2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
2023年7月19日:Meta 发布开源可商用模型 Llama 2。
Llama 2是一个预训练和微调的生成文本模型的集合,其规模从70亿到700亿个参数不等。
经过微调的LLMs称为Llama-2-Chat,针对对话用例进行了优化。Llama-2-Chat模型在我们测试的大多数基准测试中都优于开源聊天模型,在对有用性和安全性的人工评估中,与ChatGPT和PaLM等一些流行的封闭源代码模型不相上下。
LLaMA-2-chat 几乎是开源模型中唯一做了 RLHF 的模型。LLaMA-2 经过 5 轮 RLHF 后,在 Meta 自己的 reward 模型与 GPT-4 的评价下,都表现出了超过 ChatGPT 性能。
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
地址:
https://github.com/facebookresearch/llama
地址:
https://huggingface.co/meta-llama

Llama2-chat:
其他模型请查看:
https://huggingface.co/meta-llama
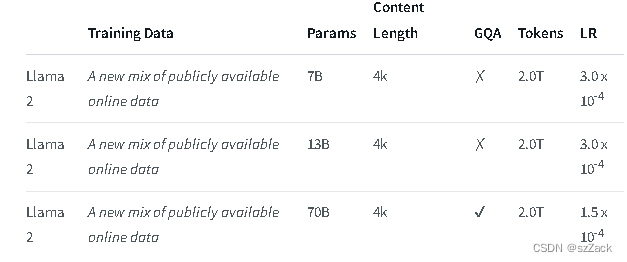
上下文长度为 4K。
免费商用
需要注册申请
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://github.com/facebookresearch/llama
https://huggingface.co/meta-llama

潜心研究技术三十余年,精通java、linux、javascript、php、css、等等各种语言,在开源领域有诸多贡献,建立开发者文档站,将一些技术开发中的问题分享出来,以供大家查阅
