2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
विषयसूची तथा लेखमालानां लिङ्कानि
पूर्वलेखः : १.यन्त्रशिक्षण (5) -- पर्यवेक्षितशिक्षण (5) -- रेखीय प्रतिगमन 2
अग्रिमः लेखः : १.यन्त्रशिक्षण (5) -- पर्यवेक्षितशिक्षण (7) --SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
लॉजिस्टिक रिग्रेशन = रेखीय प्रतिगमन + सिग्मोइड फंक्शन
Logistic regression (Logistic Regression) केवलं द्विचक्रीयदत्तांशस्य विभाजनार्थं सीधारेखां अन्वेष्टुं भवति ।
कस्यचित् वर्गस्य वस्तूनि वर्गीकृत्य द्विचक्रीयवर्गीकरणसमस्यायाः समाधानं कुर्वन्तुसंभाव्यता मूल्यकस्यचित् वर्गस्य अस्ति वा इति निर्धारयितुं अयं वर्गः पूर्वनिर्धारितरूपेण 1 (सकारात्मकं उदाहरणम्) इति चिह्नितः भवति, अन्यः वर्गः 0 (नकारात्मकोदाहरणम्) इति चिह्नितः भविष्यति
वस्तुतः एतत् रेखीयप्रतिगमनपदस्य सदृशम् अस्ति ।
भवद्भिः इनपुट्-दत्तांशं 0-1 मध्ये मैप् कर्तुं फंक्शन् (sigmoid function) इत्यस्य उपयोगः करणीयः, यदि च फंक्शन् मूल्यं 0.5 इत्यस्मात् अधिकं भवति तर्हि तत् 1 इति निर्णीयते, अन्यथा 0 इति एतत् संभाव्यतावादीप्रतिपादने परिणतुं शक्यते ।
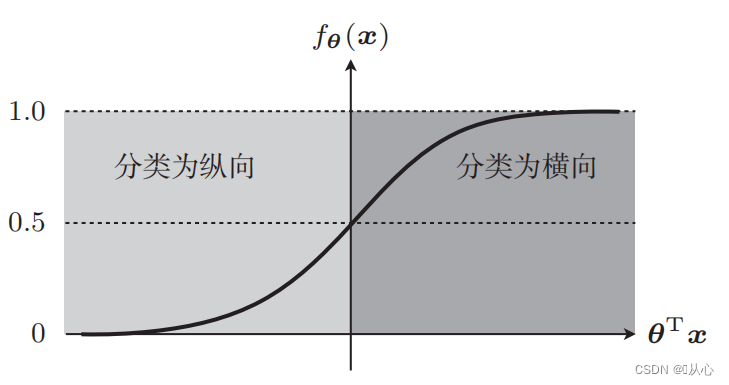
चित्रवर्गीकरणं उदाहरणरूपेण गृह्य चित्राणि लम्बवत् क्षैतिजं च विभजन्तु
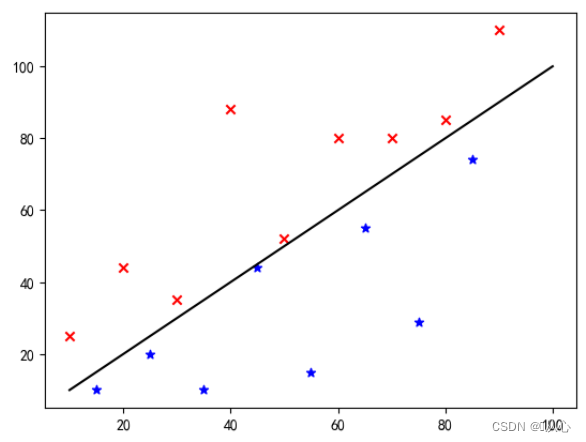
एतत् दत्तांशं आलेखे कथं प्रदर्शितं भवति आलेखे भिन्नवर्णानां (विभिन्नवर्गाणां) बिन्दून् पृथक् कर्तुं वयं तादृशीम् रेखां आकर्षयामः । अस्य वर्गीकरणस्य उद्देश्यं तादृशरेखायाः अन्वेषणम् अस्ति ।
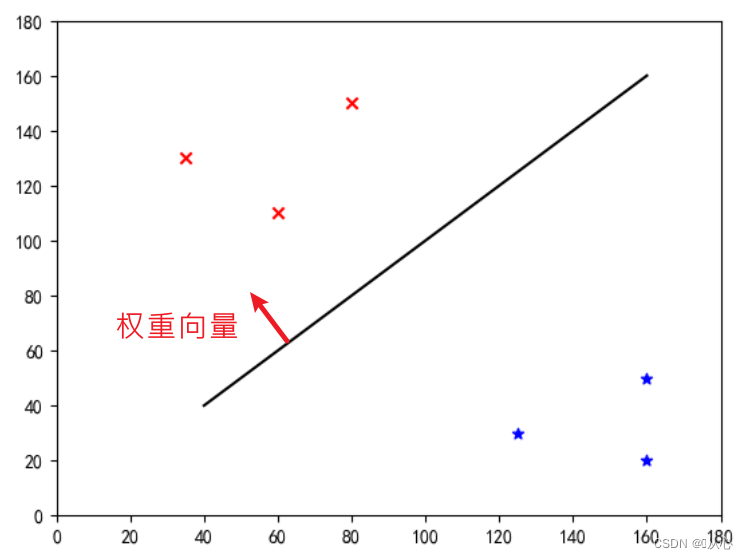
इयं "ऋजुरेखा या भारसदिशं सामान्यसदिशं करोति" (भारसदिशः रेखायाः लम्बः भवतु) ।
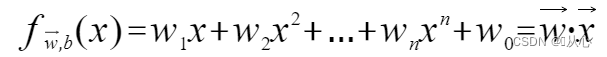
w इति भारसदिशः सामान्यसदिशस्य ऋजुरेखा भवति, अपि
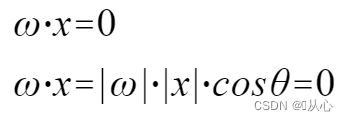
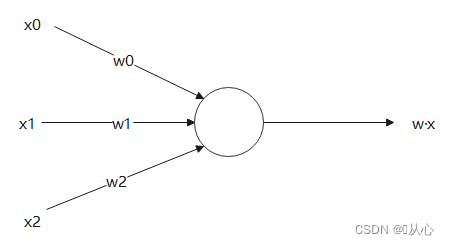
एकं प्रतिरूपं यत् बहुमूल्यानि स्वीकुर्वति, प्रत्येकं मूल्यं स्वस्वभारेन गुणयति, अन्ते च योगं निर्गच्छति ।
आन्तरिकं उत्पादं सदिशयोः साम्यस्य प्रमाणस्य मापः भवति सकारात्मकं परिणामं समानतां सूचयति, 0 मूल्यं लम्बताम् सूचयति, ऋणात्मकं परिणामं च असमानतां सूचयति
उपयुञ्जताम्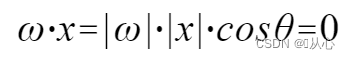 अवगन्तुं श्रेयस्करम्, यतः |w|., |x| ९० अंशः इति विषमः इत्यर्थः
अवगन्तुं श्रेयस्करम्, यतः |w|., |x| ९० अंशः इति विषमः इत्यर्थः
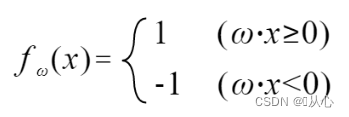
यदि मूललेबलमूल्येन समानं भवति तर्हि भारसदिशः अद्यतनं न भविष्यति यदि मूललेबलमूल्येन समानं न भवति तर्हि भारसदिशस्य अद्यतनीकरणाय सदिशसंयोजनस्य उपयोगः भविष्यति ।
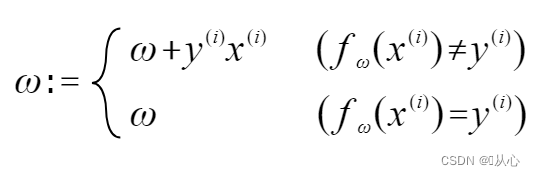
यथा चित्रे दर्शितं, यदि मूललेबलस्य समं न भवति तर्हि
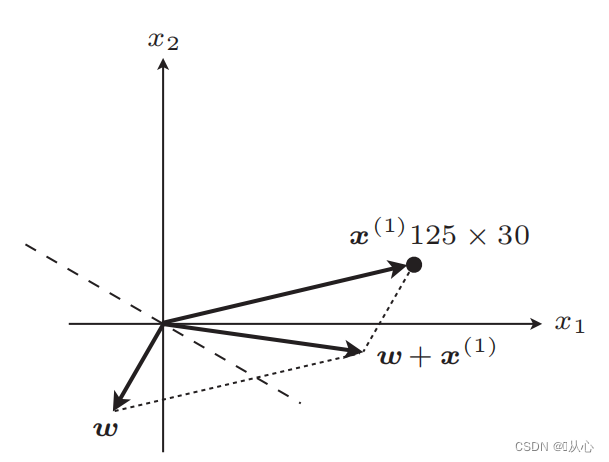
अद्यतनस्य अनन्तरं सीधी रेखा
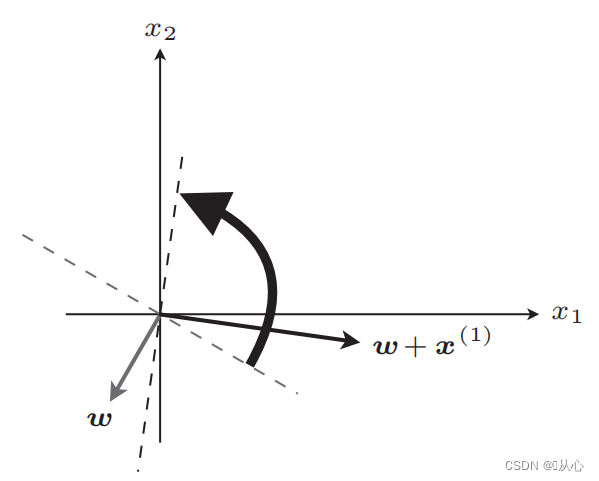
अद्यतनस्य अनन्तरं समानम्
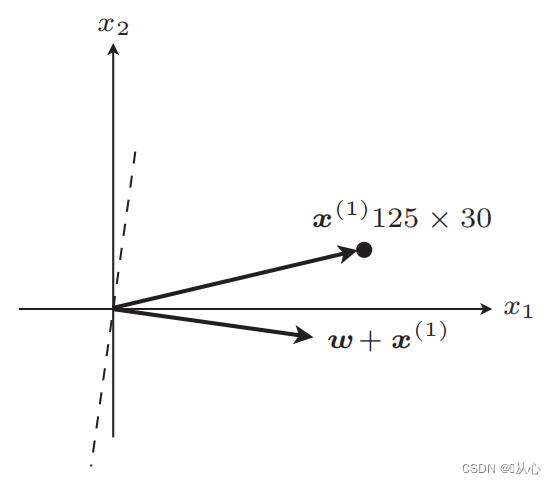
चरणाः : प्रथमं यादृच्छिकरूपेण एकां सीधारेखां निर्धारयन्तु (अर्थात् यादृच्छिकरूपेण भारसदिशं w निर्धारयन्तु), आन्तरिकं उत्पादं वास्तविकमूल्यदत्तांशं x प्रतिस्थापयन्तु, तथा च विवेकशीलफलनस्य माध्यमेन मूल्यं (1 अथवा -1) प्राप्नुवन्तु मूललेबलमूल्यं प्रति, भारसदिशः Update नास्ति, यदि मूललेबलमूल्यात् भिन्नः अस्ति तर्हि भारसदिशं अद्यतनीकर्तुं सदिशसंयोजनस्य उपयोगं कुर्वन्तु ।
! ! !नोटः- परसेप्ट्रॉन् केवलं रेखीयरूपेण पृथक्करणीयसमस्यानां समाधानं कर्तुं शक्नोति
रेखीयरूपेण पृथक्करणीयम् : एतादृशाः प्रकरणाः यत्र वर्गीकरणार्थं ऋजुरेखाः उपयोक्तुं शक्यन्ते
रेखीय अविभाज्यता : ऋजुरेखाभिः वर्गीकरणं कर्तुं न शक्यते
कृष्णं सिग्मोइड् कार्यं, रक्तं सोपानं (असंततम्)
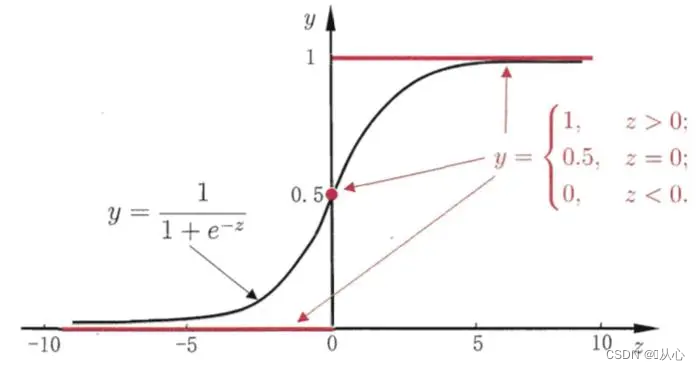
कार्यम् : लॉजिस्टिक प्रतिगमनस्य निवेशः रेखीयप्रतिगमनस्य परिणामः भवति ।वयं रेखीयप्रतिगमने पूर्वानुमानितं मूल्यं प्राप्तुं शक्नुमः सिग्मोइड् फंक्शन् [0,1] अन्तरालस्य कृते किमपि इनपुट् मैप् करोति, अतः मूल्यात् संभाव्यतायां परिवर्तनं सम्पन्नं करोति, यत् वर्गीकरणकार्यम् अस्ति
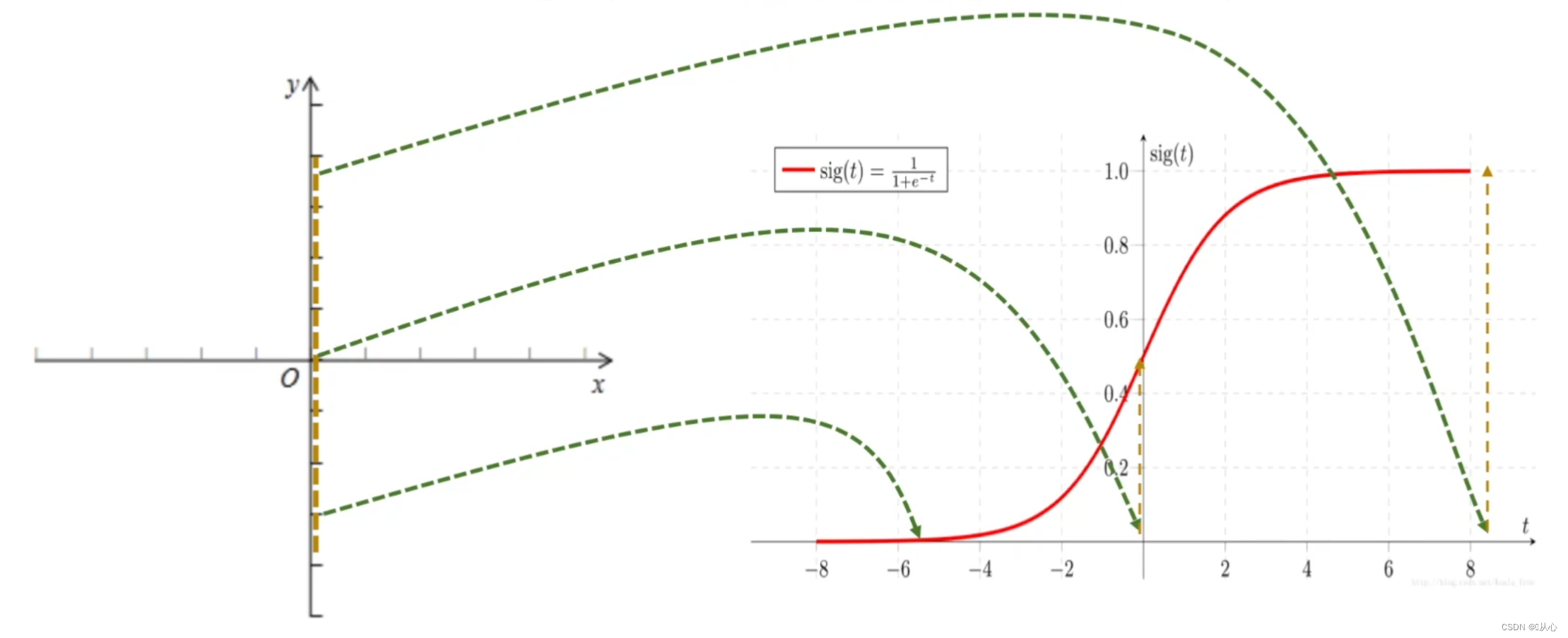
लॉजिस्टिक रिग्रेशन = रेखीय प्रतिगमन + सिग्मोइड फंक्शन
रेखीय प्रतिगमन : १.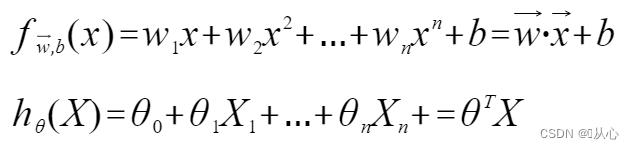
सिग्मोइड कार्य : १.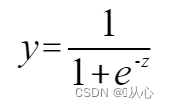
लॉजिस्टिक रिग्रेशन : १.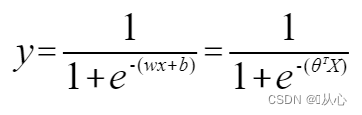
y इत्यनेन लेबलस्य प्रतिनिधित्वं कर्तुं, तत् परिवर्तयन्तु:
संभाव्यताः कर्तुं प्रयोगं कुर्वन्तु : १.
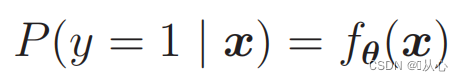
संभाव्यतया वर्गाणां भेदः कर्तुं शक्यते इति यावत्
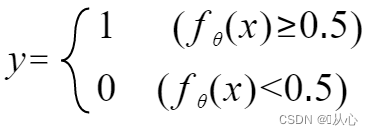
पुनः लिखितुं शक्यते यथा - १.
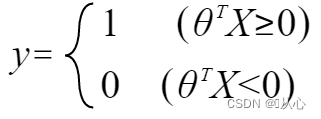
कदा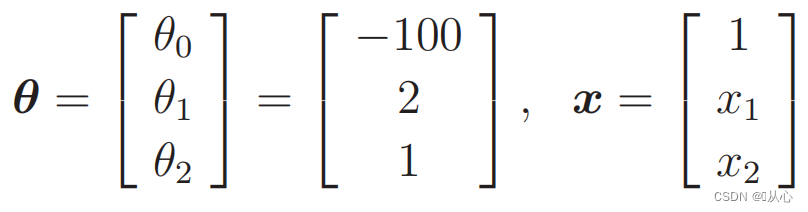
प्रतिस्थापनदत्तांशः : १.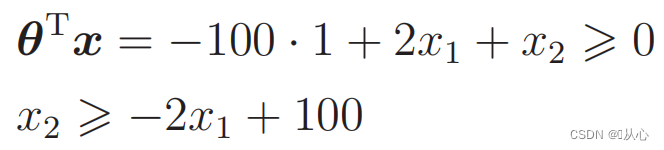
तत्र तादृशं चित्रम् अस्ति
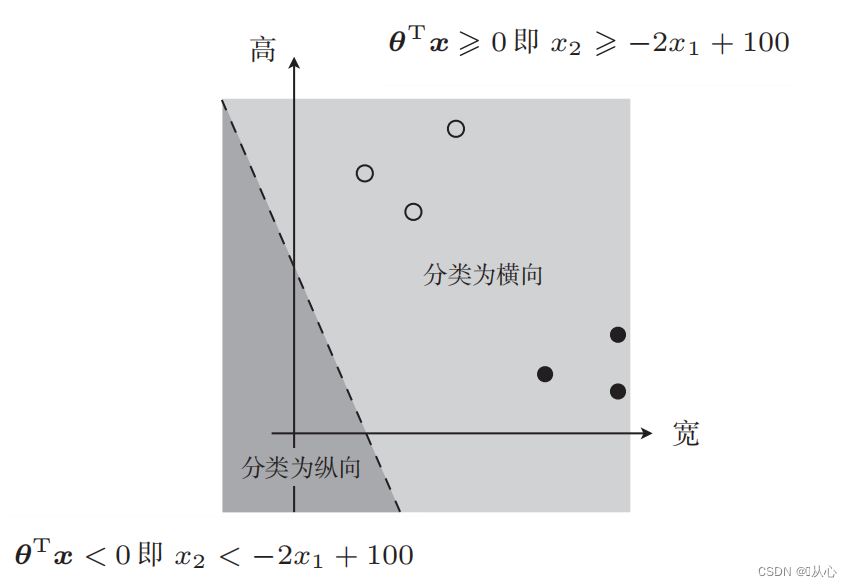 दत्तांशवर्गीकरणाय प्रयुक्ता ऋजुरेखा निर्णयसीमा अस्ति
दत्तांशवर्गीकरणाय प्रयुक्ता ऋजुरेखा निर्णयसीमा अस्ति
वयं यत् इच्छामः तत् अस्ति यत् -
यदा y=1, तदा P(y=1|x) बृहत्तमः भवति
यदा y=0, तदा P(y=0|x) बृहत्तमः भवति
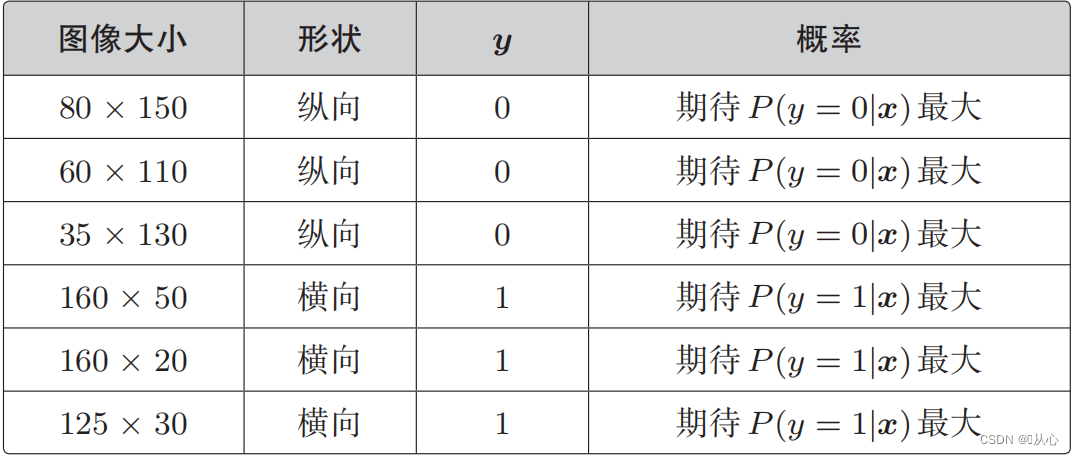
Likelihood function (joint probability): अत्र वयं अधिकतमं कर्तुम् इच्छामः संभाव्यता अस्ति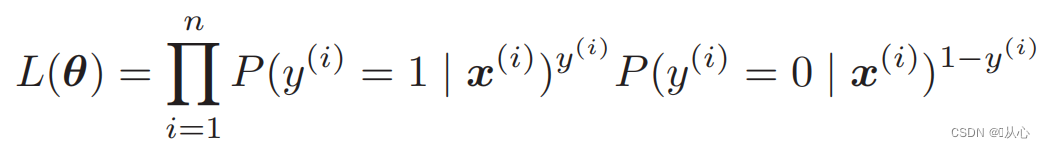
Log likelihood function: likelihood function इत्यस्य प्रत्यक्षतया भेदः कठिनः भवति, तथा च प्रथमं लघुगणकं ग्रहीतुं आवश्यकम् अस्ति
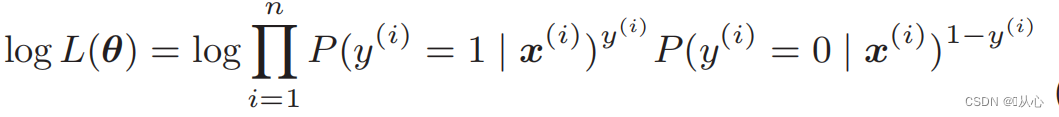
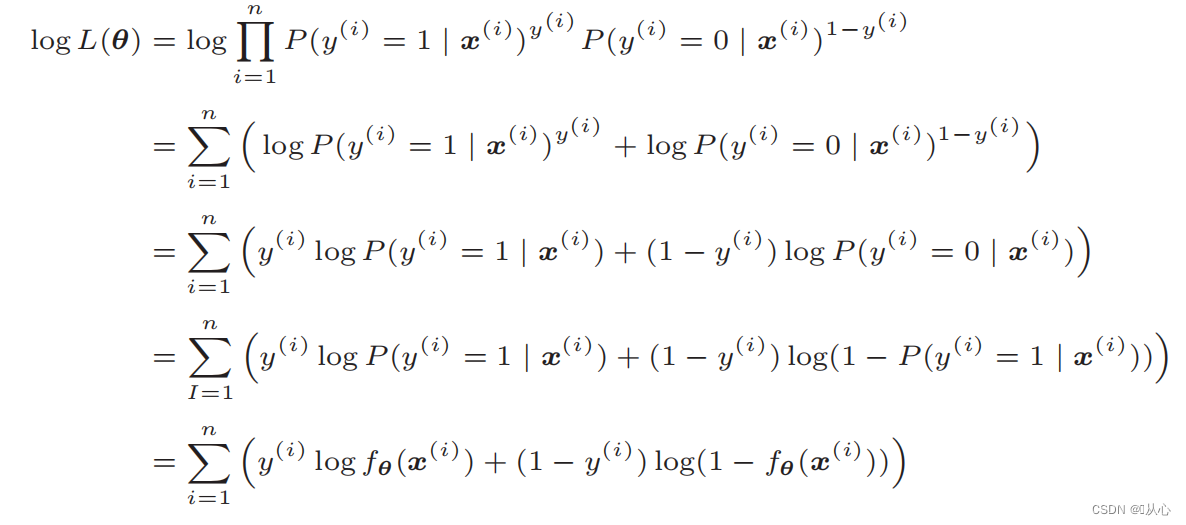
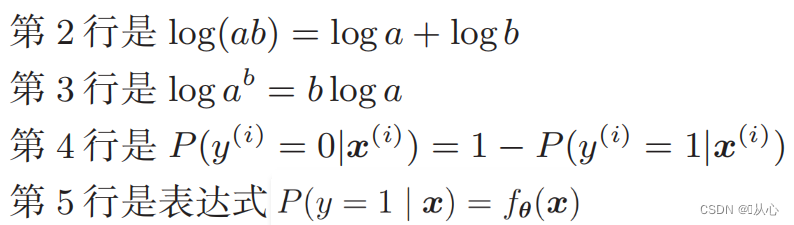
विकृतेः अनन्तरं भवति- १.
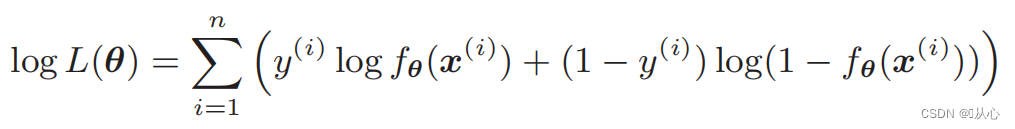
संभावनाकार्यस्य भेदः : १.
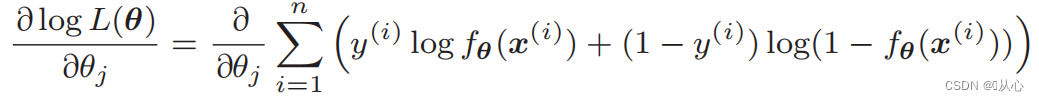
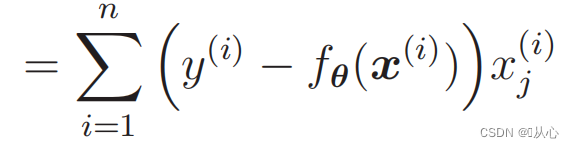
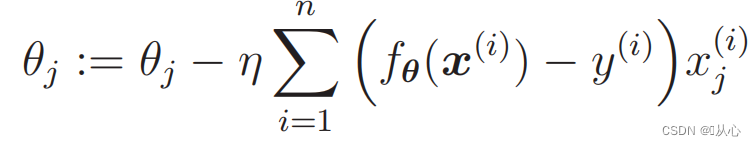
1. कार्यान्वयनार्थं सरलम् : लॉजिस्टिक रिग्रेशनः एकः सरलः एल्गोरिदम् अस्ति यस्य अवगमनं कार्यान्वयनञ्च सुलभम् अस्ति ।
2. उच्चगणनादक्षता : लॉजिस्टिक रिग्रेशनस्य गणनायाः अपेक्षाकृतं अल्पं भवति तथा च बृहत्-परिमाणस्य आँकडा-समूहानां कृते उपयुक्तम् अस्ति ।
3. दृढव्याख्याक्षमता : लॉजिस्टिक प्रतिगमनस्य उत्पादनपरिणामाः संभाव्यतामूल्यानि सन्ति, ये सहजतया प्रतिरूपस्य उत्पादनं व्याख्यातुं शक्नुवन्ति।
1. रेखीयपृथक्करणस्य आवश्यकताः : लॉजिस्टिक प्रतिगमनं रेखीयप्रतिरूपं भवति तथा च अरैखिकपृथक्करणसमस्यानां कृते दुर्बलं कार्यं करोति।
2. विशेषतासहसंबन्धसमस्या : लॉजिस्टिकप्रतिगमनं निवेशविशेषतानां मध्ये सहसंबन्धस्य प्रति अधिकं संवेदनशीलं भवति यदा विशेषतानां मध्ये प्रबलः सहसंबन्धः भवति तदा तस्य कारणेन मॉडलस्य कार्यक्षमतायाः न्यूनता भवितुम् अर्हति
3. अतिफिटिंग समस्या : यदा अत्यधिकं नमूनाविशेषताः सन्ति अथवा नमूनानां संख्या अल्पा भवति तदा लॉजिस्टिक रिग्रेशन ओवरफिटिंग समस्यां प्रति प्रवृत्ता भवति।
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
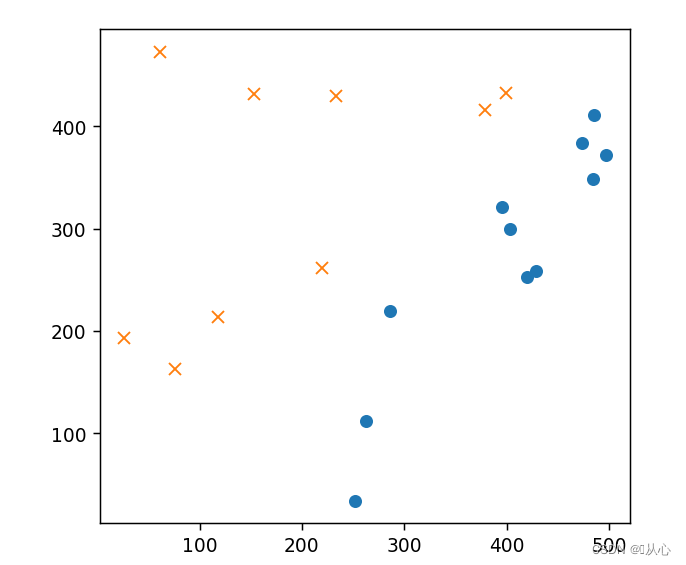
- # 初始化参数
- theta=np.random.randn(3)
-
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
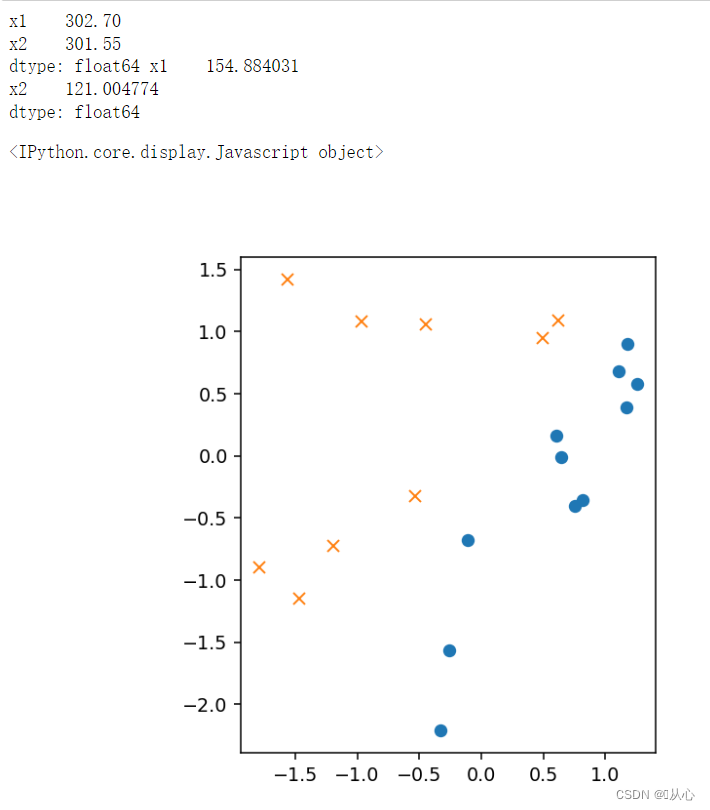
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
- # 绘图确认
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
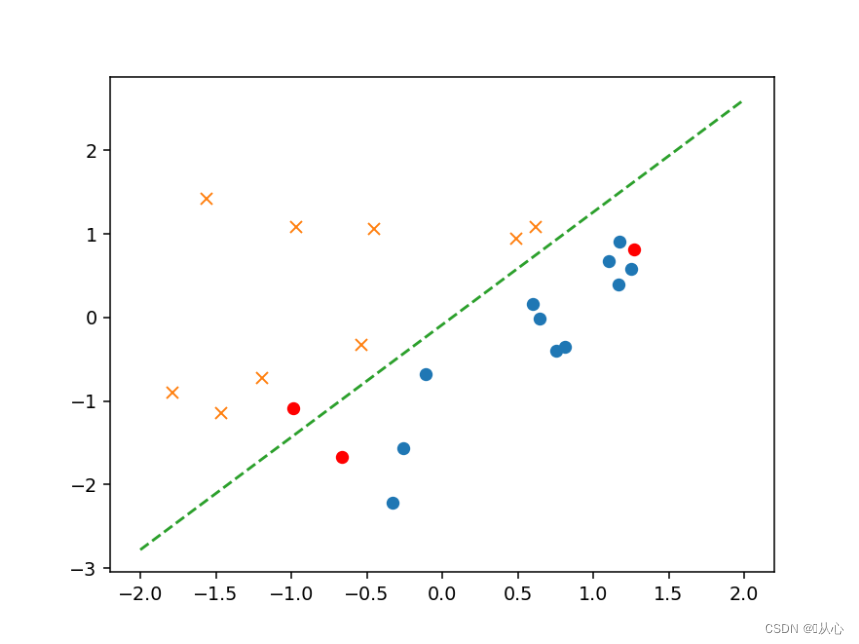
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
- # 键
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
- # 每个特征信息
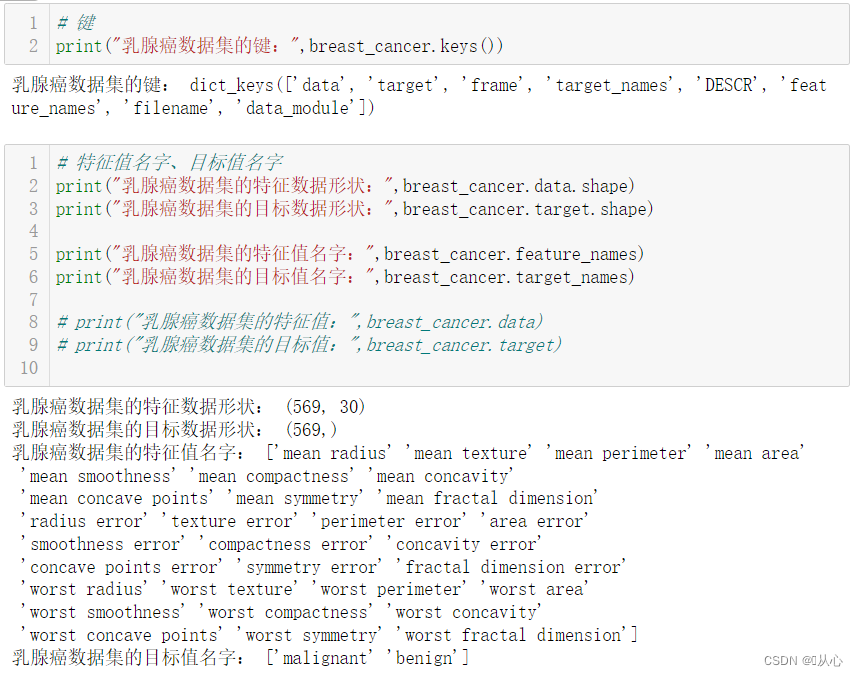
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
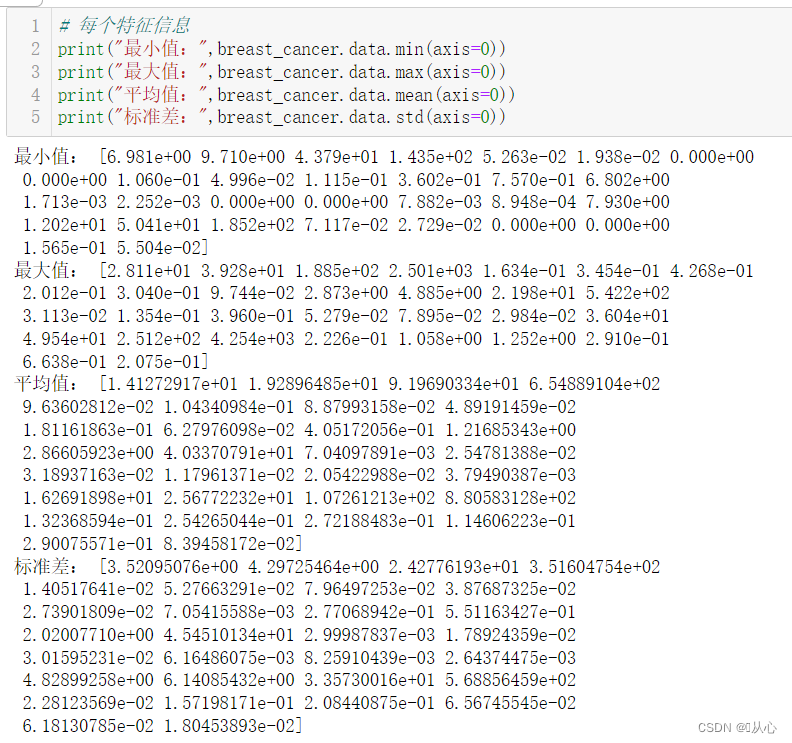
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
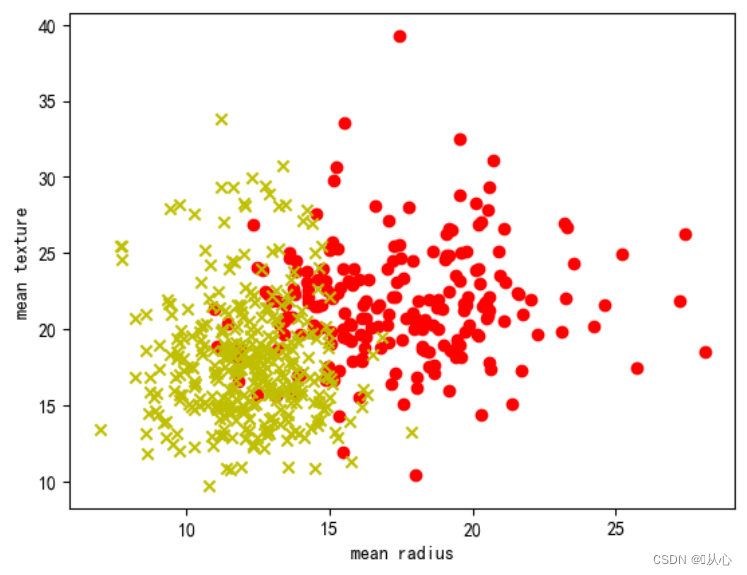
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
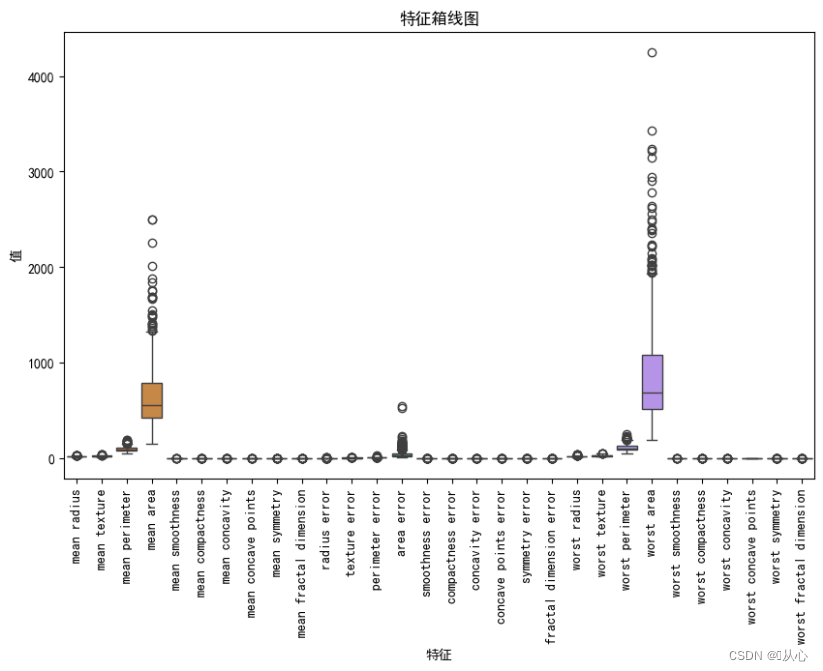
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
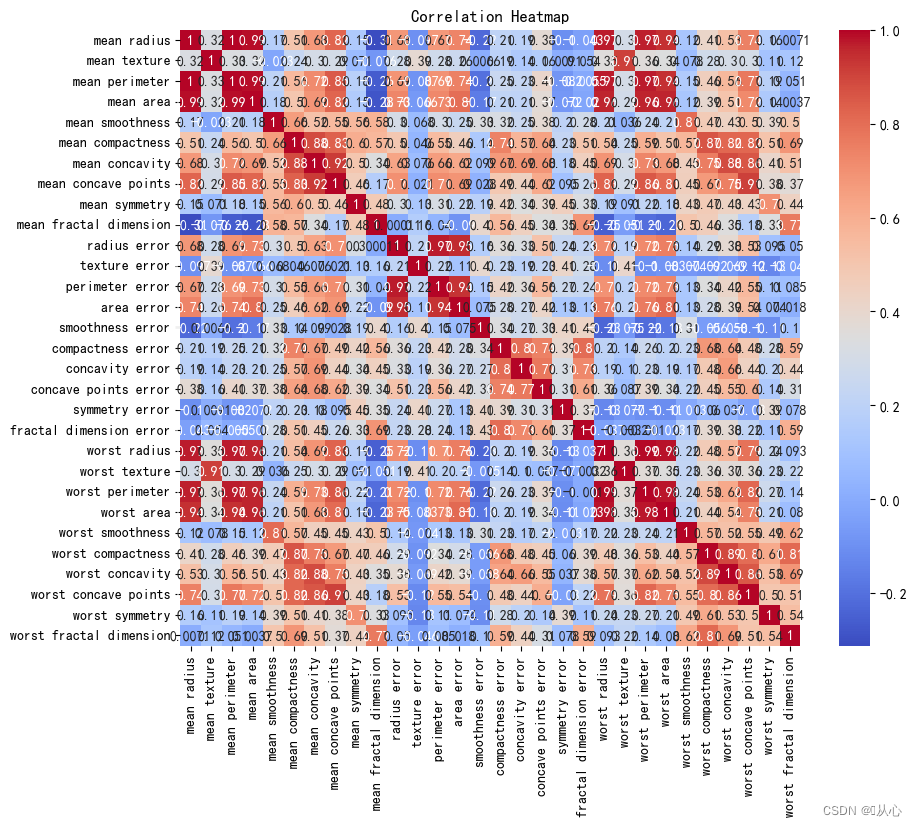
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 २、एपि
२、एपि- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
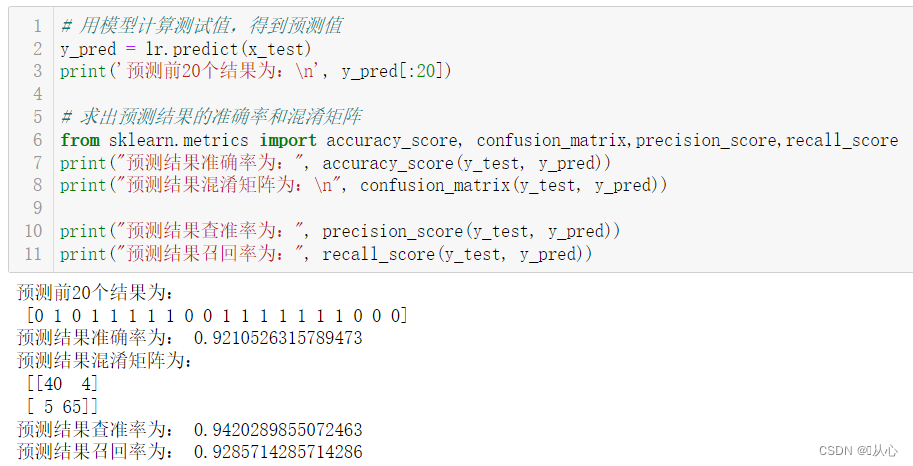
- print("建立的逻辑回归模型为:n", lr)

- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
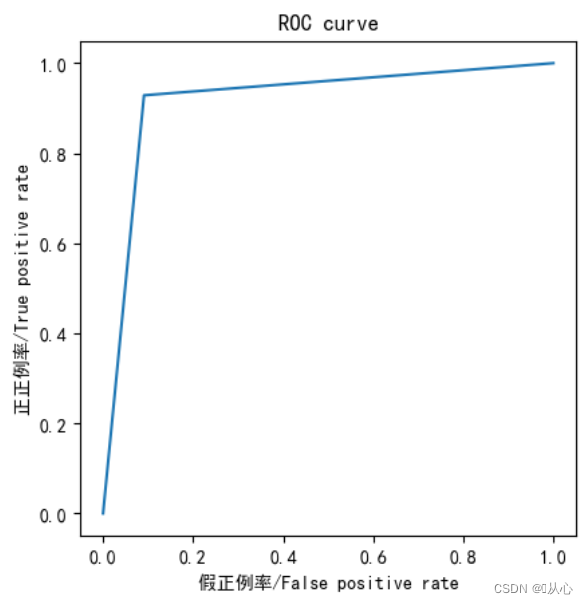
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

आदर्शमूल्यांकनानन्तरं यत् प्रतिरूपं गच्छति तत् पूर्वानुमानार्थं वास्तविकमूल्ये प्रतिस्थापयितुं शक्यते ।
पुरातनस्वप्नाः पुनः जीवितुं शक्यन्ते, पश्यामः :यन्त्रशिक्षण (5) -- पर्यवेक्षितशिक्षण (5) -- रेखीय प्रतिगमन 2
यदि भवान् ज्ञातुम् इच्छति यत् अग्रे किं भवति तर्हि अवलोकयामः :यन्त्रशिक्षण (5) -- पर्यवेक्षितशिक्षण (7) --SVM1

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु
