2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Tabula contentorum et nexus ad seriem articulorum
Articulus prior:Apparatus Discens (5) -- Supervised Learning (5)
Articulus proximus:Apparatus Discens (5) -- Supervised Learning (7) --SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
Logiscus regressus = linearis regressus + munus sigmoidea
Regressio logistica (regressio logistica) simpliciter est invenire lineam rectam ad datam binariam dividere.
Solvere problema binarii classificationem digerendo ea quae ad certum genus pertinentprobabile valoremDecernere num ad certum categoriam pertineat, hoc categoriam 1 (exempli positivi) per defaltam designatum, et alterum categoria ut 0 (exempli negativum).
Re vera, haec est similis regressioni lineari gradui. Differentia est in modis adhibitis "exemplum reprimendi effectum convenientem" et "exemplari locum accommodare angulum".
Opus est uti functione (sigmoide) ad describendam datam inputationem inter 0-1, et si valor functionis maior est quam 0.5, esse I aestimatur, secus 0 est. Hoc converti potest in repraesentationem probabilisticam.
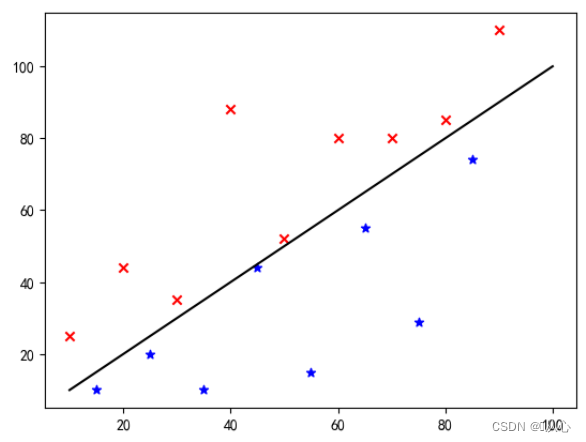
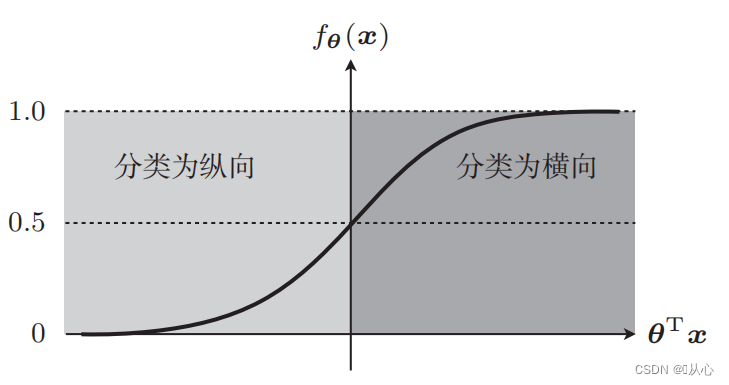
Sume in exemplum picturae classificationis, imagines divide in verticali et horizontali
Ita haec notitia in grapho monstratur. Ut puncta diversorum colorum (diversi praedicamentorum) in graphe distinguamus, talem lineam ducimus. Propositum classificationis est talem lineam invenire.
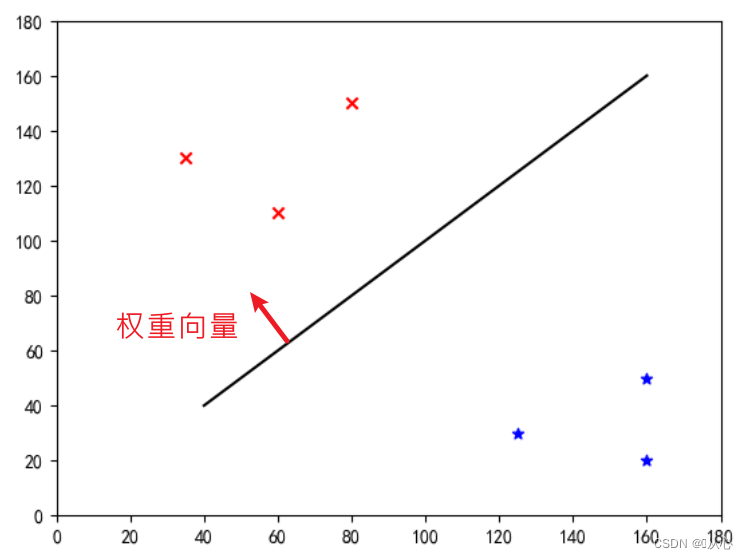
Haec est "linea recta quae pondus vector normalem vectorem" facit (vector sit pondus ad lineam perpendiculum)
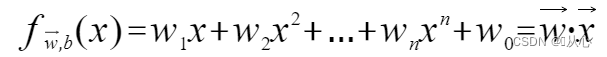
w est pondus vector;
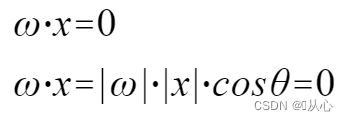
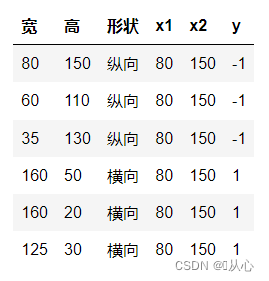
Exemplar, quod multiplices valores accipit, unumquodque valorem suo cuiusque pondere multiplicat, ac tandem summam erigit.
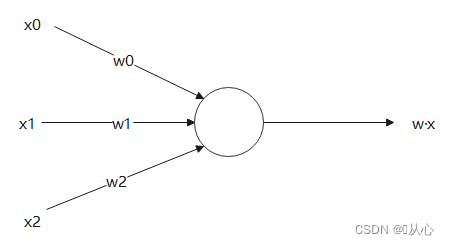
Productus interior mensura gradus similitudinis inter vectores est. Effectus positivum similitudinem indicat, valor 0 indicat verticalitatem, effectus negativus dissimilitudinem indicat.
usus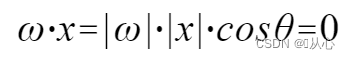 Melius est intelligere, quia |w| . et |x| 90 gradus dissimile est
Melius est intelligere, quia |w| . et |x| 90 gradus dissimile est
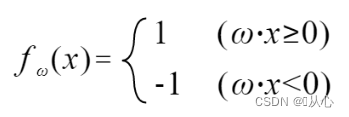
Si par est pretii originali pittacii, vector pondus non renovabitur.
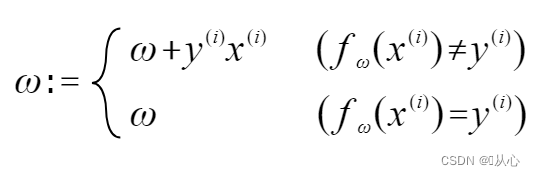
Ut patet in figura, si non est aequalis cum originali pittacio, tunc
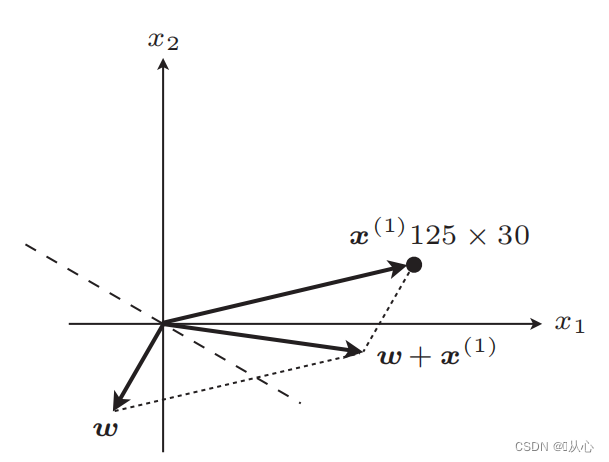
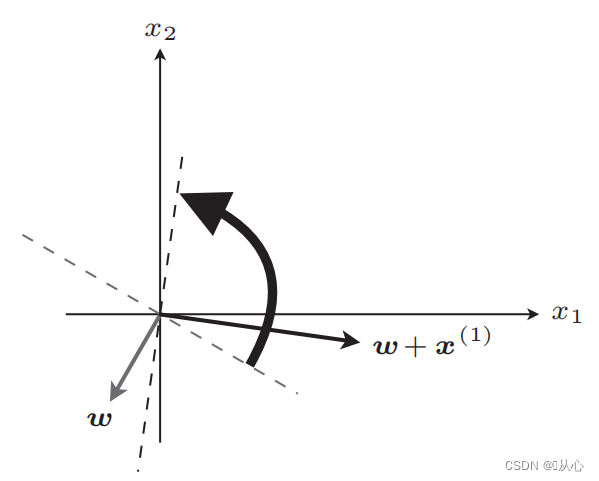
recta ad renovatio
Post update, aequalis
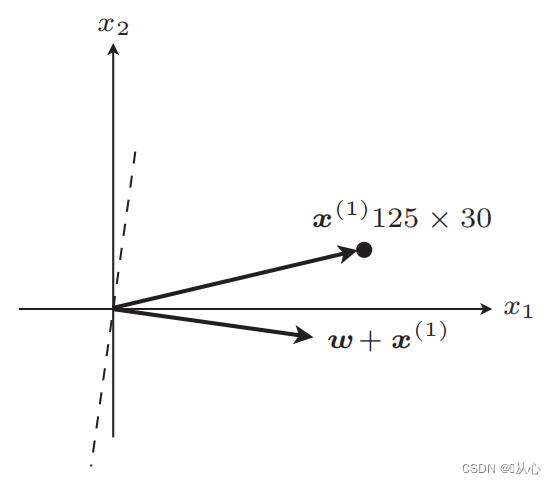
Gradus: Primum passim rectam lineam determinant (hoc est, vectorem pondus passim determinant) valorem realem datam x in productum interiorem substituunt, et obtinent valorem (1 vel -1) per functionem discriminantem Ad valorem pittacii originalis, pondus vector Update non est, si a valore label originali differt, vector uti addito ad pondus vectoris renovandum.
! ! !Nota: Perceptronum non potest nisi problemata separabilia solvere
Linearibus separabilibus: casibus in quibus lineae rectae adhiberi possunt pro classificatione
Linearibus inseparabilitas: lineae rectis distingui non possunt
Nigrum est munus sigmoidea, rubrum est munus gradus (discontinuum)
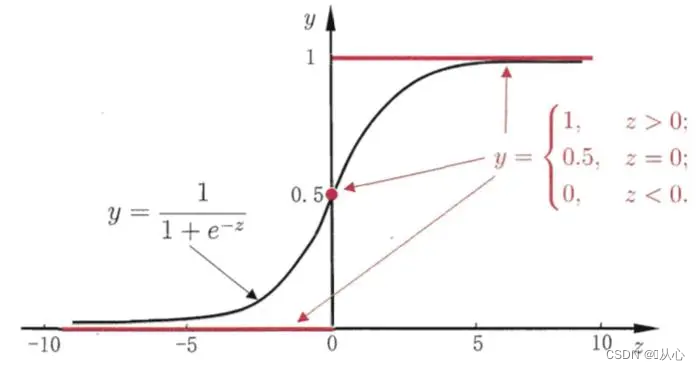
Functio: Initus regressionis logisticae effectus est regressionis linearis.Valorem praedictum in lineari procedere possumus. Munus Sigmoidea mappis quaevis initus ad [0,1] intervallum, ita conversionem a valore in probabilitatem complentes, quod est munus classificationis.
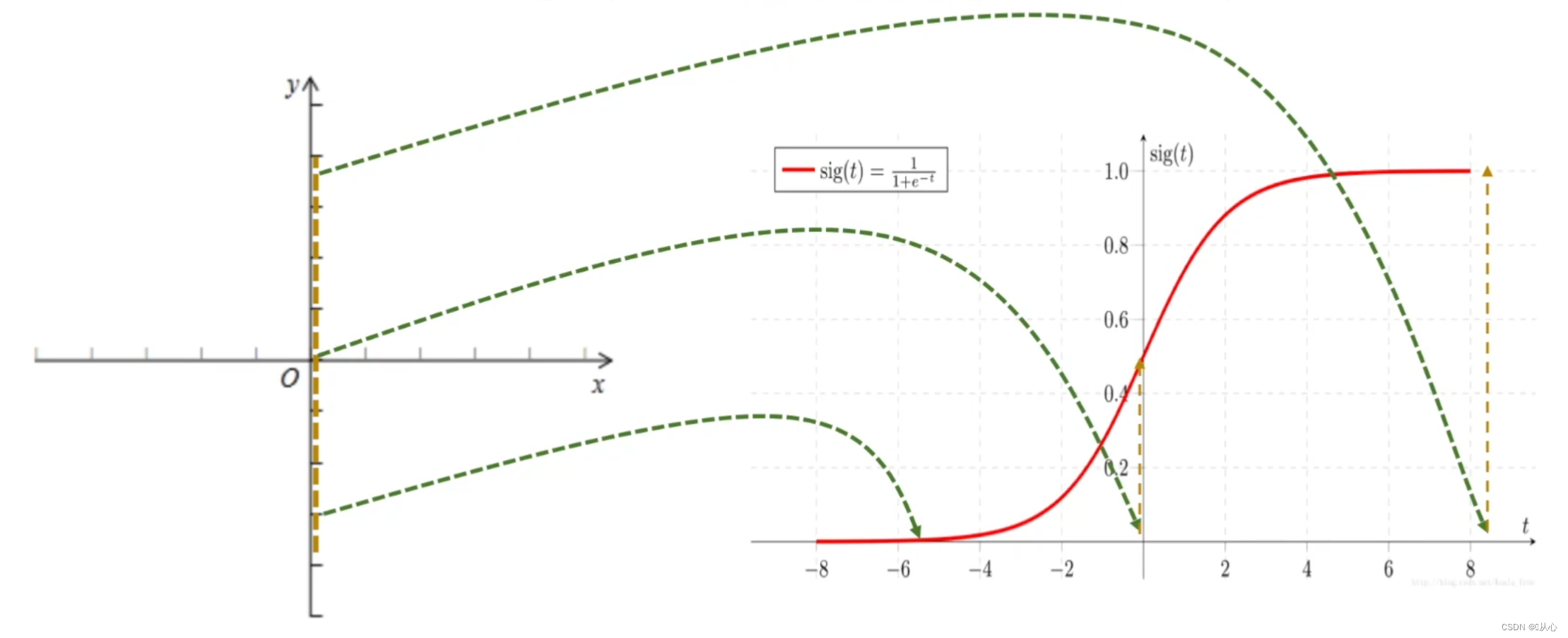
Logiscus regressus = linearis regressus + munus sigmoidea
Progredior linearis: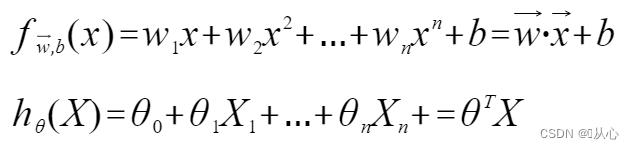
munus coion;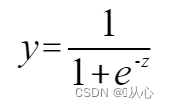
Regressio logisticae: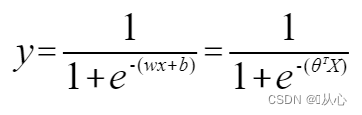
Ut sit y titulus repraesentare, mutare;
Facere probabilia uteris:
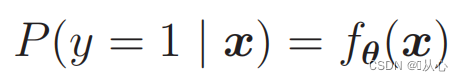
Genera vero probabilitate distingui possunt
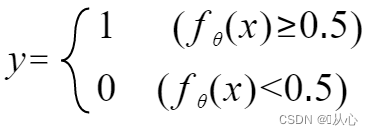
Rescriptum esse potest sic:
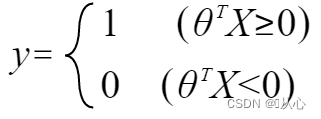
quando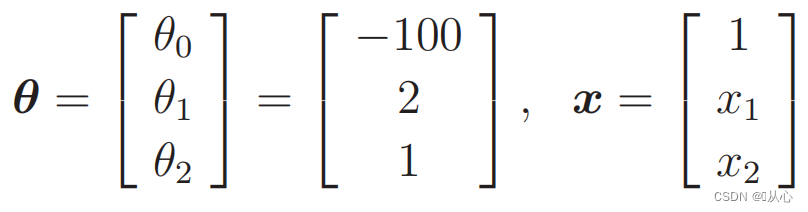
Substitutus data: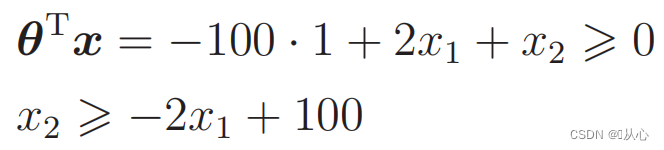
Est talis imago
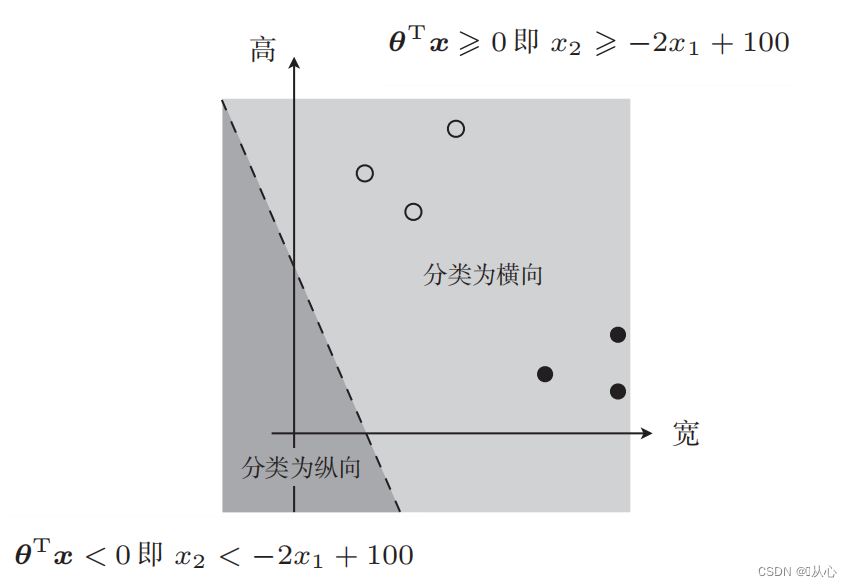 Recta linea pro notitia partitio est consilium terminus
Recta linea pro notitia partitio est consilium terminus
Quod volumus, hoc est;
Cum y = I, P (y = I | x) est maximum
Cum y=0, P(y=0|x) est maximum*
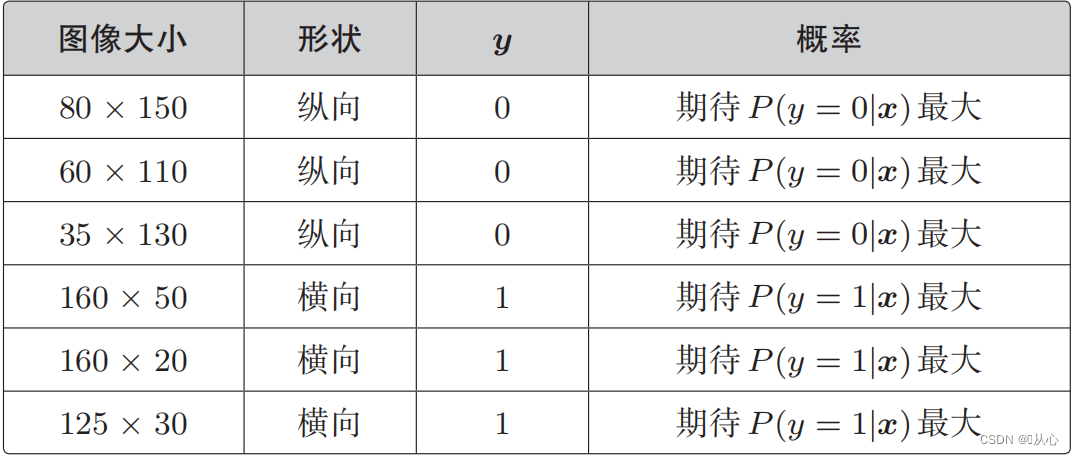
Munus likelihood (probabilitatis iuncturam): hic est probabile volumus maximize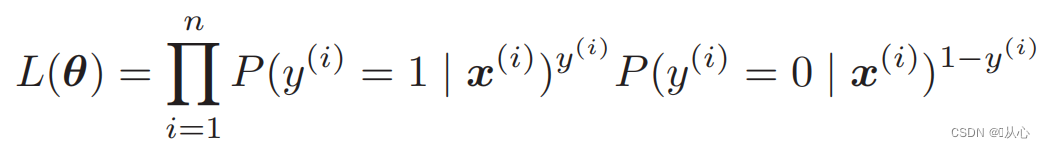
Munus probabilitatis Log: Difficile est munus directe differre verisimilitudinem, et logarithmus primo sumi debet.
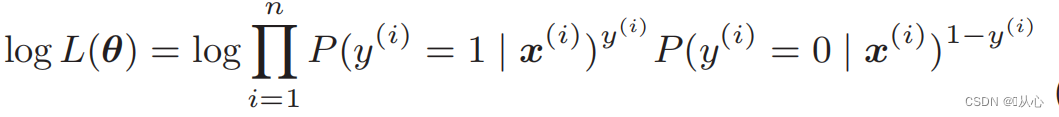
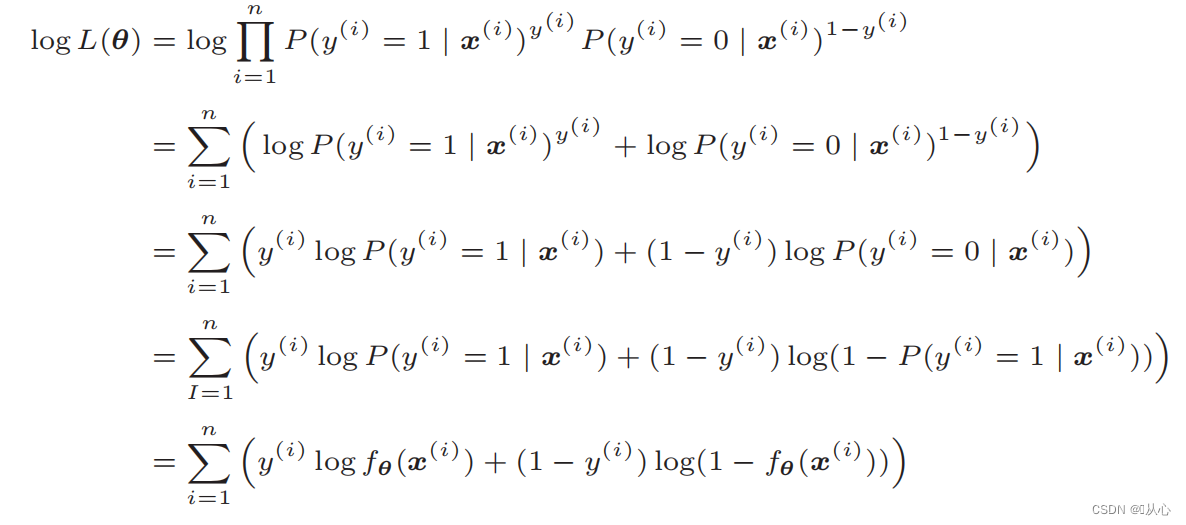
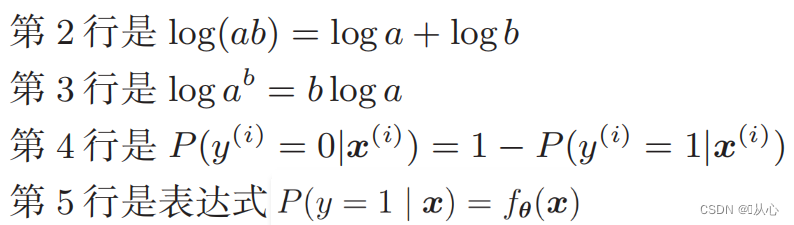
Post deformationem fit;
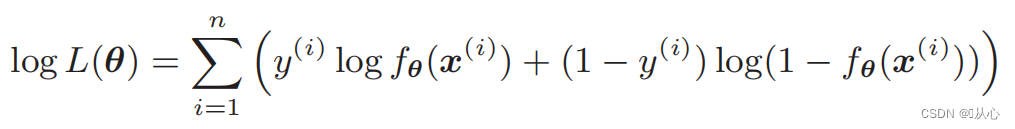
Distinctio probabilis functionis;
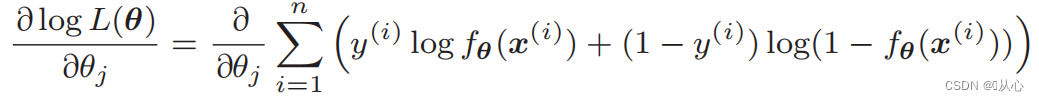
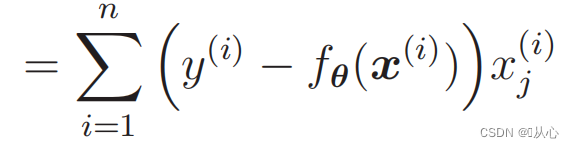
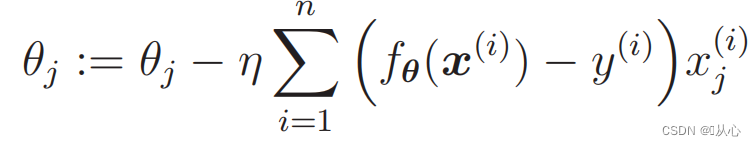
1. Simplex ad efficiendum: Regressio Logistica est algorithmus simplex qui facile est ad intelligendum et ad efficiendum.
2. Alta efficientia computationalis: Regressio Logistica relative parvam quantitatem calculi habet et ad notitias magnas magnas aptas est.
3. Fortis interpretabilitas: Proventus regressionis logisticae outputa sunt valores probabiles, qui intuitive explicari possunt emissionem exemplaris.
1. Separabilitas linearis requisita: Regressio Logistica exemplar est linearis et male agit pro quaestionibus separabilibus nonlinearibus.
2. Problema Feature ratione: Regressio Logistica magis sensitiva est ad relationem inter lineamenta initus. Cum valida relatio inter lineamenta datur, perficiendi exemplar declinare potest.
3. Problema overfitting: Cum nimis multae lineamenta specimen vel numerus exemplorum exiguus sit, regressio logistica propensior est ad problemata superflua.
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # 初始化参数
- theta=np.random.randn(3)
-
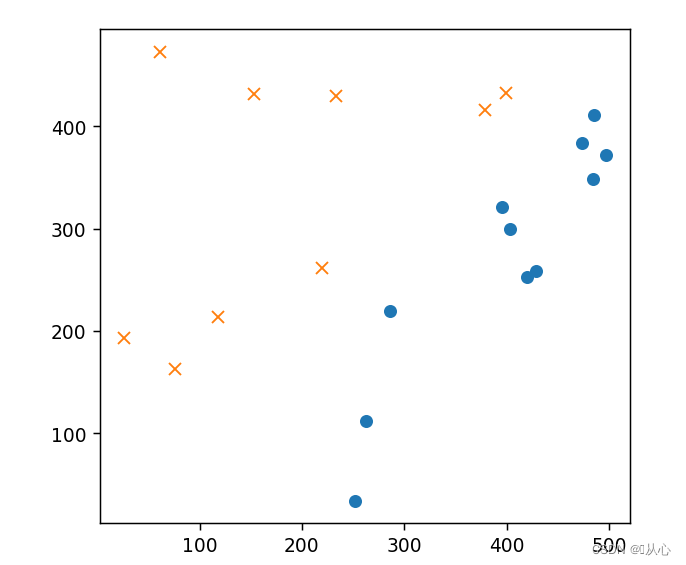
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
- # 绘图确认
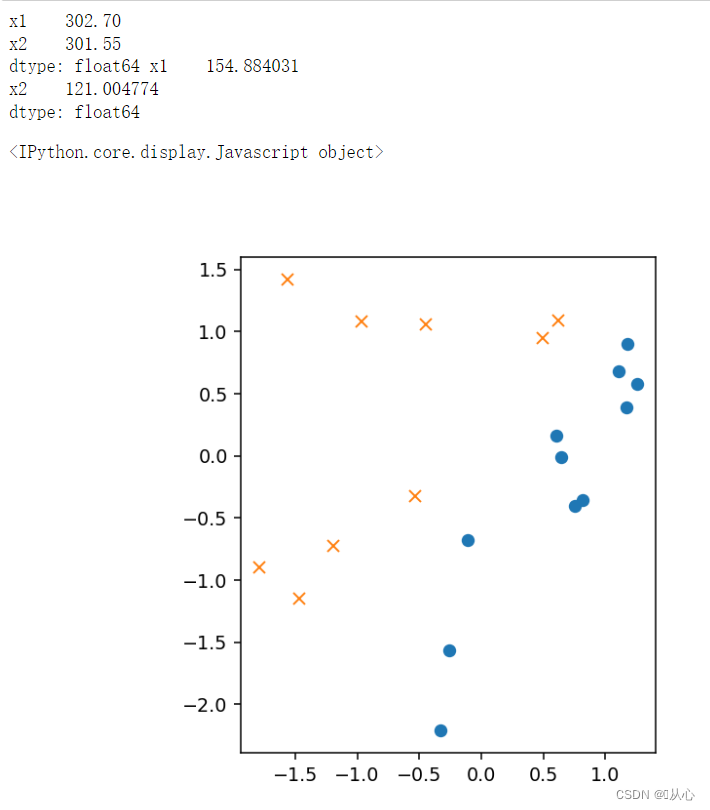
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
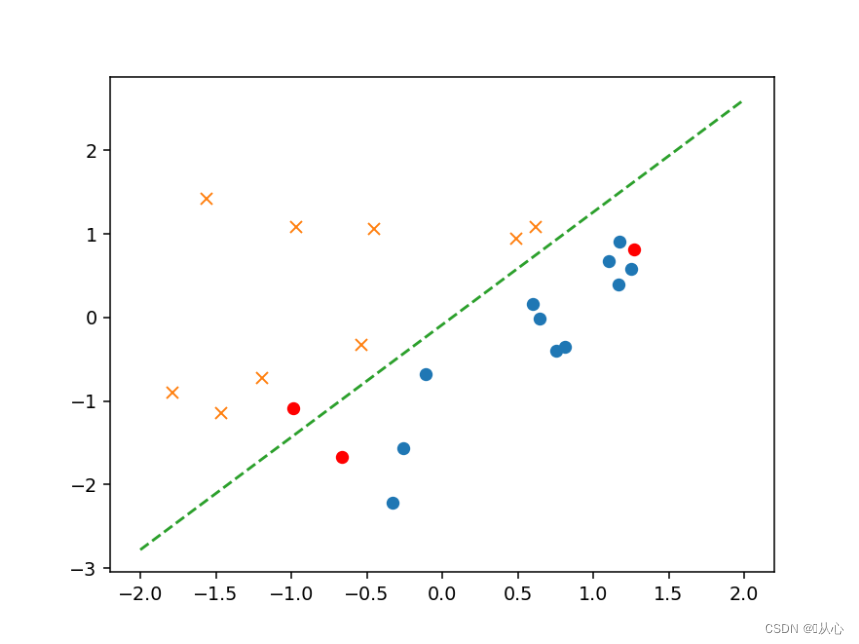
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
- # 键
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
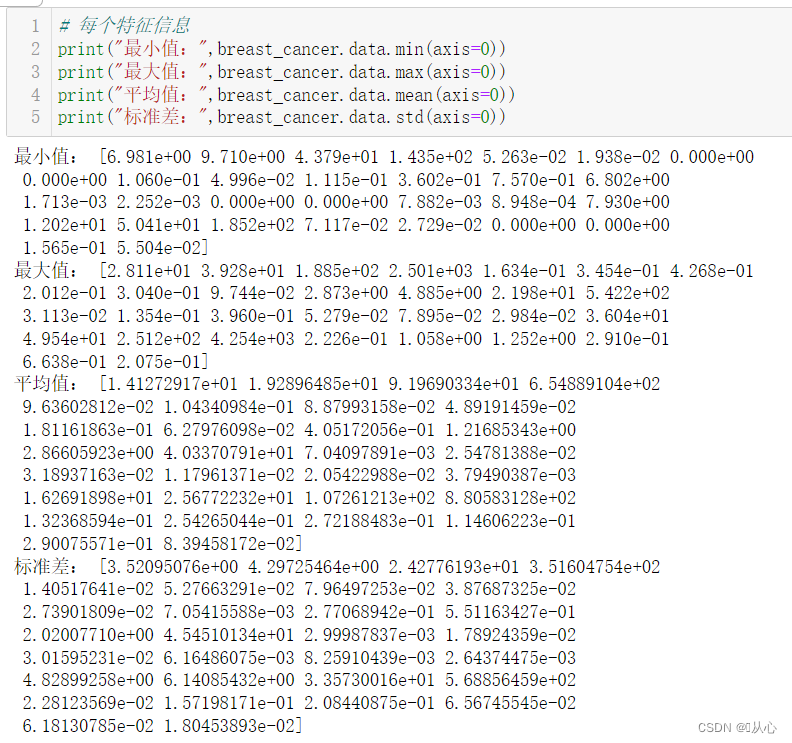
- # 每个特征信息
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
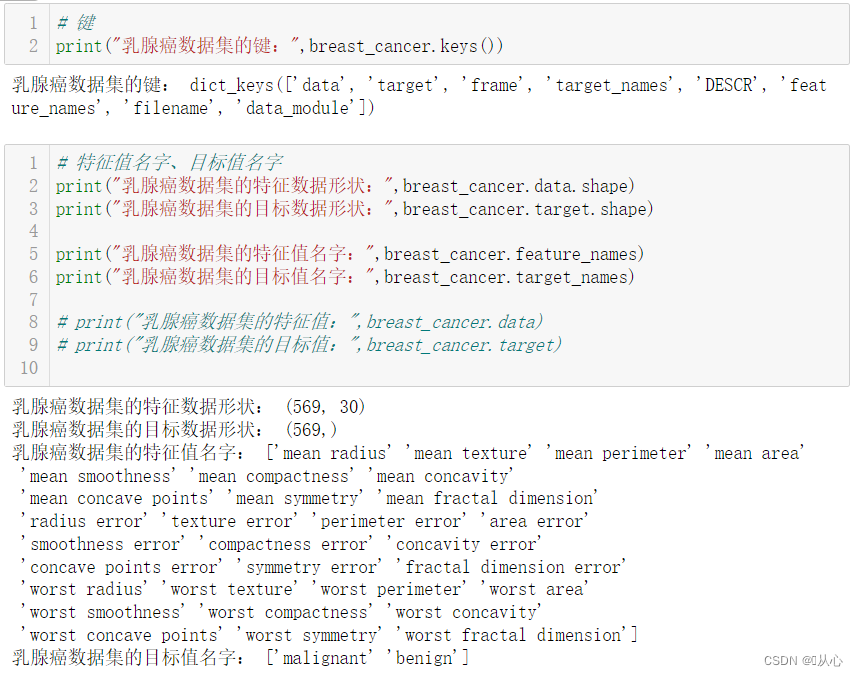
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
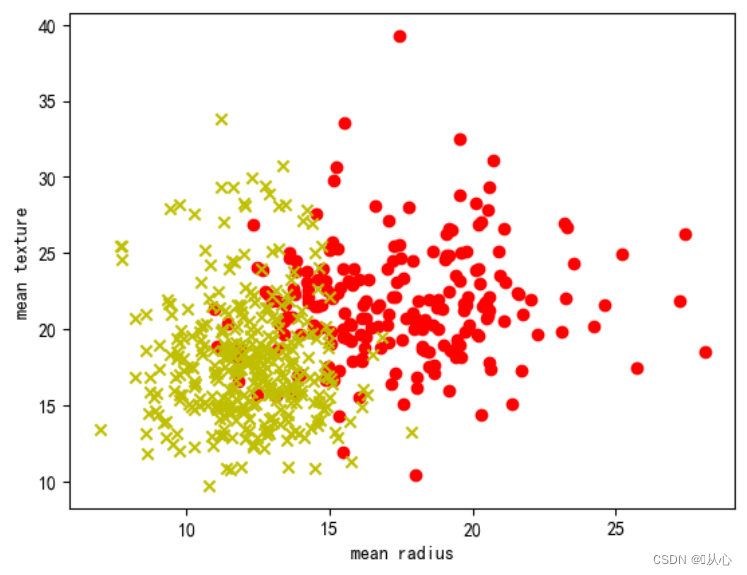
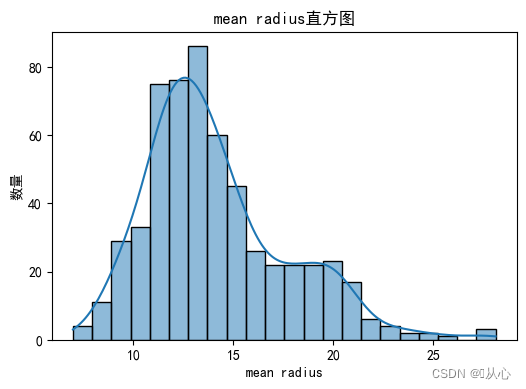
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
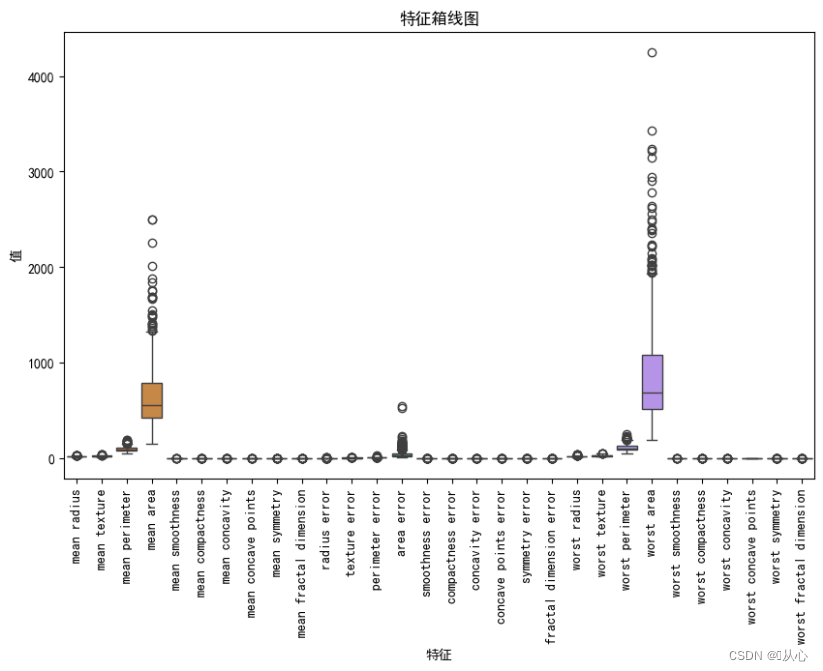
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
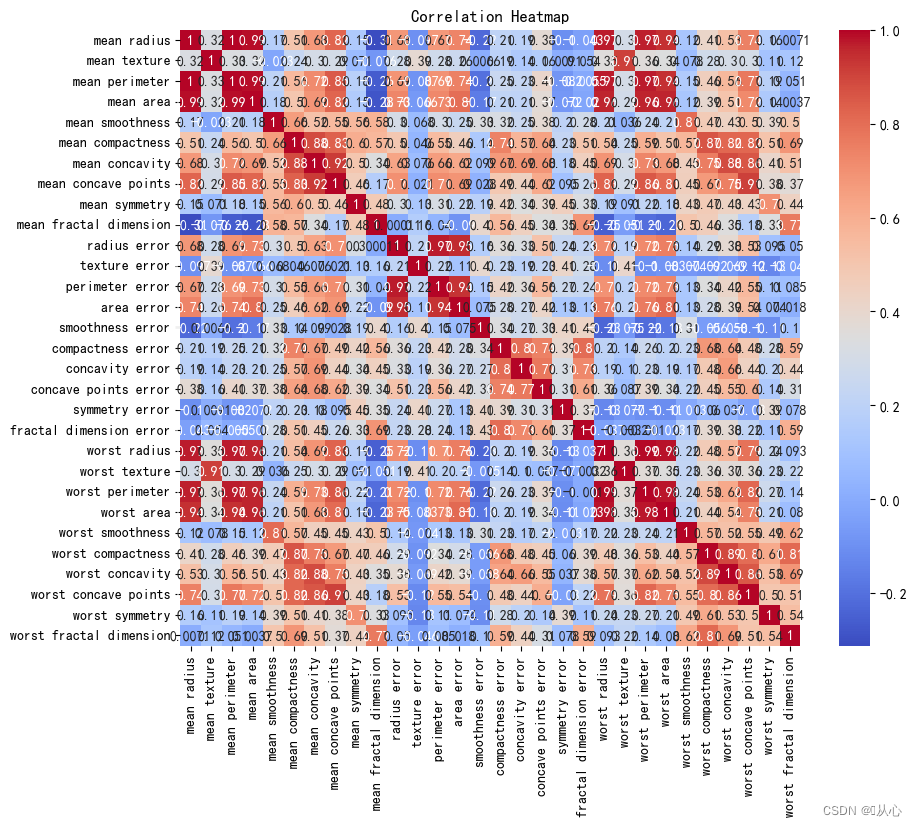
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 2、API
2、API- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
- print("建立的逻辑回归模型为:n", lr)

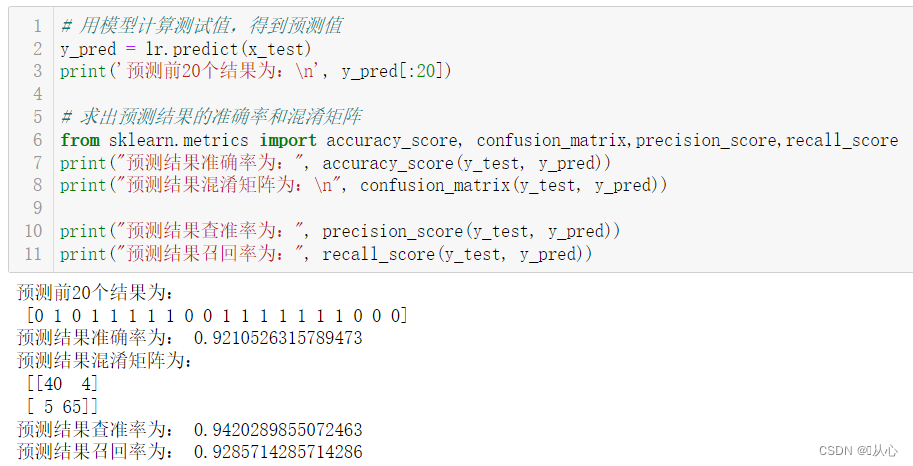
- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
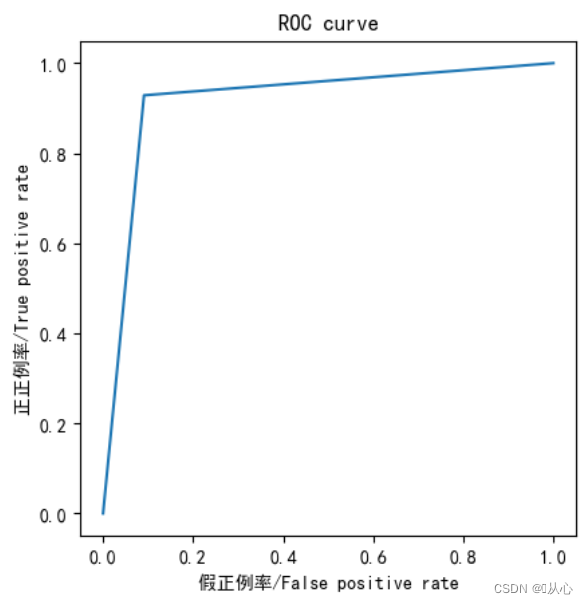
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

Exemplar, quod post exemplar perpensionis transit, substitui potest in valorem realem praenuntiationis.
Vetera somnia recreari possunt, videamus:Apparatus Discens (5) -- Supervised Learning (5)
Si vis scire quid deinde fiat, vultu vide;Apparatus Discens (5) -- Supervised Learning (7) --SVM1

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones in technologia progressus ad futuram referentiam
