내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
이전 기사:기계 학습(5) -- 지도 학습(5) -- 선형 회귀 2
다음 기사:기계 학습(5) -- 지도 학습(7) --SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
로지스틱 회귀 = 선형 회귀 + 시그모이드 함수
로지스틱 회귀(Logistic Regression)는 단순히 이진 데이터를 나누기 위해 직선을 찾는 것입니다.
특정 카테고리에 속하는 객체를 분류하여 이진 분류 문제를 해결합니다.확률값특정 카테고리에 속하는지 판단하기 위해 기본적으로 이 카테고리는 1(긍정 예시)로 표시되고, 다른 카테고리는 0(부정 예시)으로 표시됩니다.
실제로 이는 "모델 피팅 효과 확인"과 "모델 위치 각도 조정"에 사용되는 방법에 차이가 있는 선형 회귀 단계와 유사합니다.
입력 데이터를 0~1 사이에 매핑하려면 함수(시그모이드 함수)를 사용해야 하며, 함수 값이 0.5보다 크면 1로 판단하고, 그렇지 않으면 0으로 판단합니다. 이를 확률적 표현으로 변환할 수 있습니다.
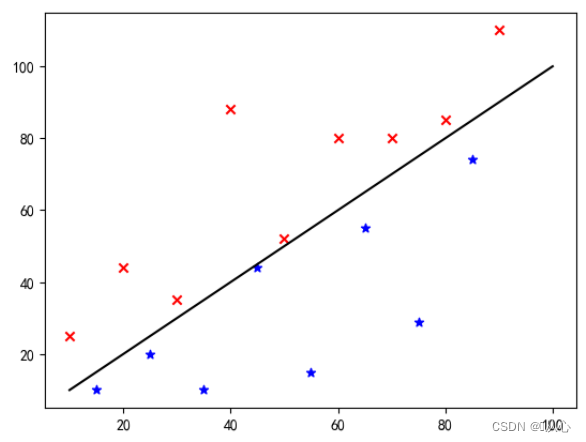
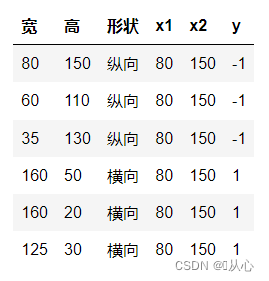
사진 분류를 예로 들어 사진을 세로와 가로로 나눕니다.
이것이 바로 이 데이터가 그래프에 표시되는 방식입니다. 그래프에서 서로 다른 색상(다른 범주)의 점을 구분하기 위해 이러한 선을 그립니다. 이 분류의 목적은 그러한 선을 찾는 것입니다.
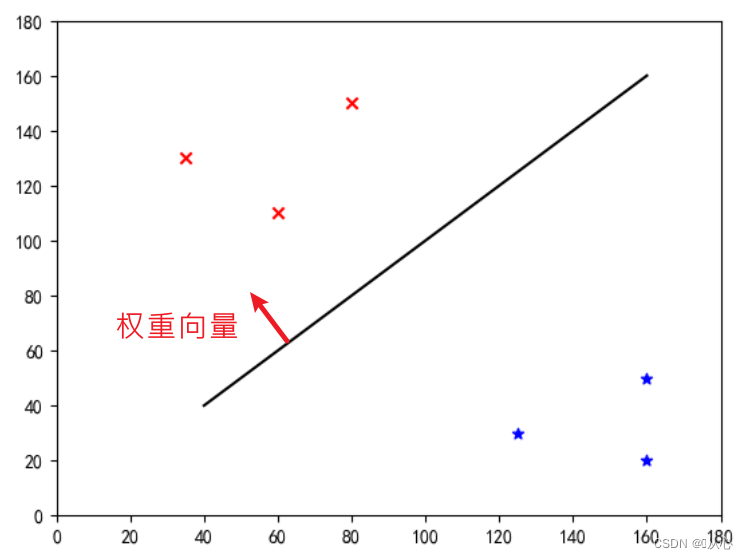
이것은 "가중치 벡터를 법선 벡터로 만드는 직선"입니다(가중치 벡터가 선에 수직이 되도록 합니다).
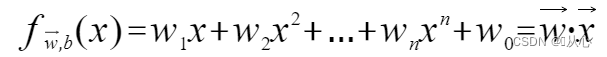
w는 가중 벡터이며 법선 벡터의 직선이 됩니다.
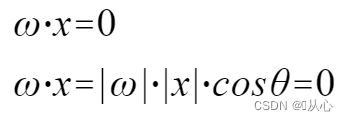
여러 값을 허용하고 각 값에 해당 가중치를 곱한 후 최종적으로 합계를 출력하는 모델입니다.
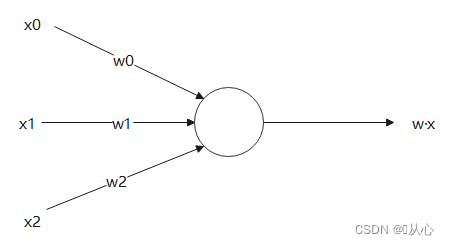
내적은 벡터 간의 유사도를 측정한 값으로, 양의 결과는 유사성을 나타내고, 0의 값은 수직성을 나타내며, 음의 결과는 비유사성을 나타냅니다.
사용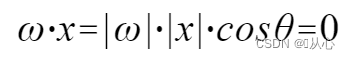 |w|와 |x|는 모두 양수이기 때문에 이해하기 쉽습니다. 따라서 내적의 부호는 cosθ에 의해 결정됩니다. 즉, 90도보다 작으면 비슷합니다. 90도보다 크면 서로 다릅니다.
|w|와 |x|는 모두 양수이기 때문에 이해하기 쉽습니다. 따라서 내적의 부호는 cosθ에 의해 결정됩니다. 즉, 90도보다 작으면 비슷합니다. 90도보다 크면 서로 다릅니다.
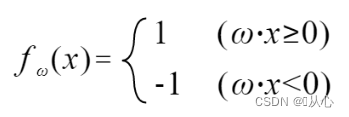
원래 레이블 값과 같으면 가중치 벡터가 업데이트되지 않습니다. 원래 레이블 값과 같지 않으면 벡터 추가를 사용하여 가중치 벡터를 업데이트합니다.
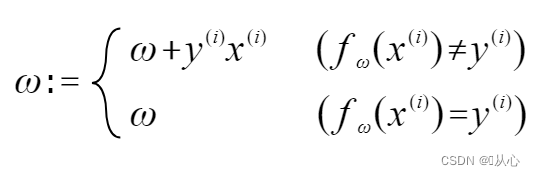
그림과 같이 원래 라벨과 동일하지 않은 경우
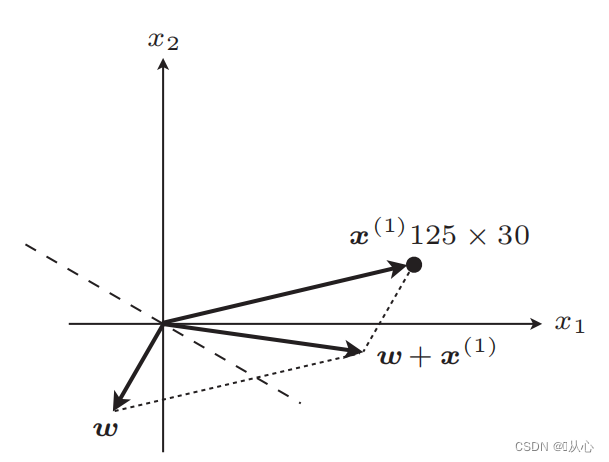
업데이트 후 직선
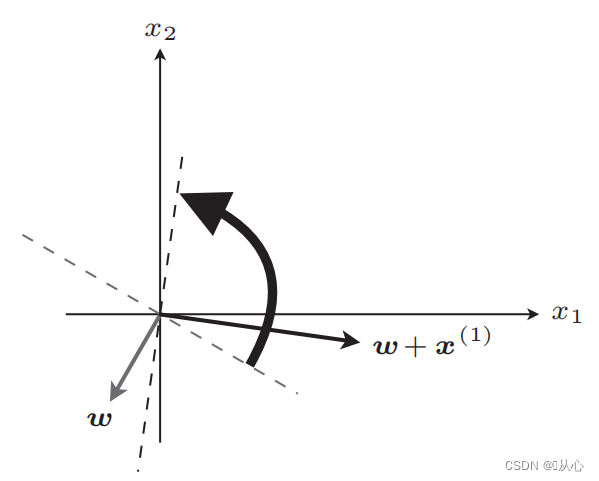
업데이트 후 동일
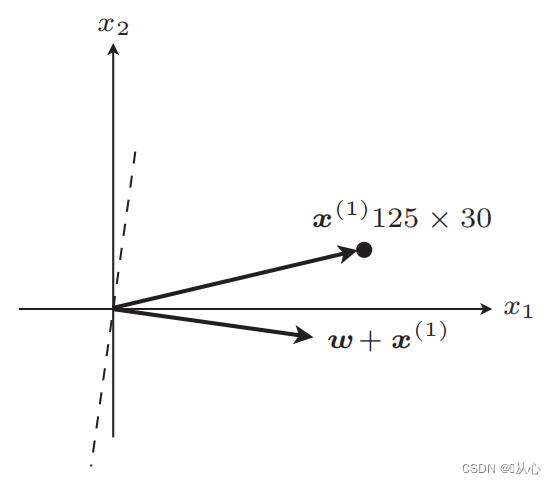
단계: 먼저 직선을 무작위로 결정(즉, 가중치 벡터 w를 무작위로 결정)하고, 실수값 데이터 x를 내적에 대입하고, 판별 함수를 통해 값(1 또는 -1)을 얻습니다. 원래 레이블 값에 대한 가중치 벡터는 업데이트되지 않습니다. 원래 레이블 값과 다른 경우 벡터 추가를 사용하여 가중치 벡터를 업데이트합니다.
! ! !참고: 퍼셉트론은 선형으로 분리 가능한 문제만 풀 수 있습니다.
선형 분리 가능: 직선을 사용하여 분류할 수 있는 경우
선형 비분리성: 직선으로 분류할 수 없음
검은색은 시그모이드 함수, 빨간색은 계단 함수(불연속)
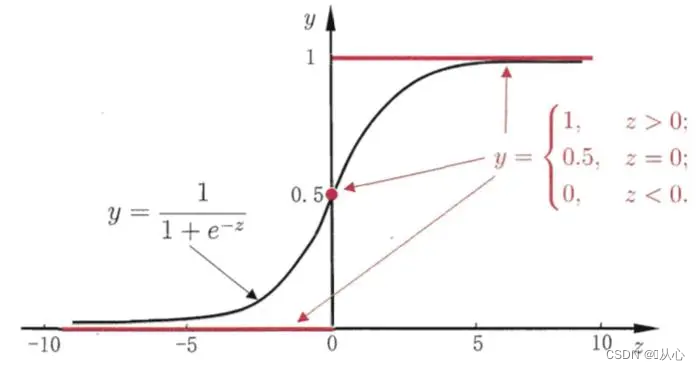
기능: 로지스틱 회귀의 입력은 선형 회귀의 결과입니다.선형 회귀에서 예측 값을 얻을 수 있습니다. Sigmoid 함수는 모든 입력을 [0,1] 간격으로 매핑하여 분류 작업인 값에서 확률로의 변환을 완료합니다.
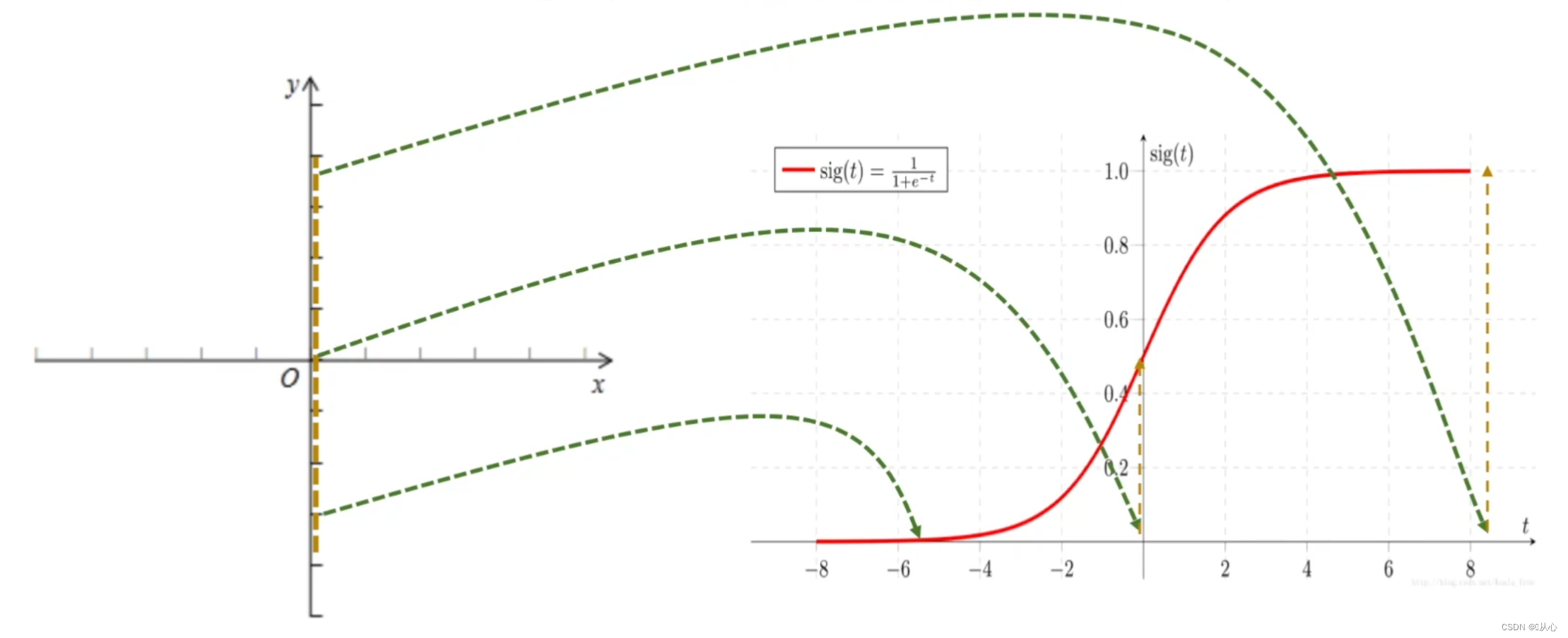
로지스틱 회귀 = 선형 회귀 + 시그모이드 함수
선형 회귀: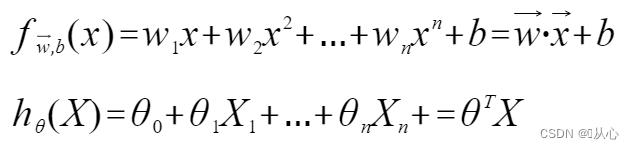
시그모이드 함수: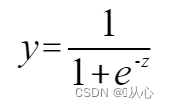
로지스틱 회귀: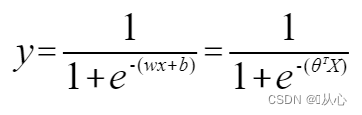
y가 레이블을 나타내도록 하려면 다음과 같이 변경하십시오.
확률을 계산하려면 다음을 사용하세요.
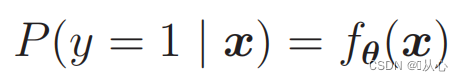
즉, 카테고리는 확률에 따라 구분될 수 있습니다.
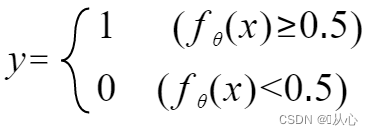
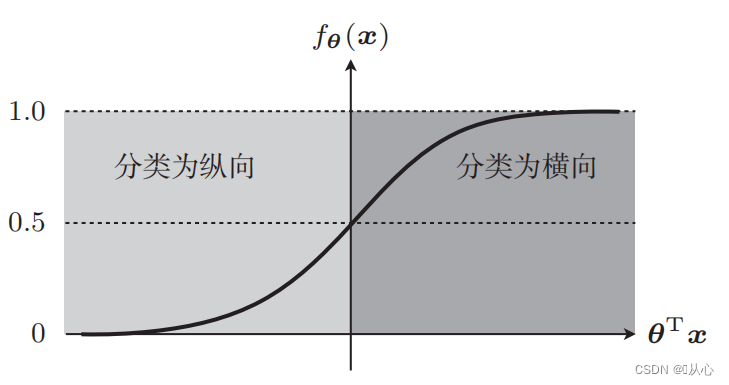
다음과 같이 다시 작성할 수 있습니다.
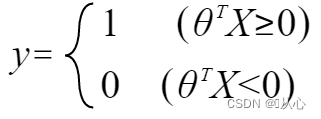
언제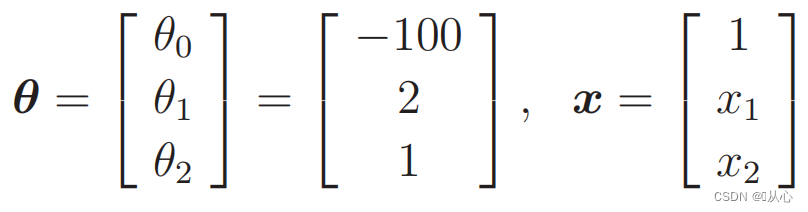
대체 데이터: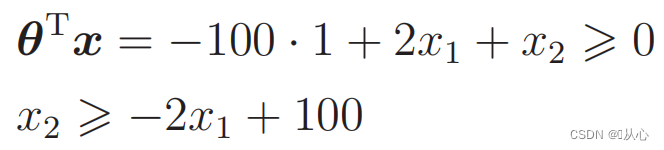
이런 사진이 있군요
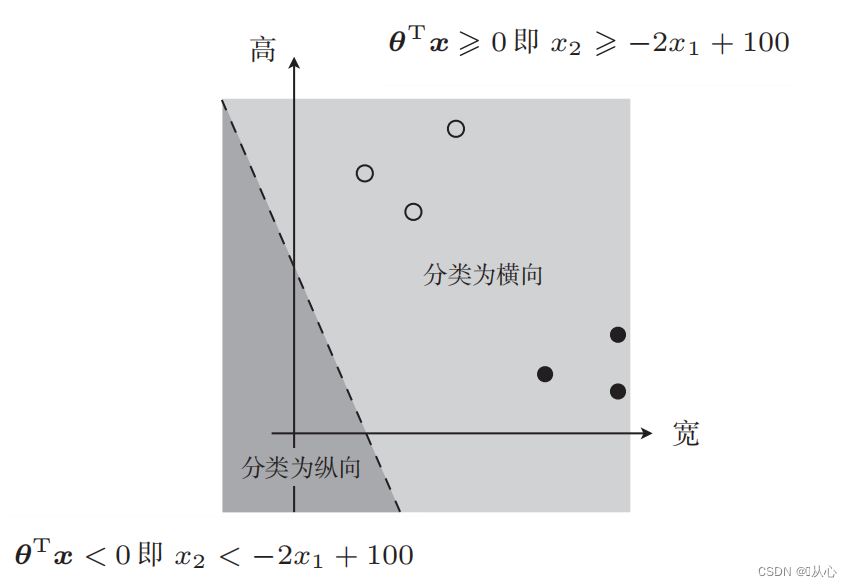 데이터 분류에 사용되는 직선이 의사결정 경계입니다.
데이터 분류에 사용되는 직선이 의사결정 경계입니다.
우리가 원하는 것은 이것이다:
y=1일 때 P(y=1|x)가 가장 큽니다.
y=0일 때 P(y=0|x)가 가장 큽니다.
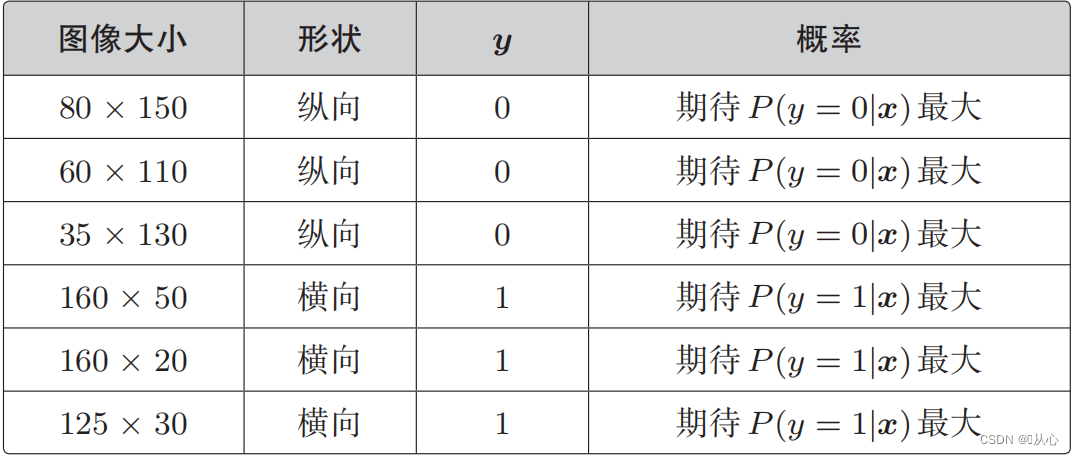
우도 함수(결합 확률): 여기에 우리가 최대화하려는 확률이 있습니다.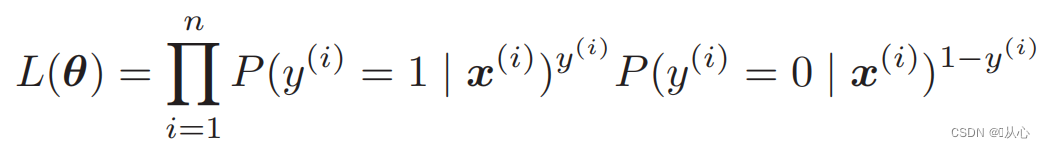
로그우도함수: 우도함수를 직접적으로 미분하기 어렵고 로그를 먼저 취해야 함
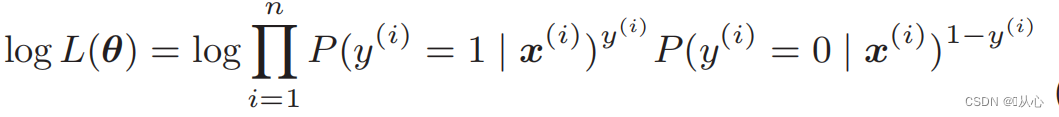
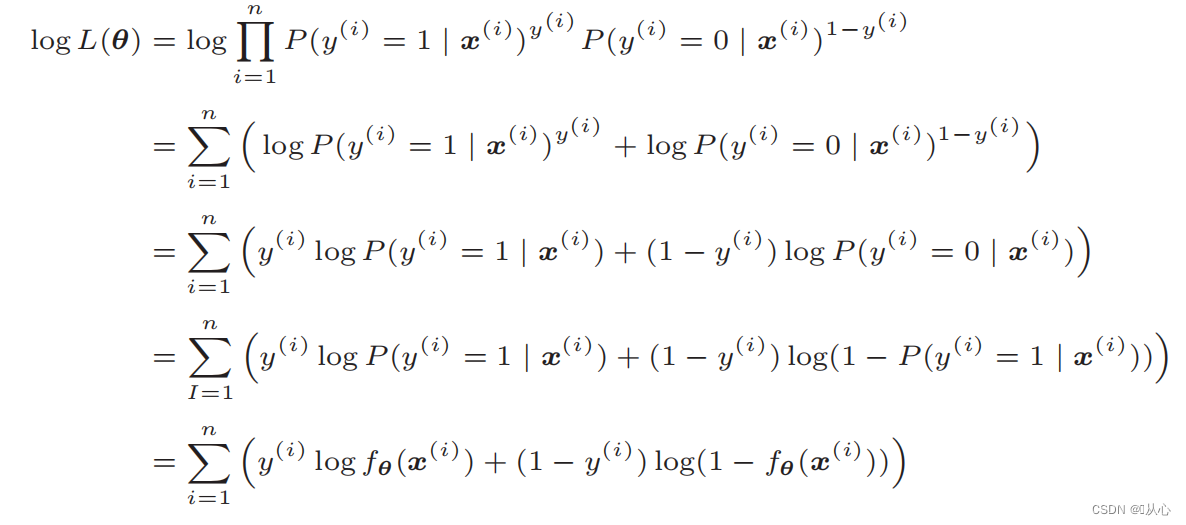
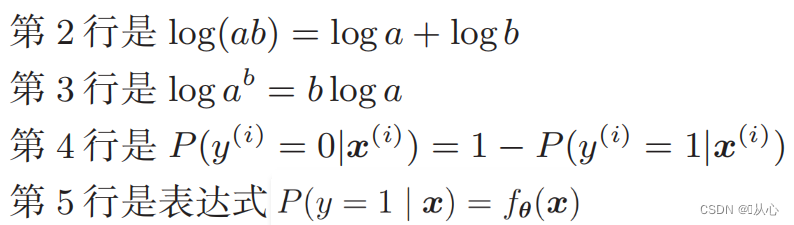
변형 후에는 다음과 같습니다.
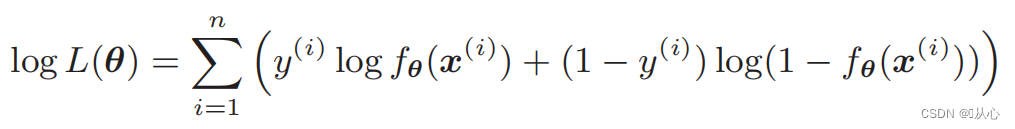
우도 함수의 미분:
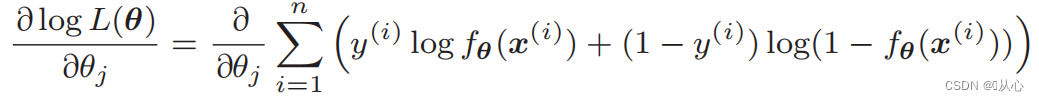
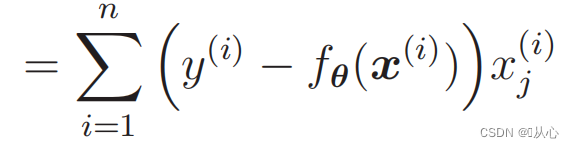
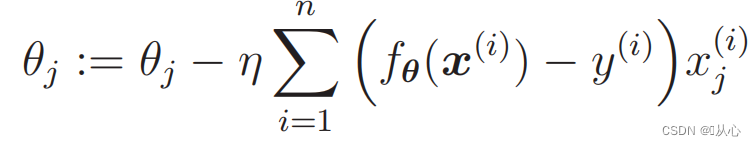
1. 구현이 간단함: 로지스틱 회귀는 이해하고 구현하기 쉬운 간단한 알고리즘입니다.
2. 높은 계산 효율성: 로지스틱 회귀는 계산량이 상대적으로 적고 대규모 데이터 세트에 적합합니다.
3. 강력한 해석성: 로지스틱 회귀의 출력 결과는 모델의 출력을 직관적으로 설명할 수 있는 확률 값입니다.
1. 선형 분리성 요구 사항: 로지스틱 회귀는 선형 모델이며 비선형 분리 가능 문제에 대해서는 제대로 수행되지 않습니다.
2. 특성 상관 문제: 로지스틱 회귀는 특성 간의 상관 관계에 더 민감하며, 특성 간에 강한 상관 관계가 있는 경우 모델 성능이 저하될 수 있습니다.
3. 과적합 문제: 표본 특징이 너무 많거나 표본 수가 적은 경우 로지스틱 회귀 분석에서 과적합 문제가 발생하기 쉽습니다.
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
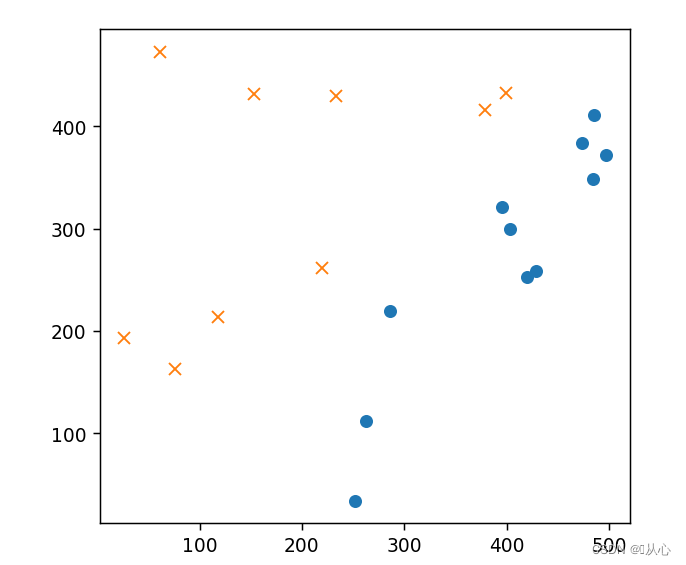
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # 初始化参数
- theta=np.random.randn(3)
-
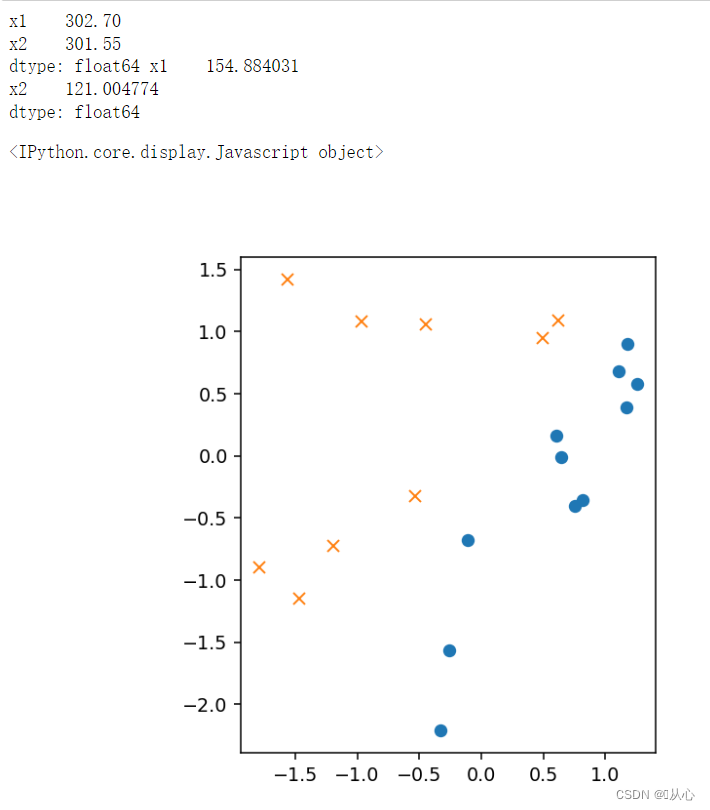
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
- # 绘图确认
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
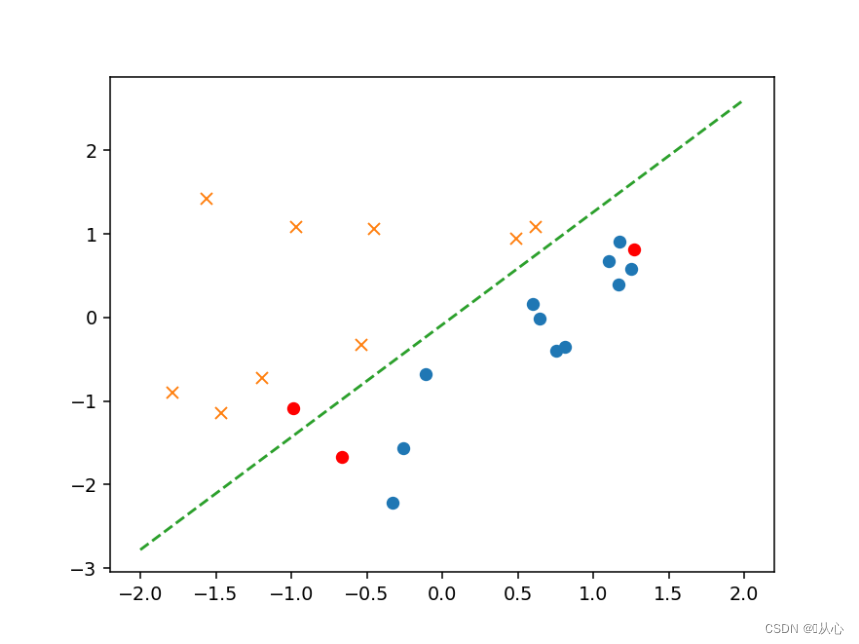
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
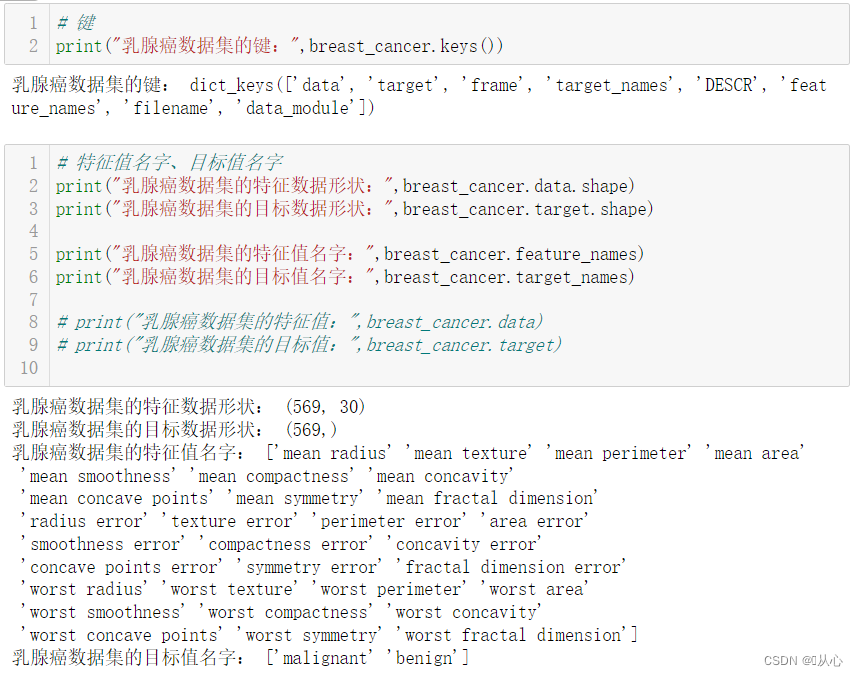
- # 键
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
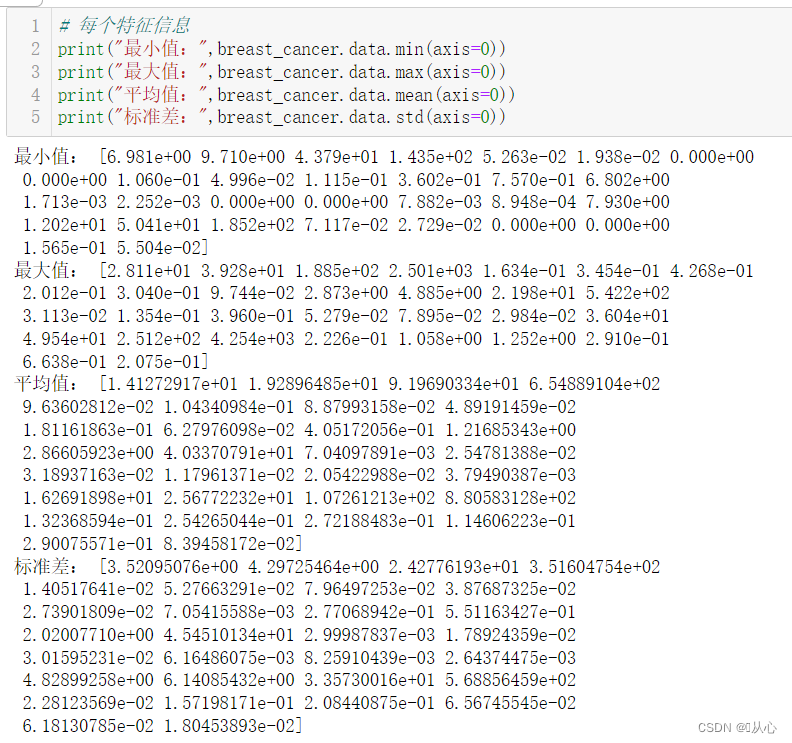
- # 每个特征信息
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
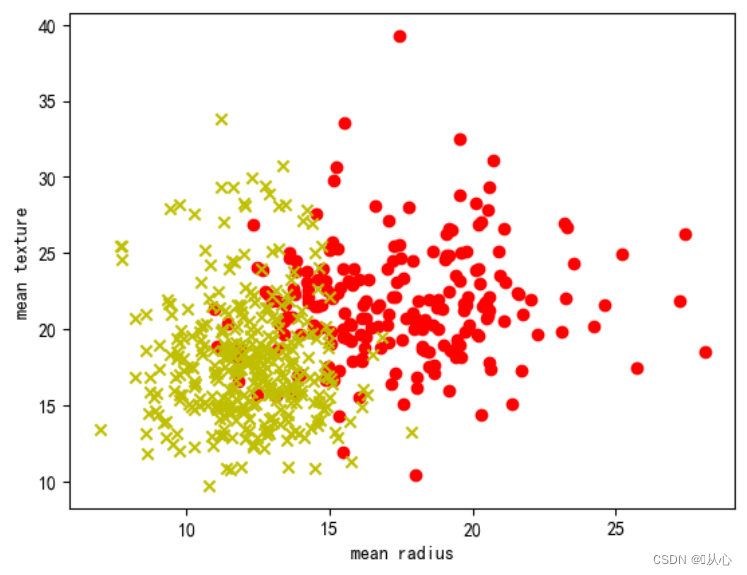
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
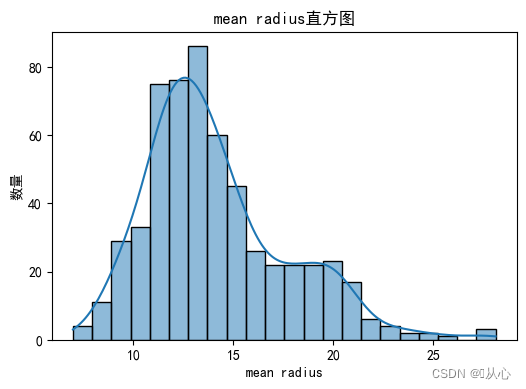
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
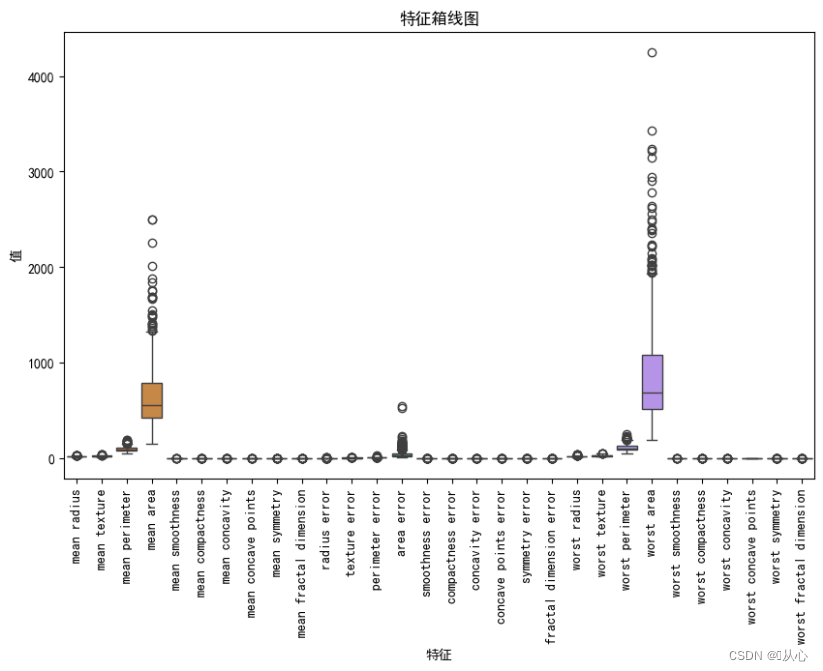
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
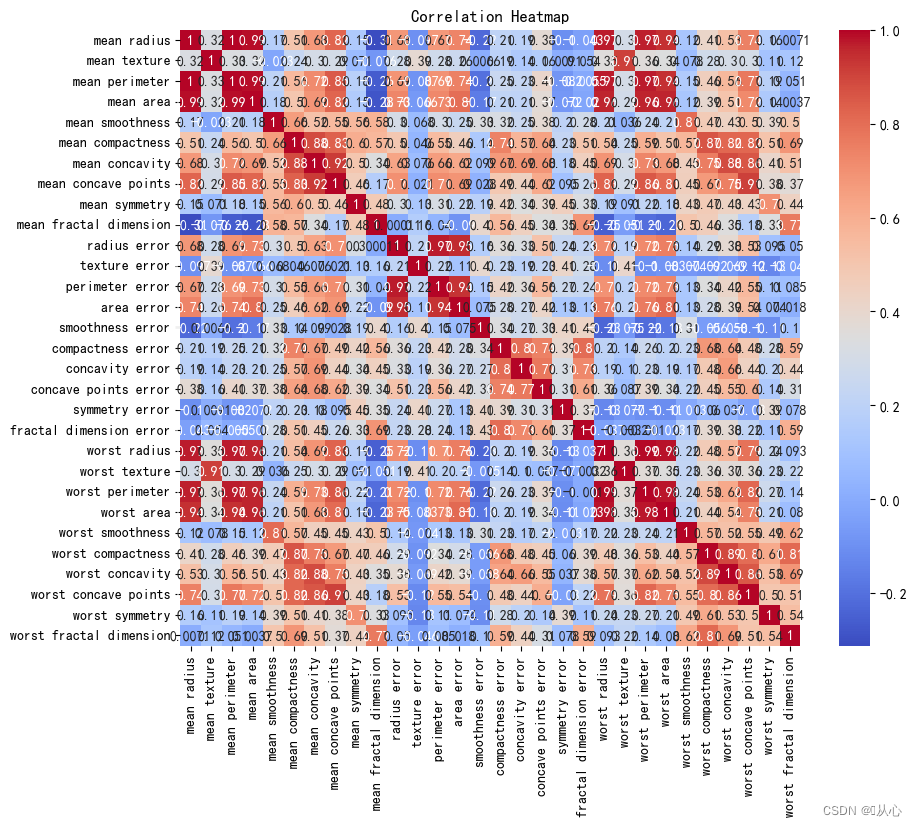
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 2、API
2、API- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
- print("建立的逻辑回归模型为:n", lr)

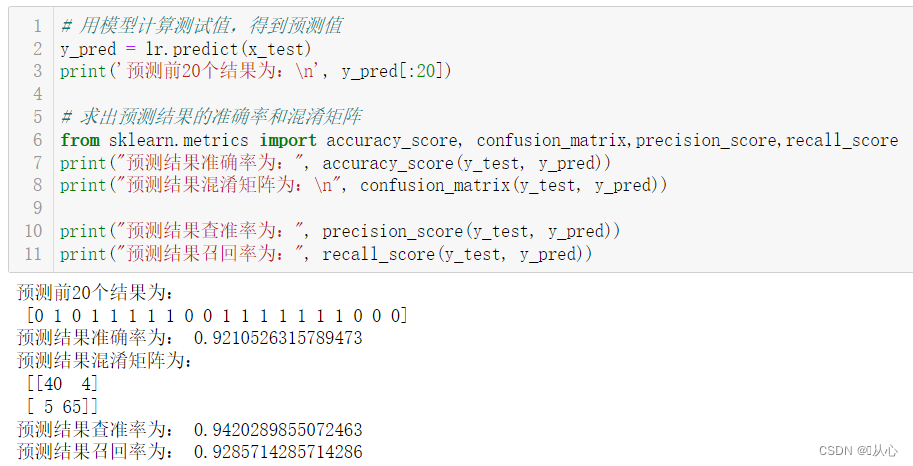
- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
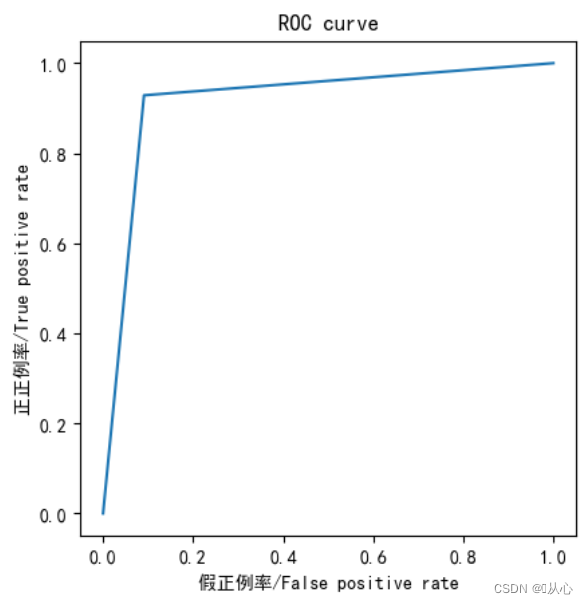
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

모델 평가 후 통과한 모델은 예측을 위한 실제 값으로 대체될 수 있습니다.
오래된 꿈은 다시 살아날 수 있습니다. 살펴보겠습니다:기계 학습(5) -- 지도 학습(5) -- 선형 회귀 2
다음에 무슨 일이 일어나는지 알고 싶다면 다음을 살펴보세요.기계 학습(5) -- 지도 학습(7) --SVM1

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에서 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com