2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Connaissez-vous les clusters MySQL ? Comprenez-vous le processus de réplication maître-esclave ? Comment gérez-vous des quantités massives de données ? Cet article se concentre sur l'introduction des questions d'entretien, et j'aimerais que chaque programmeur puisse participer ! ! !
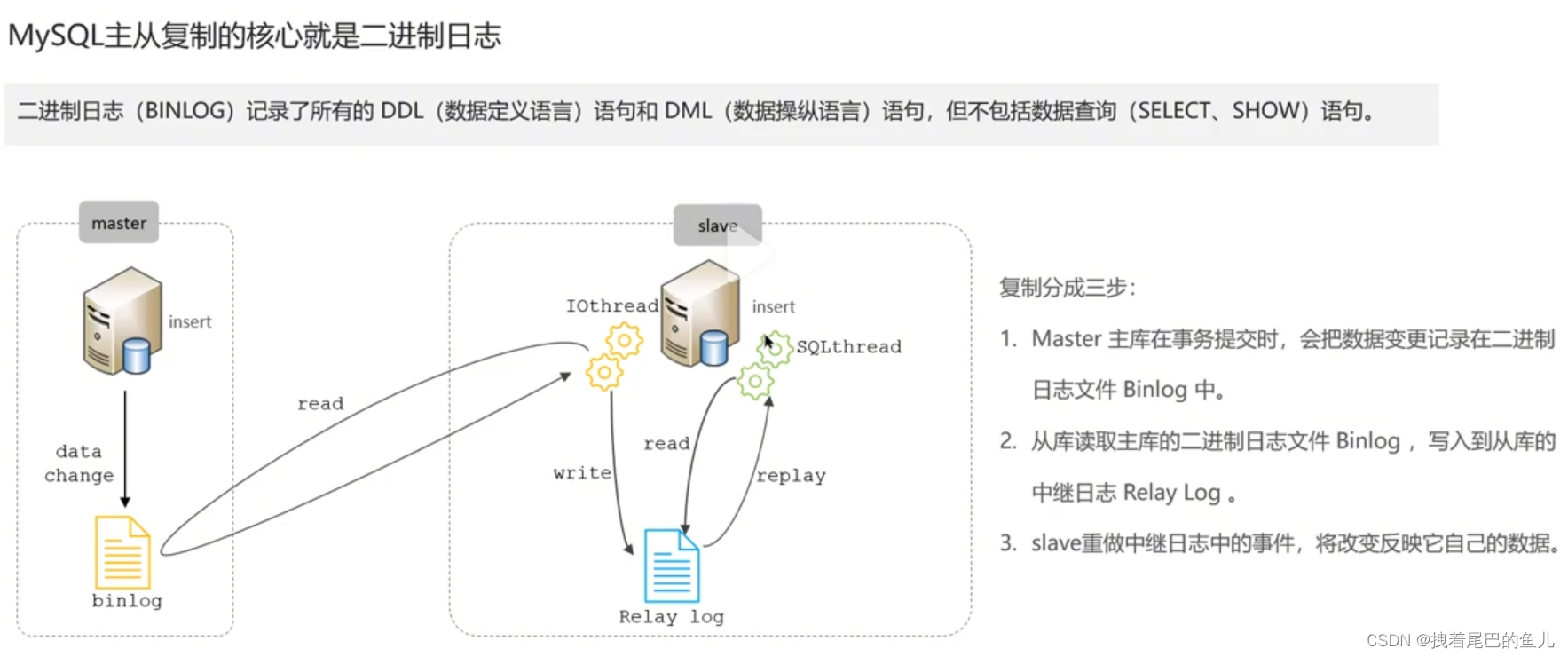
Dans l'environnement en ligne, nous déployons généralement une instance Mysql avec 1 maître et 1 esclave, ou 1 maître avec plusieurs esclaves, pour obtenir la haute disponibilité de Mysql et la séparation en lecture-écriture de Mysql est effectuée via les journaux binlog.
Concernant la construction du cluster maître-esclave Mysql, vous pouvez vous référer à l'article ci-dessous du blogueur
En tant que stockage de données relationnelles, MySQL aura un goulot d'étranglement en termes de performances lorsque le volume de données d'une seule table dépasse 30 millions. De même, la connexion client et la concurrence prises en charge par une seule instance MySQL présentent actuellement certains goulots d'étranglement. envisagez d'utiliser la technologie des sous-bases de données et des sous-tableaux pour la mise en œuvre.
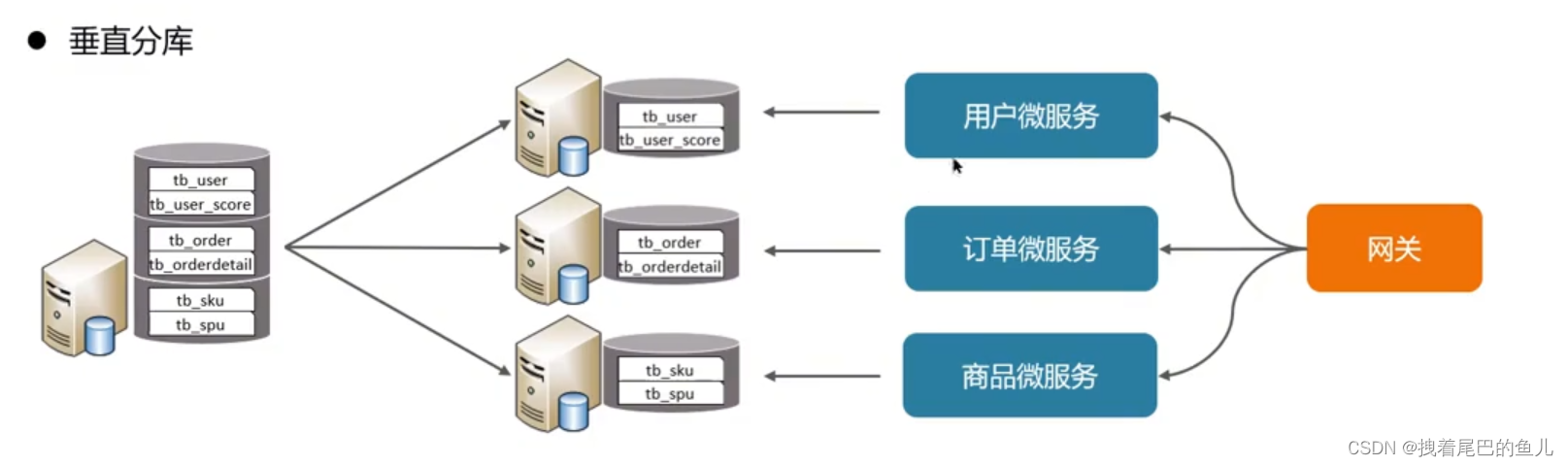
Par exemple, les microservices d'aujourd'hui ont été divisés verticalement. Chaque module de microservice peut être connecté à sa propre instance de base de données Mysql. Sa caractéristique est qu'il est basé sur des tables et divise différentes tables en différentes bibliothèques selon l'activité. et étendre les données à différents niveaux ; augmenter les connexions I0 du disque et le volume de données dans des conditions de concurrence élevée ;
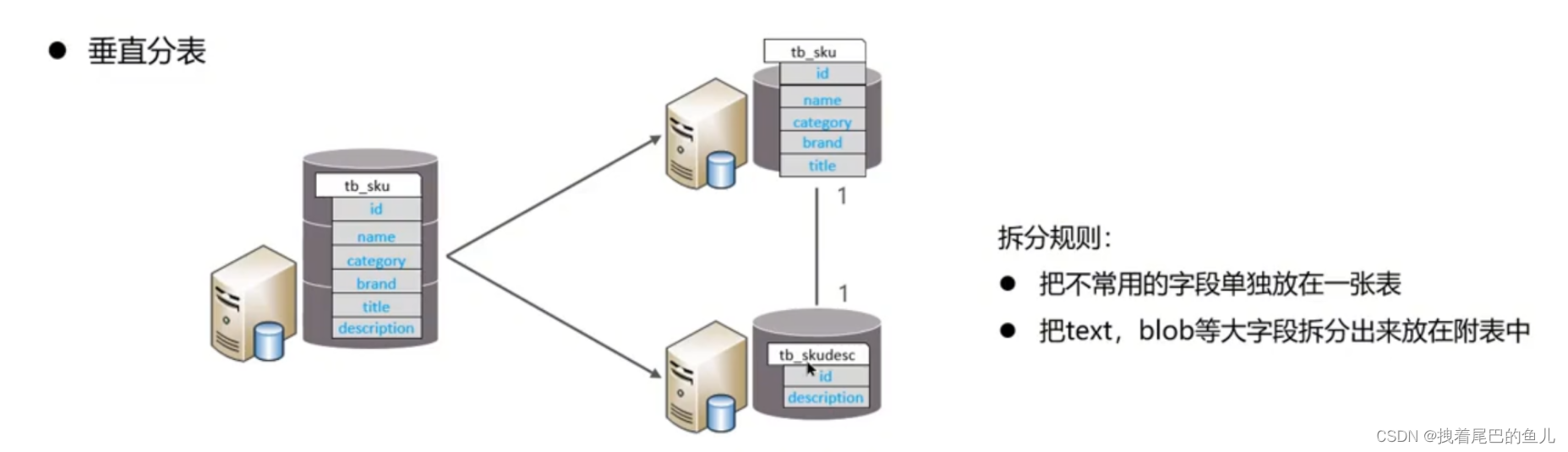
En fonction des champs, différents champs sont divisés en différentes tables en fonction des attributs de champ.Cela peut être fait : séparer les données chaudes et froides ; réduire la concurrence de transition IO, et les deux tables ne s'affectent pas.
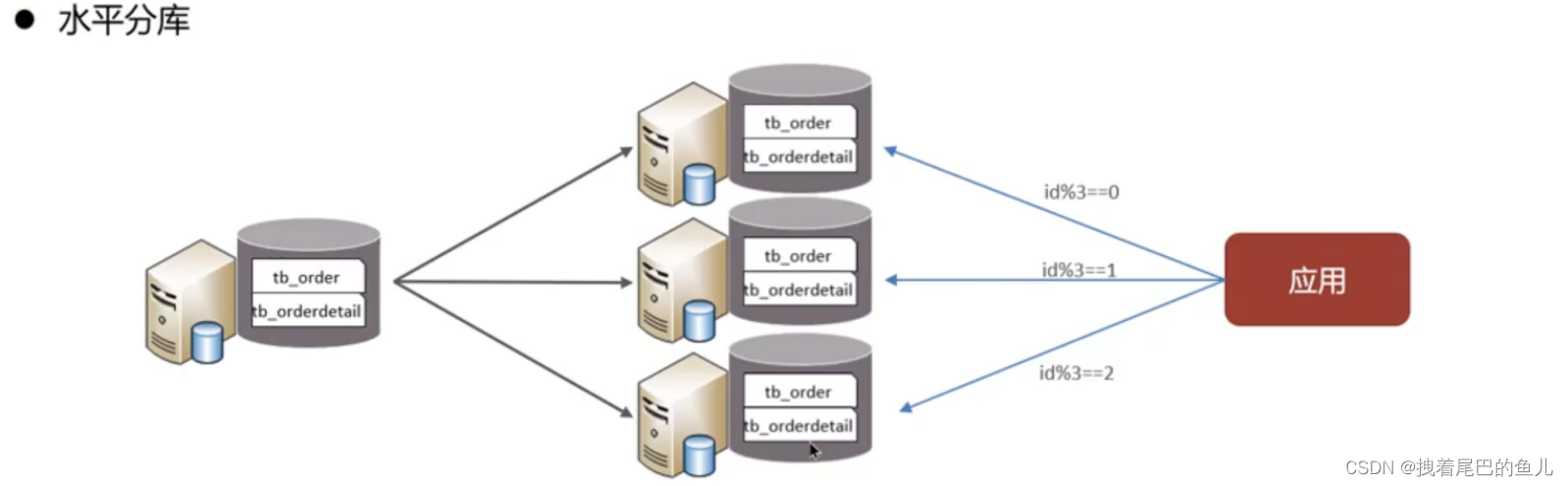
Divisez les données d'une bibliothèque en plusieurs bibliothèques. Il résout le problème des goulots d'étranglement des performances liés au grand nombre de bibliothèques uniques et à la concurrence élevée, et améliore la stabilité et la disponibilité du système.
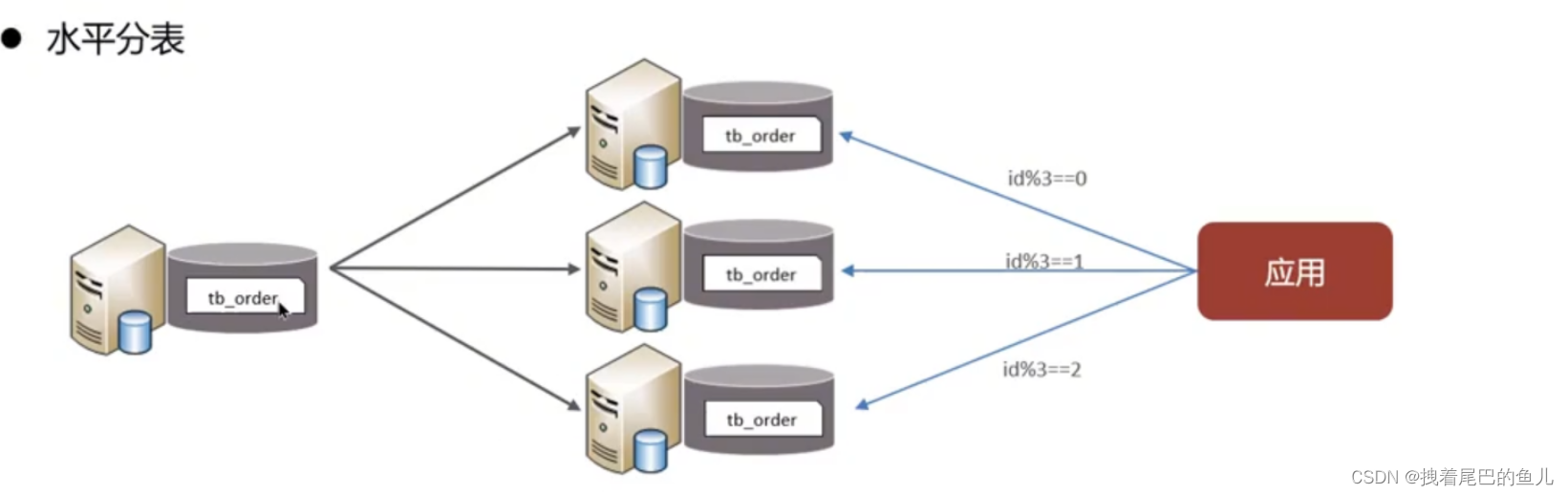
Divisez les données d'une table en plusieurs tables (peut être dans la même bibliothèque). Optimiser les problèmes de performances causés par un volume de données excessif dans une seule table ; éviter les conflits d'E/S et réduire la probabilité de verrouillage de table ;
Nous avons établi des instances de bases de données selon différentes activités dans spring-boot gérées par spring-cloud, et réalisé un partitionnement vertical. Afin de faire face au stockage de données massives, notre projet utilise également le middleware Mycat pour diviser les bases de données et les tables.
Installation de Mycat et intégration Spring-boot :
Une fois la base de données divisée en tables, étant donné que les données seront stockées dans plusieurs tables de plusieurs bases de données, des transactions distribuées seront rencontrées : des identifiants globaux distribués, des paramètres de règles de routage et des problèmes de pagination entre nœuds ;
Cet article répond à quelques questions d'entretien sur les clusters Mysql, les sous-bases de données et les tables.

Il se consacre à la recherche technologique depuis plus de trente ans, maîtrise divers langages tels que java, linux, javascript, php, css, etc., et a apporté de nombreuses contributions dans le domaine de l'open source. une station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.