informasi kontak saya
Surat[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
19 Juli 2023: Meta merilis model komersial sumber terbuka Llama 2.
Llama 2 adalah kumpulan model teks generatif yang telah dilatih dan disempurnakan dengan ukuran mulai dari 7 miliar hingga 70 miliar parameter.
LLM yang disempurnakan, disebut Llama-2-Chat, dioptimalkan untuk kasus penggunaan percakapan. Model Llama-2-Chat mengungguli model obrolan sumber terbuka pada sebagian besar tolok ukur yang kami uji, dan setara dengan beberapa model sumber tertutup populer seperti ChatGPT dan PaLM dalam evaluasi kegunaan dan keamanan manusia.
LLaMA-2-chat hampir merupakan satu-satunya model sumber terbuka yang menjalankan RLHF. Setelah 5 putaran RLHF, LLaMA-2 menunjukkan kinerja yang lebih baik daripada ChatGPT berdasarkan evaluasi model hadiah Meta sendiri dan GPT-4.
https://ai.meta.com/research/publications/llama-2-membuka-fondasi-dan-menyempurnakan-model-obrolan/
alamat:
https://github.com/facebookresearch/llama
alamat:
https://huggingface.co/meta-llama

Obrolan Llama2:
Untuk model lain silakan lihat:
https://huggingface.co/meta-llama
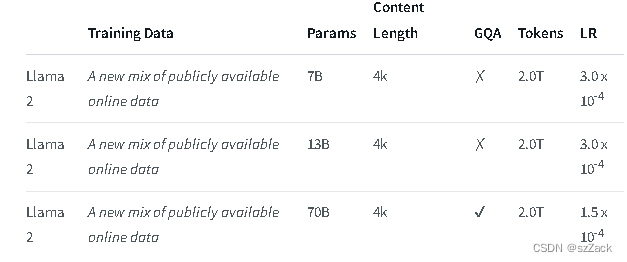
Panjang konteksnya adalah 4K.
Gratis untuk penggunaan komersial
Diperlukan aplikasi pendaftaran
https://ai.meta.com/research/publications/llama-2-membuka-fondasi-dan-menyempurnakan-model-obrolan/
https://github.com/facebookresearch/llama
https://huggingface.co/meta-llama

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]