2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Table des matières et liens vers des séries d'articles
Article précédent :Apprentissage automatique (5) -- Apprentissage supervisé (5) -- Régression linéaire 2
Article suivant :Apprentissage automatique (5) -- Apprentissage supervisé (7) --SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
Régression logistique = régression linéaire + fonction sigmoïde
La régression logistique (Logistic Regression) consiste simplement à trouver une ligne droite pour diviser une donnée binaire.
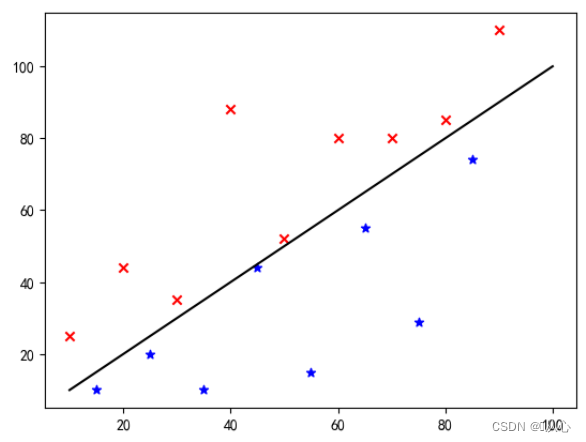
Résoudre le problème de classification binaire en classant les objets appartenant à une certaine catégorievaleur de probabilitéPour déterminer si elle appartient à une certaine catégorie, cette catégorie est marquée par défaut par 1 (exemple positif), et l'autre catégorie sera marquée par 0 (exemple négatif).
En fait, cela est similaire à l'étape de régression linéaire. La différence réside dans les méthodes utilisées pour « vérifier l'effet d'ajustement du modèle » et « ajuster l'angle de position du modèle ».
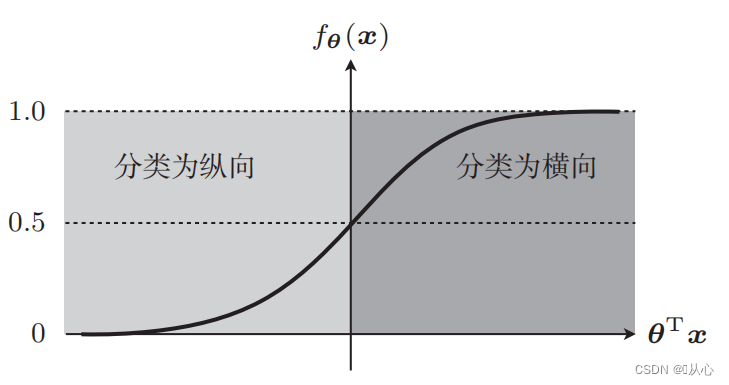
Vous devez utiliser une fonction (fonction sigmoïde) pour mapper les données d'entrée entre 0 et 1, et si la valeur de la fonction est supérieure à 0,5, elle est jugée égale à 1, sinon elle est égale à 0. Cela peut être converti en une représentation probabiliste.
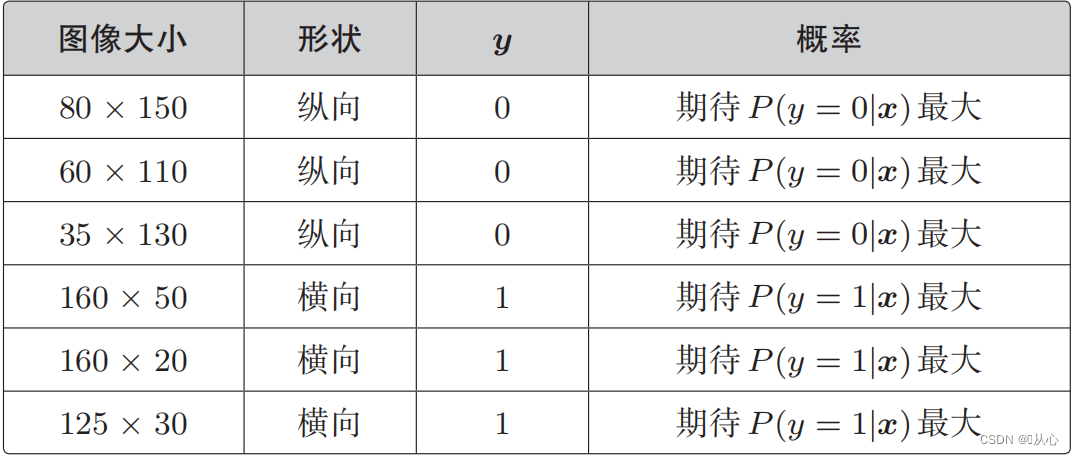
Prenons l'exemple de la classification des images, divisez les images en verticales et horizontales
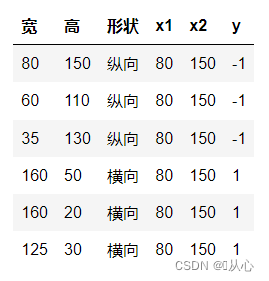
C'est ainsi que ces données sont affichées sur le graphique. Afin de séparer les points de différentes couleurs (différentes catégories) dans le graphique, nous traçons une telle ligne. Le but de cette classification est de trouver une telle ligne.
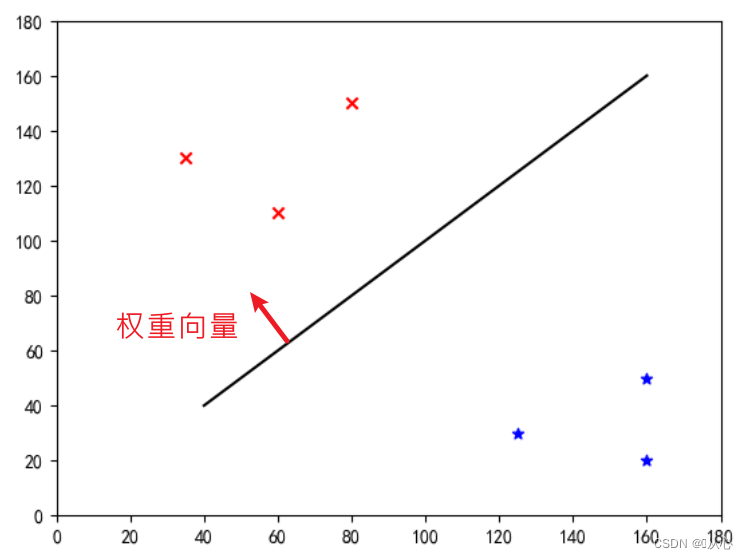
Il s'agit d'une "ligne droite qui fait du vecteur de poids un vecteur normal" (que le vecteur de poids soit perpendiculaire à la ligne)
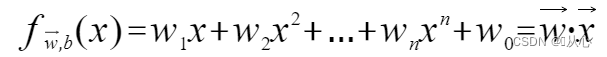
w est le vecteur poids ; ce qui en fait une droite du vecteur normal, même
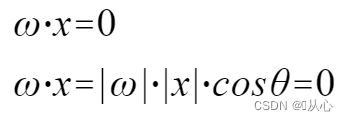
Un modèle qui accepte plusieurs valeurs, multiplie chaque valeur par son poids respectif et génère finalement la somme.
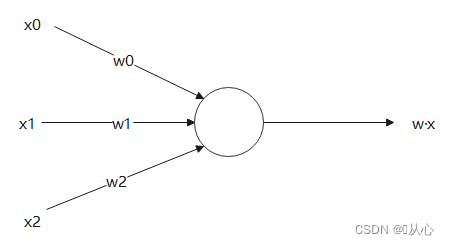
Le produit scalaire est une mesure du degré de similarité entre les vecteurs. Un résultat positif indique une similarité, une valeur de 0 indique une verticalité et un résultat négatif indique une dissimilarité.
utiliser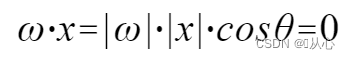 C'est plus facile à comprendre, car |w| et |x| sont tous deux des nombres positifs, donc le signe du produit scalaire est déterminé par cosθ, c'est-à-dire que s'il est inférieur à 90 degrés, il est similaire, et s'il est supérieur à 90 degrés, il est différent, c'est-à-dire
C'est plus facile à comprendre, car |w| et |x| sont tous deux des nombres positifs, donc le signe du produit scalaire est déterminé par cosθ, c'est-à-dire que s'il est inférieur à 90 degrés, il est similaire, et s'il est supérieur à 90 degrés, il est différent, c'est-à-dire
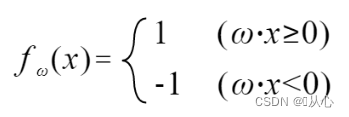
S'il est égal à la valeur de l'étiquette d'origine, le vecteur de poids ne sera pas mis à jour. S'il n'est pas égal à la valeur de l'étiquette d'origine, l'ajout de vecteurs sera utilisé pour mettre à jour le vecteur de poids.
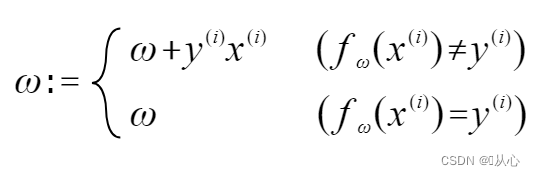
Comme le montre la figure, si elle n'est pas égale à l'étiquette d'origine, alors
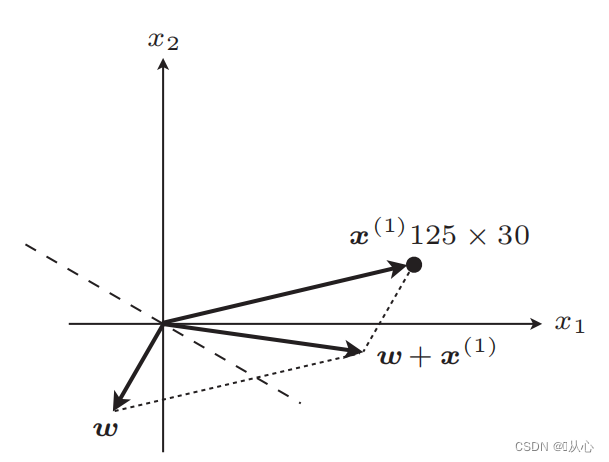
ligne droite après mise à jour
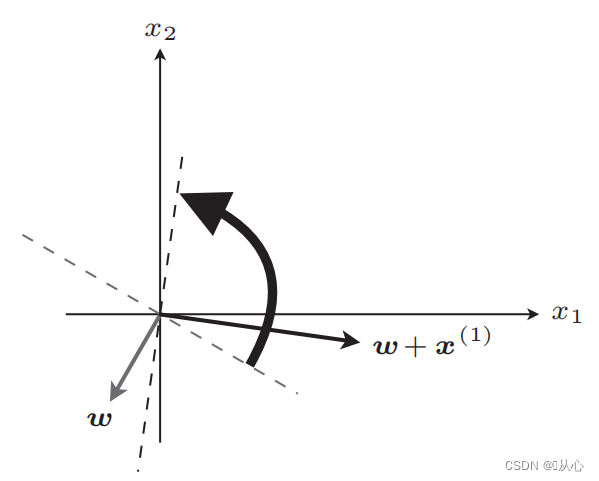
Après mise à jour, égal
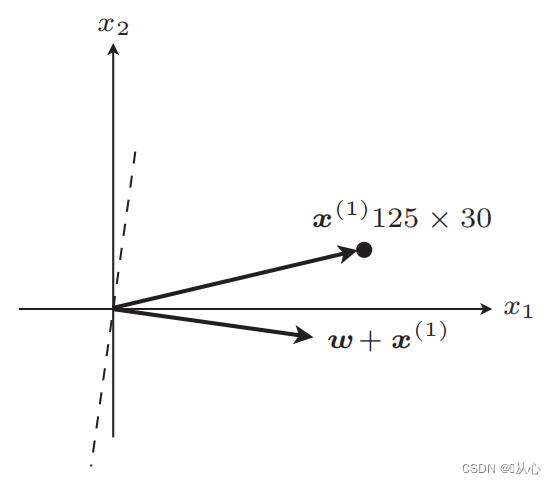
Étapes : Déterminez d'abord au hasard une ligne droite (c'est-à-dire déterminez au hasard un vecteur de poids w), remplacez une valeur réelle x dans le produit interne et obtenez une valeur (1 ou -1) via la fonction discriminante si elle est égale. à la valeur de l'étiquette d'origine, le vecteur de poids n'est pas mis à jour, s'il est différent de la valeur de l'étiquette d'origine, utilisez l'ajout de vecteur pour mettre à jour le vecteur de poids.
! ! !Remarque : le perceptron ne peut résoudre que des problèmes linéairement séparables
Linéairement séparable : cas où des lignes droites peuvent être utilisées pour la classification
Inséparabilité linéaire : ne peut être classée par des lignes droites
Le noir est la fonction sigmoïde, le rouge est la fonction échelon (discontinue)
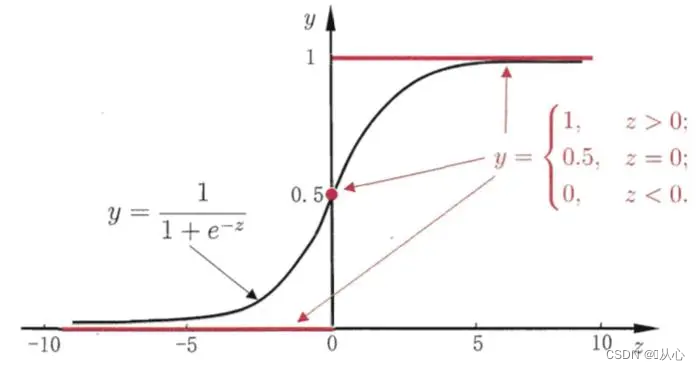
Fonction : L'entrée de la régression logistique est le résultat de la régression linéaire.Nous pouvons obtenir une valeur prédite en régression linéaire. La fonction sigmoïde mappe n'importe quelle entrée sur l'intervalle [0,1], complétant ainsi la conversion de la valeur en probabilité, qui est une tâche de classification.
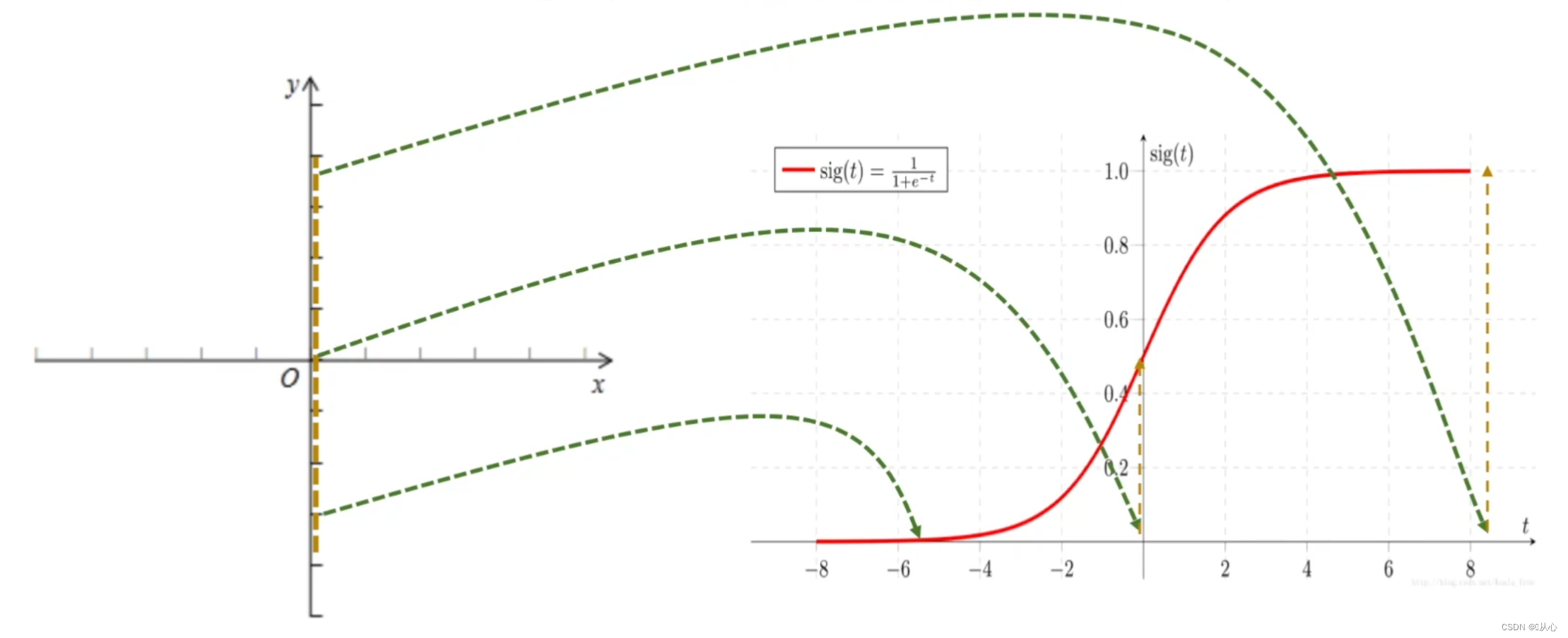
Régression logistique = régression linéaire + fonction sigmoïde
Régression linéaire: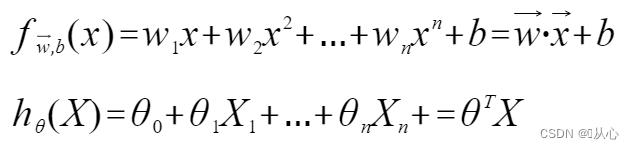
fonction sigmoïde :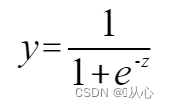
Régression logistique: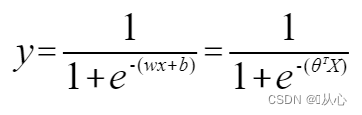
Pour que y représente l'étiquette, remplacez-la par :
Pour faire des probabilités, utilisez :
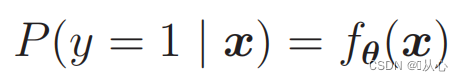
Autrement dit, les catégories peuvent être distinguées par probabilité
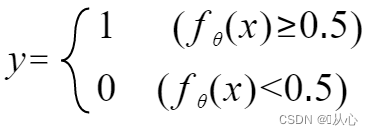
Il peut être réécrit comme suit :
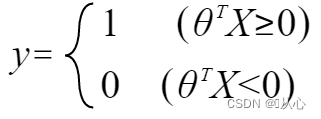
quand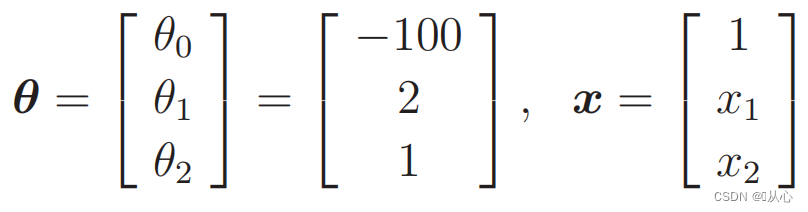
Données de remplacement :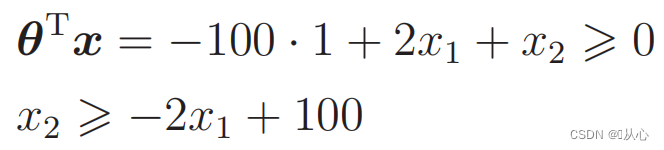
Il y a une telle image
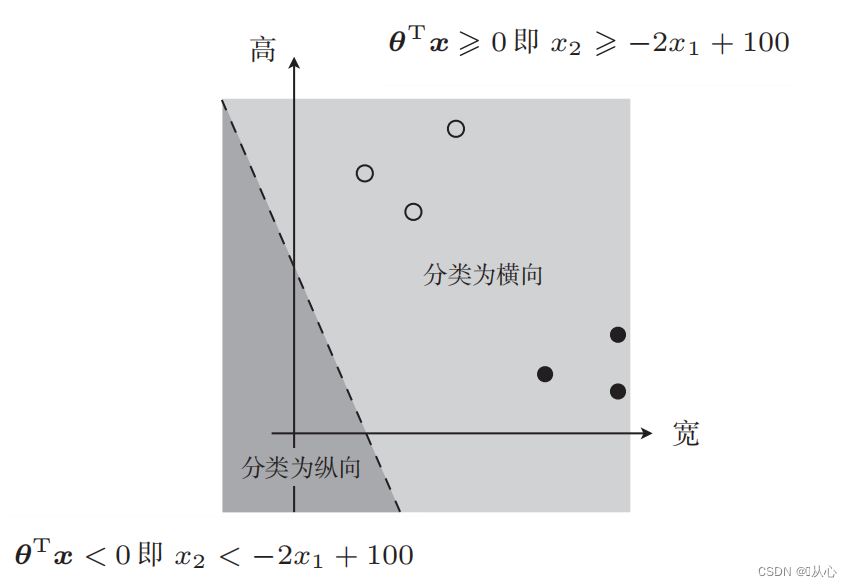 La ligne droite utilisée pour la classification des données est la limite de décision
La ligne droite utilisée pour la classification des données est la limite de décision
Ce que nous voulons, c'est ceci :
Lorsque y=1, P(y=1|x) est le plus grand
Lorsque y=0, P(y=0|x) est le plus grand
Fonction de vraisemblance (probabilité conjointe) : voici la probabilité que l'on souhaite maximiser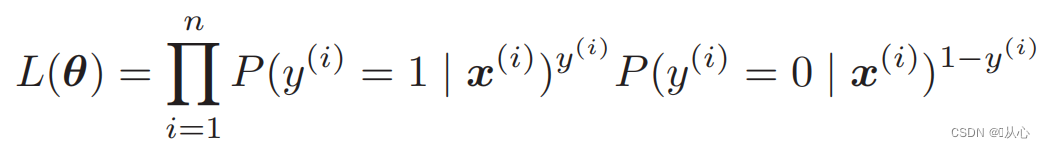
Fonction log-vraisemblance : Il est difficile de différencier directement la fonction de vraisemblance. Vous devez d'abord prendre le logarithme.
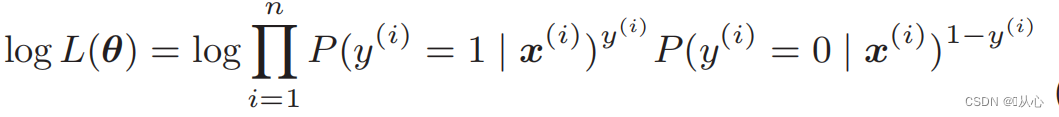
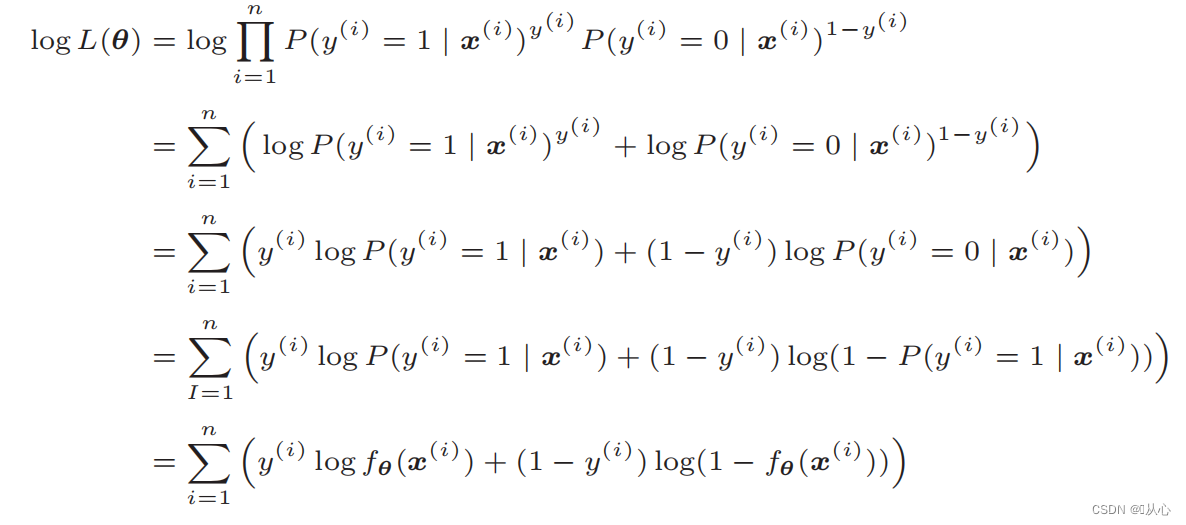
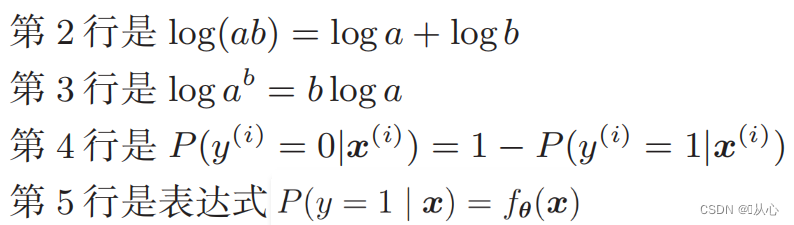
Après déformation, il devient :
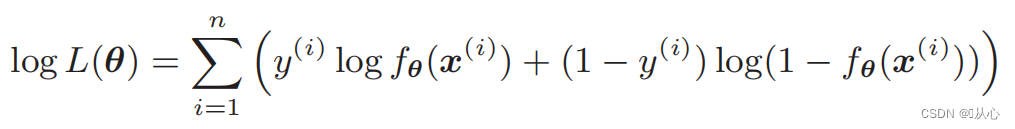
Différenciation de la fonction de vraisemblance :
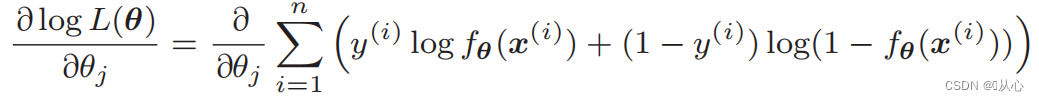
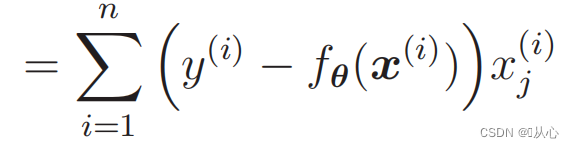
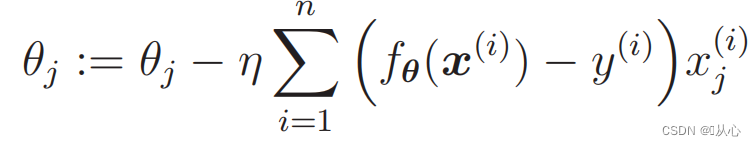
1. Simple à mettre en œuvre : La régression logistique est un algorithme simple, facile à comprendre et à mettre en œuvre.
2. Efficacité de calcul élevée : la régression logistique nécessite une quantité relativement faible de calculs et convient aux ensembles de données à grande échelle.
3. Forte interprétabilité : les résultats de sortie de la régression logistique sont des valeurs de probabilité, qui peuvent expliquer intuitivement la sortie du modèle.
1. Exigences de séparabilité linéaire : la régression logistique est un modèle linéaire et fonctionne mal pour les problèmes séparables non linéaires.
2. Problème de corrélation des caractéristiques : la régression logistique est plus sensible à la corrélation entre les caractéristiques d'entrée. Lorsqu'il existe une forte corrélation entre les caractéristiques, cela peut entraîner une baisse des performances du modèle.
3. Problème de surajustement : lorsqu'il y a trop de caractéristiques d'échantillon ou que le nombre d'échantillons est petit, la régression logistique est sujette à des problèmes de surajustement.
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
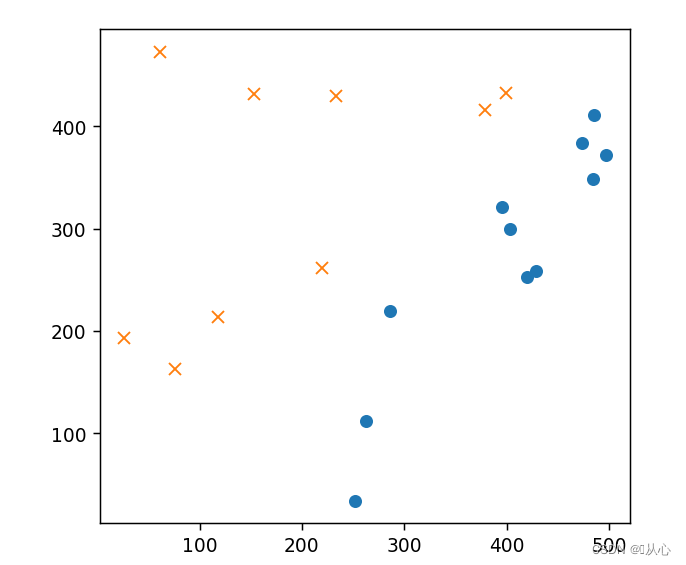
- # 初始化参数
- theta=np.random.randn(3)
-
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
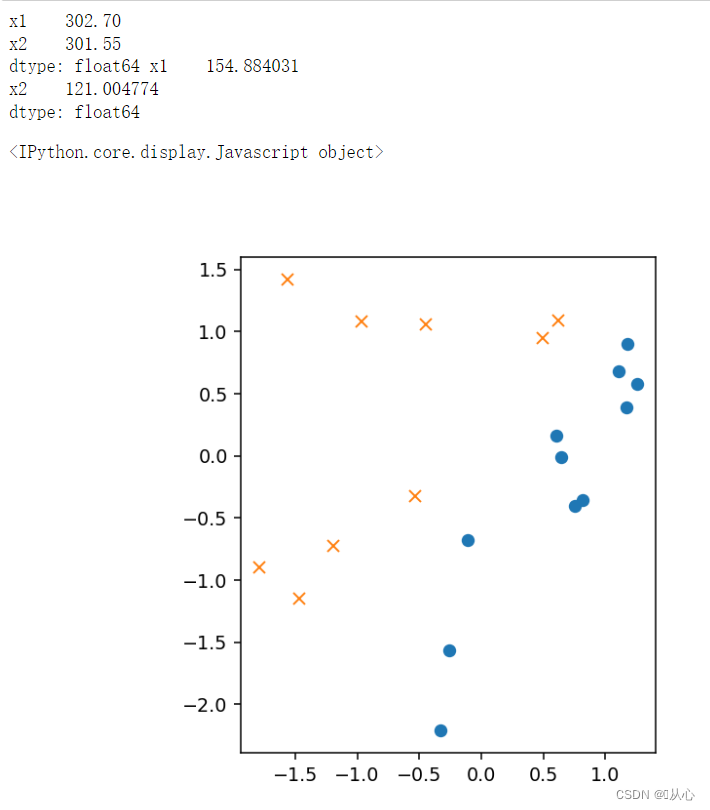
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
- # 绘图确认
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
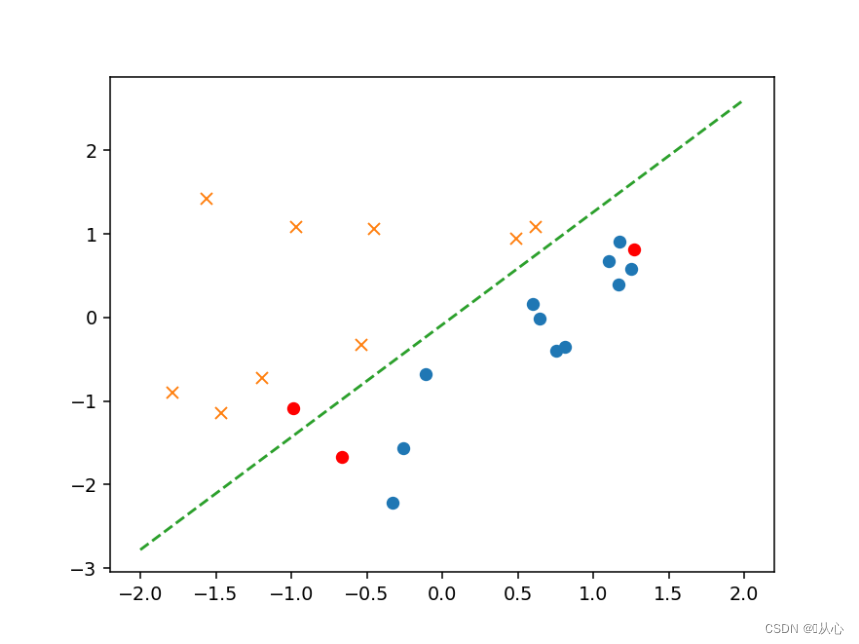
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
- # 键
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
- # 每个特征信息
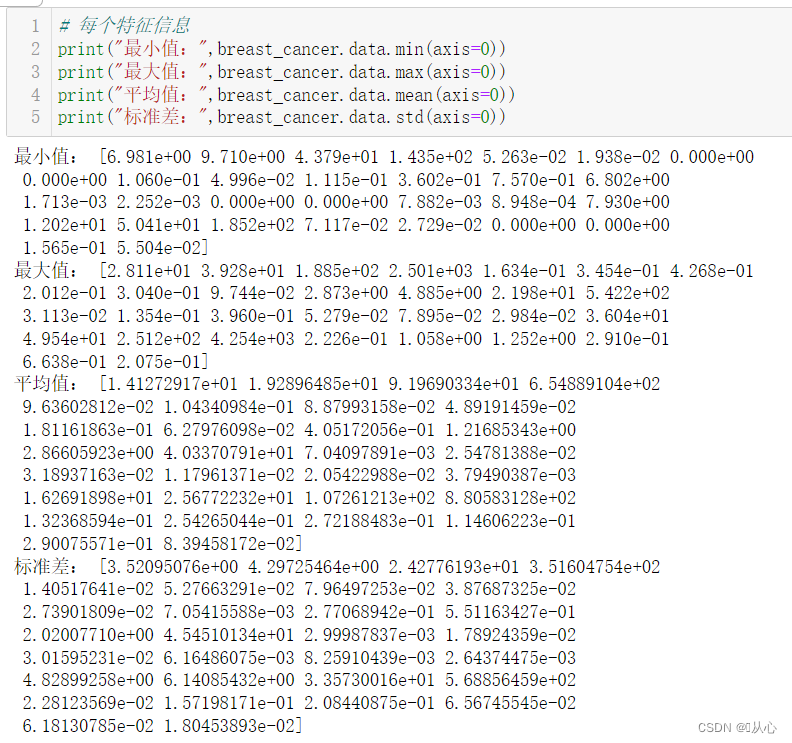
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
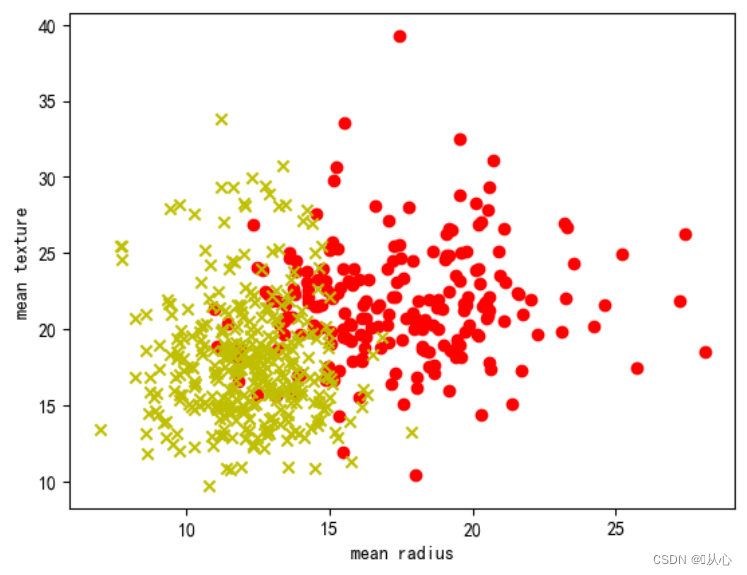
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
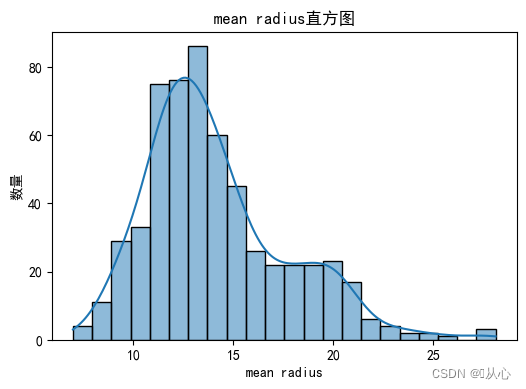
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
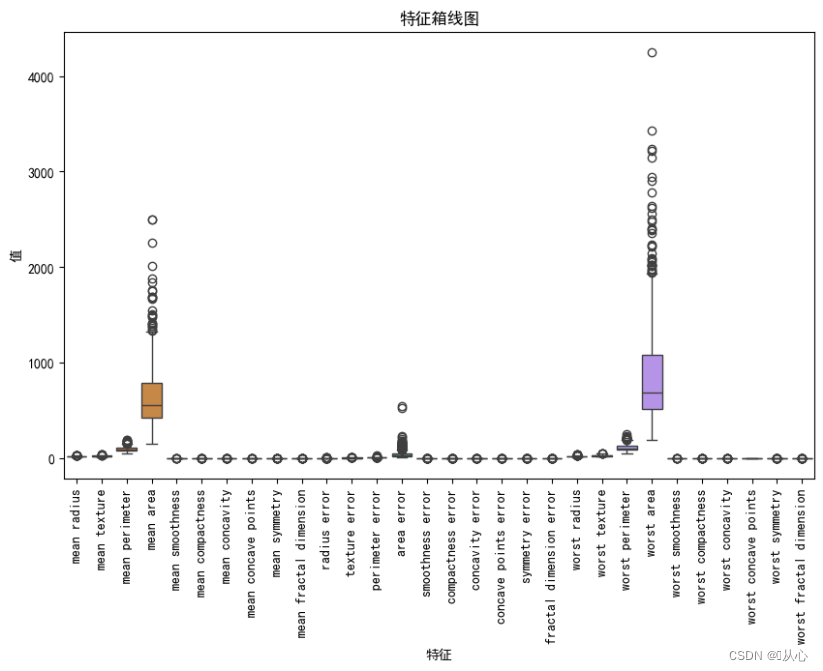
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
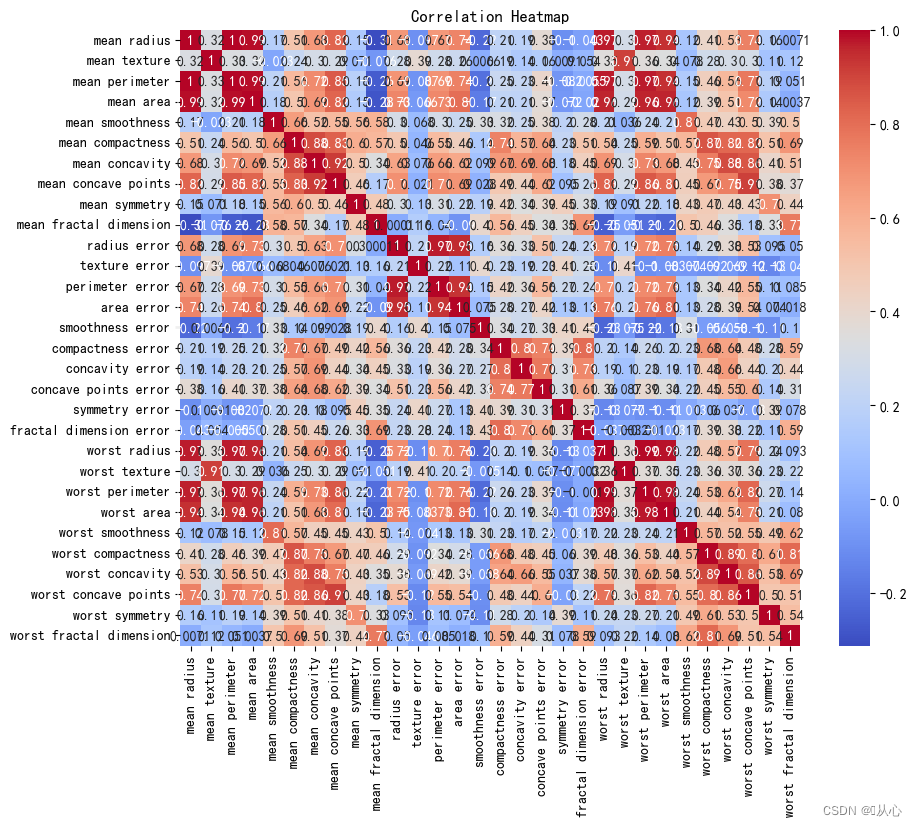
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 2. API
2. API- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
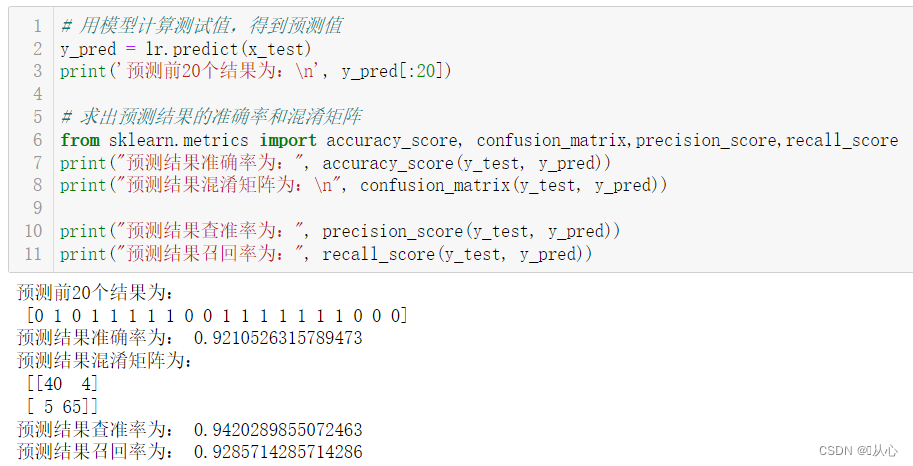
- print("建立的逻辑回归模型为:n", lr)

- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
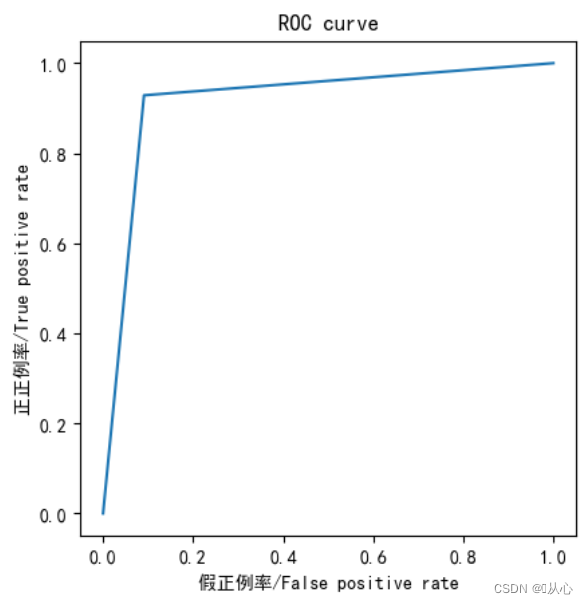
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

Le modèle qui passe après l'évaluation du modèle peut être remplacé par la valeur réelle à des fins de prédiction.
Les vieux rêves peuvent être revécus, voyons voir :Apprentissage automatique (5) -- Apprentissage supervisé (5) -- Régression linéaire 2
Si vous voulez savoir ce qui se passe ensuite, jetons un coup d’œil :Apprentissage automatique (5) -- Apprentissage supervisé (7) --SVM1

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
