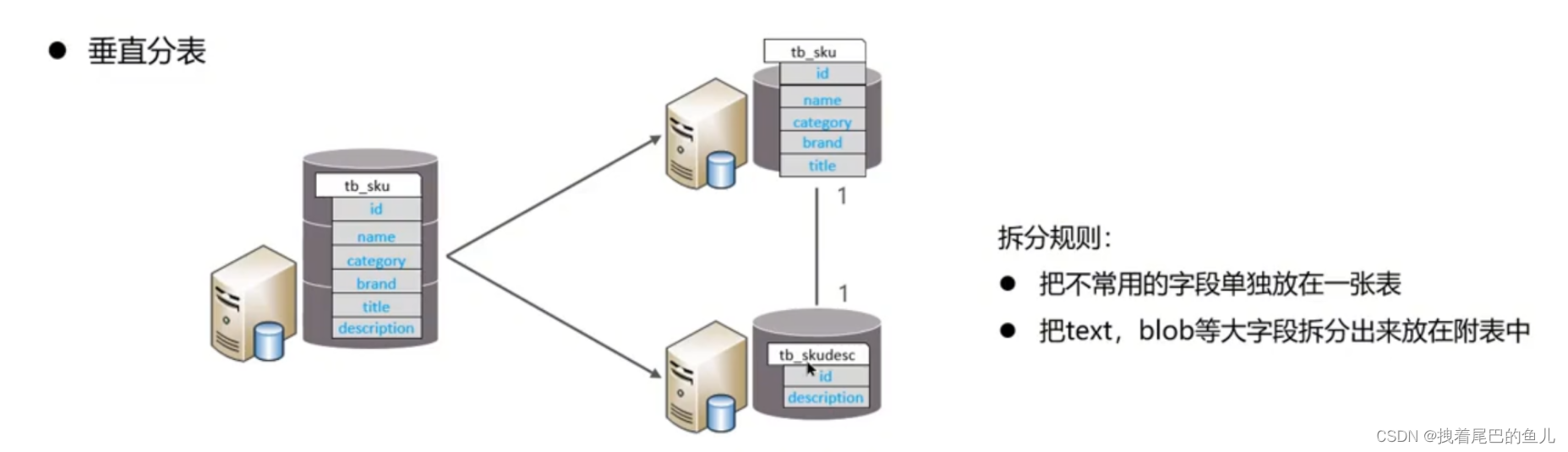
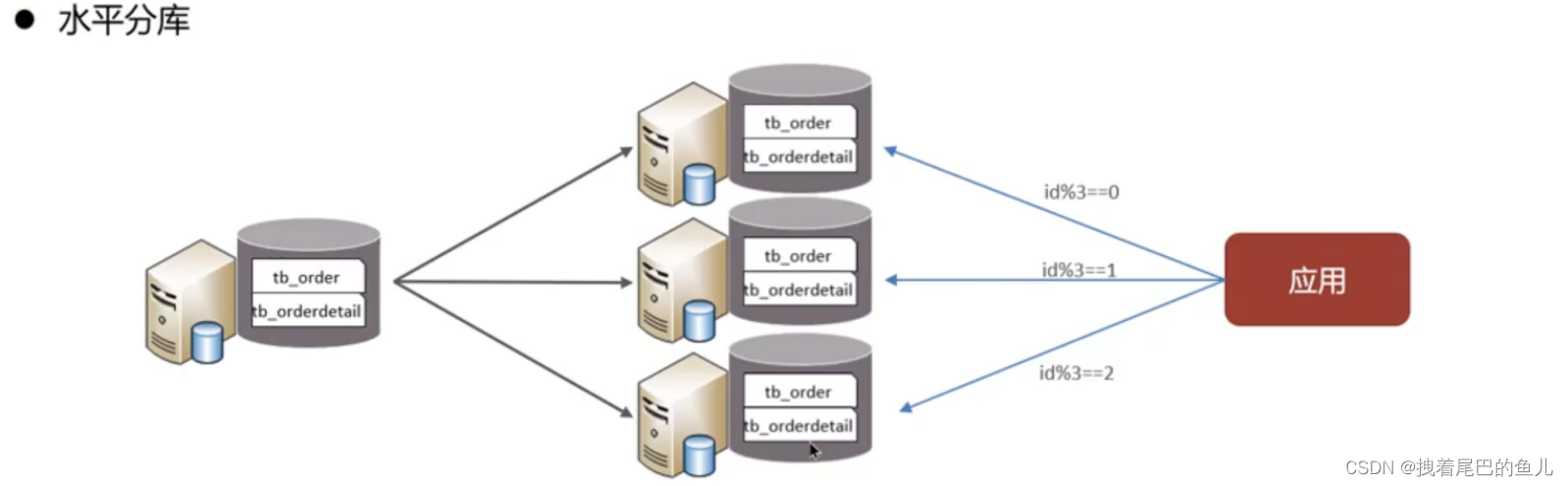
Divida os dados de uma biblioteca em várias bibliotecas. Ele resolve o problema de gargalo de desempenho de um grande número de bibliotecas únicas e alta simultaneidade e melhora a estabilidade e disponibilidade do sistema.
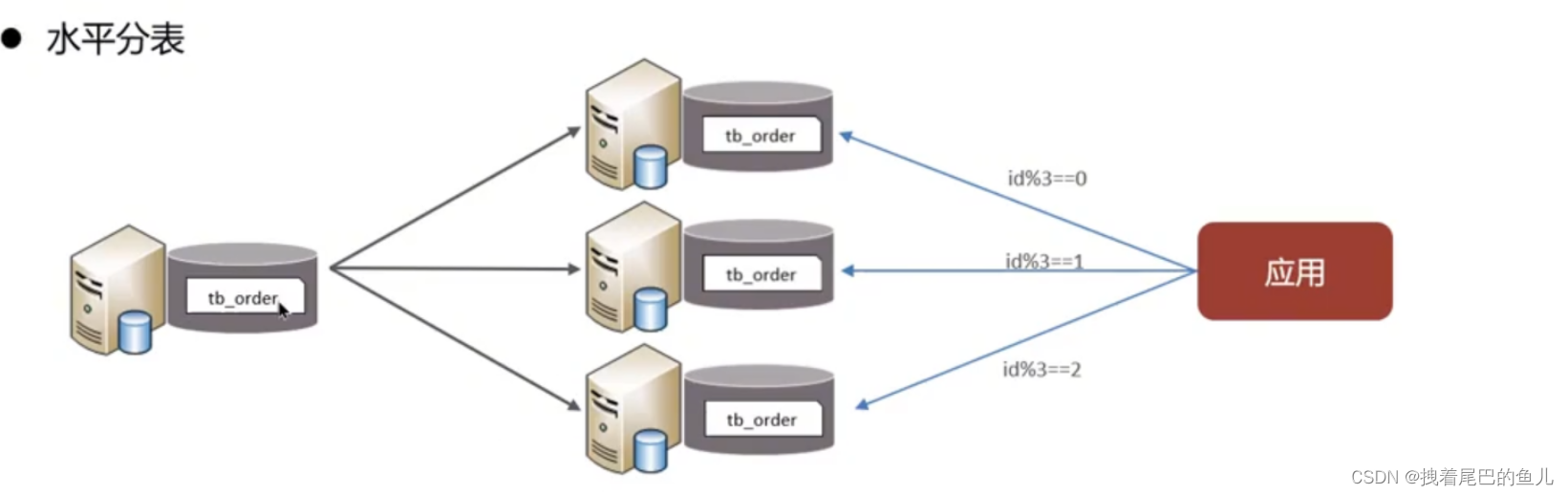
Divida os dados de uma tabela em várias tabelas (podem estar na mesma biblioteca). Otimizar problemas de desempenho causados por volume excessivo de dados em uma única tabela; evitar contenção de IO e reduzir a probabilidade de bloqueios de tabelas;
Estabelecemos instâncias de banco de dados de acordo com diferentes negócios em spring-boot gerenciados por spring-cloud e realizamos particionamento vertical. Para lidar com o armazenamento de dados massivos, nosso projeto também utiliza o middleware Mycat para dividir bancos de dados e tabelas.
Instalação do Mycat e integração do Spring-boot:
Depois que o banco de dados for dividido em tabelas, porque os dados serão armazenados em várias tabelas em vários bancos de dados, serão encontradas transações distribuídas, IDs globais distribuídos, configurações de regras de roteamento e problemas de paginação entre nós;
Este artigo responde a algumas perguntas da entrevista sobre clusters, subbancos de dados e tabelas Mysql.

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]