minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Índice e links para séries de artigos
Artigo anterior:Aprendizado de Máquina (5) - Aprendizado Supervisionado (5) - Regressão Linear 2
Próximo artigo:Aprendizado de Máquina (5) – Aprendizado Supervisionado (7) –SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
Regressão logística = regressão linear + função sigmóide
A regressão logística (regressão logística) consiste simplesmente em encontrar uma linha reta para dividir dados binários.
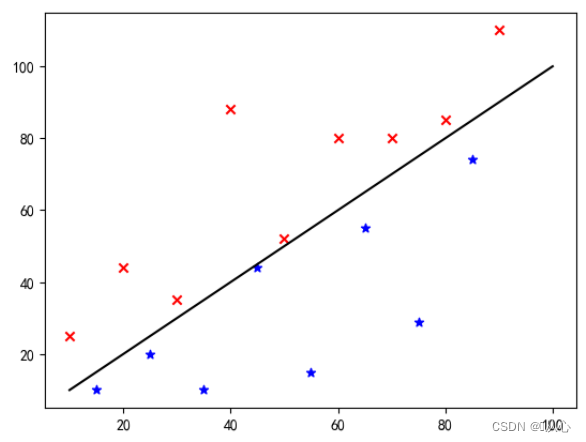
Resolva o problema de classificação binária classificando os objetos pertencentes a uma determinada categoriavalor de probabilidadePara determinar se pertence a uma determinada categoria, esta categoria é marcada como 1 (exemplo positivo) por padrão, e a outra categoria será marcada como 0 (exemplo negativo).
Na verdade, isso é semelhante à etapa de regressão linear. A diferença está nos métodos usados para “verificar o efeito de ajuste do modelo” e “ajustar o ângulo de posição do modelo”.
Você precisa usar uma função (função sigmóide) para mapear os dados de entrada entre 0 e 1 e, se o valor da função for maior que 0,5, será considerado 1, caso contrário, será 0. Isso pode ser convertido em uma representação probabilística.
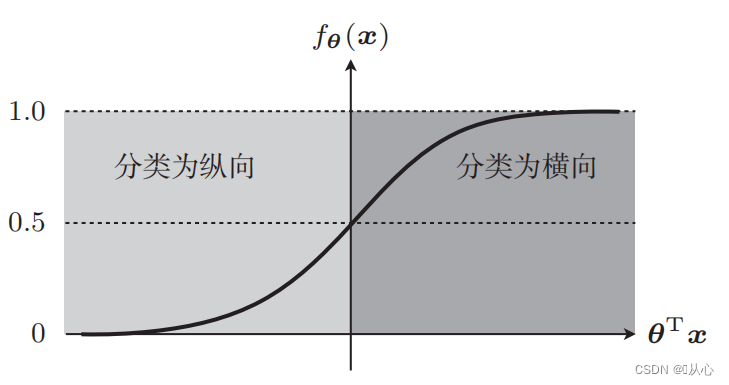
Tome como exemplo a classificação das imagens, divida as imagens em verticais e horizontais
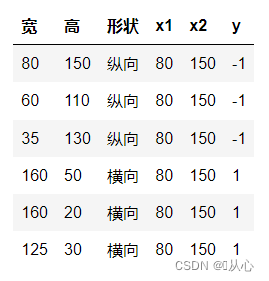
É assim que esses dados são exibidos no gráfico. Para separar os pontos de cores diferentes (categorias diferentes) no gráfico, traçamos essa linha. O objetivo desta classificação é encontrar tal linha.
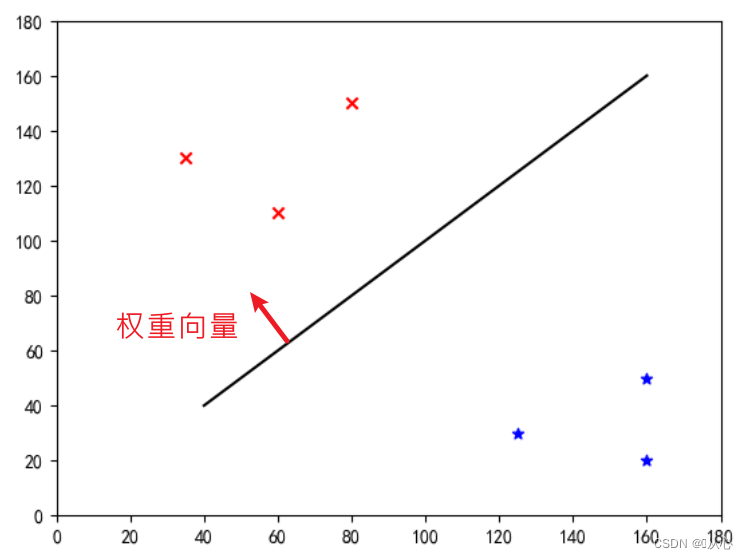
Esta é uma "linha reta que torna o vetor de peso um vetor normal" (deixe o vetor de peso ser perpendicular à linha)
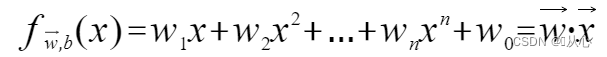
w é o vetor de peso, tornando-o uma linha reta do vetor normal, par;
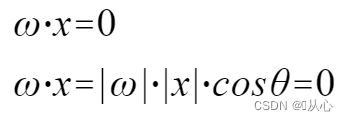
Um modelo que aceita vários valores, multiplica cada valor pelo seu respectivo peso e, finalmente, gera a soma.
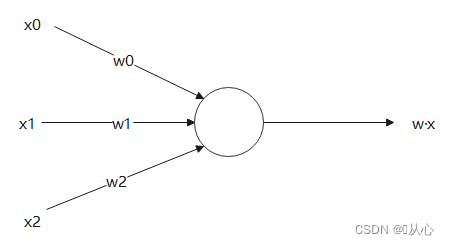
O produto interno é uma medida do grau de similaridade entre os vetores. Um resultado positivo indica similaridade, um valor 0 indica verticalidade e um resultado negativo indica dissimilaridade.
usar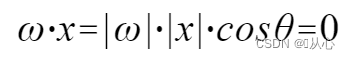 É melhor entender, porque |w| e |x| são ambos números positivos, então o sinal do produto interno é cosθ, ou seja, se for menor que 90 graus, é semelhante, e se for maior que 90 graus, é diferente, ou seja
É melhor entender, porque |w| e |x| são ambos números positivos, então o sinal do produto interno é cosθ, ou seja, se for menor que 90 graus, é semelhante, e se for maior que 90 graus, é diferente, ou seja
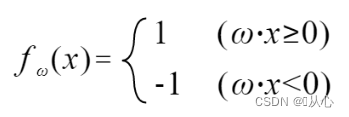
Se for igual ao valor do rótulo original, o vetor de peso não será atualizado. Se não for igual ao valor do rótulo original, a adição do vetor será usada para atualizar o vetor de peso.
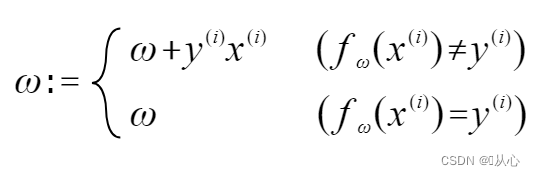
Conforme mostrado na figura, se não for igual ao rótulo original, então
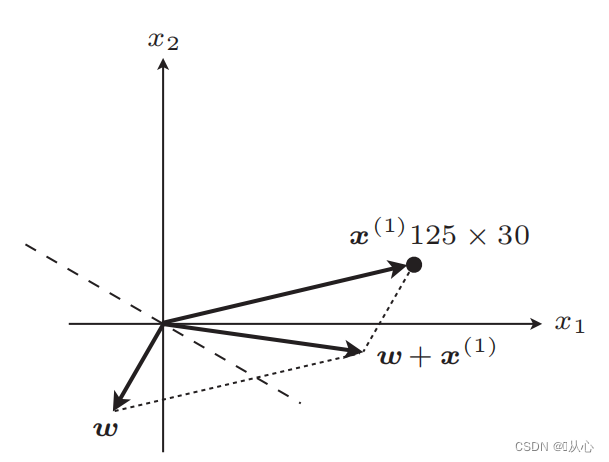
linha reta após atualização
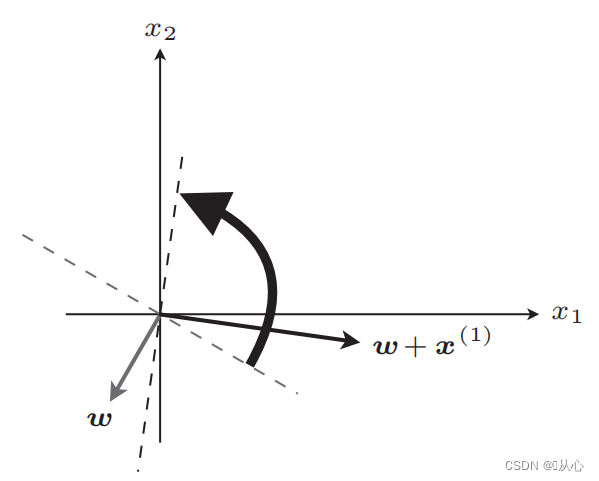
Após a atualização, igual
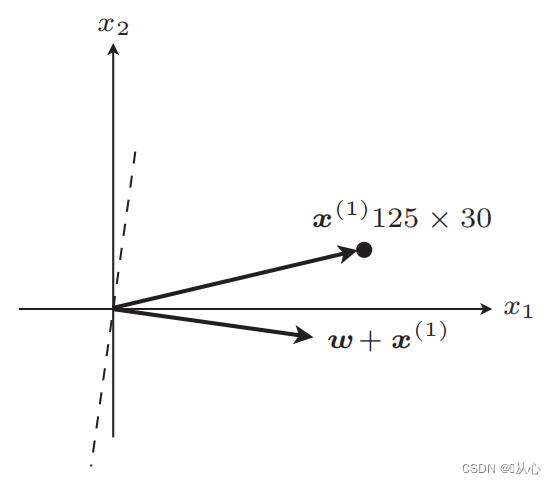
Etapas: primeiro determine aleatoriamente uma linha reta (ou seja, determine aleatoriamente um vetor de peso w), substitua um dado de valor real x no produto interno e obtenha um valor (1 ou -1) por meio da função discriminante se for igual. ao valor do rótulo original, o vetor de peso não é atualizado. Se for diferente do valor do rótulo original, use a adição de vetor para atualizar o vetor de peso.
! ! !Nota: O perceptron só pode resolver problemas linearmente separáveis
Linearmente separável: casos em que linhas retas podem ser usadas para classificação
Inseparabilidade linear: não pode ser classificada por linhas retas
Preto é a função sigmóide, vermelho é a função degrau (descontínua)
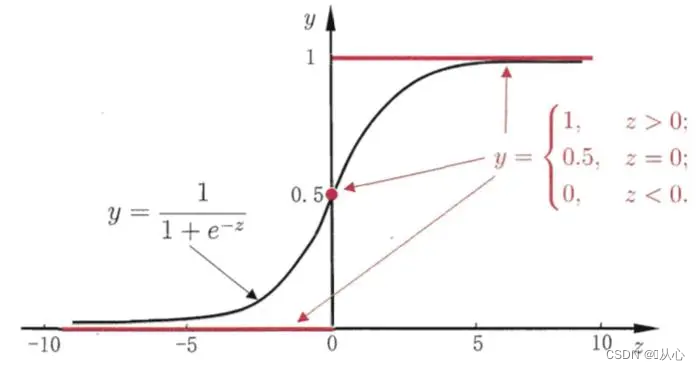
Função: A entrada da regressão logística é o resultado da regressão linear.Podemos obter um valor previsto na regressão linear. A função Sigmóide mapeia qualquer entrada para o intervalo [0,1], completando assim a conversão de valor em probabilidade, que é uma tarefa de classificação.
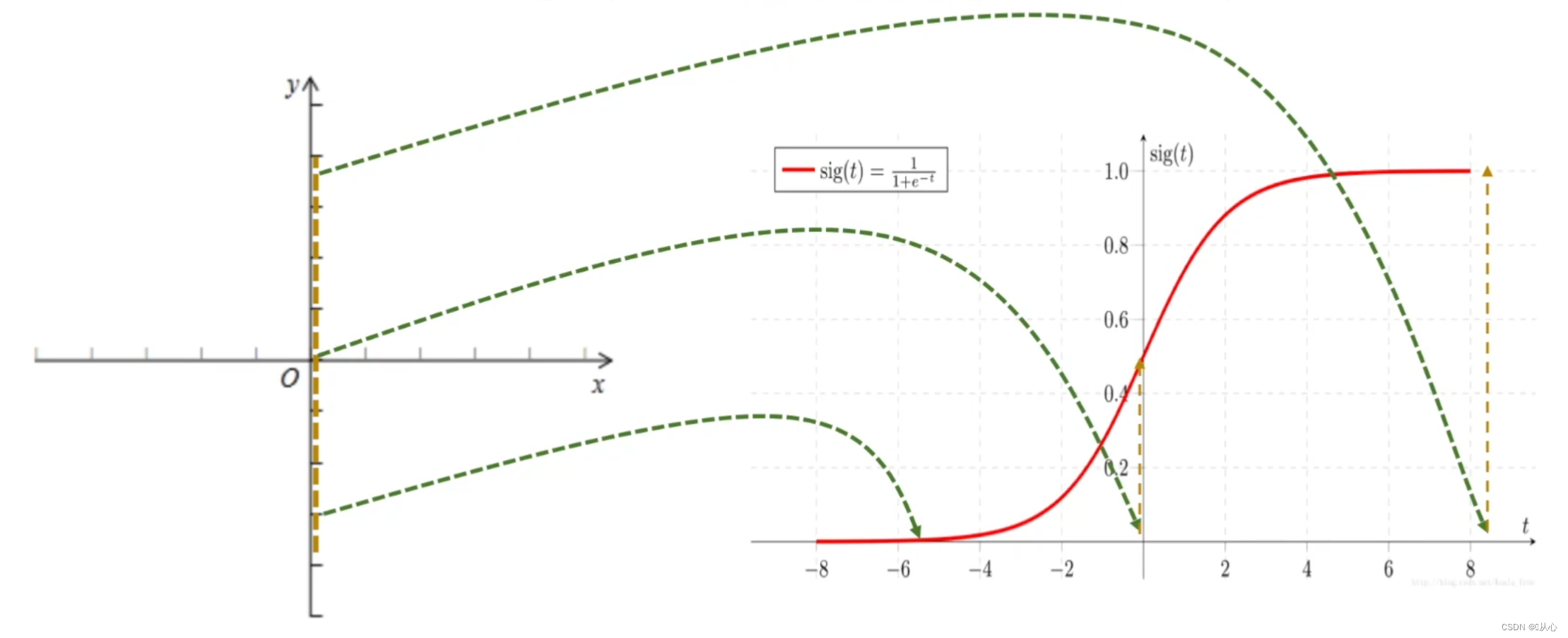
Regressão logística = regressão linear + função sigmóide
Regressão linear: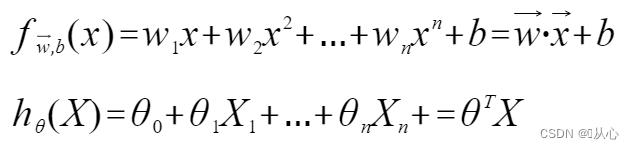
função sigmóide: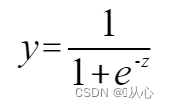
Regressão logística: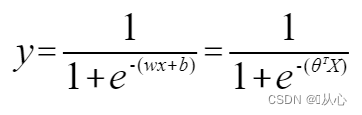
Para deixar y representar o rótulo, altere-o para:
Para fazer probabilidades use:
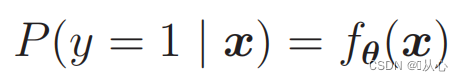
Ou seja, as categorias podem ser distinguidas por probabilidade
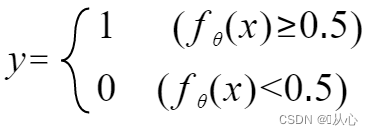
Pode ser reescrito da seguinte forma:
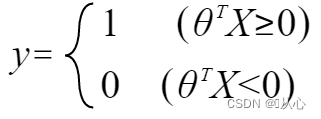
quando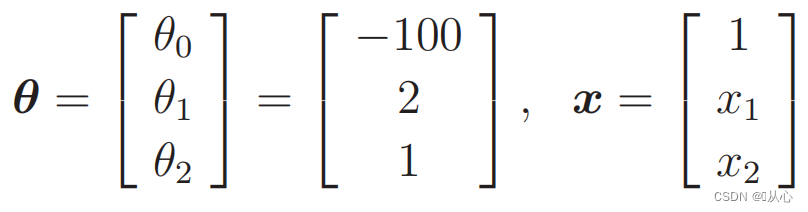
Dados substitutos: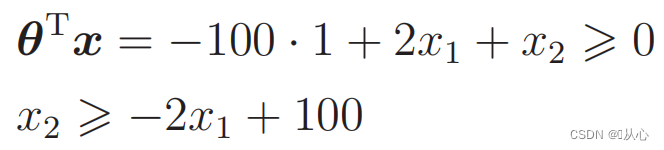
Existe uma imagem assim
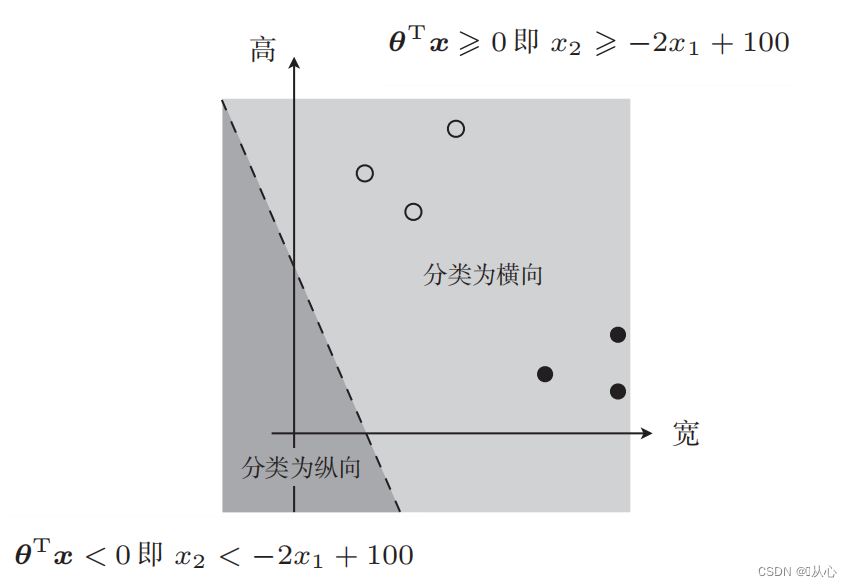 A linha reta usada para classificação de dados é o limite de decisão
A linha reta usada para classificação de dados é o limite de decisão
O que queremos é isto:
Quando y=1, P(y=1|x) é o maior
Quando y=0, P(y=0|x) é o maior
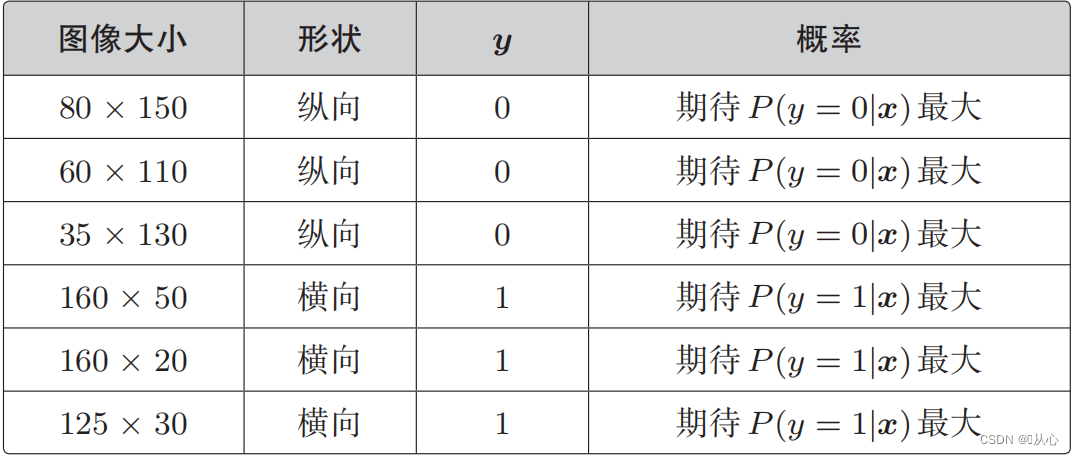
Função de verossimilhança (probabilidade conjunta): aqui está a probabilidade que queremos maximizar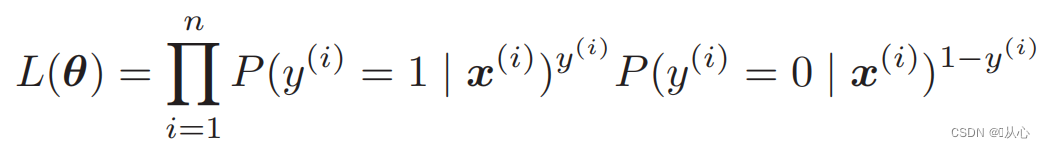
Função de log de verossimilhança: é difícil diferenciar diretamente a função de verossimilhança e o logaritmo precisa ser obtido primeiro
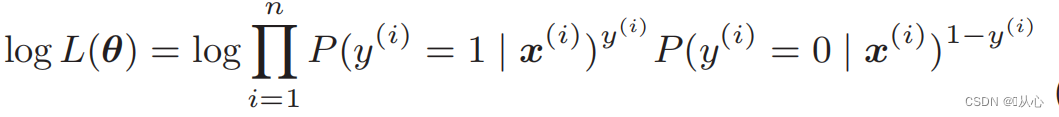
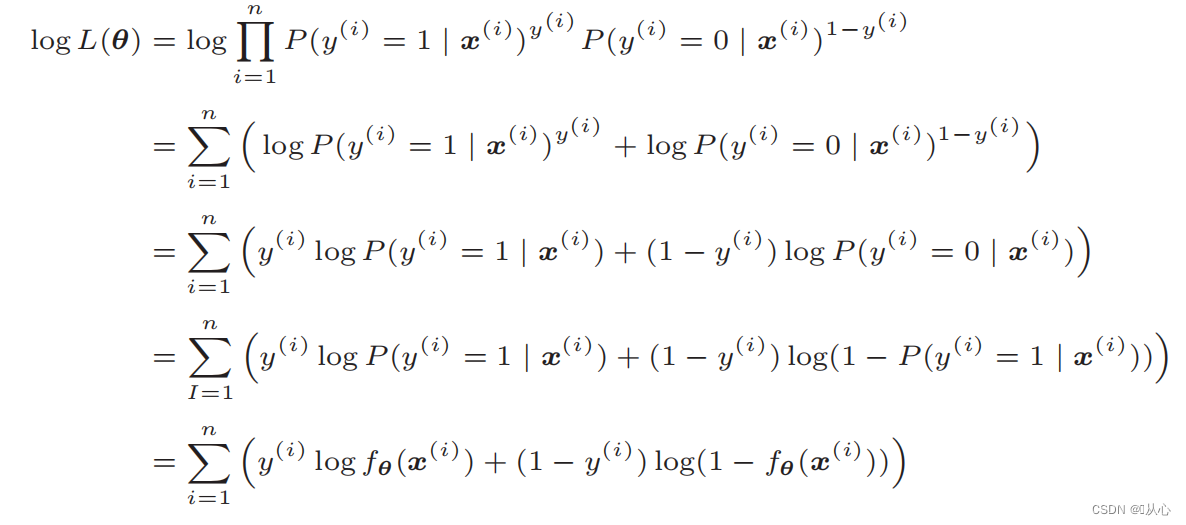
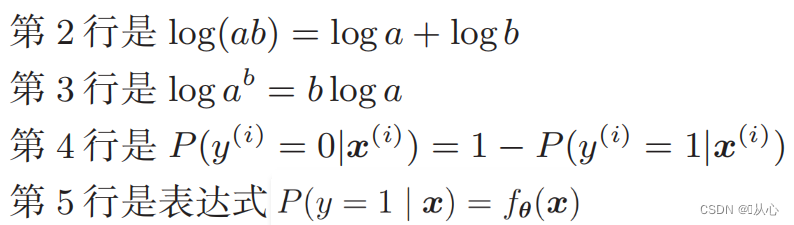
Após a deformação, torna-se:
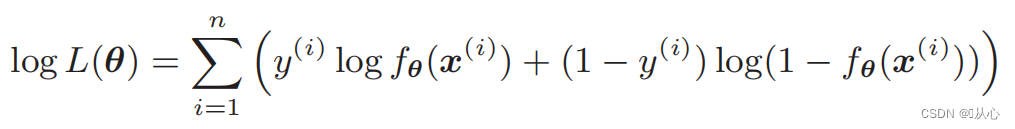
Diferenciação da função de verossimilhança:
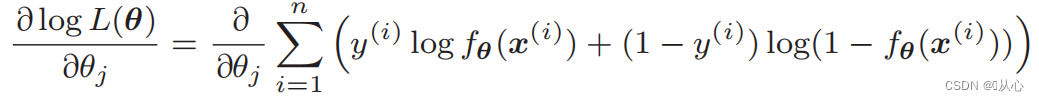
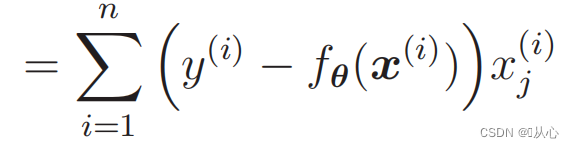
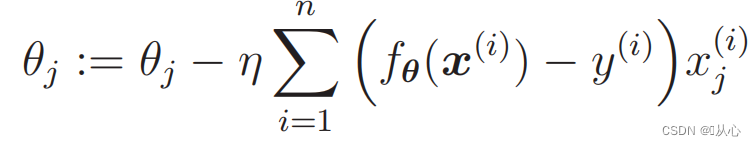
1. Simples de implementar: A regressão logística é um algoritmo simples, fácil de entender e implementar.
2. Alta eficiência computacional: A regressão logística tem uma quantidade relativamente pequena de cálculos e é adequada para conjuntos de dados em grande escala.
3. Forte interpretabilidade: Os resultados da regressão logística são valores de probabilidade, que podem explicar intuitivamente a saída do modelo.
1. Requisitos de separabilidade linear: A regressão logística é um modelo linear e tem desempenho insatisfatório para problemas separáveis não lineares.
2. Problema de correlação de recursos: A regressão logística é mais sensível à correlação entre recursos de entrada. Quando há uma forte correlação entre recursos, pode causar declínio no desempenho do modelo.
3. Problema de overfitting: Quando há muitos recursos de amostra ou o número de amostras é pequeno, a regressão logística está sujeita a problemas de overfitting.
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
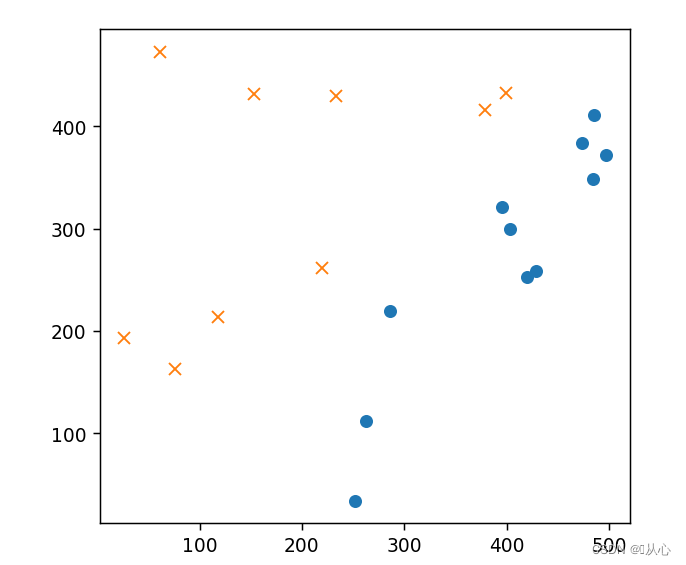
- # 初始化参数
- theta=np.random.randn(3)
-
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
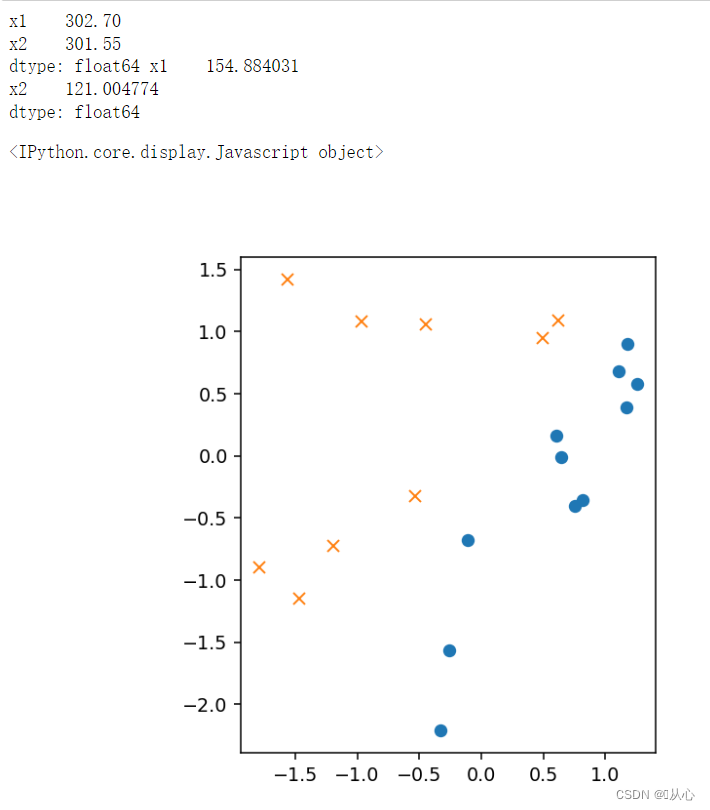
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
- # 绘图确认
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
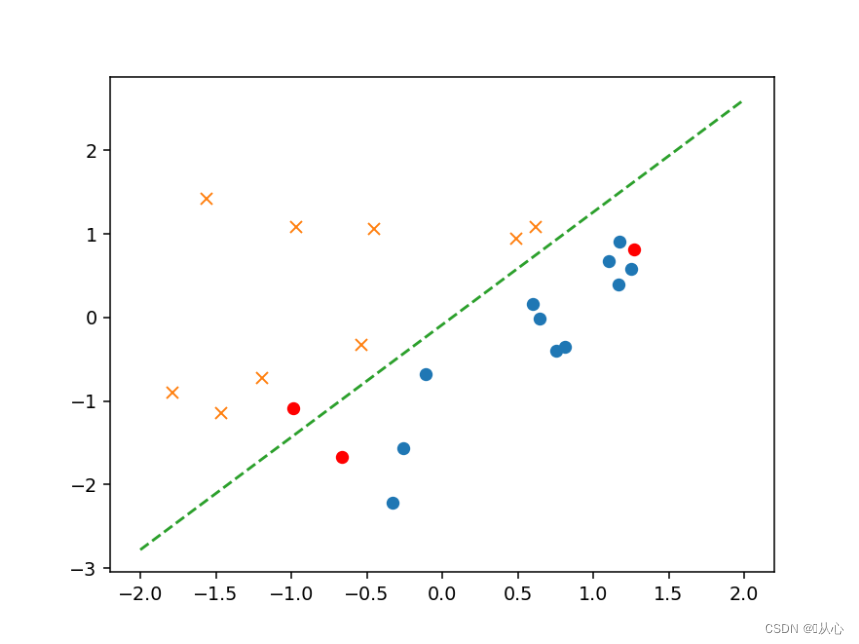
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
- # 键
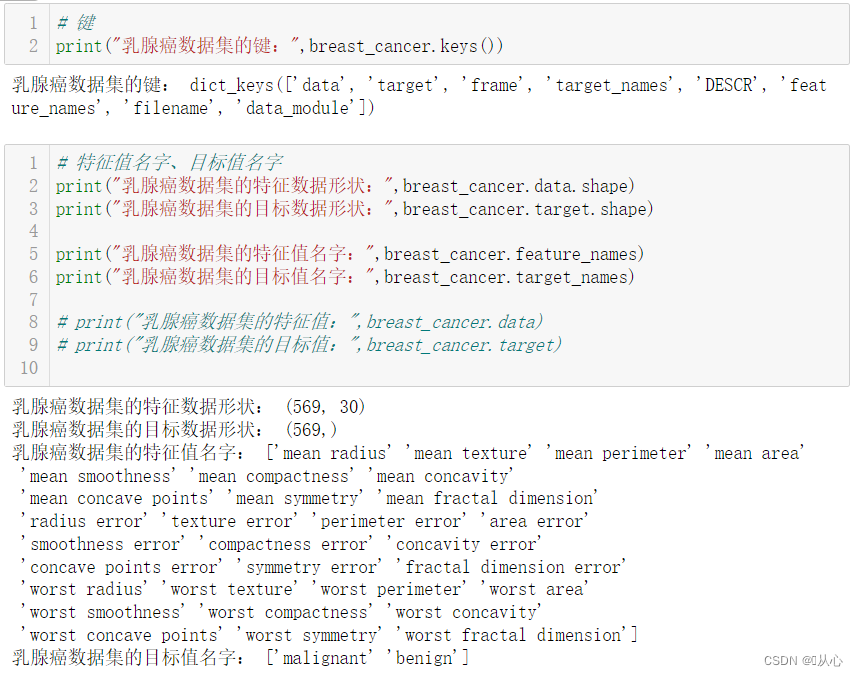
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
- # 每个特征信息
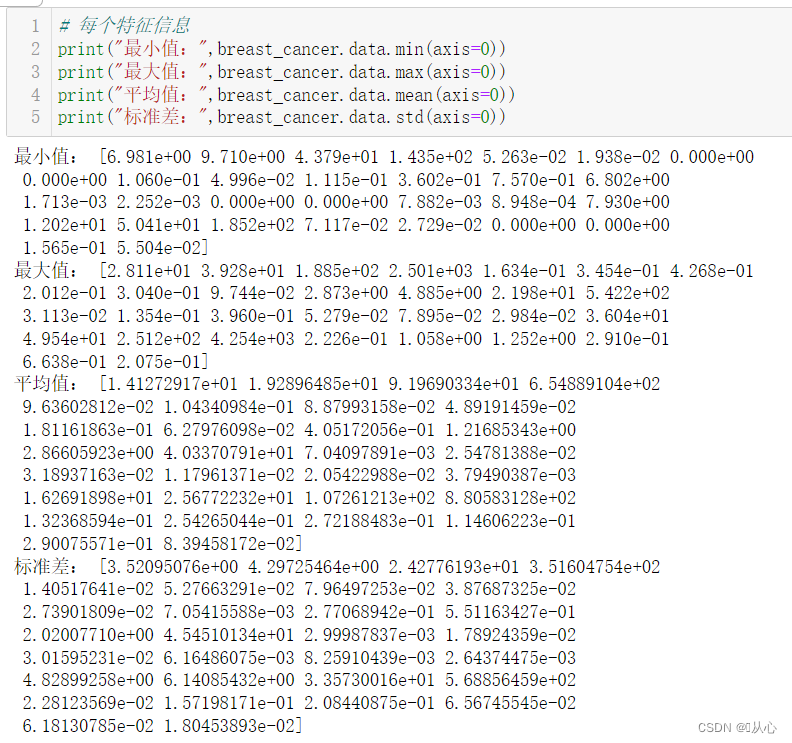
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
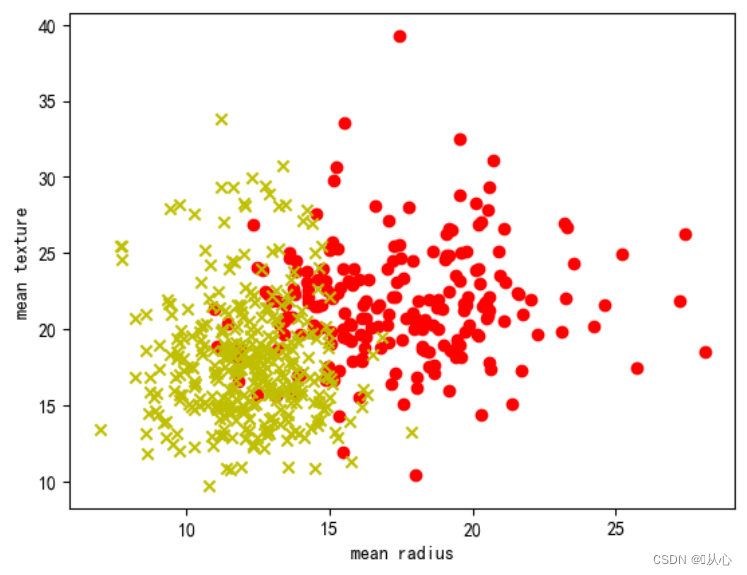
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
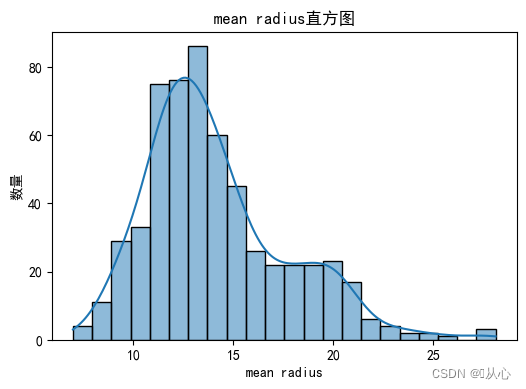
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
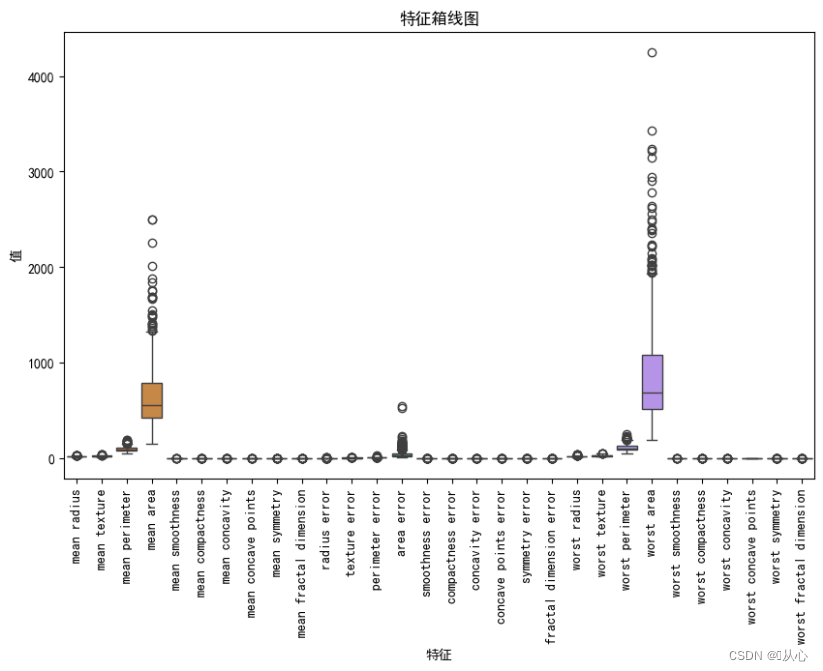
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
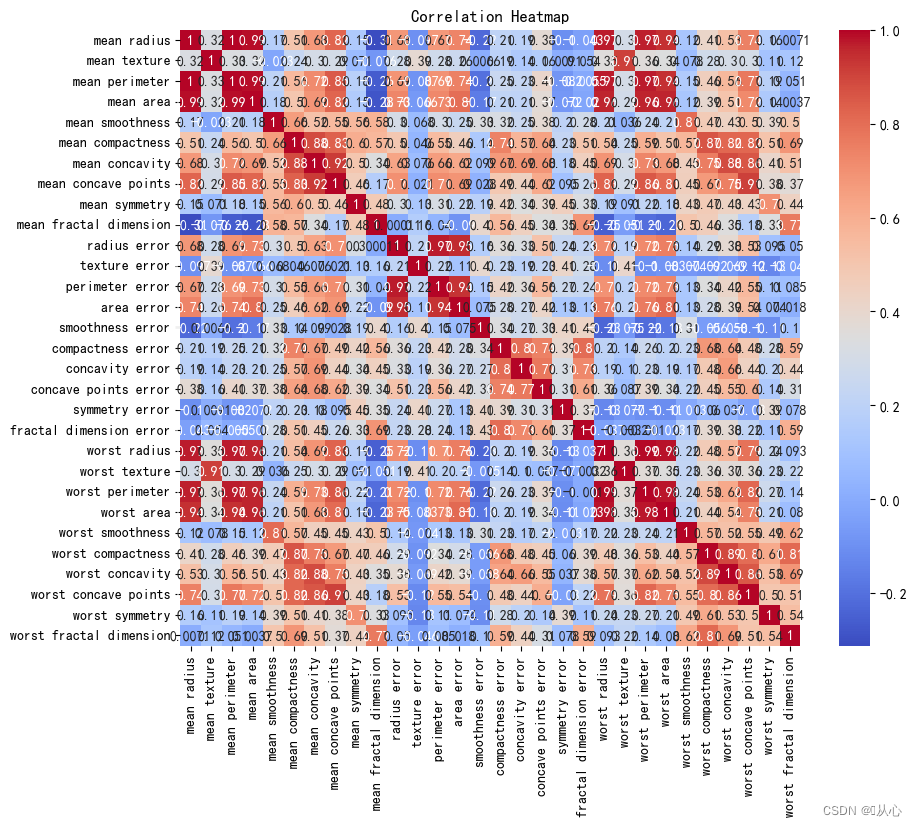
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 2、API
2、API- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
- print("建立的逻辑回归模型为:n", lr)

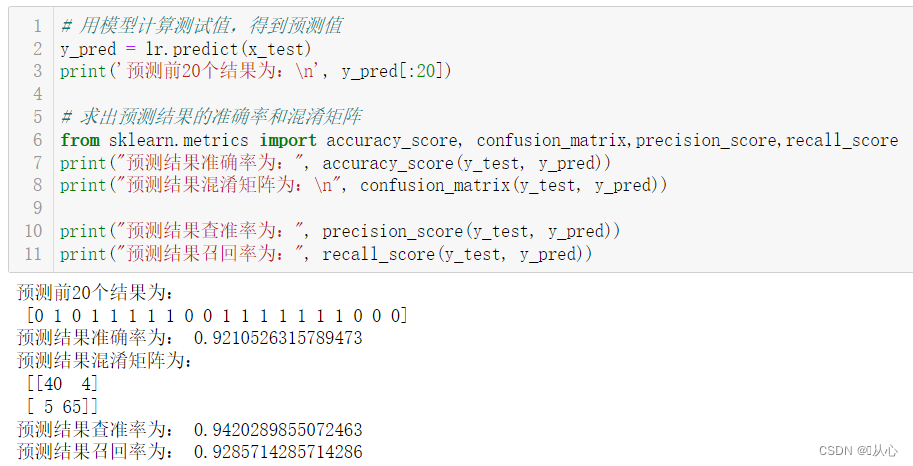
- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
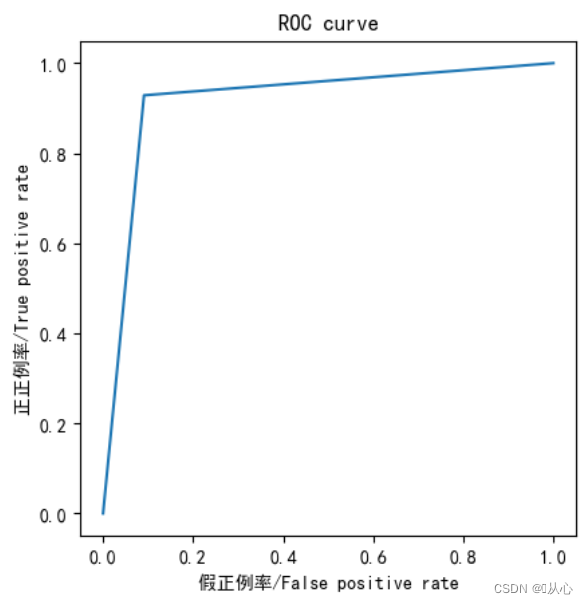
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

O modelo aprovado após a avaliação do modelo pode ser substituído pelo valor real para previsão.
Antigos sonhos podem ser revividos, vejamos:Aprendizado de Máquina (5) - Aprendizado Supervisionado (5) - Regressão Linear 2
Se você quiser saber o que acontece a seguir, vamos dar uma olhada:Aprendizado de Máquina (5) – Aprendizado Supervisionado (7) –SVM1

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]