Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
¿Conoce los clústeres de MySQL? ¿Entiende el proceso de replicación maestro-esclavo? ¿Cómo maneja cantidades masivas de datos? Este artículo se centra en presentar las preguntas de la entrevista y deseo que todos los programadores puedan participar. ! !
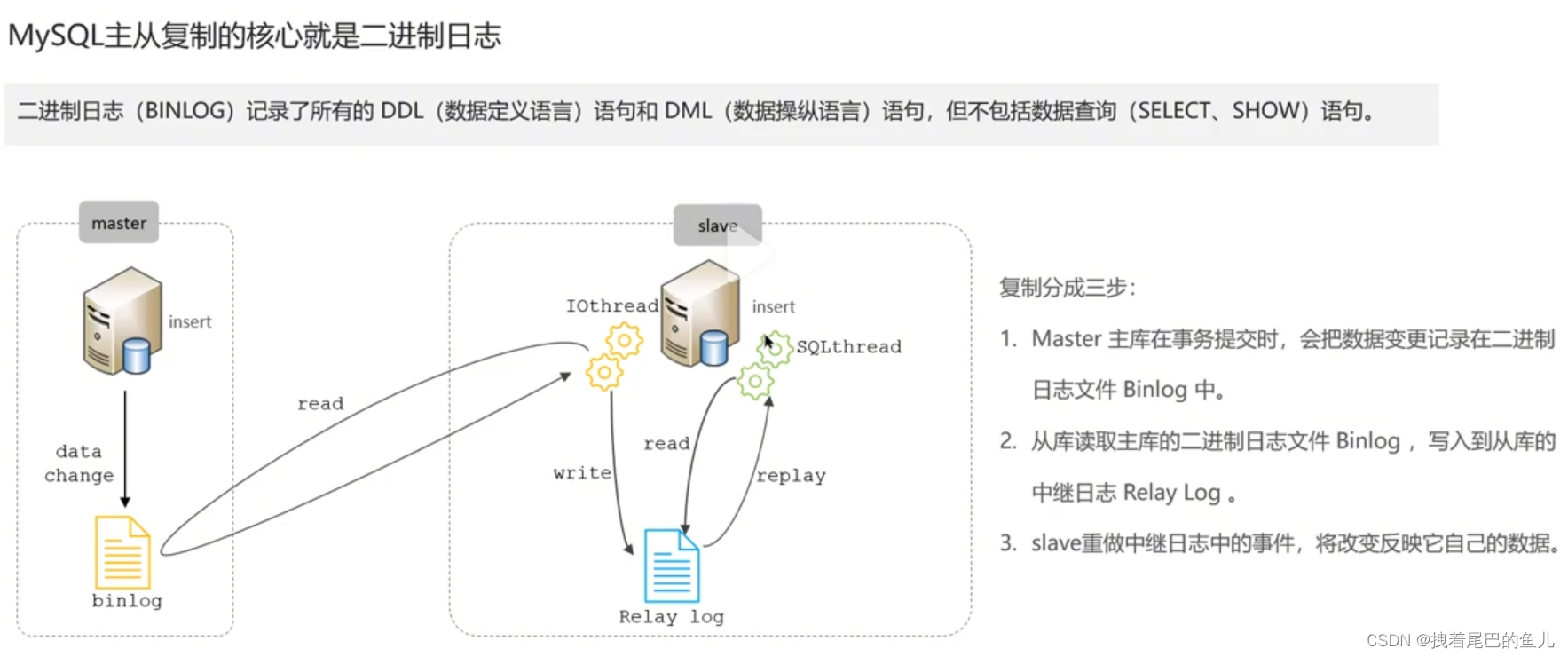
En el entorno en línea, generalmente implementamos una instancia de Mysql con 1 maestro y 1 esclavo, o 1 maestro con múltiples esclavos, para lograr la alta disponibilidad de Mysql y la sincronización maestro-esclavo de Mysql se realiza a través de registros binlog.
Con respecto a la construcción del clúster maestro-esclavo de Mysql, puede consultar el siguiente artículo del blogger
Como almacenamiento de datos relacionales, MySQL tendrá un cuello de botella en el rendimiento cuando el volumen de datos de una sola tabla supere los 30 millones. De manera similar, la conexión del cliente y la concurrencia admitida por una sola instancia de MySQL tendrán ciertos cuellos de botella. considere utilizar la tecnología de subbase de datos y subtabla para implementar.
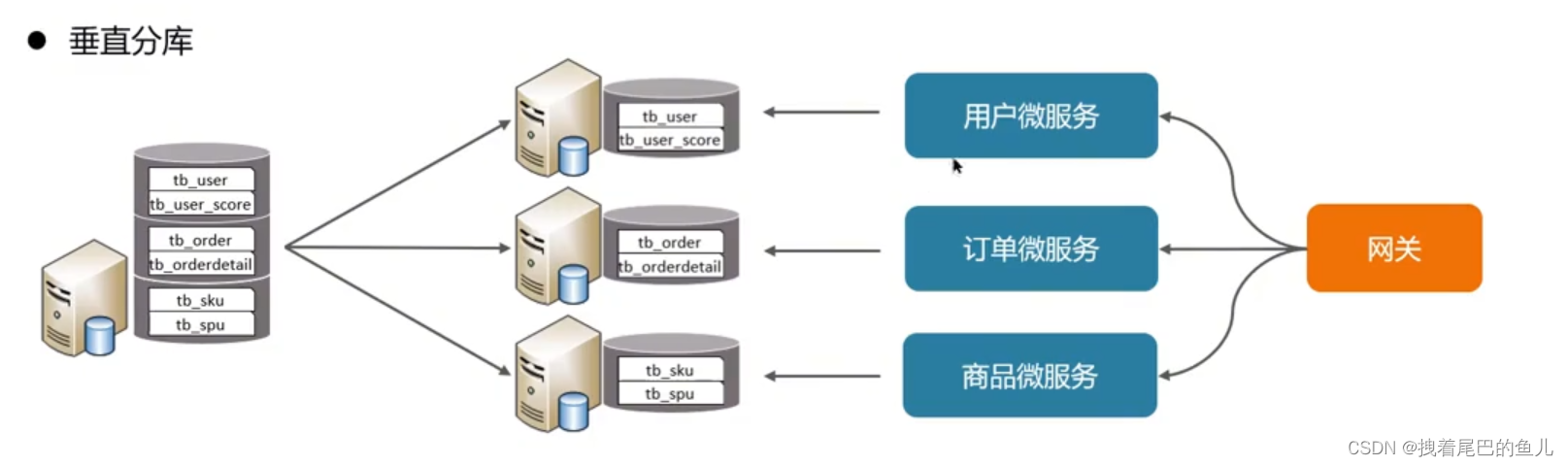
Por ejemplo, los microservicios actuales se han dividido verticalmente. Cada módulo de microservicio se puede conectar a su propia instancia de base de datos Mysql. Su característica es que se basa en tablas y divide diferentes tablas en diferentes bibliotecas según el negocio. y ampliar los datos en diferentes niveles; aumentar la I0 del disco y las conexiones del volumen de datos en condiciones de alta concurrencia;
Según los campos, los diferentes campos se dividen en diferentes tablas según los atributos del campo.Se puede hacer: separar los datos fríos y calientes; reducir la competencia de transición de IO y las dos tablas no se afectan entre sí.
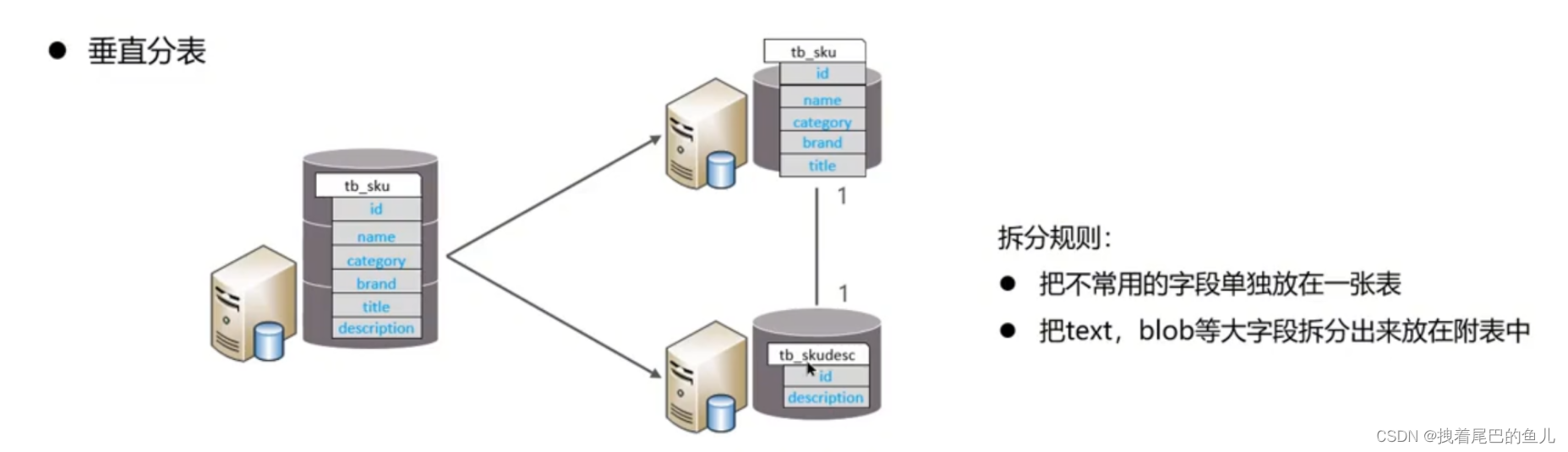
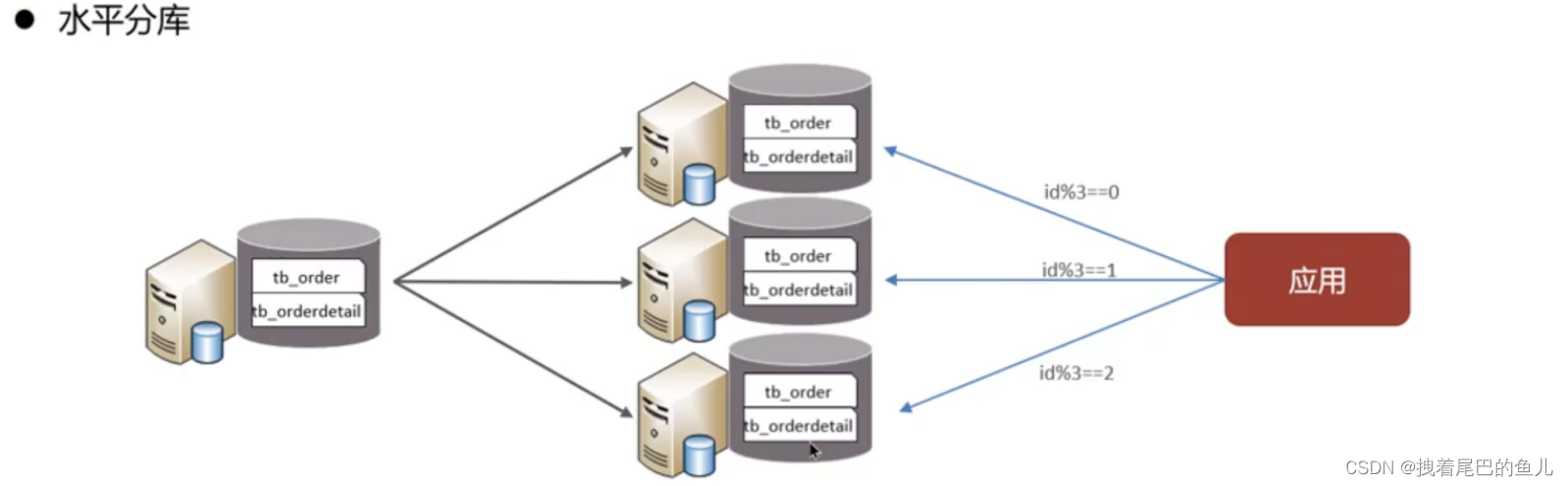
Divida los datos de una biblioteca en varias bibliotecas. Resuelve el problema del cuello de botella en el rendimiento causado por una gran cantidad de bibliotecas únicas y una alta concurrencia, y mejora la estabilidad y disponibilidad del sistema.
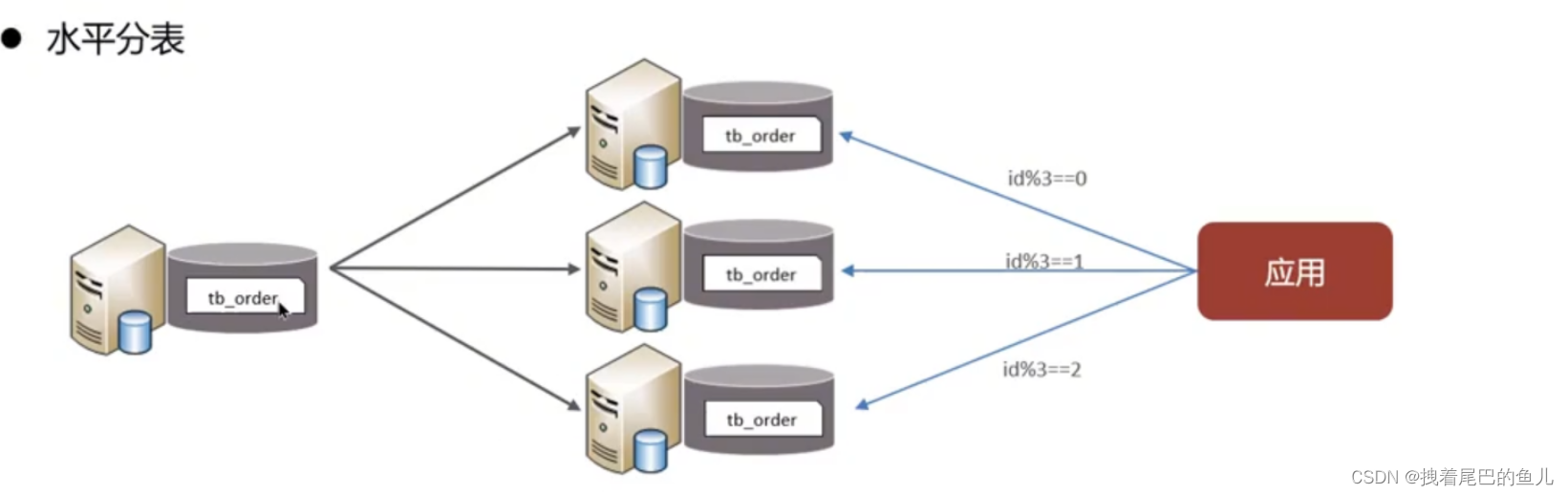
Divida los datos de una tabla en varias tablas (pueden estar en la misma biblioteca). Optimice los problemas de rendimiento causados por un volumen excesivo de datos en una sola tabla; evite la contención de IO y reduzca la probabilidad de bloqueos de tablas;
Hemos establecido instancias de bases de datos según diferentes negocios en spring-boot administrado por spring-cloud y realizamos particiones verticales. Para hacer frente al almacenamiento de datos masivos, nuestro proyecto también utiliza el middleware Mycat para dividir bases de datos y tablas.
Instalación de Mycat e integración Spring-boot:
Después de dividir la base de datos en tablas, debido a que los datos se almacenarán en varias tablas en varias bases de datos, se encontrarán transacciones distribuidas con ID globales distribuidas, configuraciones de reglas de enrutamiento y problemas de paginación entre nodos;
Este artículo clasifica algunas preguntas de la entrevista sobre clústeres, subbases de datos y tablas de Mysql.

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]