minhas informações de contato
Correspondência[email protected]
2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
19 de julho de 2023: Meta lançou o modelo comercial de código aberto Llama 2.
Llama 2 é uma coleção de modelos de texto generativo pré-treinados e ajustados que variam em tamanho de 7 bilhões a 70 bilhões de parâmetros.
Os LLMs aprimorados, chamados Llama-2-Chat, são otimizados para casos de uso de conversação. O modelo Llama-2-Chat supera os modelos de chat de código aberto na maioria dos benchmarks que testamos e está no mesmo nível de alguns modelos populares de código fechado, como ChatGPT e PaLM, em avaliações humanas de utilidade e segurança.
LLaMA-2-chat é quase o único modelo de código aberto que executa RLHF. Após 5 rodadas de RLHF, o LLaMA-2 apresentou melhor desempenho que o ChatGPT na avaliação do próprio modelo de recompensa do Meta e do GPT-4.
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
endereço:
https://github.com/facebookresearch/llama
endereço:
https://huggingface.co/meta-llama

Llama2-chat:
Para outros modelos consulte:
https://huggingface.co/meta-llama
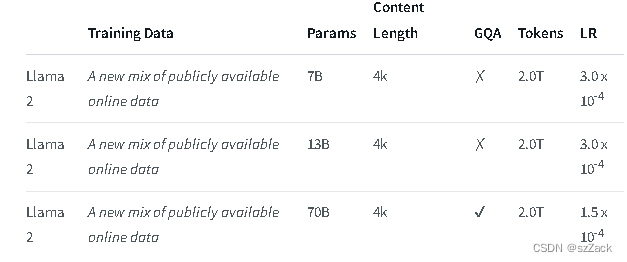
O comprimento do contexto é 4K.
Gratuito para uso comercial
Solicitação de registro necessária
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://github.com/facebookresearch/llama
https://huggingface.co/meta-llama

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]