Der praktische Austausch von AsiaInfo Technology zu Apache SeaTunnel
Vorstellen
Hallo Kommilitonen, es ist mir eine Ehre, über die Apache SeaTunnel-Community mit Ihnen zu teilen und zu kommunizieren. Ich bin Pan Zhihong von AsiaInfo Technology. Ich bin hauptsächlich für die Entwicklung der unternehmensinternen Rechenzentrumsprodukte verantwortlich.
Das Thema dieses Austauschs ist die Integrationspraxis von Apache SeaTunnel in AsiaInfo Technology. Konkret werden wir darüber sprechen, wie unser Rechenzentrum SeaTunnel integriert.
Inhaltsübersicht teilen
In diesem Austausch werde ich mich auf die folgenden Aspekte konzentrieren:
Warum SeaTunnel wählen?
So integrieren Sie SeaTunnel
Bei der Integration von SeaTunnel sind Probleme aufgetreten
Sekundäre Entwicklung von SeaTunnel
Erwartungen an SeaTunnel
Warum SeaTunnel wählen?
Lassen Sie mich zunächst vorstellen, dass ich hauptsächlich für die iterative Entwicklung des Rechenzentrumsprodukts DATAOS von AsiaInfo verantwortlich bin. DATAOS ist ein relativ standardmäßiges Rechenzentrumsprodukt, das Funktionsmodule wie Datenintegration, Datenentwicklung, Datenverwaltung und Datenoffenheit abdeckt. Das Wichtigste im Zusammenhang mit SeaTunnel ist das Datenintegrationsmodul, das hauptsächlich für die Datenintegration verantwortlich ist.
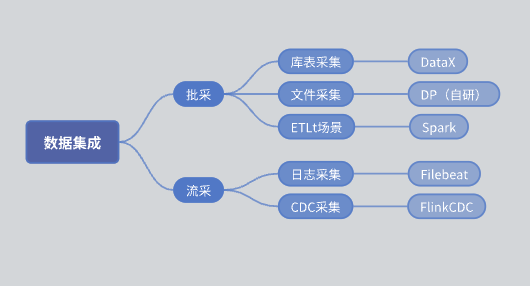
Vor der Einführung von SeaTunnel war die funktionale Architektur unseres Datenintegrationsmoduls wie folgt:
Batch-Kauf: Unterteilt in Bibliothekstabellensammlung und Dateisammlung.
Bibliothekstabellensammlung: hauptsächlich mit DataX implementiert.
Dateisammlung: selbstentwickelte DP-Engine.
ETLt-Sammlung: Selbstentwickelte ETLt-Sammlungs-Engine. DataX bevorzugt ELT (Extrahieren, Laden, Konvertieren), das für komplexe Konvertierungen nach der Datenextraktion und -speicherung geeignet ist. In einigen Szenarien ist jedoch EL Small T (Extrahieren, Laden, einfache Konvertierung) erforderlich, und DataX ist nicht geeignet. Deshalb haben wir eine Engine basierend auf Spark SQL entwickelt.
Liucai: Die Protokollsammlung basiert hauptsächlich auf Filebeat und die CDC-Sammlung basiert hauptsächlich auf Flink CDC.
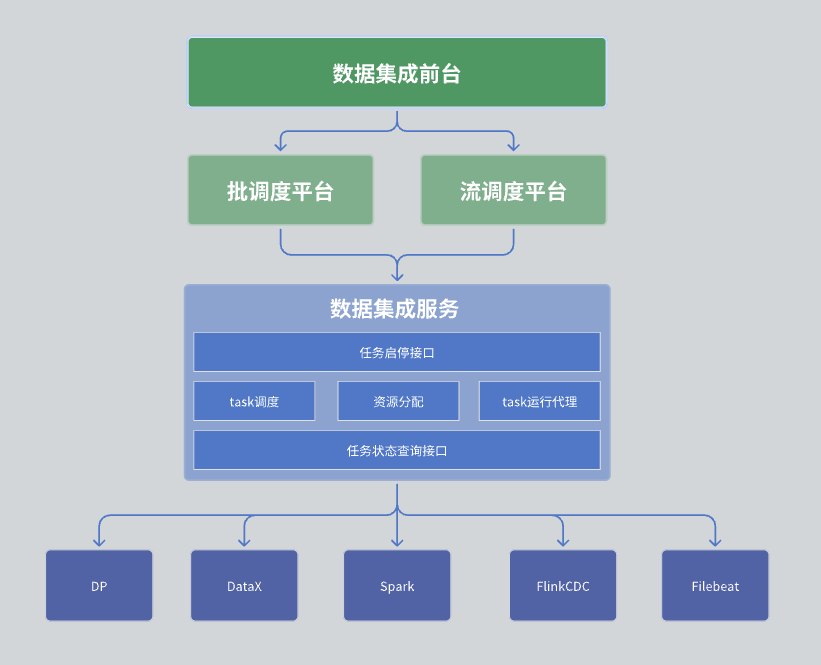
In unserem Datenintegrationsmodul ist die Gesamtarchitektur in drei Schichten unterteilt, nämlich Datenintegrations-Frontdesk, Planungsplattform und Datenintegrationsdienst.
Nachfolgend finden Sie eine detaillierte Beschreibung jeder Ebene:
Die erste Ebene: Datenintegrations-Rezeption
Der Datenintegrations-Frontdesk ist hauptsächlich für die Verwaltung von Datenintegrationsaufgaben verantwortlich. Konkret umfasst es Aufgabenentwicklung, Planungsentwicklung und Betriebsüberwachung. Diese Aufgaben kombinieren verschiedene integrierte Operatoren über DAG (Directed Asymmetric Graph), um komplexe Datenverarbeitungsprozesse zu implementieren. Die Front-End-Schnittstelle bietet eine intuitive Aufgabenverwaltungsoberfläche, mit der Benutzer Datenintegrationsaufgaben einfach konfigurieren und überwachen können.
Zweite Ebene: Planungsplattform
Die Planungsplattform ist für die Planung und Verwaltung von Aufgabenvorgängen verantwortlich. Es unterstützt sowohl den Stapelverarbeitungs- als auch den Stream-Verarbeitungsmodus und kann entsprechende Aufgaben basierend auf Aufgabenabhängigkeiten und Planungsstrategien abrufen.
Die dritte Ebene: Datenintegrationsdienst
Der Datenintegrationsdienst ist der Kern des gesamten Rechenzentrumsdienstes und bietet eine Reihe wichtiger Funktionen:
Schnittstelle zur Aufgabenverwaltung: Einschließlich Funktionen wie Aufgabenerstellung, Löschung, Aktualisierung und Abfrage.
Schnittstelle zum Starten und Stoppen von Aufgaben: Ermöglicht Benutzern das Starten oder Stoppen bestimmter Aufgaben.
Schnittstelle zur Abfrage des Aufgabenstatus: Fragen Sie die aktuellen Statusinformationen der Aufgabe ab, um die Überwachung und Verwaltung zu erleichtern.
Der Datenintegrationsdienst ist auch für die konkrete Ausführung von Aufgaben verantwortlich. Da unsere Erfassungsaufgabe möglicherweise mehrere Engines umfasst, ist bei der Ausführung der Aufgabe eine Koordination und Planung mehrerer Engines erforderlich.
Task-Laufprozess
Die Ausführung der Aufgabe umfasst im Wesentlichen die folgenden Schritte:
Aufgabenplanung: Entsprechend der vorgegebenen Planungsstrategie und den Abhängigkeiten ruft die Planungsplattform die entsprechenden Aufgaben ab.
Aufgabenausführung: Während der Aufgabenausführung wird jeder Operator der Reihe nach entsprechend der DAG-Konfiguration der Aufgabe ausgeführt.
Koordination mehrerer Motoren: Bei Aufgaben, die mehrere Engines enthalten (z. B. DataX- und Spark-Hybridaufgaben), ist es erforderlich, den Betrieb jeder Engine während des Ausführungsprozesses zu koordinieren, um eine reibungslose Ausführung der Aufgabe sicherzustellen.
Ressourcenzuteilung
Damit DataX, eine eigenständige Aufgabe, besser verteilt ausgeführt werden kann und eine Wiederverwendung von Ressourcen erreicht wird, haben wir gleichzeitig die Ressourcenzuweisung für die DataX-Aufgabe optimiert:
Verteilte Planung: Durch den Ressourcenzuweisungsmechanismus werden DataX-Aufgaben so verteilt, dass sie auf mehreren Knoten ausgeführt werden, um Engpässe an einzelnen Punkten zu vermeiden und die Aufgabenparallelität und Ausführungseffizienz zu verbessern.
Wiederverwendung von Ressourcen: Stellen Sie durch angemessene Ressourcenmanagement- und Zuteilungsstrategien eine effiziente Wiederverwendung von Ressourcen für verschiedene Aufgaben sicher und reduzieren Sie Ressourcenverschwendung.
Task-Ausführungsagent
Wir implementieren entsprechende Task-Ausführungsagenten für jede Ausführungs-Engine, um eine einheitliche Verwaltung und Überwachung von Aufgaben zu erreichen:
Ausführungs-Engine-Agent : Im Datenintegrationsdienst verwaltet der Agent verschiedene Ausführungs-Engines wie DataX, Spark, Flink CDC usw. Der Agent ist für das Starten, Stoppen und die Statusüberwachung von Aufgaben verantwortlich.
einheitliche Schnittstelle: Bietet eine einheitliche Aufgabenverwaltungsschnittstelle, sodass Aufgaben verschiedener Engines über dieselbe Schnittstelle verwaltet werden können, wodurch die Betriebs-, Wartungs- und Verwaltungsarbeiten vereinfacht werden.
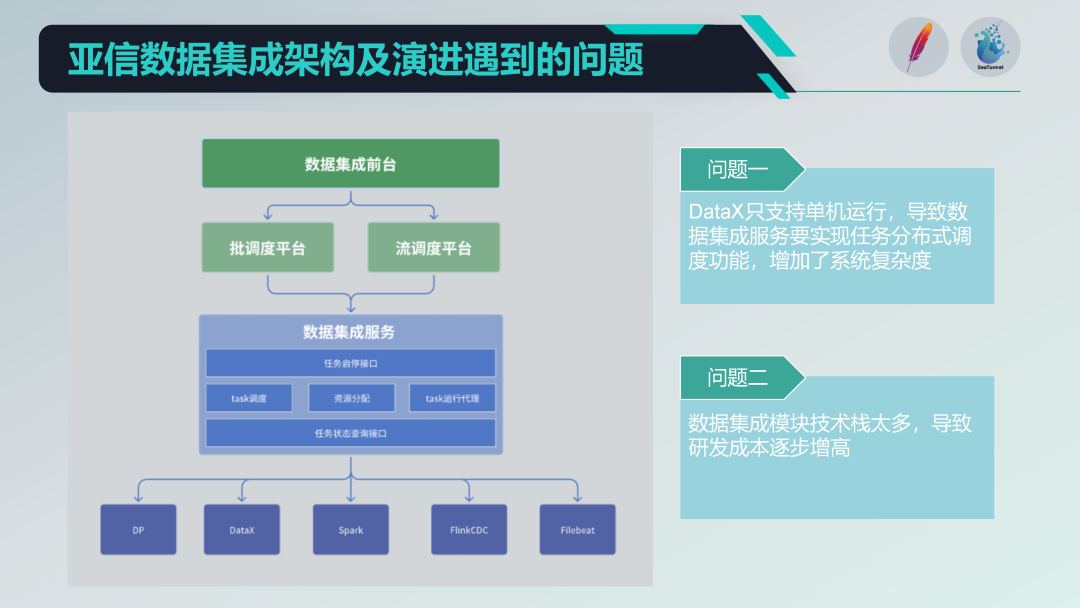
Einige Probleme mit der alten Datenintegrationsarchitektur
Wir haben einige Open-Source-Projekte wie DataX, Spark, Flink CDC, Filebeat usw. integriert, um eine leistungsstarke Plattform für Datenintegrationsdienste zu schaffen. Aber wir stehen auch vor einigen Problemen:
Einschränkungen beim Betrieb einzelner Maschinen: DataX unterstützt nur den Einzelmaschinenbetrieb, weshalb wir auf seiner Basis verteilte Planungsfunktionen implementieren müssen, was die Komplexität des Systems erhöht.
Der Technologie-Stack ist zu vielfältig: Die Einführung mehrerer Technologie-Stacks (wie Spark und Flink) ist zwar reich an Funktionen, führt jedoch auch zu hohen Forschungs- und Entwicklungskosten. Jedes Mal, wenn neue Funktionen entwickelt werden, müssen Kompatibilitäts- und Integrationsprobleme mehrerer Technologie-Stacks gelöst werden.
Architekturentwicklung
Um die Architektur zu optimieren und die Komplexität zu reduzieren, haben wir die bestehende Architektur weiterentwickelt:
Integrieren Sie Multi-Engine-Funktionalität: Nach der Einführung von SeaTunnel können wir die Funktionen mehrerer Engines vereinheitlichen und mehrere Datenverarbeitungsfunktionen auf einer einzigen Plattform erreichen.
Vereinfachen Sie die Ressourcenverwaltung: Die Ressourcenverwaltungsfunktion von SeaTunnel vereinfacht die verteilte Planung eigenständiger Aufgaben wie DataX und reduziert die Komplexität der Ressourcenzuweisung und -verwaltung.
Reduzieren Sie die F&E-Kosten: Durch eine einheitliche Architektur und ein einheitliches Schnittstellendesign werden die durch mehrere Technologie-Stacks verursachten Entwicklungs- und Wartungskosten reduziert und die Skalierbarkeit und Wartungsfreundlichkeit des Systems verbessert.
Durch die Optimierung und Weiterentwicklung der Architektur haben wir die Probleme der DataX-Betriebseinschränkungen auf einer einzelnen Maschine und der hohen Forschungs- und Entwicklungskosten, die durch mehrere Technologie-Stacks verursacht werden, erfolgreich gelöst.
Nach der Einführung von SeaTunnel konnten wir mehrere Datenverarbeitungsfunktionen auf einer Plattform implementieren, gleichzeitig die Ressourcenverwaltung und Aufgabenplanung vereinfachen und die Gesamteffizienz und Stabilität des Systems verbessern.
Warum SeaTunnel wählen?
Unser Kontakt mit SeaTunnel lässt sich bis in die Waterdrop-Zeit zurückverfolgen und wir haben viele Anwendungspraktiken für Waterdrop durchgeführt.
Letztes Jahr startete SeaTunnel die Zeta-Engine, unterstützte die verteilte Architektur und wurde zu einem Top-Level-Apache-Projekt. Dadurch konnten wir letztes Jahr einen geeigneten Zeitpunkt finden, eingehende Recherchen durchführen und uns für die Einführung von SeaTunnel entscheiden.
Hier sind einige der Hauptgründe, warum wir uns für SeaTunnel entschieden haben:
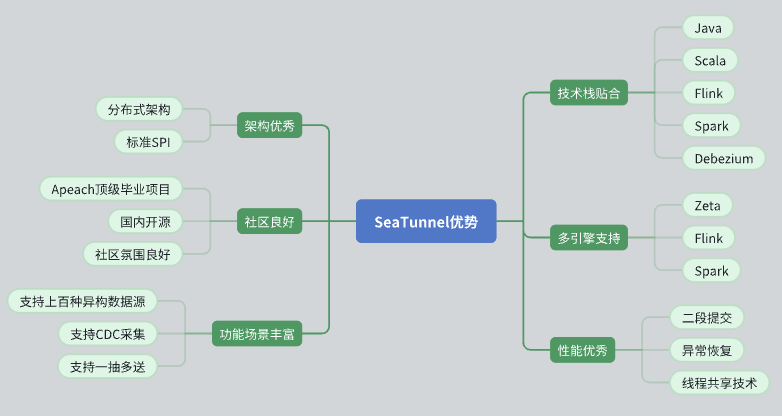
Ausgezeichnetes architektonisches Design
SeaTunnel verfügt über eine verteilte Architektur, die unseren Anforderungen gut entspricht.
Sein API-Design ist standardisiert und übernimmt den SPI-Modus (Service Provider Interface), um die Erweiterung und Integration zu erleichtern.
Aktive Community-Unterstützung
SeaTunnel ist ein Top-Level-Apache-Projekt mit einer guten Community-Atmosphäre. Die aktiven Entwickler- und Benutzergruppen bieten starke Unterstützung bei der Problemlösung und Funktionserweiterung.
Der Hintergrund inländischer Open-Source-Projekte macht unsere Kommunikation und Zusammenarbeit reibungsloser.
Umfangreiche Funktionalität und Datenquellenunterstützung
SeaTunnel unterstützt mehrere Datenquellen und verfügt über umfangreiche Funktionen, um unsere vielfältigen Datenverarbeitungsanforderungen zu erfüllen.
Unterstützt CDC (Change Data Capture) und ermöglicht so die Datensynchronisierung und -verarbeitung in Echtzeit.
Unterstützt den Eins-zu-Viele-Datenübertragungsmodus und verbessert so die Flexibilität der Datenübertragung.
Technologie-Stack-Fit
SeaTunnel ist mit Java kompatibel und unterstützt Flink und Spark, sodass wir es nahtlos in den vorhandenen Technologie-Stack integrieren und anwenden können.
Die Technologie, die Debezium für die CDC-Datenerfassung verwendet, ist ausgereift und stabil.
Unterstützung mehrerer Engines
SeaTunnel unterstützt eine Vielzahl von Computer-Engines, darunter Zeta, Flink und Spark, und kann entsprechend den spezifischen Anforderungen die am besten geeignete Engine für die Berechnung auswählen.
Dies ist sehr wichtig, da es uns ermöglicht, in verschiedenen Szenarien den optimalen Rechenmodus auszuwählen und so die Flexibilität und Effizienz des Systems zu verbessern.
Hervorragende Leistung
SeaTunnel hat Leistungsoptimierungsmechanismen wie zweiphasiges Commit, Fehlertoleranzwiederherstellung und Thread-Sharing entwickelt, um eine effiziente und stabile Datenverarbeitung sicherzustellen.
Probleme nach Einführung von SeaTunnel behoben
SeaTunnel löst die beiden Hauptprobleme, die wir zuvor erwähnt haben:
Verteilte Planung
DataX kann nur auf einem einzelnen Computer ausgeführt werden und wir müssen zusätzliche verteilte Planungsfunktionen implementieren. SeaTunnel unterstützt von Natur aus eine verteilte Architektur, unabhängig davon, ob Zeta, Flink oder Spark als Computer-Engine verwendet werden, es kann problemlos eine verteilte Datenverarbeitung implementieren, was unsere Arbeit erheblich vereinfacht.
Technologie-Stack-Integration
Wir haben zuvor eine Vielzahl von Technologie-Stacks verwendet, darunter DataX, Spark, Flink CDC usw., was die Forschungs- und Entwicklungskosten hoch und das System komplex machte. Durch die einheitliche Kapselung dieser Technologie-Stacks bietet SeaTunnel eine integrierte Plattform, die sowohl ELT- als auch ETL-Prozesse unterstützen kann, wodurch die Systemarchitektur erheblich vereinfacht und die Entwicklungs- und Wartungskosten gesenkt werden.
So integrieren Sie SeaTunnel
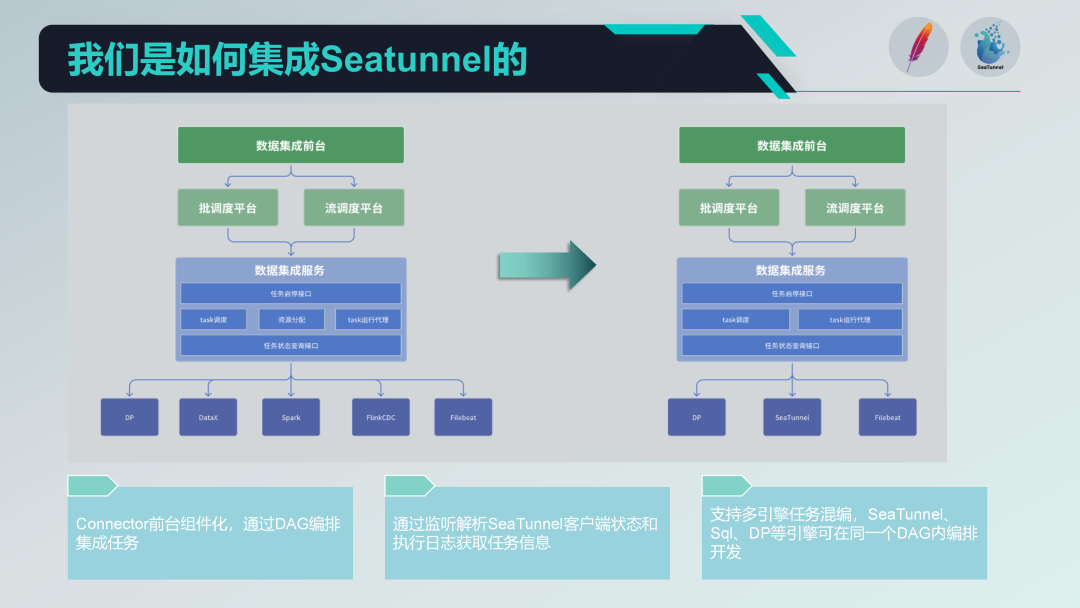
Vor der Integration von SeaTunnel existierte und lief unsere alte Architektur schon seit einiger Zeit. Sie war in drei Schichten unterteilt: Rezeption, Planungsplattform und Datenintegrationsdienst. Die Rezeption ist für die Aufgabenverwaltung und -entwicklung verantwortlich, die Planungsplattform ist für die Aufgabenplanung und das Abhängigkeitsmanagement verantwortlich und der Datenintegrationsdienst ist der Kernbestandteil der Ausführung und Verwaltung aller Datenintegrationsaufgaben.
Das Folgende ist unsere neue Architektur nach der Integration von SeaTunnel.
Zunächst haben wir den Teil der Ressourcenzuweisung der alten Architektur mit DataX eliminiert. Da SeaTunnel selbst eine verteilte Architektur unterstützt, ist kein zusätzliches Ressourcenzuteilungsmanagement mehr erforderlich. Diese Anpassung vereinfacht unsere Architektur erheblich.
Austausch des Technologie-Stacks
Wir haben den alten Technologie-Stack nach und nach durch SeaTunnel ersetzt. Konkrete Schritte sind wie folgt:
Ersetzen von Stapelverarbeitungsaufgaben: Wir haben zunächst den Teil der alten Architektur ersetzt, der DataX und Spark für die Stapelverarbeitung von ETL verwendet hat.
Ersetzen Sie die Stream-Verarbeitungsaufgabe: Als Nächstes werden wir den Teil schrittweise durch Flink CDC für die Stream-Verarbeitung ersetzen. Durch diesen schrittweisen Ansatz können wir sicherstellen, dass das System während des schrittweisen Übergangs stabil bleibt.
Komponentisierter SeaTunnel-Anschluss
Wir führten ein komponentenbasiertes Design auf Basis des Connectors von SeaTunnel durch und führten die Konfiguration und DAG-Orchestrierung über Formulare am Frontend durch. Obwohl auch SeaTunnel Web ähnliche Arbeiten durchführt, haben wir die Entwicklung an unsere eigenen Bedürfnisse angepasst, um eine bessere Integration in bestehende Systeme zu ermöglichen.
Task-Ausführungsagent
Im Hinblick auf Task-Run-Agents übermitteln wir Aufgaben über den SeaTunnel-Client und überwachen den Status und die Ausführungsprotokolle des SeaTunnel-Clients. Durch das Parsen dieser Protokolle können wir Informationen zum Status der Aufgabenausführung erhalten und die Überwachbarkeit und Rückverfolgbarkeit der Aufgabenausführung sicherstellen.
Mehrmotorige Hybridentwicklung
Wir unterstützen die Hybridentwicklung mit mehreren Engines und können die DAG-Orchestrierung mit mehreren Engines für eine Planungsaufgabe auf der Startseite durchführen. Auf diese Weise können wir in einer Planungsaufgabe gleichzeitig verschiedene Engines (z. B. SQL-Engine und DP-Engine) für die Aufgabenentwicklung verwenden und so die Flexibilität und Skalierbarkeit des Systems verbessern.
Bei der Integration von SeaTunnel sind Probleme aufgetreten
Bei der Integration von SeaTunnel sind wir auf einige Probleme gestoßen. Im Folgenden sind einige repräsentative Probleme und ihre Lösungen aufgeführt:
Frage 1: Fehlerbehandlung
Bei der Verwendung von SeaTunnel sind wir auf einige Fehlerberichte gestoßen, die sich auf den Code des Frameworks beziehen. Da es in den offiziellen Dokumenten keine relevanten Anweisungen gibt, sind wir der WeChat-Community-Gruppe beigetreten, haben die Entwickler in der Gruppe um Hilfe gebeten und das Problem rechtzeitig gelöst.
Frage 2: Aufgabenumstellung
Unsere alten Erfassungsaufgaben wurden mit DataX implementiert. Wenn wir sie durch SeaTunnel ersetzen, müssen wir Probleme bei der Aufgabenumstellung berücksichtigen.
Wir lösen es durch die folgenden Lösungen:
Komponentendesign : Unsere Datenerfassungsaufgaben im Middle Office sind komponentenbasiert konzipiert und es gibt eine Konvertierungsschicht zwischen den Front-End-Komponenten und der Back-End-Ausführungs-Engine. Das Frontend konfiguriert das Formular und das Backend generiert die JSON-Datei, die DataX über die Konvertierungsschicht ausführen muss.
Ähnliche JSON-Dateigenerierung : Die Konfiguration von SeaTunnel ähnelt der von DataX. Das Frontend wird ebenfalls über ein Formular konfiguriert und die JSON-Datei, die SeaTunnel ausführen muss, wird im Backend generiert. Auf diese Weise können wir alte Aufgaben nahtlos auf die neue SeaTunnel-Plattform übertragen und so einen reibungslosen Übergang der Aufgaben gewährleisten.
SQL-Skriptkonvertierung : Schreiben Sie SQL-Skripte, um alte DataX-Aufgaben zu bereinigen und zu konvertieren, damit sie sich an SeaTunnel anpassen können. Diese Methode ist flexibler und anpassungsfähiger, da SeaTunnel häufig aktualisiert wird und das direkte Schreiben von Hartcodierung aus Kompatibilitätsgründen keine langfristige Lösung darstellt. Durch die Skriptkonvertierung können Aufgaben effizienter migriert werden, um sie an SeaTunnel-Updates anzupassen.
Frage 3: Versionsverwaltung
Bei der Verwendung von SeaTunnel sind Probleme mit der Versionsverwaltung aufgetreten. SeaTunnel wird regelmäßig aktualisiert und unser Team muss die neueste Version für die zweite Version kontinuierlich weiterverfolgen. Hier ist unsere Lösung:
Lokale Filialleitung : Wir haben einen lokalen Zweig basierend auf SeaTunnel Version 2.3.2 erstellt und eine sekundäre Entwicklung darauf durchgeführt, einschließlich der Behebung personalisierter Anforderungen und vorübergehender Fehlerbehebungen. Um den Umfang des lokal gepflegten Codes zu minimieren, behalten wir nur notwendige Änderungen bei und versuchen, für andere Teile die neueste Version aus der Community zu verwenden.
Regelmäßig integrierte Community-Updates : Wir führen regelmäßig neue Versionen aus der Community in den lokalen Zweig ein, insbesondere um sie zu aktualisieren und mit den von uns geänderten Teilen kompatibel zu machen. Obwohl diese Methode umständlich ist, stellt sie sicher, dass wir über die neuesten Funktionen und Korrekturen der Community auf dem Laufenden bleiben.
Geben Sie der Gemeinschaft etwas zurück : Um den Code besser verwalten und pflegen zu können, planen wir, einige unserer Änderungen und personalisierten Anforderungen an die Community zu übermitteln, um Akzeptanz und Unterstützung durch die Community zu erreichen. Dies trägt nicht nur dazu bei, unsere Wartungsarbeiten vor Ort zu reduzieren, sondern trägt auch zur gemeinsamen Entwicklung der Gemeinschaft bei.
Sekundäre Entwicklung und Praxis von SeaTunnel
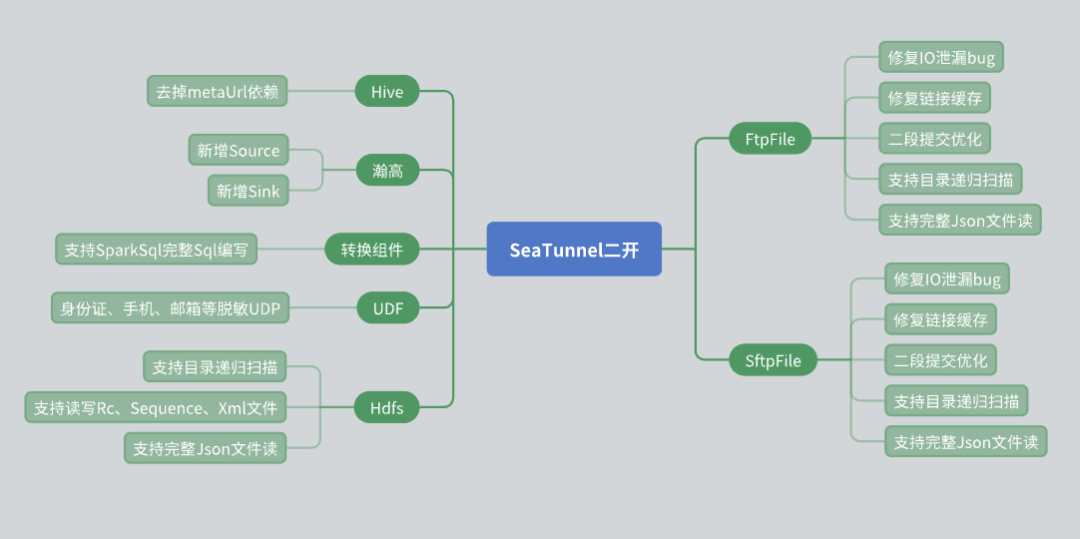
Während des Einsatzes von SeaTunnel haben wir eine Reihe sekundärer Entwicklungen basierend auf den tatsächlichen Geschäftsanforderungen durchgeführt, insbesondere auf der Connector-Ebene. Im Folgenden sind die Probleme und Lösungen aufgeführt, auf die wir während der Sekundärentwicklung gestoßen sind.
Renovierung des Hive Connectors
Der ursprüngliche SeaTunnel Hive Connector nutzt die Meta-URL, um Metadaten abzurufen. In tatsächlichen Anwendungen sind viele Drittbenutzer jedoch aus Sicherheitsgründen nicht in der Lage, Meta-URLs bereitzustellen. Um dieser Situation gerecht zu werden, haben wir folgende Änderungen vorgenommen:
Verwenden Sie die JDBC-Schnittstelle von Hive Server 2, um die Metadateninformationen der Tabelle abzurufen und so eine Abhängigkeit von der Meta-URL zu vermeiden.
Auf diese Weise können wir Benutzern die Möglichkeit geben, Hive-Daten flexibler zu lesen und zu schreiben und gleichzeitig die Datensicherheit zu gewährleisten.
Unterstützung der Hangao-Datenbank
Die Hangao-Datenbank wird in unseren Projekten häufig verwendet, daher haben wir Unterstützung für das Lesen und Schreiben von Datenquellen für die Hangao-Datenbank hinzugefügt. Gleichzeitig haben wir Konvertierungskomponenten entwickelt, um einige spezielle Anforderungen der Hangao-Datenbank zu erfüllen:
Unterstützt komplexe Konvertierungsvorgänge wie Zeile zu Spalte und Spalte zu Zeile.
Er hat verschiedene UDFs (benutzerdefinierte Funktionen) für die Desensibilisierung von Daten und andere Vorgänge geschrieben.
Änderung des Dateikonnektors
Der File System Connector spielt bei unserer Nutzung eine wichtige Rolle, daher haben wir mehrere Änderungen daran vorgenommen:
HDFS-Anschluss: Die Funktion der Verzeichnisrekursion und des Scannens von Dateien mit regulären Ausdrücken wurde hinzugefügt und unterstützt gleichzeitig das Lesen und Schreiben mehrerer Dateiformate (wie RC, Sequence, XML, JSON).
FTP- und SFTP-Anschlüsse: Der I/O-Leak-Fehler wurde behoben und der Verbindungs-Caching-Mechanismus optimiert, um die Unabhängigkeit zwischen verschiedenen Konten mit derselben IP sicherzustellen.
Optimierung des zweistufigen Einreichungsmechanismus
Bei der Verwendung von SeaTunnel verfügen wir über ein umfassendes Verständnis des zweistufigen Übermittlungsmechanismus zur Gewährleistung der Datenkonsistenz. Im Folgenden sind die Probleme und Lösungen aufgeführt, auf die wir während dieses Prozesses gestoßen sind:
Problembeschreibung : Beim Verwenden von FTP und SFTP zum Schreiben von Dateien wird eine Fehlermeldung angezeigt, dass keine Schreibberechtigung vorliegt. Die Untersuchung ergab, dass SeaTunnel die Datei zunächst in das temporäre Verzeichnis schreibt und sie dann verschiebt, um die Datenkonsistenz sicherzustellen.
Der Schreibvorgang schlug jedoch aufgrund der Berechtigungseinstellungen verschiedener Konten im temporären Verzeichnis fehl.
Lösung : Legen Sie beim Erstellen eines temporären Verzeichnisses höhere Berechtigungen fest (z. B. 777), um sicherzustellen, dass alle Konten über Schreibberechtigungen verfügen. Gleichzeitig wird das Problem des Umbenennungsbefehlsfehlers aufgrund dateiübergreifender Dateiverschiebungen gelöst. Durch die Erstellung eines temporären Verzeichnisses unter demselben Dateisystem werden dateisystemübergreifende Vorgänge vermieden.
Sekundäres Entwicklungsmanagement
Während des sekundären Entwicklungsprozesses standen wir vor dem Problem, wie wir die neue Version von SeaTunnel verwalten und synchronisieren sollten. Unsere Lösung lautet wie folgt:
Lokale Filialleitung: Einen lokalen Zweig basierend auf der SeaTunnel 2.3.2-Version gezogen
Regelmäßig integrierte Community-Updates: Führen Sie regelmäßig neue Versionen der Community in lokalen Zweigstellen zusammen, um sicherzustellen, dass wir zeitnah neue Funktionen und Korrekturen von der Community erhalten.
Geben Sie der Gemeinschaft etwas zurück: Wir planen, einige unserer Änderungen und personalisierten Anforderungen der Community vorzulegen, um die Akzeptanz und Unterstützung der Community zu gewinnen und so den Arbeitsaufwand für die lokale Wartung zu reduzieren.
SeaTunnel-Integration und -Anwendungen
Bei der Integration von SeaTunnel konzentrieren wir uns hauptsächlich auf folgende Punkte:
Optimierung der Ressourcenzuteilung: Die Verwendung der verteilten Architektur von SeaTunnel vereinfacht das Problem der Ressourcenzuweisung und erfordert keine zusätzlichen verteilten Planungsfunktionen mehr.
Technologie-Stack-Integration: Integrieren Sie die Funktionen verschiedener Technologie-Stacks wie DataX, Spark und FlinkCDC in SeaTunnel und kapseln Sie sie einheitlich, um die Integration von ETL und ELT zu erreichen.
Durch die oben genannten Schritte und Strategien haben wir SeaTunnel erfolgreich in unseren Datenintegrationsdienst integriert, einige wichtige Probleme im alten System gelöst und die Leistung und Stabilität des Systems optimiert.
Während dieses Prozesses beteiligen wir uns aktiv an der Community, suchen Hilfe und geben Feedback zu Problemen, um den reibungslosen Ablauf der Integrationsarbeit sicherzustellen. Diese positive Interaktion verbessert nicht nur unser technisches Niveau, sondern fördert auch die Entwicklung der SeaTunnel-Community.
Erfahrung in der Teilnahme an der Open-Source-Community
Im Rahmen meiner Teilnahme an SeaTunnel habe ich folgende Erfahrungen gemacht:
Es ist jetzt Zeit : Wir haben uns für dieses Projekt in der schnellen Entwicklungsphase von SeaTunnel entschieden und das Timing war sehr gut. Die Entwicklung von SeaTunnel gibt uns große Zuversicht, dass noch viel getan werden kann.
persönliche Ziele: Ich habe mir zum Ziel gesetzt, mich Anfang dieses Jahres an der Open-Source-Community zu beteiligen und setze dies aktiv in die Tat um.
Gemeinschaftsfreundlichkeit : Die SeaTunnel-Community ist sehr freundlich, alle kommunizieren reibungslos und helfen sich gegenseitig. Diese positive Atmosphäre macht es für mich sehr lohnenswert, dabei zu sein.
Diejenigen unter Ihnen, die schon immer Teil der Open-Source-Community sein wollten, aber noch nicht den ersten Schritt gemacht haben, möchte ich ermutigen, den Sprung zu wagen. Das Wichtigste an einer Community sind ihre Menschen. Solange Sie Mitglied sind, sind Sie ein unverzichtbarer Teil der Community.
Erwartungen an SeaTunnel
Abschließend möchte ich einige Erwartungen an SeaTunnel mitteilen:
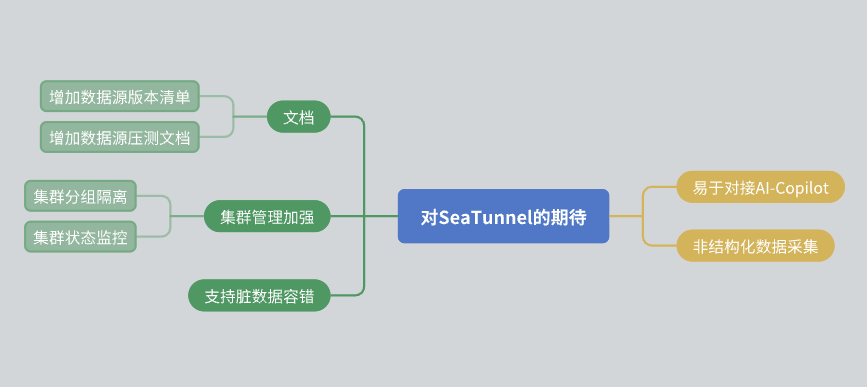
Verbesserungen der Dokumentation: Ich hoffe, dass die Community die Dokumentation weiter verbessern kann, einschließlich der Versionsliste der Datenquellen und Stresstestberichte.
Clustermanagement: Es besteht die Hoffnung, dass SeaTunnel eine Ressourcenisolation innerhalb des Clusters erreichen und umfassendere Informationen zur Clusterstatusüberwachung bereitstellen kann.
Datenfehlertoleranz: Obwohl SeaTunnel bereits über einen fehlertoleranten Mechanismus verfügt, hoffen wir, dass dieser in Zukunft weiter optimiert werden kann.
KI-Integration: Ich hoffe, dass SeaTunnel mehr Schnittstellen bereitstellen kann, um den KI-gestützten Zugang zu erleichtern.
Vielen Dank an alle Mitglieder der SeaTunnel-Community für Ihre harte Arbeit. Das ist alles, was ich teile, vielen Dank an alle!