τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
19 Ιουλίου 2023: Η Meta κυκλοφόρησε το εμπορικό μοντέλο ανοιχτού κώδικα Llama 2.
Το Llama 2 είναι μια συλλογή προεκπαιδευμένων και βελτιστοποιημένων μοντέλων δημιουργίας κειμένου που κυμαίνονται σε μέγεθος από 7 δισεκατομμύρια έως 70 δισεκατομμύρια παραμέτρους.
Τα τελειοποιημένα LLM, που ονομάζονται Llama-2-Chat, είναι βελτιστοποιημένα για περιπτώσεις χρήσης συνομιλίας. Το μοντέλο Llama-2-Chat υπερτερεί των μοντέλων συνομιλίας ανοιχτού κώδικα στα περισσότερα σημεία αναφοράς που δοκιμάσαμε και είναι στο ίδιο επίπεδο με ορισμένα δημοφιλή μοντέλα κλειστού κώδικα, όπως το ChatGPT και το PaLM, σε ανθρώπινες αξιολογήσεις χρησιμότητας και ασφάλειας.
Το LLaMA-2-chat είναι σχεδόν το μόνο μοντέλο ανοιχτού κώδικα που εκτελεί RLHF. Μετά από 5 γύρους RLHF, το LLaMA-2 έδειξε καλύτερη απόδοση από το ChatGPT υπό την αξιολόγηση του μοντέλου ανταμοιβής του ίδιου του Meta και του GPT-4.
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
διεύθυνση:
https://github.com/facebookresearch/llama
διεύθυνση:
https://huggingface.co/meta-llama

Llama2-chat:
Για άλλα μοντέλα, ελέγξτε:
https://huggingface.co/meta-llama
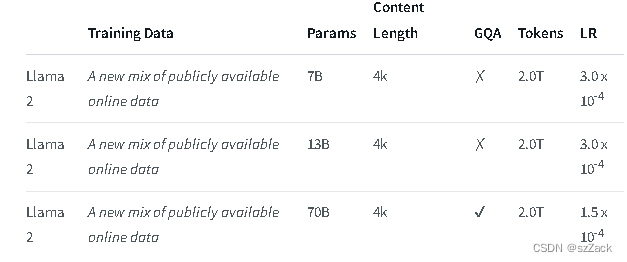
Το μήκος περιβάλλοντος είναι 4K.
Δωρεάν για εμπορική χρήση
Απαιτείται αίτηση εγγραφής
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://github.com/facebookresearch/llama
https://huggingface.co/meta-llama

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]