私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
前の記事:機械学習 (5) -- 教師あり学習 (5) -- 線形回帰 2
次の記事:機械学習 (5) -- 教師あり学習 (7) -- SVM1
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
ロジスティック回帰 = 線形回帰 + シグモイド関数
ロジスティック回帰(ロジスティック回帰)とは、単純にバイナリデータを分割する直線を見つけることです。
特定のカテゴリに属するオブジェクトを分類することによって二項分類問題を解決します確率値特定のカテゴリに属するかどうかを判断するために、このカテゴリはデフォルトで 1 (肯定的な例) としてマークされ、他のカテゴリは 0 (否定的な例) としてマークされます。
実際、これは線形回帰ステップと似ていますが、違いは「モデルのフィッティング効果の確認」と「モデルの位置角度の調整」に使用される方法にあります。
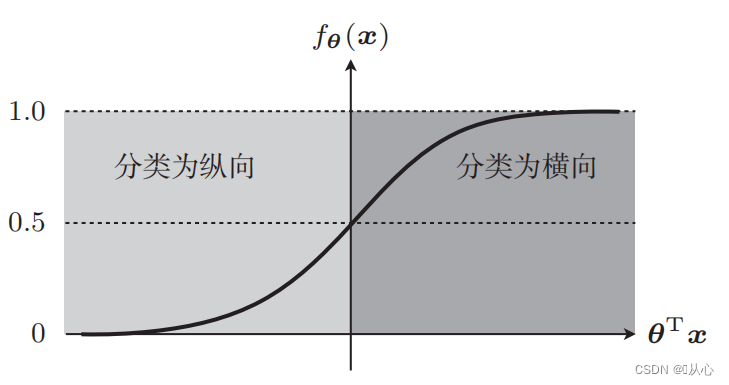
入力データを0~1にマッピングする関数(シグモイド関数)を使用する必要があり、関数の値が0.5より大きい場合は1、それ以外の場合は0と判定されます。これは確率表現に変換できます。
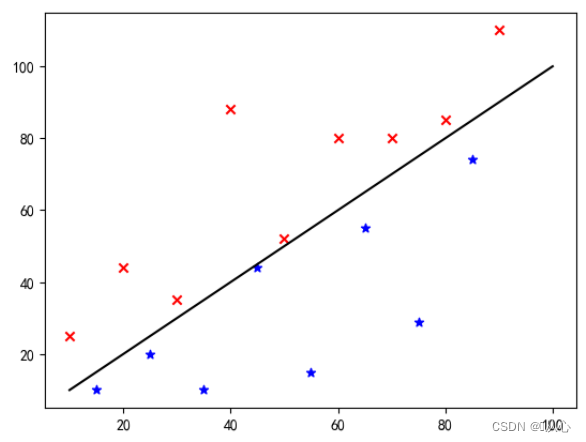
写真の分類を例に挙げると、写真を縦方向と横方向に分割します。
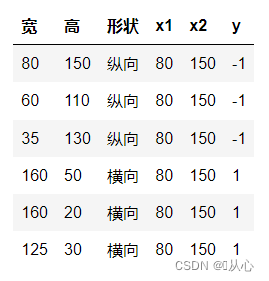
このデータをグラフ上に表示する方法は、グラフ内の異なる色の点 (異なるカテゴリ) を分離するために、このような線を描きます。この分類の目的は、そのような線を見つけることです。
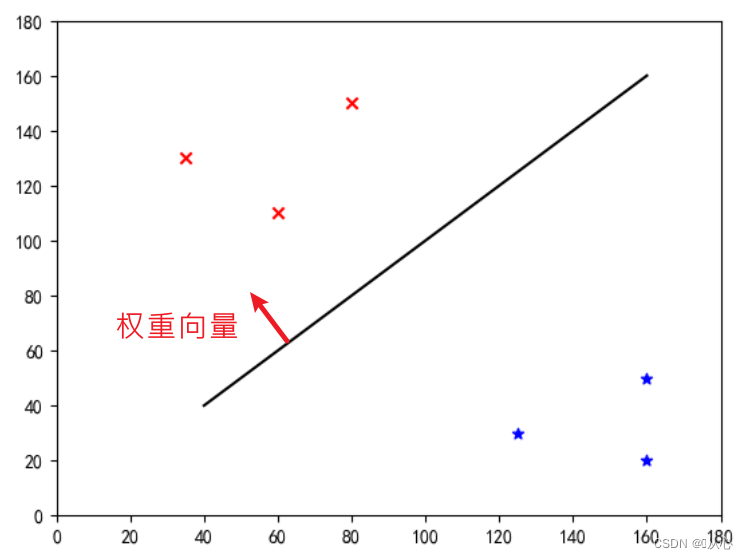
これは「重みベクトルを法線ベクトルにする直線」です(重みベクトルをその線に垂直にする)
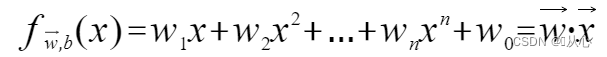
w は重みベクトルであり、法線ベクトルの直線になります。
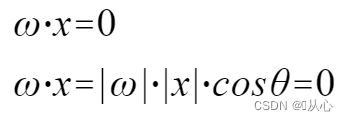
複数の値を受け入れ、各値にそれぞれの重みを乗算し、最終的に合計を出力するモデル。
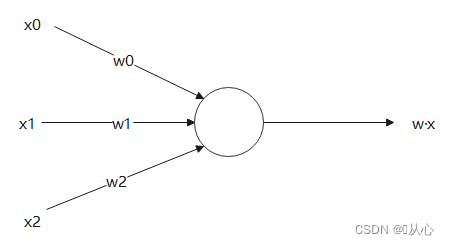
内積はベクトル間の類似度の尺度であり、正の結果は類似性を示し、値 0 は垂直性を示し、負の結果は非類似性を示します。
使用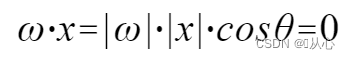 |w| と |x| は両方とも正の数なので、内積の符号は cosθ によって決まります。つまり、90 度未満の場合は同様になります。 90度を超えると、それは似ていない、つまり
|w| と |x| は両方とも正の数なので、内積の符号は cosθ によって決まります。つまり、90 度未満の場合は同様になります。 90度を超えると、それは似ていない、つまり
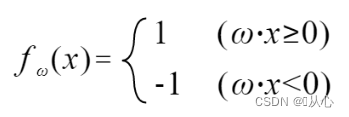
元のラベル値と等しい場合、重みベクトルは更新されません。元のラベル値と等しくない場合、重みベクトルの更新にベクトル加算が使用されます。
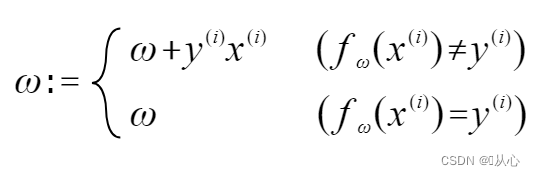
図に示すように、元のラベルと等しくない場合は、
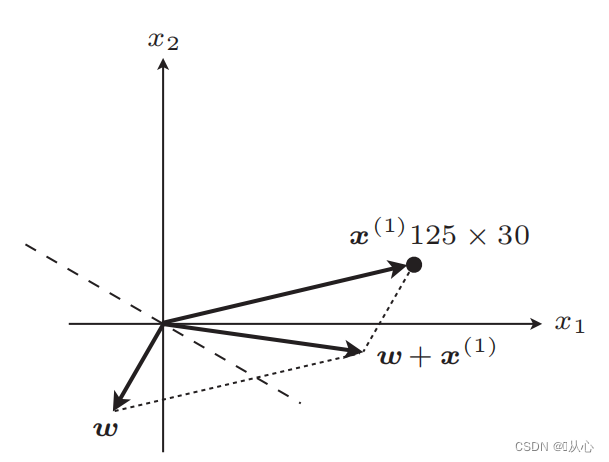
アップデート後は直線
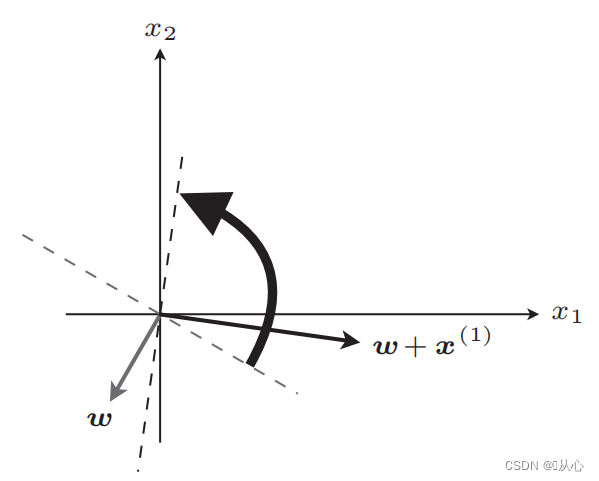
アップデート後は同等
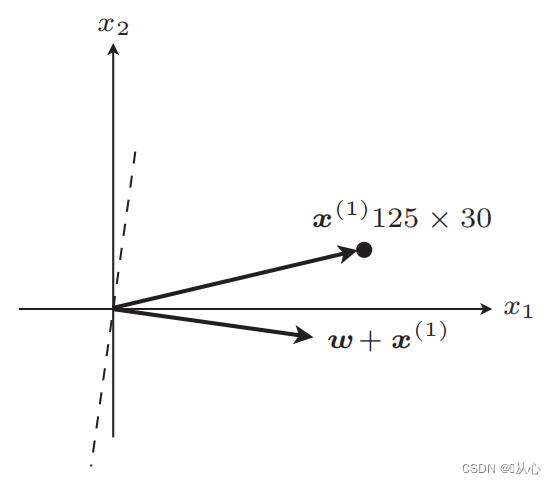
手順:まず直線をランダムに決定し(つまり重みベクトルwをランダムに決定)、内積に実数値データxを代入し、等しい場合に判別関数で値(1または-1)を取得します。元のラベル値に戻すと、重みベクトルは更新されません。元のラベル値と異なる場合は、ベクトル加算を使用して重みベクトルを更新します。
! ! !注: パーセプトロンは線形分離可能な問題のみを解決できます。
線形分離可能:直線で分類できる場合
線形不可分性: 直線で分類できない
黒はシグモイド関数、赤はステップ関数(不連続)
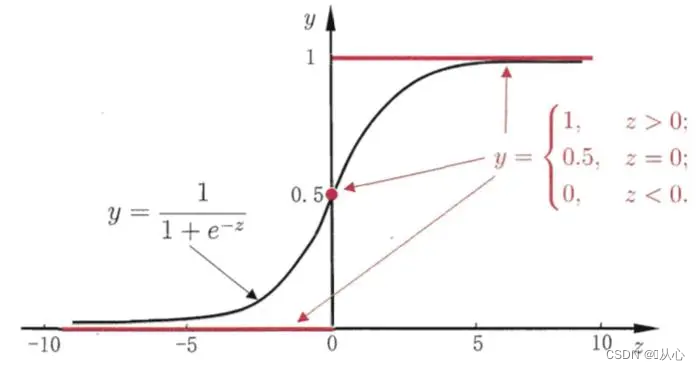
機能: ロジスティック回帰の入力は線形回帰の結果です。シグモイド関数は、線形回帰で予測値を取得できます。これにより、分類タスクである値から確率への変換が完了します。
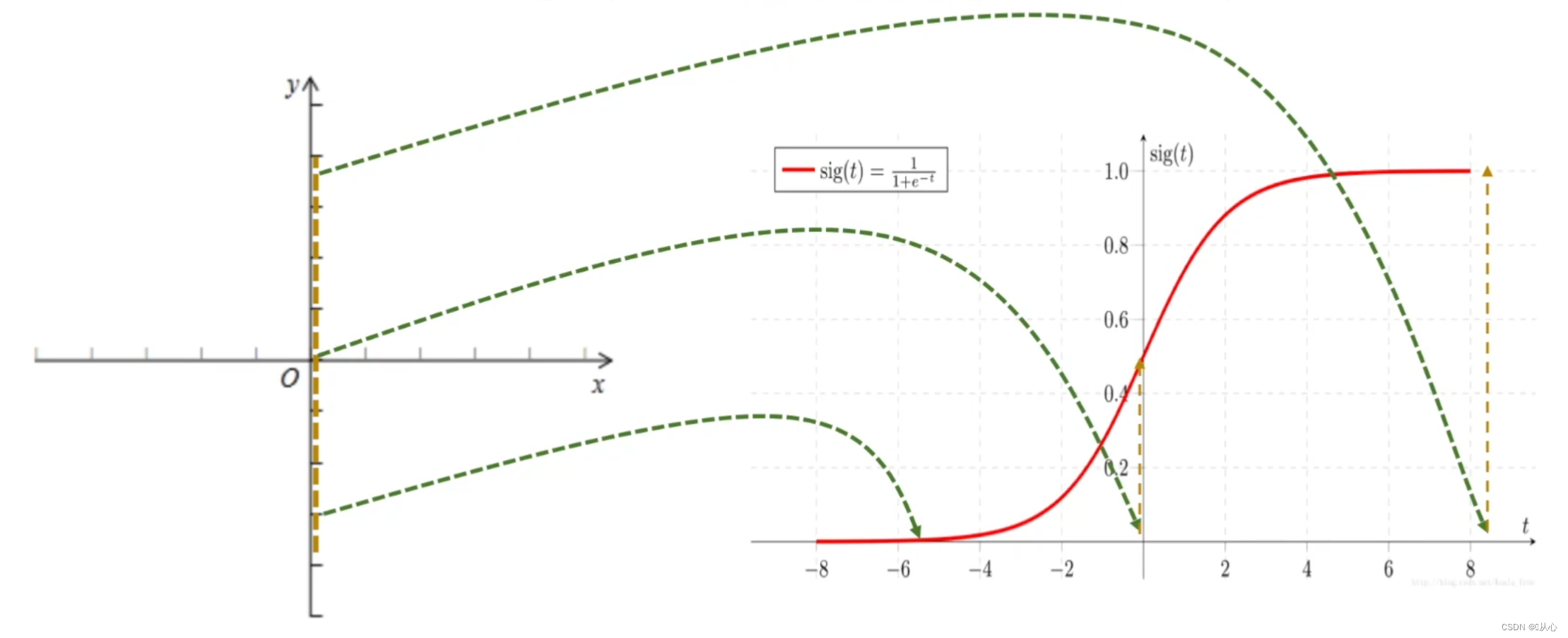
ロジスティック回帰 = 線形回帰 + シグモイド関数
線形回帰: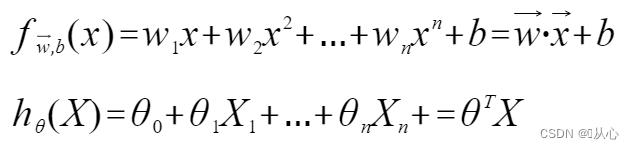
シグモイド関数: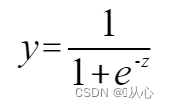
ロジスティック回帰: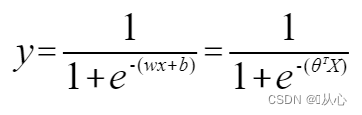
y がラベルを表すようにするには、次のように変更します。
確率を計算するには、以下を使用します。
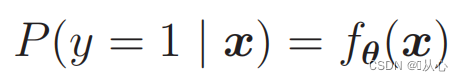
つまり、カテゴリは確率によって区別できます。
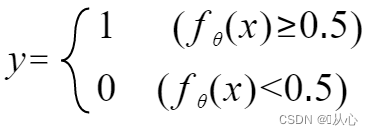
これは次のように書き換えることができます。
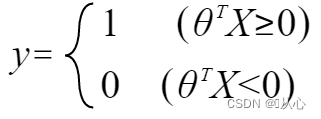
いつ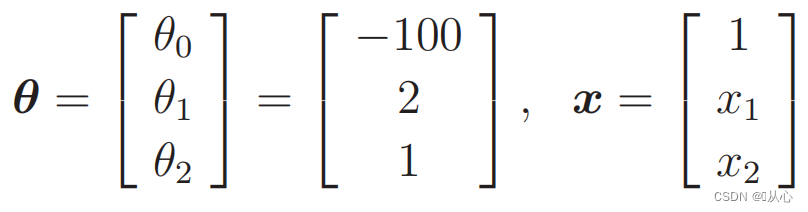
代替データ: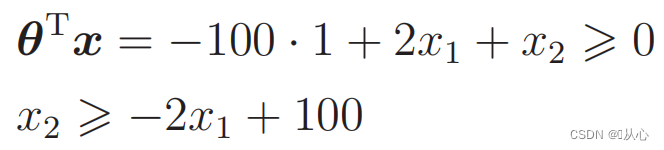
こんな絵もあるよ
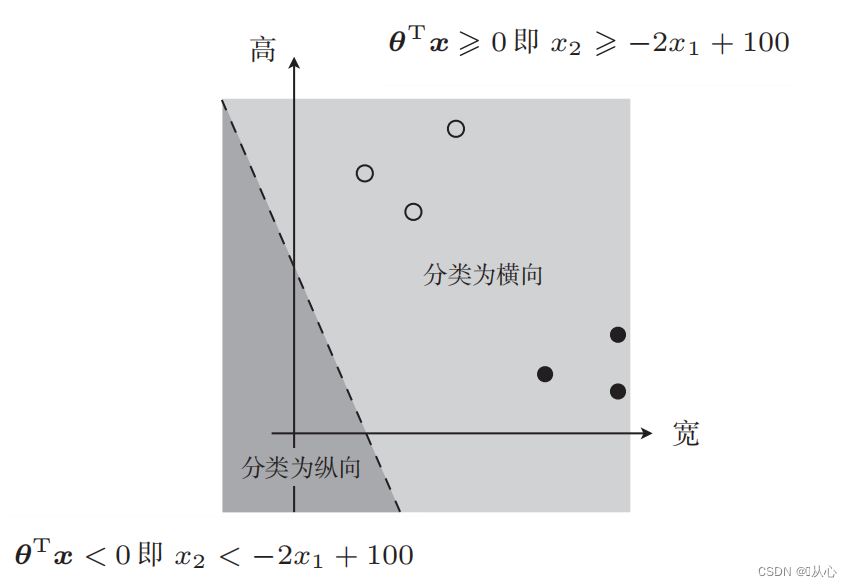 データ分類に使用される直線が決定境界です
データ分類に使用される直線が決定境界です
私たちが望んでいるのはこれです:
y=1 の場合、P(y=1|x) が最大になります
y=0 の場合、P(y=0|x) が最大になります
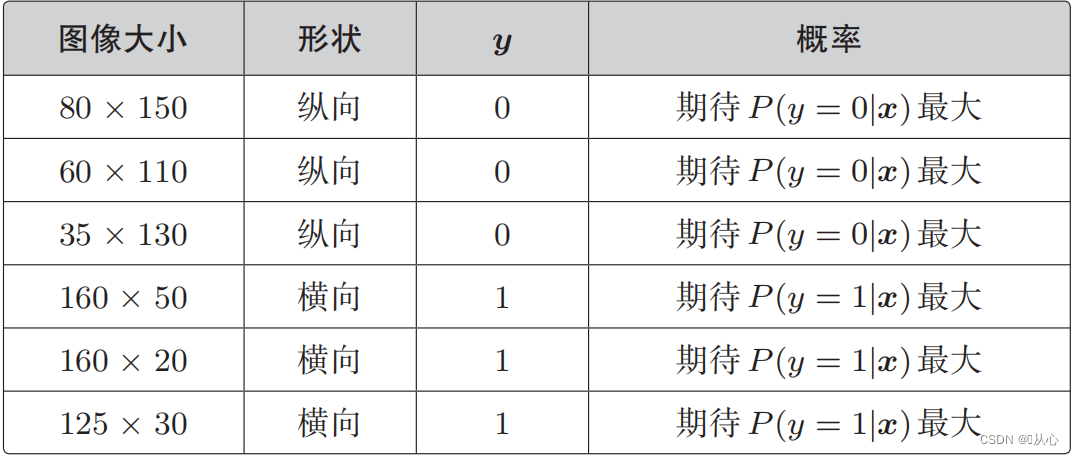
尤度関数 (同時確率): 最大化したい確率は次のとおりです。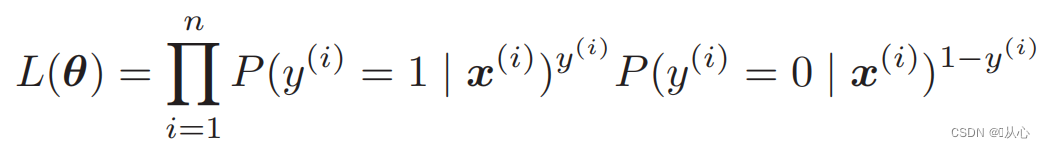
対数尤度関数: 尤度関数を直接微分することは困難です。最初に対数を取る必要があります。
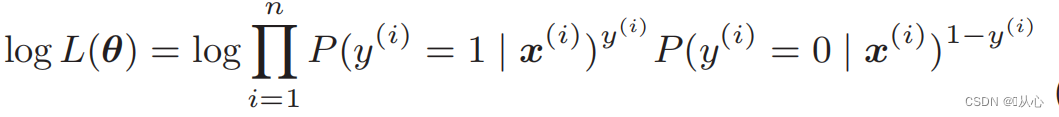
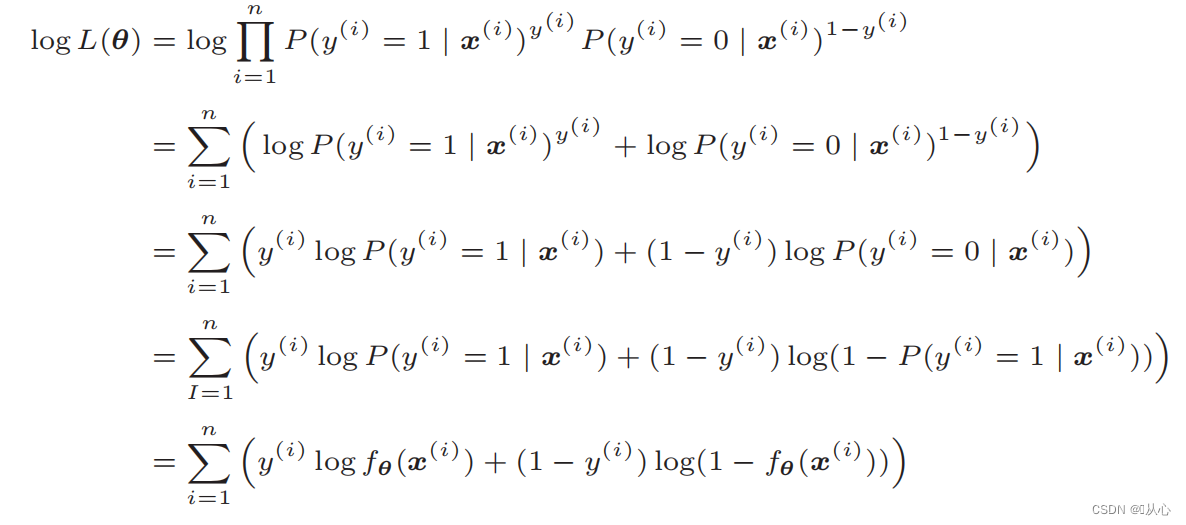
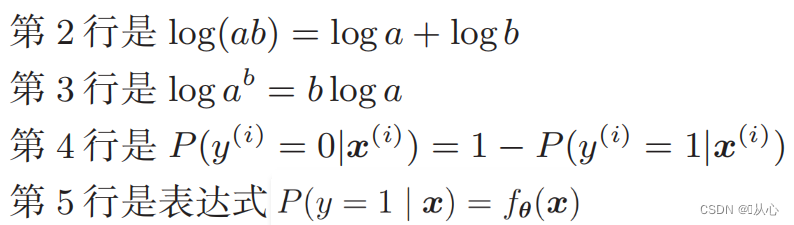
変形後は次のようになります。
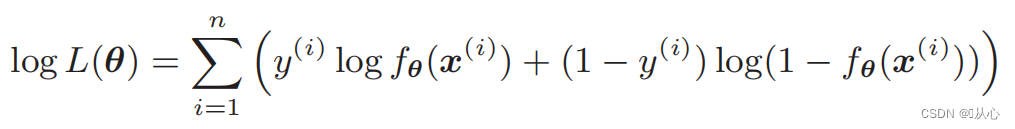
尤度関数の微分:
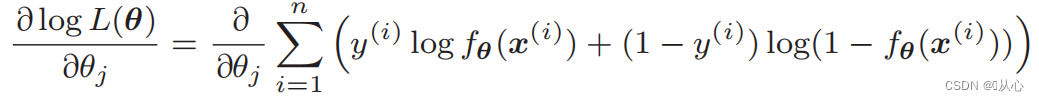
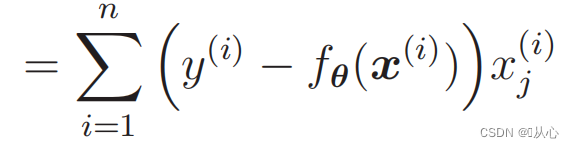
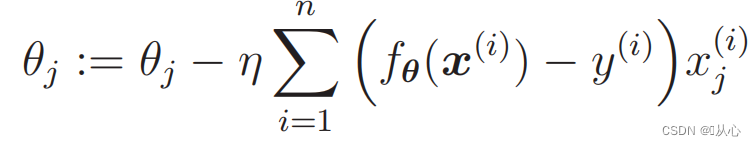
1. 実装が簡単: ロジスティック回帰は、理解と実装が簡単なシンプルなアルゴリズムです。
2. 高い計算効率: ロジスティック回帰は比較的少量の計算を必要とし、大規模なデータセットに適しています。
3. 強い解釈可能性: ロジスティック回帰の出力結果は確率値であり、モデルの出力を直感的に説明できます。
1. 線形分離可能性の要件: ロジスティック回帰は線形モデルであり、非線形分離可能問題に対してはあまり効果がありません。
2. 特徴相関問題: ロジスティック回帰は、入力特徴間の相関の影響をより受けやすく、特徴間に強い相関がある場合、モデルのパフォーマンスが低下する可能性があります。
3. 過学習問題: サンプルの特徴が多すぎる場合、またはサンプルの数が少ない場合、ロジスティック回帰では過学習の問題が発生する傾向があります。
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib notebook
-
- # 读取数据
- train=pd.read_csv('csv/images2.csv')
- train_x=train.iloc[:,0:2]
- train_y=train.iloc[:,2]
- # print(train_x)
- # print(train_y)
-
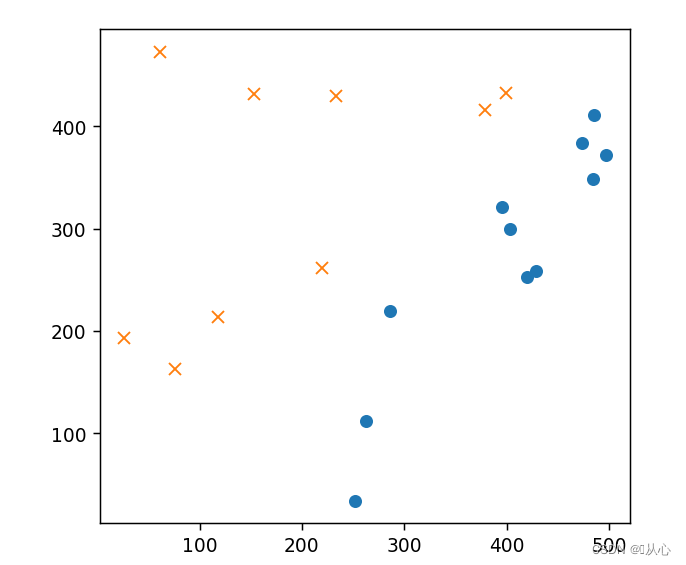
- # 绘图
- plt.figure()
- plt.plot(train_x[train_y ==1].iloc[:,0],train_x[train_y ==1].iloc[:,1],'o')
- plt.plot(train_x[train_y == 0].iloc[:,0],train_x[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # 初始化参数
- theta=np.random.randn(3)
-
- # 标准化
- mu = train_x.mean(axis=0)
- sigma = train_x.std(axis=0)
- # print(mu,sigma)
-
-
- def standardize(x):
- return (x - mu) / sigma
-
- train_z = standardize(train_x)
- # print(train_z)
-
- # 增加 x0
- def to_matrix(x):
- x0 = np.ones([x.shape[0], 1])
- return np.hstack([x0, x])
-
- X = to_matrix(train_z)
-
-
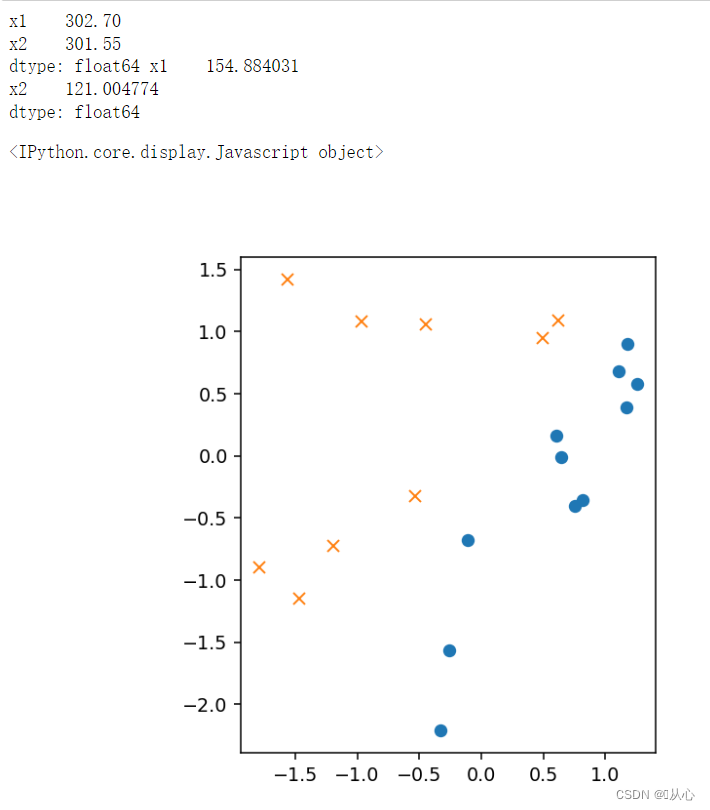
- # 绘图
- plt.figure()
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.axis('scaled')
- # plt.axis([0,500,0,500])
- plt.show()
- # sigmoid 函数
- def f(x):
- return 1 / (1 + np.exp(-np.dot(x, theta)))
-
- # 分类函数
- def classify(x):
- return (f(x) >= 0.5).astype(np.int)
- # 学习率
- ETA = 1e-3
-
- # 重复次数
- epoch = 5000
-
- # 更新次数
- count = 0
- print(f(X))
-
- # 重复学习
- for _ in range(epoch):
- theta = theta - ETA * np.dot(f(X) - train_y, X)
-
- # 日志输出
- count += 1
- print('第 {} 次 : theta = {}'.format(count, theta))
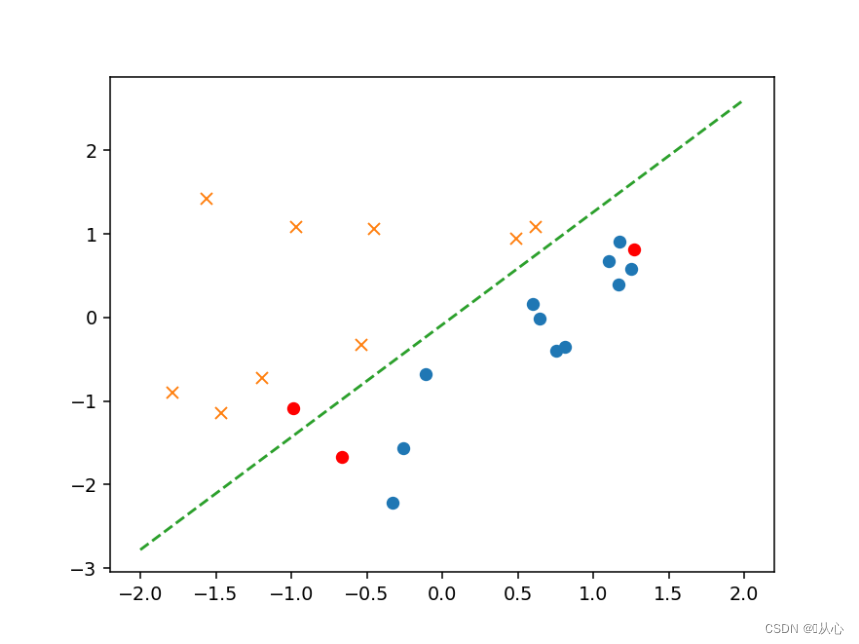
- # 绘图确认
- plt.figure()
- x0 = np.linspace(-2, 2, 100)
- plt.plot(train_z[train_y ==1].iloc[:,0],train_z[train_y ==1].iloc[:,1],'o')
- plt.plot(train_z[train_y == 0].iloc[:,0],train_z[train_y == 0].iloc[:,1],'x')
- plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2], linestyle='dashed')
- plt.show()
- # 验证
- text=[[200,100],[500,400],[150,170]]
- tt=pd.DataFrame(text,columns=['x1','x2'])
- # text=pd.DataFrame({'x1':[200,400,150],'x2':[100,50,170]})
- x=to_matrix(standardize(tt))
- print(x)
- a=f(x)
- print(a)
-
- b=classify(x)
- print(b)
-
- plt.plot(x[:,1],x[:,2],'ro')

from sklearn.datasets import load_breast_cancer
- # 键
- print("乳腺癌数据集的键:",breast_cancer.keys())
-
-
-
- # 特征值名字、目标值名字
- print("乳腺癌数据集的特征数据形状:",breast_cancer.data.shape)
- print("乳腺癌数据集的目标数据形状:",breast_cancer.target.shape)
-
- print("乳腺癌数据集的特征值名字:",breast_cancer.feature_names)
- print("乳腺癌数据集的目标值名字:",breast_cancer.target_names)
-
- # print("乳腺癌数据集的特征值:",breast_cancer.data)
- # print("乳腺癌数据集的目标值:",breast_cancer.target)
-
-
-
- # 返回值
- # print("乳腺癌数据集的返回值:n", breast_cancer)
- # 返回值类型是bunch--是一个字典类型
-
- # 描述
- # print("乳腺癌数据集的描述:",breast_cancer.DESCR)
-
-
-
- # 每个特征信息
- print("最小值:",breast_cancer.data.min(axis=0))
- print("最大值:",breast_cancer.data.max(axis=0))
- print("平均值:",breast_cancer.data.mean(axis=0))
- print("标准差:",breast_cancer.data.std(axis=0))
-
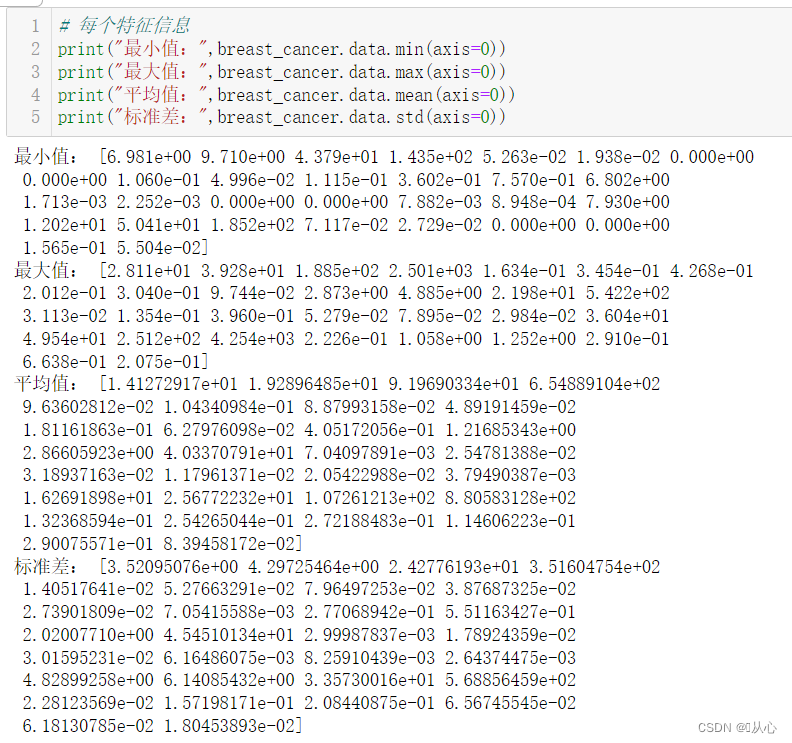
- # 取其中间两列特征
- x=breast_cancer.data[0:569,0:2]
- y=breast_cancer.target[0:569]
-
- samples_0 = x[y==0, :]
- samples_1 = x[y==1, :]
-
-
-
- # 实现可视化
- plt.figure()
- plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
- plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
- plt.xlabel('mean radius')
- plt.ylabel('mean texture')
- plt.show()
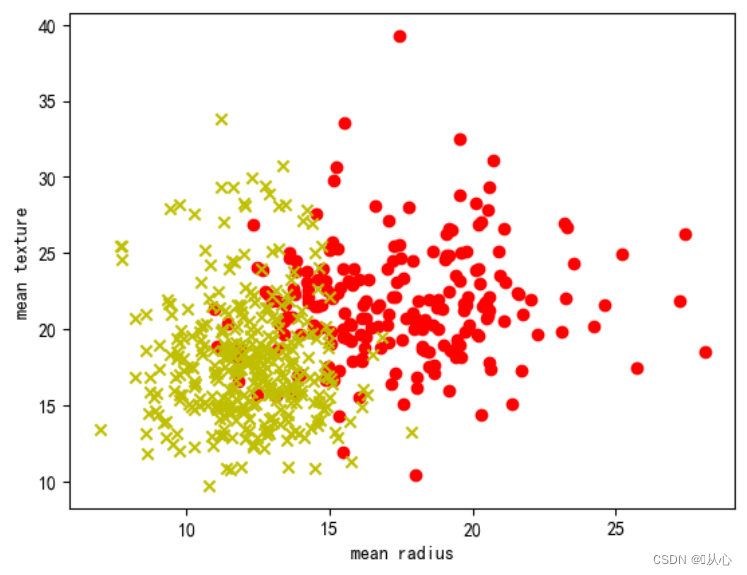
- # 绘制每个特征直方图,显示特征值的分布情况。
- for i, feature_name in enumerate(breast_cancer.feature_names):
- plt.figure(figsize=(6, 4))
- sns.histplot(breast_cancer.data[:, i], kde=True)
- plt.xlabel(feature_name)
- plt.ylabel("数量")
- plt.title("{}直方图".format(feature_name))
- plt.show()
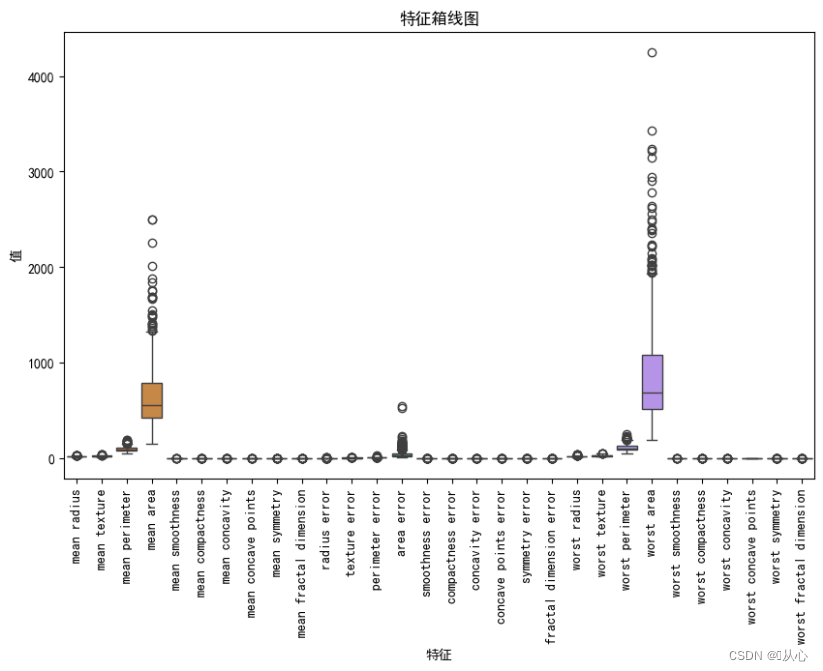
- # 绘制箱线图,展示每个特征最小值、第一四分位数、中位数、第三四分位数和最大值概括。
- plt.figure(figsize=(10, 6))
- sns.boxplot(data=breast_cancer.data, orient="v")
- plt.xticks(range(len(breast_cancer.feature_names)), breast_cancer.feature_names, rotation=90)
- plt.xlabel("特征")
- plt.ylabel("值")
- plt.title("特征箱线图")
- plt.show()
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 检测缺失值
- print("缺失值数量:")
- print(df.isnull().sum())
-
- # 检测异常值
- print("异常值统计信息:")
- print(df.describe())
- # 使用.describe()方法获取数据集的统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
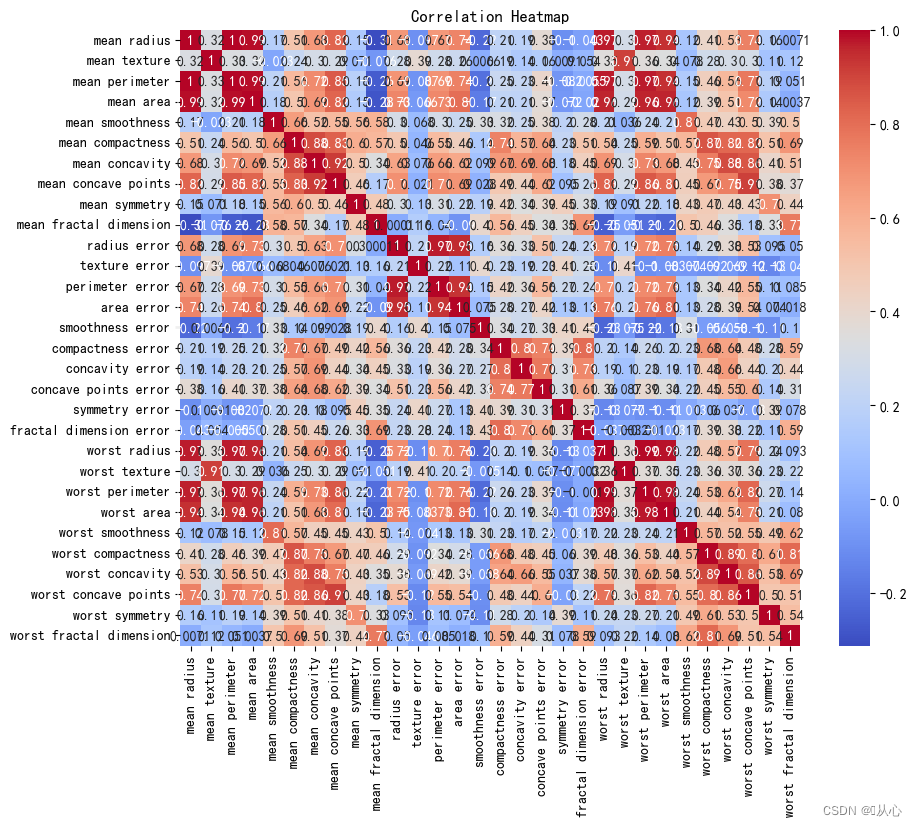
- # 创建DataFrame对象
- df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
-
- # 计算相关系数
- correlation_matrix = df.corr()
-
- # 可视化相关系数热力图
- plt.figure(figsize=(10, 8))
- sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
- plt.title("Correlation Heatmap")
- plt.show()
 2、API
2、API- sklearn.linear_model.LogisticRegression
-
- 导入:
- from sklearn.linear_model import LogisticRegression
-
- 语法:
- LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- from sklearn.datasets import load_breast_cancer
- from sklearn.model_selection import train_test_split
-
- from sklearn.linear_model import LogisticRegression
-
- # 获取数据
- breast_cancer = load_breast_cancer()
- # 划分数据集
- x_train,x_test,y_train,y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=1473)
- # 实例化学习器
- lr = LogisticRegression(max_iter=10000)
-
- # 模型训练
- lr.fit(x_train, y_train)
-
- print("建立的逻辑回归模型为:n", lr)

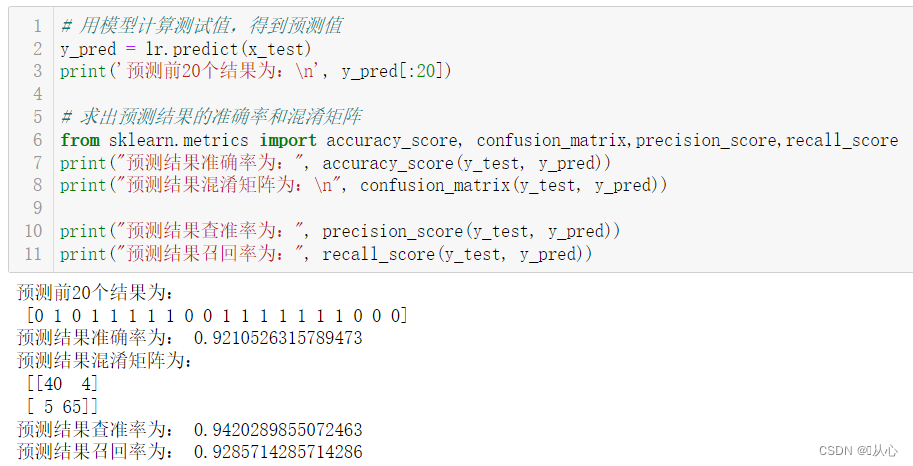
- # 用模型计算测试值,得到预测值
- y_pred = lr.predict(x_test)
- print('预测前20个结果为:n', y_pred[:20])
-
- # 求出预测结果的准确率和混淆矩阵
- from sklearn.metrics import accuracy_score, confusion_matrix,precision_score,recall_score
- print("预测结果准确率为:", accuracy_score(y_test, y_pred))
- print("预测结果混淆矩阵为:n", confusion_matrix(y_test, y_pred))
-
- print("预测结果查准率为:", precision_score(y_test, y_pred))
- print("预测结果召回率为:", recall_score(y_test, y_pred))
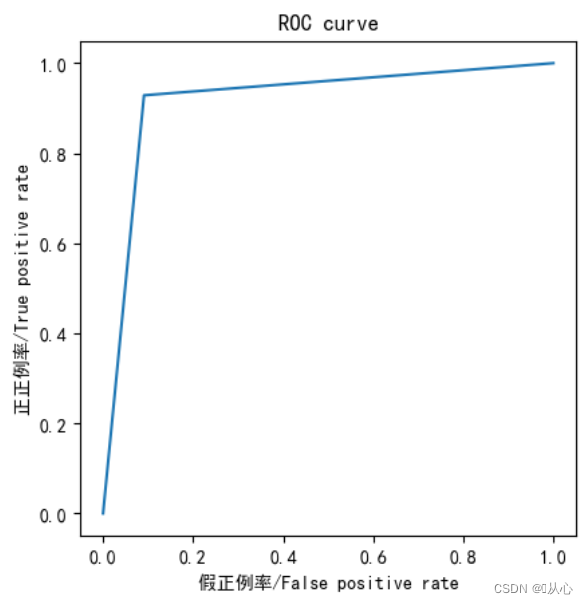
- from sklearn.metrics import roc_curve,roc_auc_score,auc
-
- fpr,tpr,thresholds=roc_curve(y_test,y_pred)
-
- plt.plot(fpr, tpr)
- plt.axis("square")
- plt.xlabel("假正例率/False positive rate")
- plt.ylabel("正正例率/True positive rate")
- plt.title("ROC curve")
- plt.show()
-
- print("AUC指标为:",roc_auc_score(y_test,y_pred))
- # 求出预测取值和真实取值一致的数目
- num_accu = np.sum(y_test == y_pred)
- print('预测对的结果数目为:', num_accu)
- print('预测错的结果数目为:', y_test.shape[0]-num_accu)
- print('预测结果准确率为:', num_accu/y_test.shape[0])

モデル評価後に渡されたモデルを実際の値に代入して予測することができます。
昔の夢を追体験することができます。見てみましょう:機械学習 (5) -- 教師あり学習 (5) -- 線形回帰 2
次に何が起こるかを知りたい場合は、見てみましょう。機械学習 (5) -- 教師あり学習 (7) -- SVM1

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: