2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
19. Juli 2023: Meta veröffentlicht das kommerzielle Open-Source-Modell Llama 2.
Llama 2 ist eine Sammlung vorab trainierter und fein abgestimmter generativer Textmodelle mit einer Größe von 7 bis 70 Milliarden Parametern.
Die fein abgestimmten LLMs namens Llama-2-Chat sind für Konversationsanwendungsfälle optimiert. Das Llama-2-Chat-Modell übertrifft Open-Source-Chat-Modelle bei den meisten von uns getesteten Benchmarks und liegt bei menschlichen Bewertungen von Nützlichkeit und Sicherheit auf Augenhöhe mit einigen beliebten Closed-Source-Modellen wie ChatGPT und PaLM.
LLaMA-2-chat ist fast das einzige Open-Source-Modell, das RLHF ausführt. Nach fünf RLHF-Runden zeigte LLaMA-2 bei der Auswertung von Metas eigenem Belohnungsmodell und GPT-4 eine bessere Leistung als ChatGPT.
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Adresse:
https://github.com/facebookresearch/llama
Adresse:
https://huggingface.co/meta-llama

Llama2-Chat:
Für andere Modelle prüfen Sie bitte:
https://huggingface.co/meta-llama
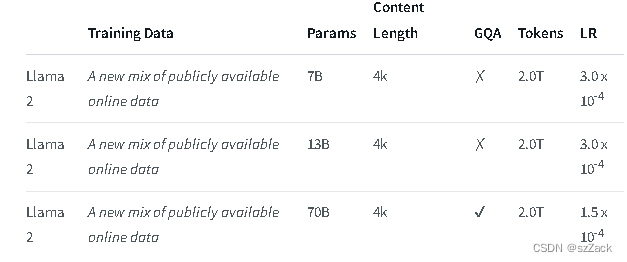
Die Kontextlänge beträgt 4K.
Kostenlos für kommerzielle Nutzung
Registrierungsantrag erforderlich
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://github.com/facebookresearch/llama
https://huggingface.co/meta-llama

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
