Berbagi praktis Teknologi AsiaInfo tentang Apache SeaTunnel
Perkenalan diri
Halo rekan-rekan pelajar, Saya merasa terhormat bisa berbagi dan berkomunikasi dengan Anda melalui komunitas Apache SeaTunnel. Saya Pan Zhihong dari AsiaInfo Technology. Saya terutama bertanggung jawab atas pengembangan produk pusat data internal perusahaan.
Topik sharing kali ini adalah praktik integrasi Apache SeaTunnel dalam Teknologi AsiaInfo. Secara khusus, kami akan membahas tentang bagaimana pusat data kami mengintegrasikan SeaTunnel.
Bagikan ikhtisar konten
Dalam sharing ini, saya akan fokus pada aspek-aspek berikut:
Mengapa memilih SeaTunnel
Bagaimana mengintegrasikan SeaTunnel
Masalah yang dihadapi selama mengintegrasikan SeaTunnel
Pengembangan sekunder SeaTunnel
Harapan untuk SeaTunnel
Mengapa memilih SeaTunnel
Pertama-tama, izinkan saya memperkenalkan bahwa saya terutama bertanggung jawab atas pengembangan berulang produk pusat data AsiaInfo, DATAOS. DATAOS adalah produk pusat data yang relatif standar, mencakup modul fungsional seperti integrasi data, pengembangan data, tata kelola data, dan keterbukaan data. Hal utama yang terkait dengan SeaTunnel adalah modul integrasi data, yang terutama bertanggung jawab untuk integrasi data.
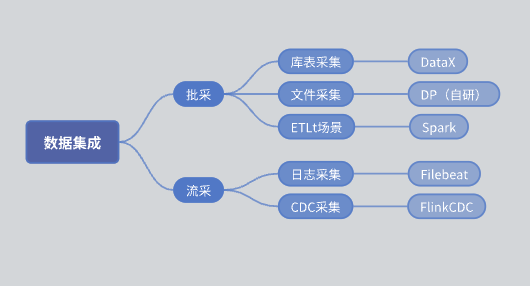
Sebelum SeaTunnel diperkenalkan, arsitektur fungsional modul integrasi data kami adalah sebagai berikut:
pembelian batch: Dibagi menjadi koleksi tabel perpustakaan dan koleksi file.
Koleksi tabel perpustakaan: terutama diimplementasikan menggunakan DataX.
Koleksi file: mesin DP yang dikembangkan sendiri.
Koleksi ETLt: mesin pengumpul ETLt yang dikembangkan sendiri. DataX lebih memilih ELT (ekstraksi, pemuatan, konversi), yang cocok untuk konversi kompleks setelah ekstraksi dan penyimpanan data. Namun, dalam beberapa skenario, EL T kecil (ekstraksi, pemuatan, konversi sederhana) diperlukan, dan DataX tidak cocok. Oleh karena itu, kami mengembangkan mesin berdasarkan Spark SQL.
Liucai: Pengumpulan log sebagian besar didasarkan pada Filebeat, dan pengumpulan CDC sebagian besar didasarkan pada Flink CDC.
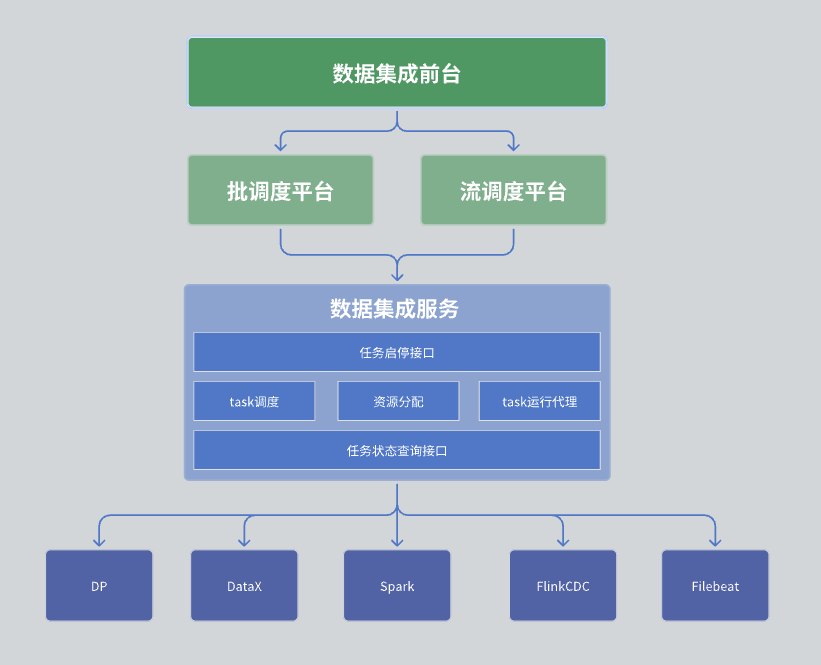
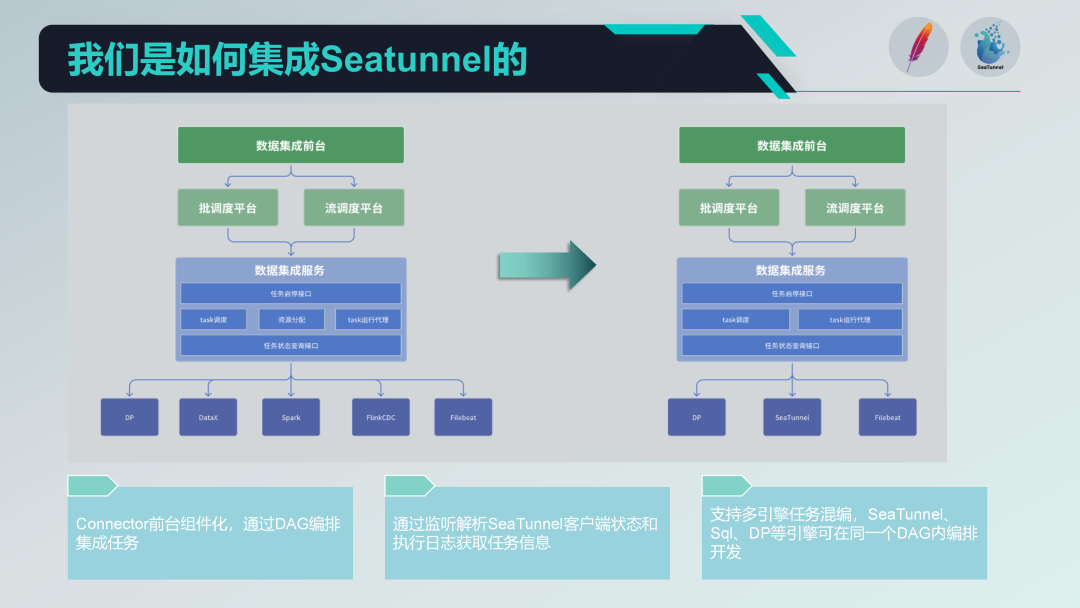
Dalam modul integrasi data kami, keseluruhan arsitektur dibagi menjadi tiga lapisan, yaitu front desk integrasi data, platform penjadwalan, dan layanan integrasi data.
Di bawah ini adalah penjelasan rinci dari setiap lapisan:
Lapisan pertama: meja depan integrasi data
Meja depan integrasi data terutama bertanggung jawab atas pengelolaan tugas integrasi data. Secara khusus, ini mencakup pengembangan tugas, pengembangan penjadwalan, dan pemantauan operasi. Tugas-tugas ini menggabungkan berbagai operator terintegrasi melalui DAG (Directed Acyclic Graph) untuk mengimplementasikan proses pemrosesan data yang kompleks. Antarmuka front-end menyediakan antarmuka manajemen tugas yang intuitif, memungkinkan pengguna dengan mudah mengonfigurasi dan memantau tugas integrasi data.
Lapisan kedua: Platform penjadwalan
Platform penjadwalan bertanggung jawab atas penjadwalan dan pengelolaan operasi tugas. Ini mendukung mode pemrosesan batch dan pemrosesan aliran, dan dapat menjalankan tugas terkait berdasarkan ketergantungan tugas dan strategi penjadwalan.
Lapisan ketiga: layanan integrasi data
Layanan integrasi data adalah inti dari keseluruhan layanan pusat data, yang menyediakan serangkaian fungsi utama:
Antarmuka manajemen tugas: Termasuk fungsi seperti pembuatan tugas, penghapusan, pembaruan, dan kueri.
Antarmuka memulai dan menghentikan tugas: Memungkinkan pengguna untuk memulai atau menghentikan tugas tertentu.
Antarmuka kueri status tugas: Meminta informasi status tugas saat ini untuk memfasilitasi pemantauan dan pengelolaan.
Layanan integrasi data juga bertanggung jawab atas pelaksanaan tugas tertentu. Karena tugas pengumpulan kita mungkin mencakup beberapa mesin, hal ini memerlukan koordinasi dan penjadwalan multi-mesin saat tugas sedang berjalan.
Proses menjalankan tugas
Menjalankan tugas terutama mencakup langkah-langkah berikut:
Penjadwalan tugas: Menurut strategi dan ketergantungan penjadwalan yang telah ditentukan, platform penjadwalan mengambil tugas yang sesuai.
Eksekusi tugas: Selama eksekusi tugas, setiap operator dieksekusi secara berurutan sesuai dengan konfigurasi DAG tugas tersebut.
Koordinasi multi-mesin: Untuk tugas yang berisi beberapa mesin (seperti tugas hibrida DataX dan Spark), pengoperasian setiap mesin perlu dikoordinasikan selama proses eksekusi untuk memastikan kelancaran pelaksanaan tugas.
Alokasi sumber daya
Pada saat yang sama, untuk memungkinkan DataX, tugas yang berdiri sendiri, berjalan lebih baik secara terdistribusi dan mencapai penggunaan kembali sumber daya, kami telah mengoptimalkan alokasi sumber daya untuk tugas DataX:
Penjadwalan terdistribusi: Melalui mekanisme alokasi sumber daya, tugas-tugas DataX didistribusikan untuk dijalankan di beberapa node untuk menghindari kemacetan satu titik dan meningkatkan paralelisme tugas dan efisiensi eksekusi.
Penggunaan kembali sumber daya: Melalui pengelolaan sumber daya dan strategi alokasi yang wajar, memastikan penggunaan kembali sumber daya secara efisien untuk berbagai tugas dan mengurangi pemborosan sumber daya.
agen yang menjalankan tugas
Kami menerapkan agen pelaksanaan tugas yang sesuai untuk setiap mesin eksekusi untuk mencapai manajemen terpadu dan pemantauan tugas:
agen mesin eksekusi : Dalam layanan integrasi data, agen mengelola berbagai mesin eksekusi, seperti DataX, Spark, Flink CDC, dll. Agen bertanggung jawab untuk memulai, menghentikan, dan memantau status tugas.
antarmuka terpadu: Menyediakan antarmuka manajemen tugas terpadu sehingga tugas mesin yang berbeda dapat dikelola melalui antarmuka yang sama, menyederhanakan pekerjaan pengoperasian, pemeliharaan, dan manajemen.
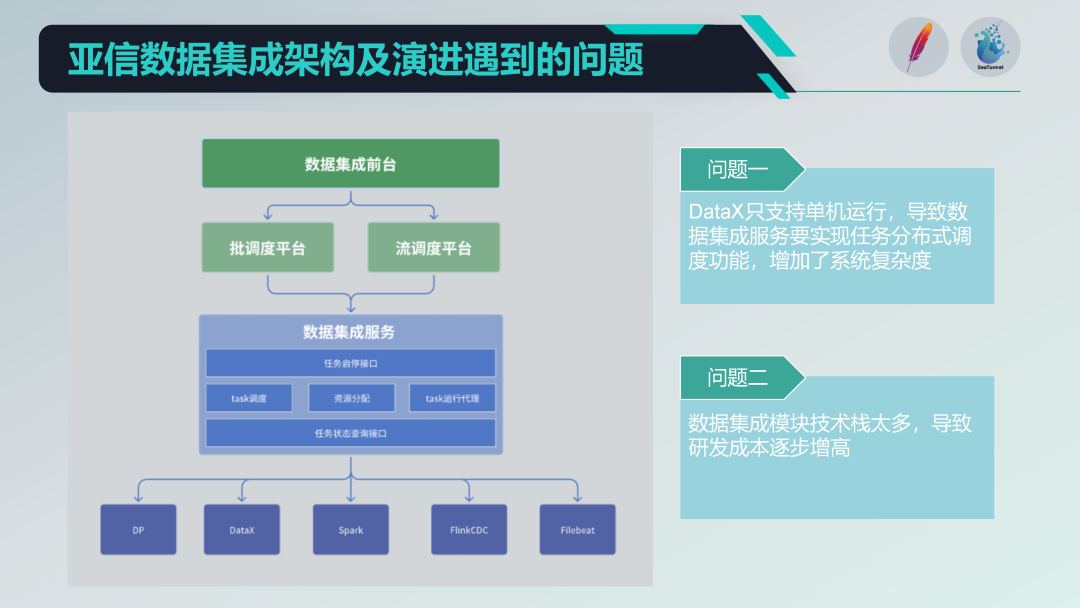
Beberapa masalah dengan arsitektur integrasi data lama
Kami telah mengintegrasikan beberapa proyek sumber terbuka, seperti DataX, Spark, Flink CDC, Filebeat, dll., untuk membentuk platform layanan integrasi data yang kuat. Namun kami juga menghadapi beberapa masalah:
Pembatasan pengoperasian mesin tunggal: DataX hanya mendukung operasi mesin tunggal, yang mengharuskan kami menerapkan fungsi penjadwalan terdistribusi berdasarkan data tersebut, sehingga meningkatkan kompleksitas sistem.
Tumpukan teknologi terlalu beragam: Berbagai tumpukan teknologi (seperti Spark dan Flink) telah diperkenalkan. Meskipun kaya akan fungsi, mereka juga memerlukan biaya penelitian dan pengembangan yang tinggi. Setiap kali mereka mengembangkan fungsi baru, mereka harus menghadapi masalah kompatibilitas dan integrasi beberapa tumpukan teknologi.
Evolusi arsitektur
Untuk mengoptimalkan arsitektur dan mengurangi kompleksitas, kami mengembangkan arsitektur yang ada:
Integrasikan fungsionalitas multi-mesin: Setelah memperkenalkan SeaTunnel, kami dapat menyatukan fungsi beberapa mesin dan mencapai berbagai kemampuan pemrosesan data pada satu platform.
Sederhanakan pengelolaan sumber daya: Fungsi manajemen sumber daya SeaTunnel menyederhanakan penjadwalan terdistribusi untuk tugas-tugas yang berdiri sendiri seperti DataX, dan mengurangi kompleksitas alokasi dan pengelolaan sumber daya.
Mengurangi biaya penelitian dan pengembangan: Melalui arsitektur terpadu dan desain antarmuka, biaya pengembangan dan pemeliharaan yang disebabkan oleh berbagai tumpukan teknologi berkurang, dan skalabilitas serta kemudahan pemeliharaan sistem ditingkatkan.
Melalui optimalisasi dan evolusi arsitektur, kami telah berhasil memecahkan masalah keterbatasan operasi mesin tunggal DataX dan tingginya biaya penelitian dan pengembangan yang disebabkan oleh berbagai tumpukan teknologi.
Setelah memperkenalkan SeaTunnel, kami dapat menerapkan beberapa fungsi pemrosesan data pada satu platform, sekaligus menyederhanakan manajemen sumber daya dan penjadwalan tugas, serta meningkatkan efisiensi dan stabilitas sistem secara keseluruhan.
Mengapa memilih SeaTunnel?
Kontak kami dengan SeaTunnel dapat ditelusuri kembali ke periode Waterdrop, dan kami telah melakukan banyak praktik penerapan untuk Waterdrop.
Tahun lalu, SeaTunnel meluncurkan mesin Zeta, mendukung arsitektur terdistribusi, dan menjadi proyek Apache tingkat atas. Hal ini memungkinkan kami menemukan titik waktu yang sesuai tahun lalu, melakukan penelitian mendalam, dan memutuskan untuk memperkenalkan SeaTunnel.
Berikut adalah beberapa alasan utama mengapa kami memilih SeaTunnel:
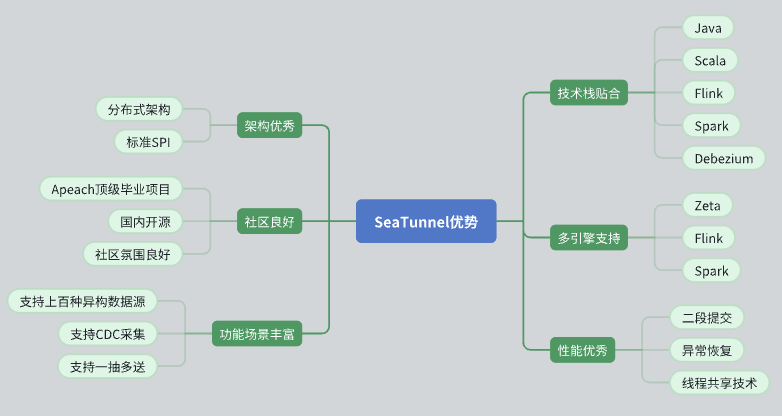
Desain arsitektur yang luar biasa
SeaTunnel memiliki arsitektur terdistribusi yang berfungsi dengan baik untuk kebutuhan kita.
Desain API-nya terstandarisasi dan mengadopsi mode SPI (Service Provider Interface) untuk memfasilitasi perluasan dan integrasi.
Dukungan komunitas yang aktif
SeaTunnel adalah proyek Apache tingkat atas dengan suasana komunitas yang baik. Pengembang aktif dan kelompok pengguna memberikan dukungan kuat untuk pemecahan masalah dan perluasan fungsi.
Latar belakang proyek open source dalam negeri membuat komunikasi dan kolaborasi kami lebih lancar.
Fungsionalitas yang kaya dan dukungan sumber data
SeaTunnel mendukung berbagai sumber data dan memiliki beragam fungsi untuk memenuhi beragam kebutuhan pemrosesan data kami.
Mendukung CDC (Change Data Capture), memungkinkan sinkronisasi dan pemrosesan data real-time.
Mendukung mode transmisi data satu-ke-banyak, meningkatkan fleksibilitas transmisi data.
Tumpukan teknologi cocok
SeaTunnel kompatibel dengan Java dan mendukung Flink dan Spark, memungkinkan kami mengintegrasikan dan menerapkannya dengan lancar pada tumpukan teknologi yang ada.
Menggunakan Debezium untuk pengambilan data CDC, teknologinya sudah matang dan stabil.
Dukungan multi-mesin
SeaTunnel mendukung berbagai mesin komputasi, termasuk Zeta, Flink, dan Spark, dan dapat memilih mesin yang paling sesuai untuk penghitungan sesuai dengan kebutuhan spesifik.
Hal ini sangat penting karena memungkinkan kita memilih mode komputasi optimal dalam berbagai skenario, sehingga meningkatkan fleksibilitas dan efisiensi sistem.
Kinerja Luar Biasa
SeaTunnel telah merancang mekanisme pengoptimalan kinerja seperti penerapan dua fase, pemulihan toleransi kesalahan, dan berbagi thread untuk memastikan pemrosesan data yang efisien dan stabil.
Masalah terpecahkan setelah memperkenalkan SeaTunnel
SeaTunnel memecahkan dua masalah utama yang kami sebutkan sebelumnya:
Penjadwalan terdistribusi
DataX hanya dapat berjalan di satu mesin, dan kita perlu mengimplementasikan fungsi penjadwalan terdistribusi tambahan. SeaTunnel secara inheren mendukung arsitektur terdistribusi. Baik menggunakan Zeta, Flink, atau Spark sebagai mesin komputasinya, SeaTunnel dapat dengan mudah mengimplementasikan pemrosesan data terdistribusi, sehingga sangat menyederhanakan pekerjaan kami.
Integrasi tumpukan teknologi
Kami sebelumnya telah menggunakan berbagai tumpukan teknologi, termasuk DataX, Spark, Flink CDC, dll., yang membuat biaya penelitian dan pengembangan menjadi tinggi dan sistem menjadi rumit. Dengan merangkum tumpukan teknologi ini secara seragam, SeaTunnel menyediakan platform terintegrasi yang dapat mendukung proses ELT dan ETL, sehingga sangat menyederhanakan arsitektur sistem dan mengurangi biaya pengembangan dan pemeliharaan.
Bagaimana mengintegrasikan SeaTunnel
Sebelum mengintegrasikan SeaTunnel, arsitektur lama kami telah ada dan berjalan selama beberapa waktu. Arsitektur ini dibagi menjadi tiga lapisan: meja depan, platform penjadwalan, dan layanan integrasi data. Meja depan bertanggung jawab atas manajemen dan pengembangan tugas, platform penjadwalan bertanggung jawab atas penjadwalan tugas dan manajemen ketergantungan, dan layanan integrasi data adalah bagian inti dalam melaksanakan dan mengelola semua tugas integrasi data.
Berikut ini adalah arsitektur baru kami setelah mengintegrasikan SeaTunnel.
Pertama, kami menghilangkan bagian alokasi sumber daya dari arsitektur lama yang melibatkan DataX. Karena SeaTunnel sendiri mendukung arsitektur terdistribusi, manajemen alokasi sumber daya tambahan tidak lagi diperlukan. Penyesuaian ini sangat menyederhanakan arsitektur kami.
Penggantian tumpukan teknologi
Kami secara bertahap mengganti tumpukan teknologi lama dengan SeaTunnel. Langkah-langkah spesifiknya adalah sebagai berikut:
Mengganti tugas pemrosesan batch: Pertama-tama kami mengganti bagian arsitektur lama yang menggunakan DataX dan Spark untuk ETL pemrosesan batch.
Ganti tugas pemrosesan aliran: Selanjutnya, kami akan mengganti bagian secara bertahap menggunakan Flink CDC untuk pemrosesan aliran. Dengan mengambil pendekatan langkah demi langkah ini, kami dapat memastikan bahwa sistem tetap stabil selama transisi bertahap.
Konektor SeaTunnel Terkomponen
Kami melakukan desain berbasis komponen berdasarkan Konektor SeaTunnel, dan melakukan konfigurasi dan orkestrasi DAG melalui formulir di ujung depan. Meskipun SeaTunnel Web juga melakukan pekerjaan serupa, kami telah menyesuaikan pengembangan sesuai dengan kebutuhan kami agar lebih terintegrasi dengan sistem yang ada.
agen yang menjalankan tugas
Dalam hal agen yang menjalankan tugas, kami mengirimkan tugas melalui klien SeaTunnel dan memantau status dan log eksekusi klien SeaTunnel. Dengan menguraikan log ini, kami dapat memperoleh informasi status pelaksanaan tugas dan memastikan kemampuan pemantauan dan penelusuran pelaksanaan tugas.
Pengembangan hibrida multi-mesin
Kami mendukung pengembangan hibrida multi-mesin, dan dapat melakukan orkestrasi DAG multi-mesin pada tugas penjadwalan di halaman depan. Dengan cara ini, kita dapat menggunakan mesin yang berbeda (seperti mesin SQL dan mesin DP) dalam satu tugas penjadwalan secara bersamaan untuk pengembangan tugas, sehingga meningkatkan fleksibilitas dan skalabilitas sistem.
Masalah yang dihadapi selama mengintegrasikan SeaTunnel
Dalam proses integrasi SeaTunnel, kami menemui beberapa masalah. Berikut adalah beberapa masalah yang mewakili dan solusinya:
Pertanyaan 1: Penanganan kesalahan
Dalam proses penggunaan SeaTunnel, kami menemukan beberapa laporan kesalahan, yang terkait dengan kode kerangka kerja. Karena tidak ada instruksi yang relevan dalam dokumen resmi, kami bergabung dengan grup komunitas WeChat dan meminta bantuan pengembang di grup tersebut, dan menyelesaikan masalah tepat waktu.
Pertanyaan 2: Peralihan tugas
Tugas pengumpulan lama kami diimplementasikan menggunakan DataX. Saat menggantinya dengan SeaTunnel, kami perlu mempertimbangkan masalah peralihan tugas.
Kami menyelesaikannya melalui solusi berikut:
Desain komponen : Tugas pengumpulan data kami di kantor tengah dirancang berbasis komponen, dan terdapat lapisan konversi antara komponen front-end dan mesin eksekusi back-end. Frontend mengonfigurasi formulir, dan backend menghasilkan file JSON yang perlu dijalankan DataX melalui lapisan konversi.
Pembuatan file JSON serupa : Konfigurasi SeaTunnel mirip dengan DataX. Frontend juga dikonfigurasi melalui formulir, dan file JSON yang perlu dijalankan SeaTunnel dibuat di backend. Dengan cara ini, kami dapat dengan mudah mentransfer tugas-tugas lama ke platform SeaTunnel baru, sehingga memastikan kelancaran transisi tugas.
Konversi skrip SQL : Tulis skrip SQL untuk membersihkan dan mengonversi tugas DataX lama sehingga dapat beradaptasi dengan SeaTunnel. Metode ini lebih fleksibel dan mudah beradaptasi, karena SeaTunnel akan sering diperbarui, dan menulis hard coding secara langsung untuk kompatibilitas bukanlah solusi jangka panjang. Melalui konversi skrip, tugas dapat dimigrasikan dengan lebih efisien untuk beradaptasi dengan pembaruan SeaTunnel.
Pertanyaan 3: Manajemen versi
Kami mengalami masalah manajemen versi saat menggunakan SeaTunnel. SeaTunnel sering diperbarui, dan tim kami perlu terus menindaklanjuti versi terbaru untuk versi kedua. Inilah solusi kami:
Manajemen cabang lokal : Kami menarik cabang lokal berdasarkan SeaTunnel versi 2.3.2 dan melakukan pengembangan sekunder pada cabang tersebut, termasuk memperbaiki persyaratan yang dipersonalisasi dan perbaikan bug sementara. Untuk meminimalkan jumlah kode yang dikelola secara lokal, kami hanya menyimpan perubahan yang diperlukan, dan mencoba menggunakan versi terbaru dari komunitas untuk bagian lain.
Pembaruan komunitas yang dimasukkan secara teratur : Kami secara rutin menggabungkan versi baru dari komunitas ke dalam cabang lokal, terutama untuk memperbarui dan membuatnya kompatibel dengan bagian yang telah kami ubah. Meskipun metode ini canggung, metode ini memastikan bahwa kami selalu mengikuti perkembangan fitur dan perbaikan terbaru dari komunitas.
Berikan kembali kepada komunitas : Untuk mengelola dan memelihara kode dengan lebih baik, kami berencana untuk mengirimkan beberapa perubahan dan persyaratan yang dipersonalisasi kepada komunitas untuk mengupayakan penerimaan dan dukungan komunitas. Hal ini tidak hanya membantu mengurangi pekerjaan pemeliharaan lokal kami, namun juga membantu masyarakat berkembang bersama.
Pengembangan dan praktik sekunder SeaTunnel
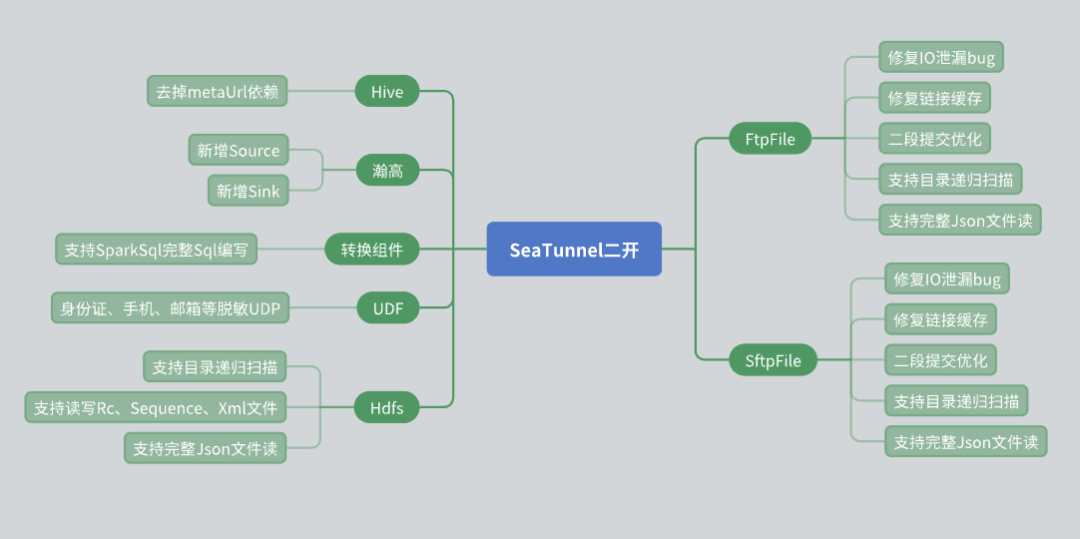
Selama penggunaan SeaTunnel, kami melakukan sejumlah pengembangan sekunder berdasarkan kebutuhan bisnis aktual, terutama di tingkat konektor. Berikut ini adalah permasalahan dan solusi yang kami temui pada saat pengembangan sekunder.
Renovasi Konektor Sarang
Konektor SeaTunnel Hive asli mengandalkan URL Meta untuk mendapatkan metadata. Namun, dalam aplikasi sebenarnya, banyak pengguna pihak ketiga tidak dapat memberikan URL Meta karena masalah keamanan. Untuk menghadapi situasi ini, kami telah melakukan perubahan berikut:
Gunakan antarmuka JDBC Hive Server 2 untuk mendapatkan informasi metadata tabel, sehingga menghindari ketergantungan pada Meta URL.
Dengan cara ini, kami dapat memberi pengguna kemampuan untuk membaca dan menulis data Hive dengan lebih fleksibel sekaligus memastikan keamanan data.
Dukungan basis data Hangao
Basis data Hangao banyak digunakan dalam proyek kami, jadi kami telah menambahkan dukungan membaca dan menulis sumber data untuk basis data Hangao. Pada saat yang sama, kami telah mengembangkan komponen konversi untuk memenuhi beberapa kebutuhan khusus database Hangao:
Mendukung operasi konversi yang kompleks seperti baris ke kolom dan kolom ke baris.
Menulis berbagai UDF (fungsi yang ditentukan pengguna) untuk desensitisasi data dan operasi lainnya.
Modifikasi konektor file
Konektor Sistem File memainkan peran penting dalam penggunaan kami, jadi kami membuat beberapa perubahan padanya:
Konektor HDFS: Menambahkan fungsi rekursi direktori dan pemindaian file ekspresi reguler, sekaligus mendukung pembacaan dan penulisan berbagai format file (seperti RC, Sequence, XML, JSON).
Konektor FTP dan SFTP: Memperbaiki bug kebocoran I/O, dan mengoptimalkan mekanisme cache koneksi untuk memastikan independensi antar akun berbeda dengan IP yang sama.
Optimalisasi mekanisme pengajuan dua tahap
Dalam proses penggunaan SeaTunnel, kami memiliki pemahaman mendalam tentang mekanisme pengiriman dua tahap untuk memastikan konsistensi data. Berikut ini adalah permasalahan dan solusi yang kami temui selama proses ini:
Deskripsi Masalah : Saat menggunakan FTP dan SFTP untuk menulis file, pesan kesalahan menunjukkan bahwa tidak ada izin menulis. Penyelidikan menemukan bahwa untuk memastikan konsistensi data, SeaTunnel pertama-tama akan menulis file ke direktori sementara dan kemudian memindahkannya.
Namun, penulisan gagal karena pengaturan izin akun yang berbeda pada direktori sementara.
larutan : Saat membuat direktori sementara, tetapkan izin yang lebih besar (seperti 777) untuk memastikan bahwa semua akun memiliki izin untuk menulis. Pada saat yang sama, ini memecahkan masalah kegagalan perintah ganti nama karena sistem lintas file selama perpindahan file. Dengan membuat direktori sementara di bawah sistem file yang sama, operasi sistem lintas file dapat dihindari.
Manajemen pembangunan sekunder
Selama proses pengembangan sekunder, kami menghadapi masalah tentang cara mengelola dan menyinkronkan SeaTunnel versi baru. Solusi kami adalah sebagai berikut:
Manajemen cabang lokal: Menarik cabang lokal berdasarkan versi SeaTunnel 2.3.2
Pembaruan komunitas yang dimasukkan secara teratur: Secara rutin menggabungkan versi baru komunitas ke dalam cabang lokal untuk memastikan bahwa kami bisa mendapatkan fitur dan perbaikan baru dari komunitas secara tepat waktu.
Berikan kembali kepada komunitas: Berencana untuk menyerahkan beberapa perubahan dan persyaratan yang dipersonalisasi kepada komunitas untuk mendapatkan penerimaan dan dukungan komunitas, sehingga mengurangi beban kerja pemeliharaan lokal.
Integrasi dan aplikasi SeaTunnel
Dalam proses integrasi SeaTunnel, kami terutama berfokus pada poin-poin berikut:
Optimalisasi alokasi sumber daya: Memanfaatkan arsitektur terdistribusi SeaTunnel menyederhanakan masalah alokasi sumber daya dan tidak lagi memerlukan fungsi penjadwalan terdistribusi tambahan.
Integrasi tumpukan teknologi: Mengintegrasikan fungsi tumpukan teknologi yang berbeda seperti DataX, Spark, dan FlinkCDC ke dalam SeaTunnel dan merangkumnya secara seragam untuk mencapai integrasi ETL dan ELT.
Melalui langkah dan strategi di atas, kami berhasil mengintegrasikan SeaTunnel ke dalam layanan integrasi data kami, memecahkan beberapa masalah utama pada sistem lama, dan mengoptimalkan kinerja dan stabilitas sistem.
Selama proses ini, kami berpartisipasi aktif dalam komunitas, mencari bantuan dan memberikan umpan balik untuk memastikan kelancaran kemajuan upaya integrasi. Interaksi positif ini tidak hanya meningkatkan tingkat teknis kami, namun juga mendorong perkembangan komunitas SeaTunnel.
Pengalaman berpartisipasi dalam komunitas open source
Dalam proses mengikuti SeaTunnel, saya mendapatkan pengalaman sebagai berikut:
Waktunya tepat : Kami memilih proyek ini selama tahap pengembangan SeaTunnel yang pesat, dan waktunya sangat tepat. Pengembangan SeaTunnel memberi kami keyakinan besar bahwa ada banyak hal yang bisa dilakukan.
tujuan pribadi: Saya menetapkan tujuan untuk berpartisipasi dalam komunitas open source pada awal tahun ini dan secara aktif mewujudkannya.
keramahan komunitas : Komunitas SeaTunnel sangat ramah, semua orang berkomunikasi dengan lancar dan saling membantu. Suasana positif ini membuat saya sangat berharga untuk menjadi bagian darinya.
Bagi Anda yang selalu ingin terlibat dalam komunitas open source namun belum mengambil langkah pertama, saya ingin mendorong Anda untuk mengambil lompatan tersebut. Hal terpenting tentang sebuah komunitas adalah orang-orangnya. Selama Anda bergabung, Anda adalah bagian yang tak terpisahkan dari komunitas tersebut.
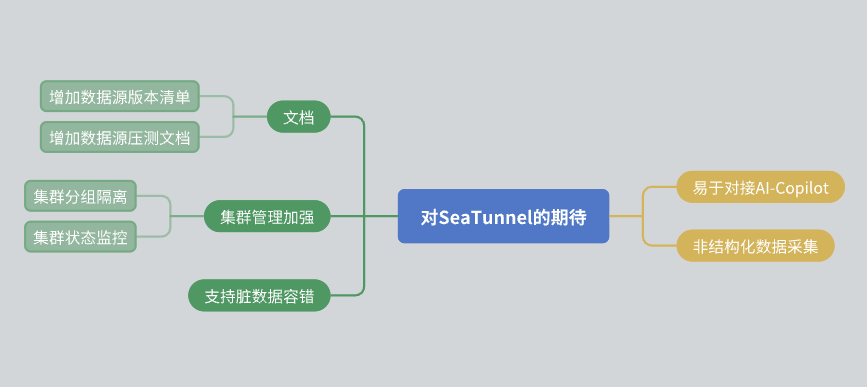
Harapan untuk SeaTunnel
Terakhir, saya ingin menyampaikan beberapa ekspektasi untuk SeaTunnel:
Perbaikan dokumentasi: Saya berharap masyarakat dapat lebih menyempurnakan dokumentasinya, termasuk daftar versi sumber data dan laporan stress test.
Manajemen klaster: SeaTunnel diharapkan dapat mencapai isolasi sumber daya dalam cluster dan memberikan informasi pemantauan status cluster yang lebih kaya.
Toleransi kesalahan data: Meskipun SeaTunnel telah memiliki mekanisme toleransi kesalahan, kami berharap mekanisme ini dapat lebih dioptimalkan di masa mendatang.
Integrasi AI: Saya berharap SeaTunnel dapat menyediakan lebih banyak antarmuka untuk memfasilitasi akses yang dibantu AI.
Terima kasih kepada setiap anggota komunitas SeaTunnel atas kerja keras Anda. Sekian sharing saya, terima kasih semuanya!