Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Índice de contenidos y enlaces a series de artículos.
Artículo anterior:Aprendizaje automático (5) - Aprendizaje supervisado (5) - Regresión lineal 2
Artículo siguiente:Aprendizaje automático (5) - Aprendizaje supervisado (7) -SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
Regresión logística = regresión lineal + función sigmoidea
La regresión logística (Regresión logística) consiste simplemente en encontrar una línea recta para dividir datos binarios.
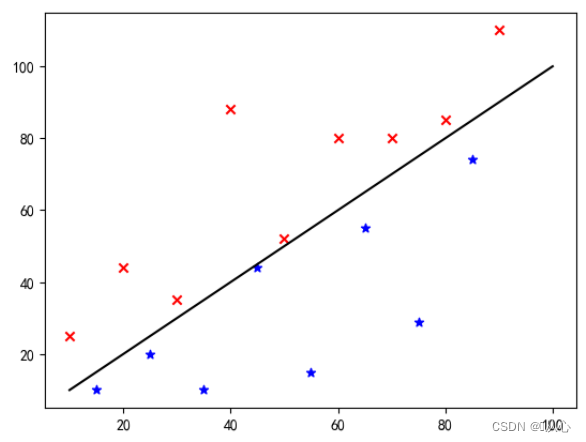
Resuelva el problema de clasificación binaria clasificando los objetos que pertenecen a una determinada categoría.valor de probabilidadPara determinar si pertenece a una determinada categoría, esta categoría se marca como 1 (ejemplo positivo) de forma predeterminada y la otra categoría se marcará como 0 (ejemplo negativo).
De hecho, esto es similar al paso de regresión lineal. La diferencia radica en los métodos utilizados para "verificar el efecto de ajuste del modelo" y "ajustar el ángulo de posición del modelo".
Debe usar una función (función sigmoidea) para asignar los datos de entrada entre 0 y 1, y si el valor de la función es mayor que 0,5, se considera 1; de lo contrario, es 0. Esto se puede convertir en una representación probabilística.
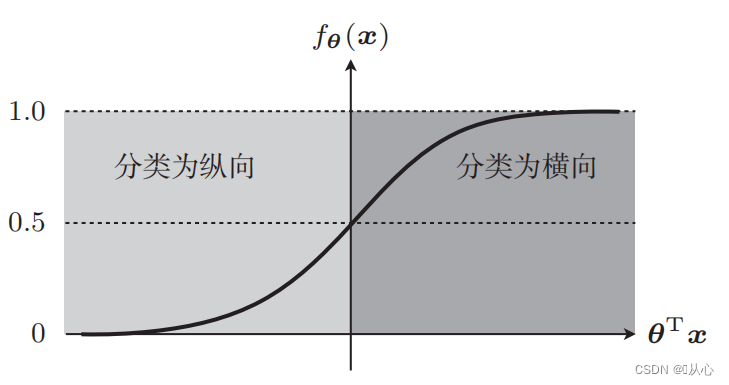
Tome la clasificación de imágenes como ejemplo, divida las imágenes en vertical y horizontal.
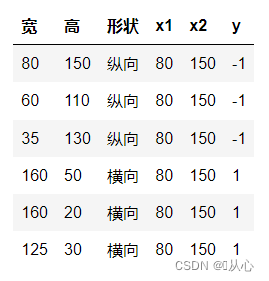
Así es como se muestran estos datos en el gráfico. Para separar los puntos de diferentes colores (diferentes categorías) en el gráfico, trazamos dicha línea. El propósito de esta clasificación es encontrar dicha línea.
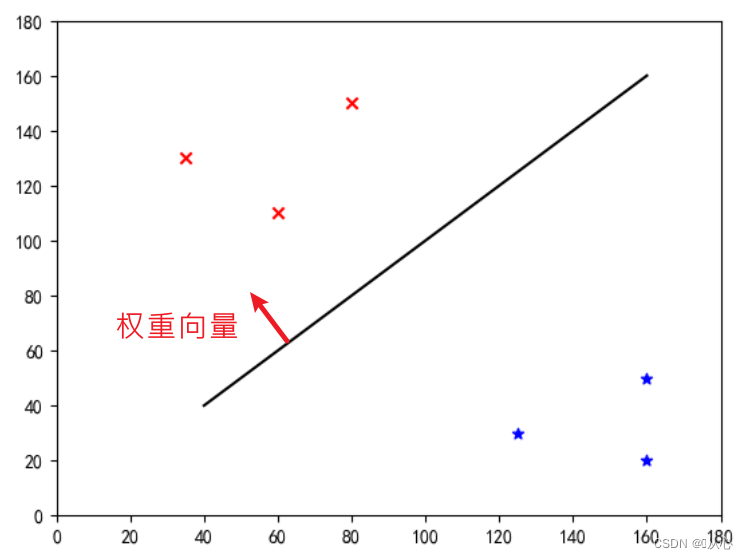
Esta es una "línea recta que hace que el vector de peso sea un vector normal" (deje que el vector de peso sea perpendicular a la línea)
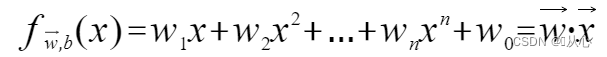
w es el vector de peso; por lo que es una línea recta del vector normal, par;
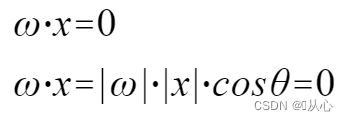
Un modelo que acepta múltiples valores, multiplica cada valor por su peso respectivo y finalmente genera la suma.
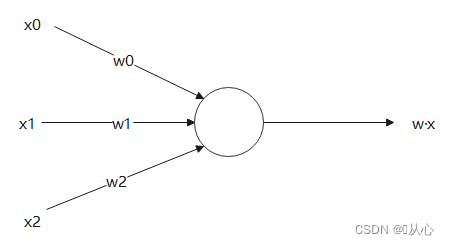
El producto interno es una medida del grado de similitud entre vectores. Un resultado positivo indica similitud, un valor de 0 indica verticalidad y un resultado negativo indica disimilitud.
usar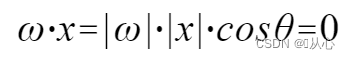 Es mejor entenderlo, porque |w| y |x| son ambos números positivos, por lo que el signo del producto interno es cosθ, es decir, si es menor que 90 grados, es similar y si es mayor que 90 grados, es diferente, es decir
Es mejor entenderlo, porque |w| y |x| son ambos números positivos, por lo que el signo del producto interno es cosθ, es decir, si es menor que 90 grados, es similar y si es mayor que 90 grados, es diferente, es decir
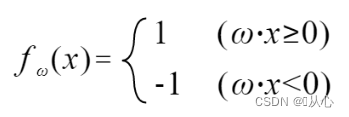
Si es igual al valor de la etiqueta original, el vector de peso no se actualizará. Si no es igual al valor de la etiqueta original, se utilizará la suma de vectores para actualizar el vector de peso.
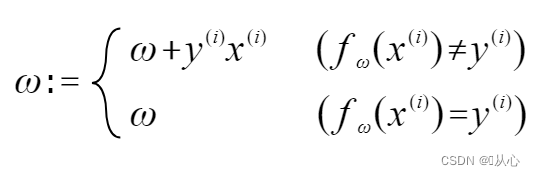
Como se muestra en la figura, si no es igual a la etiqueta original, entonces
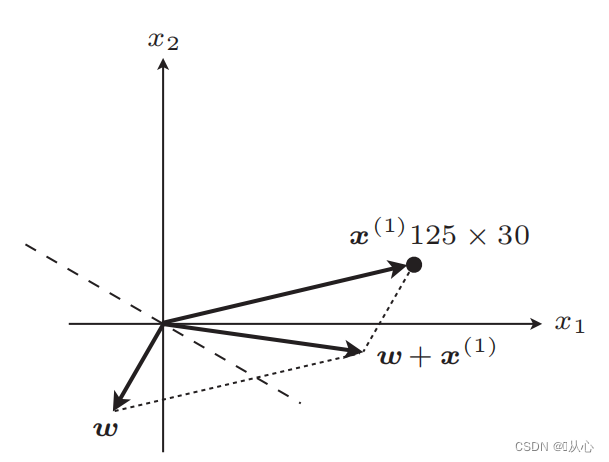
línea recta después de la actualización
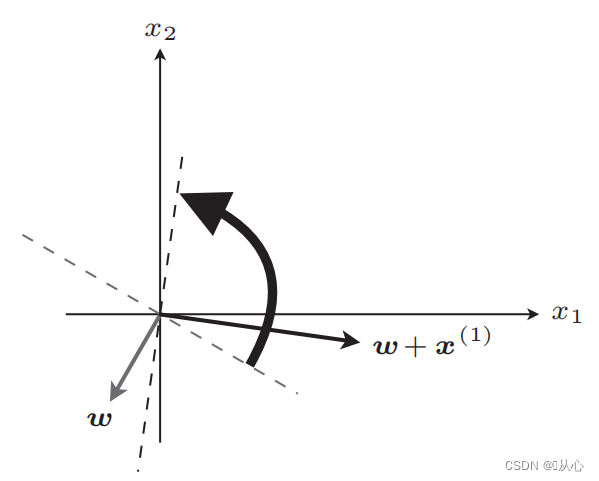
Después de la actualización, igual
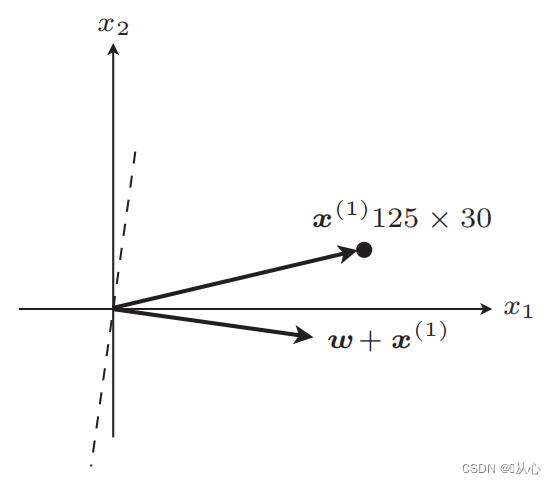
Pasos: Primero determine aleatoriamente una línea recta (es decir, determine aleatoriamente un vector de peso w), sustituya un dato de valor real x en el producto interno y obtenga un valor (1 o -1) a través de la función discriminante. al valor de la etiqueta original, el vector de peso no se actualiza; si es diferente del valor de la etiqueta original, utilice la suma de vectores para actualizar el vector de peso.
! ! !Nota: El perceptrón sólo puede resolver problemas linealmente separables.
Linealmente separable: casos en los que se pueden utilizar líneas rectas para la clasificación
Inseparabilidad lineal: no se puede clasificar por líneas rectas
El negro es la función sigmoidea, el rojo es la función escalonada (discontinua)
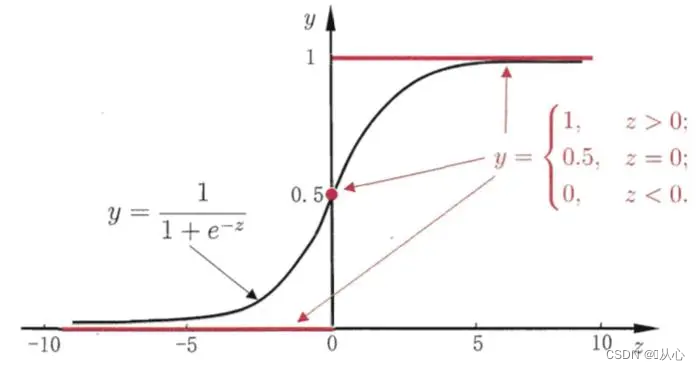
Función: La entrada de la regresión logística es el resultado de la regresión lineal.Podemos obtener un valor predicho en regresión lineal. La función sigmoidea asigna cualquier entrada al intervalo [0,1], completando así la conversión de valor a probabilidad, que es una tarea de clasificación.
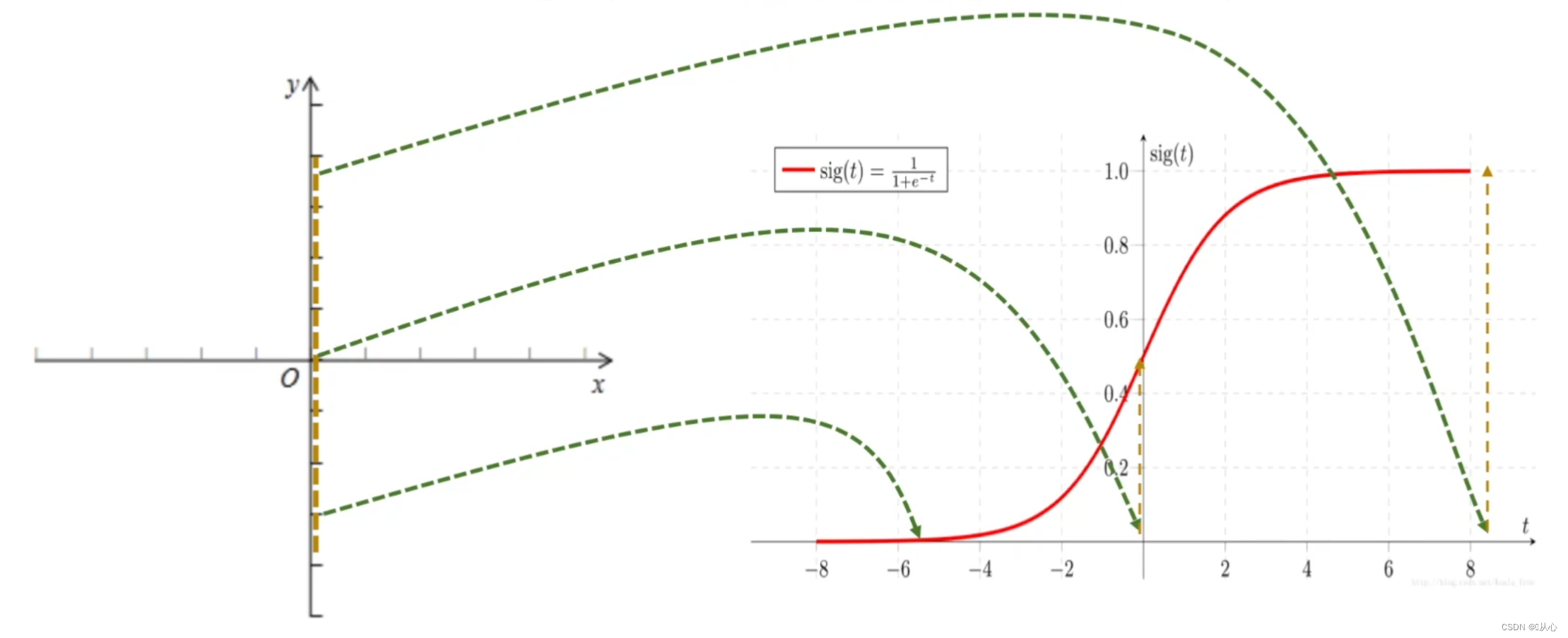
Regresión logística = regresión lineal + función sigmoidea
Regresión lineal: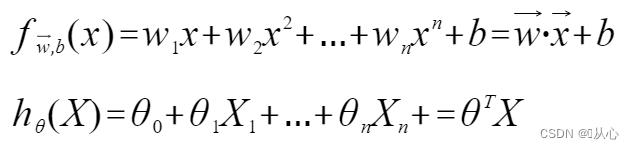
función sigmoidea: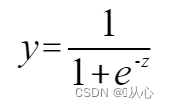
Regresión logística: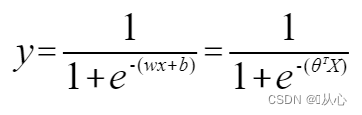
Para que y represente la etiqueta, cámbiela a:
Para hacer probabilidades use:
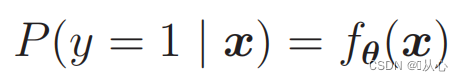
Es decir, las categorías se pueden distinguir por probabilidad.
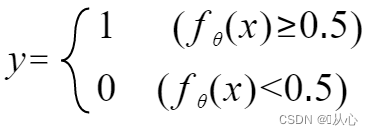
Se puede reescribir de la siguiente manera:
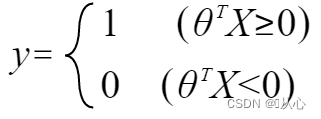
cuando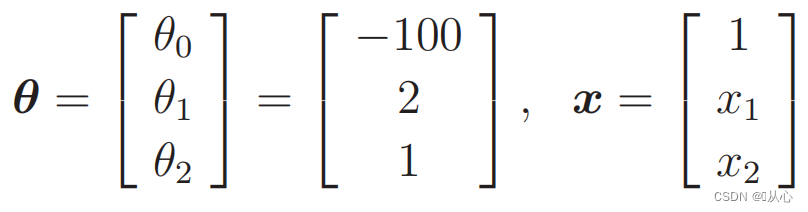
Datos sustitutos: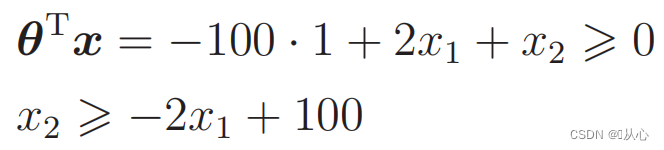
Hay tal foto
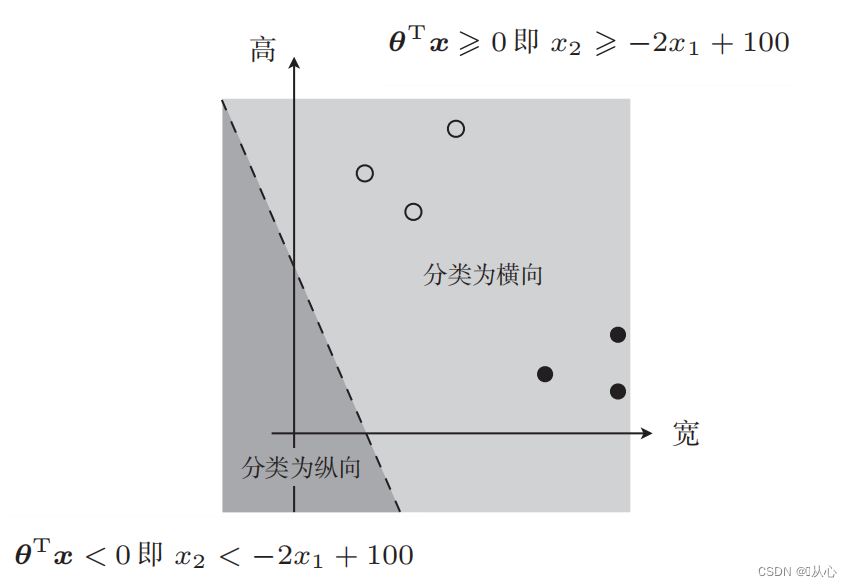 La línea recta utilizada para la clasificación de datos es el límite de decisión.
La línea recta utilizada para la clasificación de datos es el límite de decisión.
Lo que queremos es esto:
Cuando y = 1, P (y = 1 | x) es el mayor
Cuando y = 0, P (y = 0 | x) es el mayor
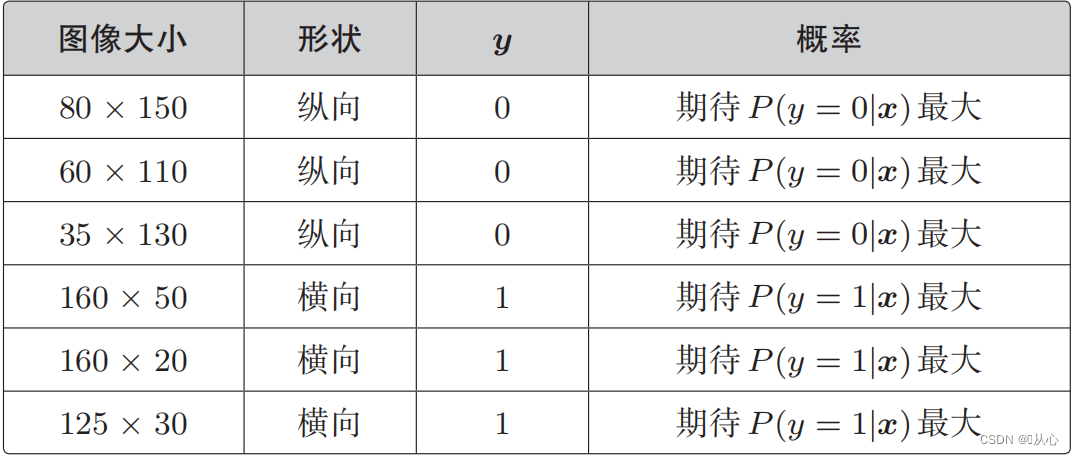
Función de probabilidad (probabilidad conjunta): aquí está la probabilidad que queremos maximizar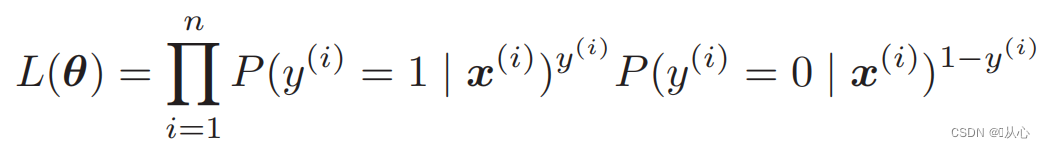
Función logarítmica de verosimilitud: es difícil diferenciar directamente la función de verosimilitud y primero es necesario tomar el logaritmo
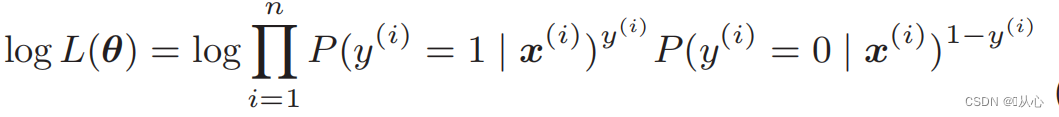
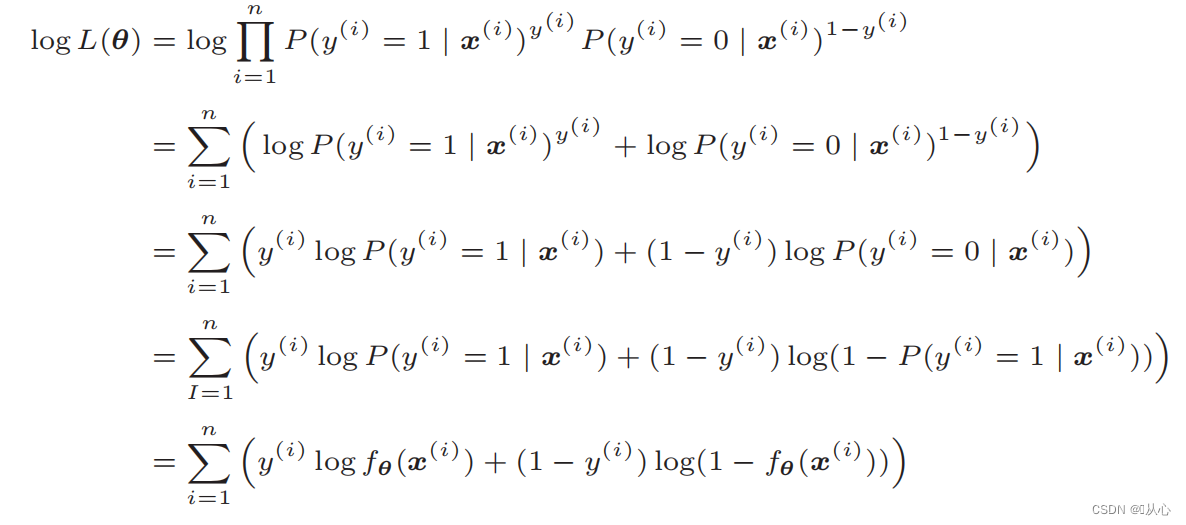
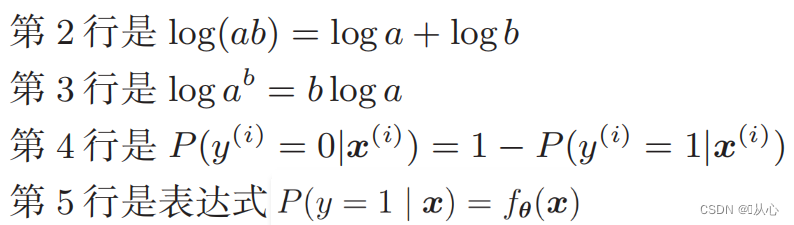
Después de la deformación, se convierte en:
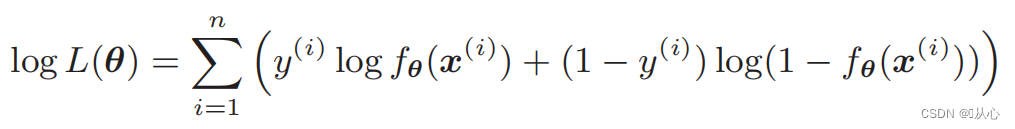
Diferenciación de la función de verosimilitud:
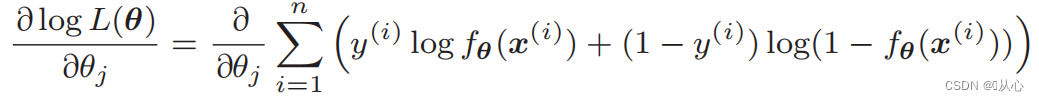
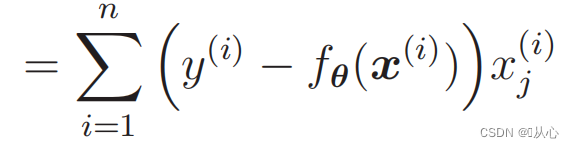
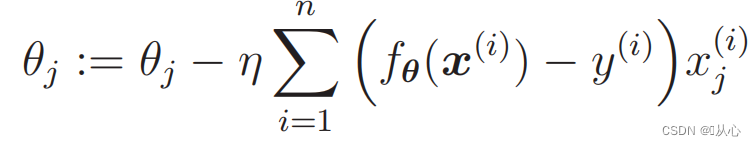
1. Fácil de implementar: la regresión logística es un algoritmo simple que es fácil de entender e implementar.
2. Alta eficiencia computacional: la regresión logística tiene una cantidad de cálculo relativamente pequeña y es adecuada para conjuntos de datos a gran escala.
3. Fuerte interpretabilidad: los resultados de la regresión logística son valores de probabilidad que pueden explicar intuitivamente el resultado del modelo.
1. Requisitos de separabilidad lineal: la regresión logística es un modelo lineal y funciona mal para problemas separables no lineales.
2. Problema de correlación de características: la regresión logística es más sensible a la correlación entre las características de entrada. Cuando existe una fuerte correlación entre las características, puede hacer que el rendimiento del modelo disminuya.
3. Problema de sobreajuste: cuando hay demasiadas características de muestra o el número de muestras es pequeño, la regresión logística es propensa a problemas de sobreajuste.
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
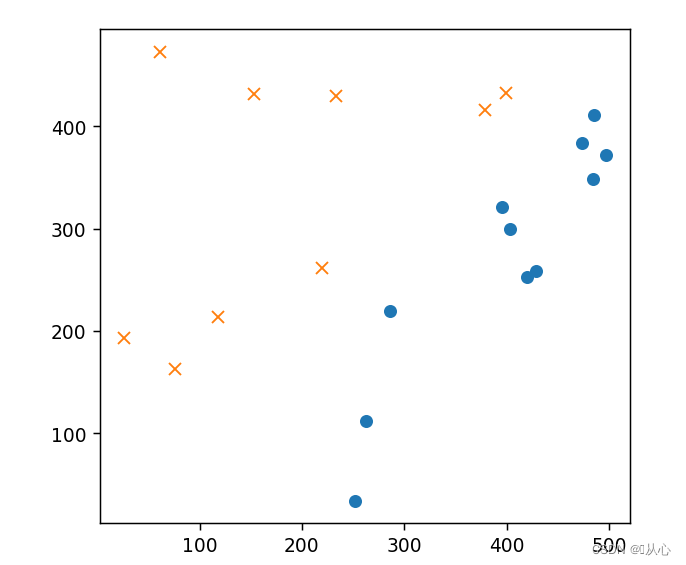
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # 初始化参数
- theta=np.random.randn(3)
-
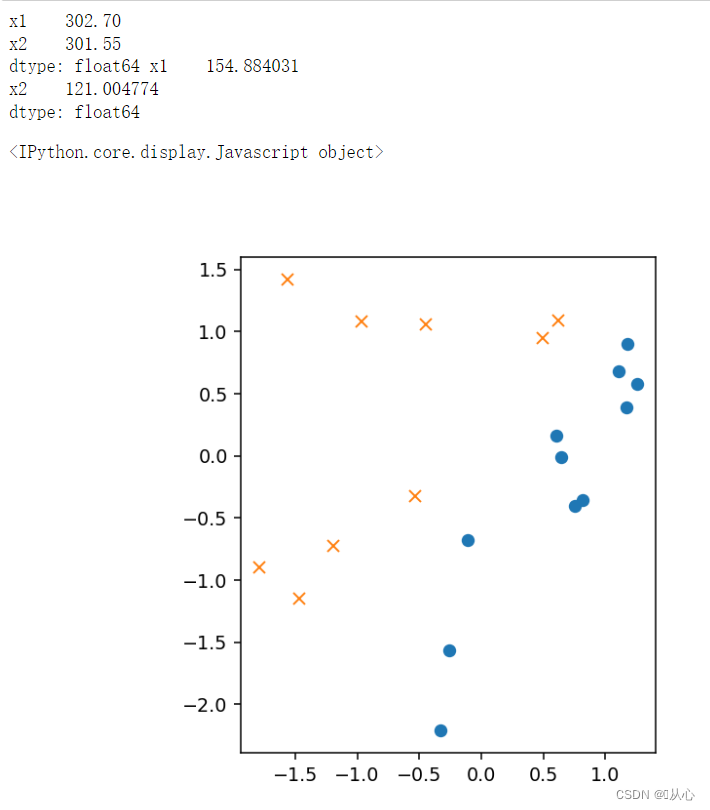
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
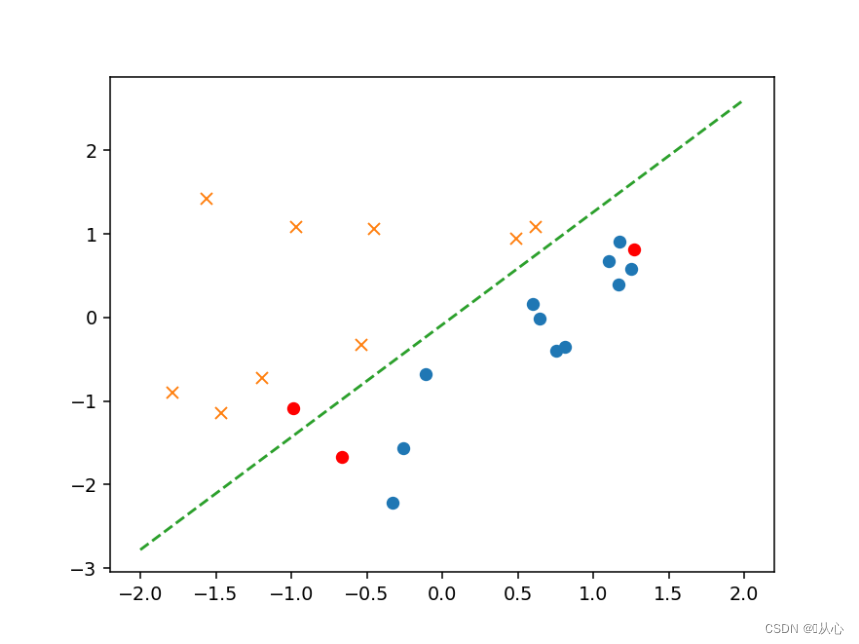
- # 绘图确认
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
- # 键
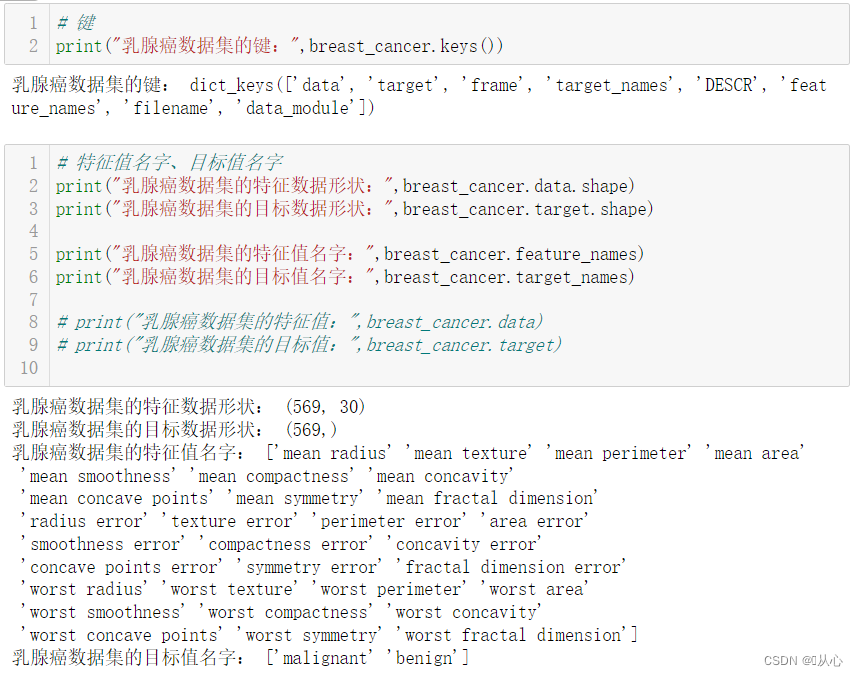
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
- # 每个特征信息
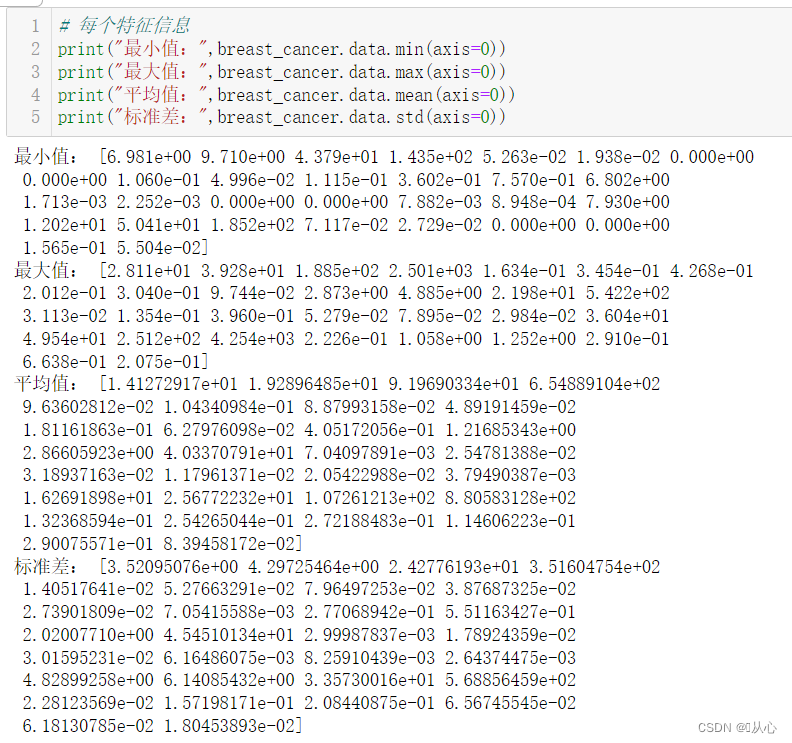
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
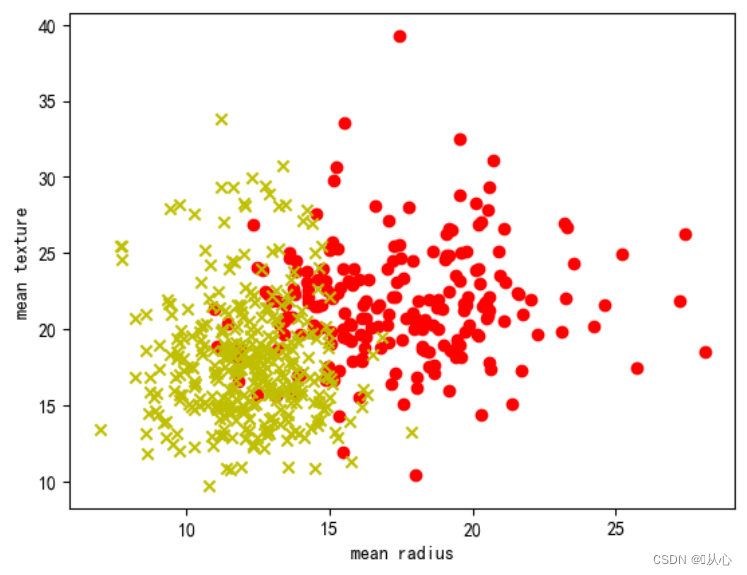
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
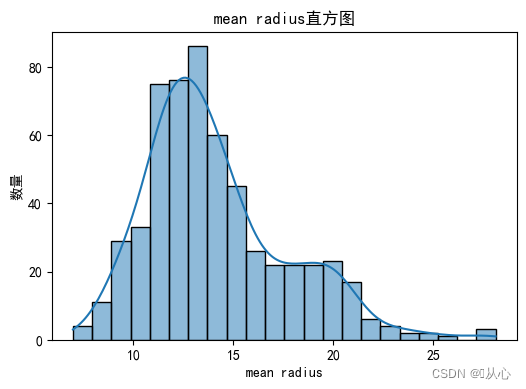
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
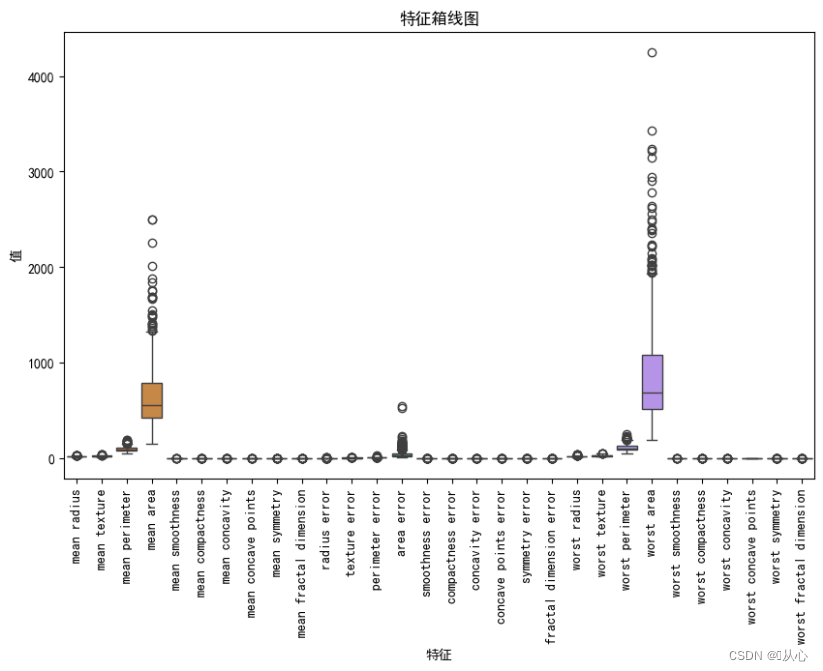
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
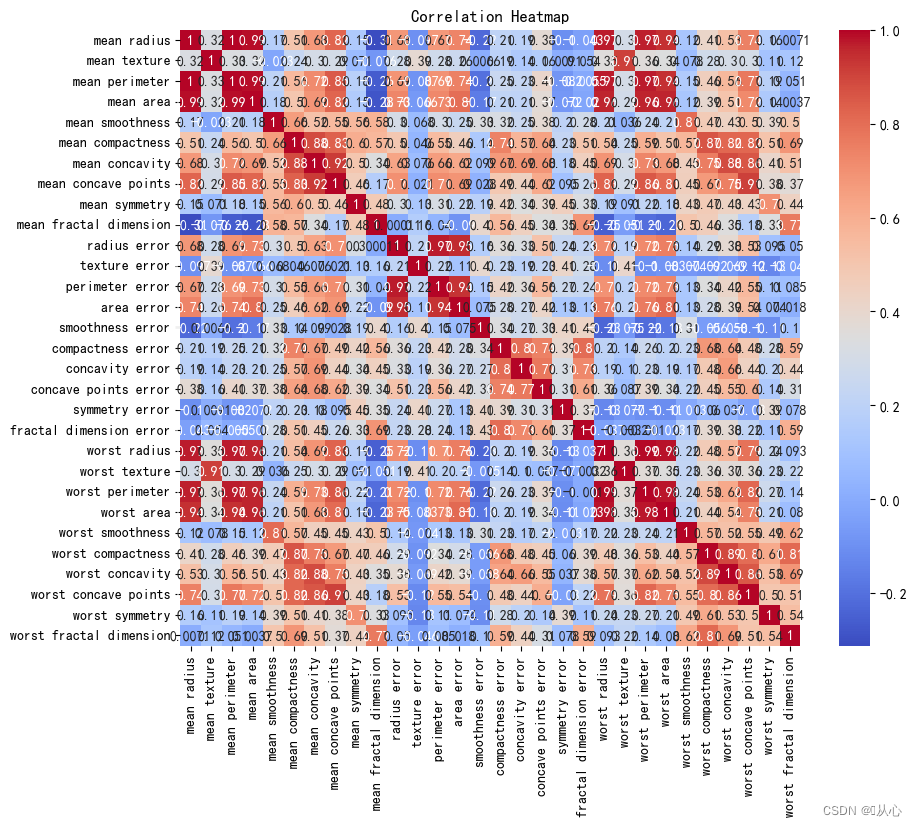
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 2. API
2. API- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
- print("建立的逻辑回归模型为:n", lr)

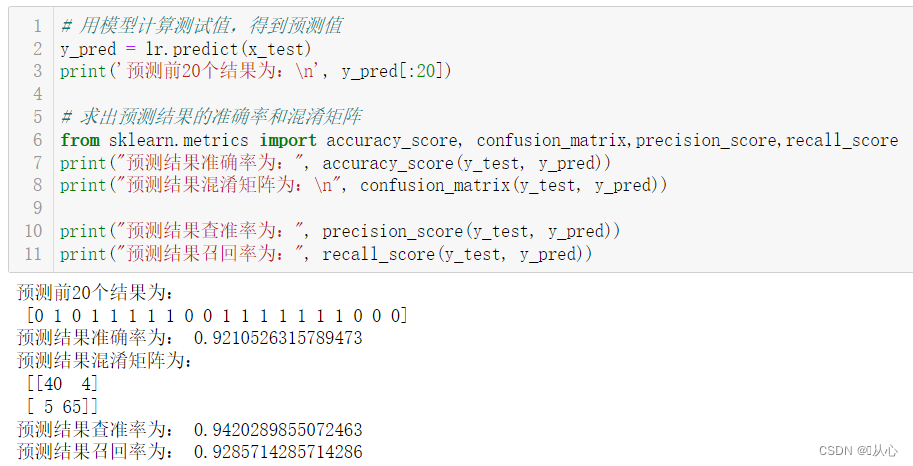
- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
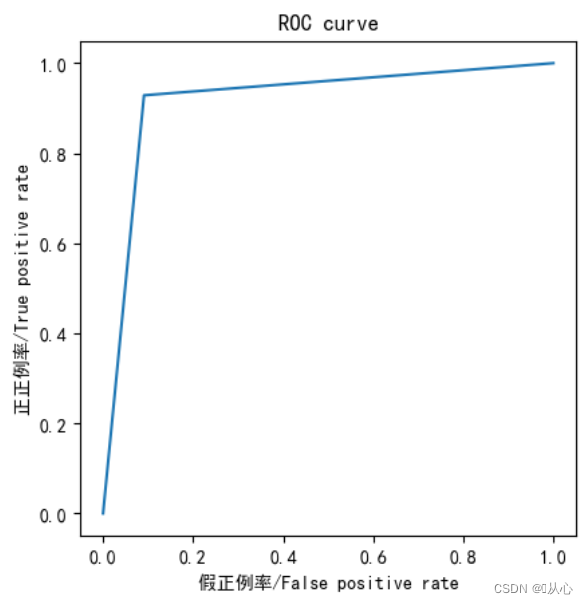
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

El modelo que pasa después de la evaluación del modelo se puede sustituir por el valor real para la predicción.
Los viejos sueños se pueden revivir, veamos:Aprendizaje automático (5) - Aprendizaje supervisado (5) - Regresión lineal 2
Si quieres saber qué pasa después, echemos un vistazo:Aprendizaje automático (5) - Aprendizaje supervisado (7) -SVM1

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]