Intercambio práctico de AsiaInfo Technology en Apache SeaTunnel
Auto presentación
Hola compañeros estudiantes, es un honor para mí compartir y comunicarme con ustedes a través de la comunidad Apache SeaTunnel. Soy Pan Zhihong de AsiaInfo Technology y soy el principal responsable del desarrollo de los productos del centro de datos internos de la empresa.
El tema de este intercambio es la práctica de integración de Apache SeaTunnel en AsiaInfo Technology. Específicamente, hablaremos sobre cómo nuestro centro de datos integra SeaTunnel.
Compartir descripción general del contenido
En este intercambio, me centraré en los siguientes aspectos:
Por qué elegir SeaTunnel
Cómo integrar SeaTunnel
Problemas encontrados durante la integración de SeaTunnel
Desarrollo secundario de SeaTunnel
Expectativas para SeaTunnel
Por qué elegir SeaTunnel
En primer lugar, permítanme presentarles que soy el principal responsable del desarrollo iterativo del producto de centro de datos DATAOS de AsiaInfo. DATAOS es un producto de centro de datos relativamente estándar, que cubre módulos funcionales como integración de datos, desarrollo de datos, gobernanza de datos y apertura de datos. Lo principal relacionado con SeaTunnel es el módulo de integración de datos, que es el principal responsable de la integración de datos.
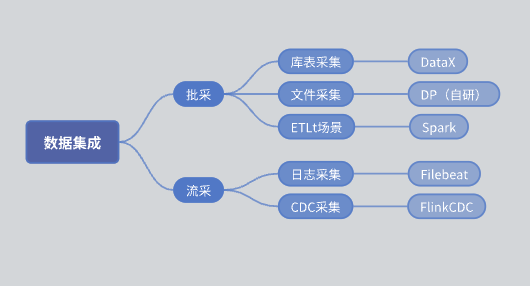
Antes de la introducción de SeaTunnel, la arquitectura funcional de nuestro módulo de integración de datos era la siguiente:
compra por lotes: Dividido en colección de tablas de biblioteca y colección de archivos.
Colección de tablas de biblioteca: implementada principalmente utilizando DataX.
Colección de archivos: motor DP de desarrollo propio.
Colección ETLt: motor de recopilación ETLt de desarrollo propio. DataX prefiere ELT (extracción, carga, conversión), que es adecuado para conversiones complejas después de la extracción y el almacenamiento de datos. Sin embargo, en algunos escenarios, se requiere EL pequeño T (extracción, carga, conversión simple) y DataX no es adecuado. Por lo tanto, desarrollamos un motor basado en Spark SQL.
Liucai: La recopilación de registros se basa principalmente en Filebeat y la recopilación de CDC se basa principalmente en Flink CDC.
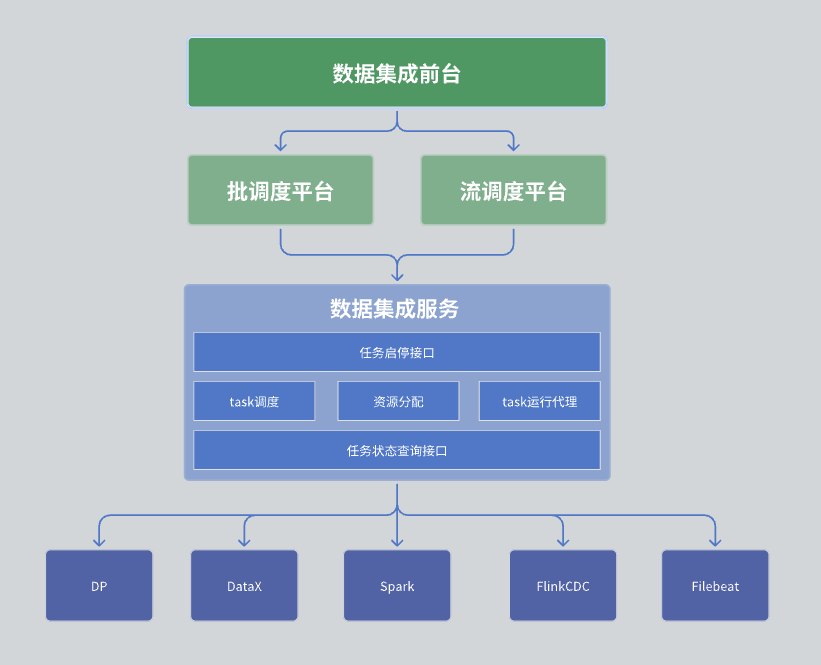
En nuestro módulo de integración de datos, la arquitectura general se divide en tres capas, a saber, recepción de integración de datos, plataforma de programación y servicio de integración de datos.
A continuación se muestra una descripción detallada de cada capa:
La primera capa: recepción de integración de datos
La recepción de integración de datos es la principal responsable de la gestión de las tareas de integración de datos. Específicamente, incluye desarrollo de tareas, desarrollo de programación y monitoreo de operaciones. Estas tareas combinan varios operadores integrados a través de DAG (Gráfico acíclico dirigido) para implementar procesos complejos de procesamiento de datos. La interfaz de usuario proporciona una interfaz intuitiva de administración de tareas, lo que permite a los usuarios configurar y monitorear fácilmente las tareas de integración de datos.
Segunda capa: plataforma de programación
La plataforma de programación es responsable de la programación y gestión de las operaciones de tareas. Admite modos de procesamiento por lotes y procesamiento de flujo, y puede generar las tareas correspondientes en función de las dependencias de las tareas y las estrategias de programación.
La tercera capa: servicio de integración de datos.
El servicio de integración de datos es el núcleo de todo el servicio del centro de datos y proporciona una serie de funciones clave:
Interfaz de gestión de tareas: Incluye funciones como creación, eliminación, actualización y consulta de tareas.
Interfaz de inicio y parada de tareas: permite a los usuarios iniciar o detener tareas específicas.
Interfaz de consulta de estado de tarea: Consulta la información del estado actual de la tarea para facilitar el seguimiento y la gestión.
El servicio de integración de datos también es responsable de la ejecución específica de tareas. Dado que nuestra tarea de recopilación puede incluir varios motores, esto requiere coordinación y programación de varios motores cuando la tarea se está ejecutando.
Proceso de ejecución de tareas
La ejecución de la tarea incluye principalmente los siguientes pasos:
Programación de tareas: De acuerdo con la estrategia de programación predeterminada y las dependencias, la plataforma de programación genera las tareas correspondientes.
Ejecución de tareas: Durante la ejecución de la tarea, cada operador se ejecuta en secuencia de acuerdo con la configuración DAG de la tarea.
Coordinación multimotor: Para tareas que contienen múltiples motores (como tareas híbridas de DataX y Spark), es necesario coordinar la operación de cada motor durante el proceso de ejecución para garantizar la ejecución sin problemas de la tarea.
Asignación de recursos
Al mismo tiempo, para permitir que DataX, una tarea independiente, se ejecute mejor de manera distribuida y logre la reutilización de recursos, hemos optimizado la asignación de recursos para la tarea DataX:
Programación distribuida: A través del mecanismo de asignación de recursos, las tareas de DataX se distribuyen para ejecutarse en múltiples nodos para evitar cuellos de botella de un solo punto y mejorar el paralelismo de tareas y la eficiencia de ejecución.
Reutilización de recursos: A través de estrategias razonables de gestión y asignación de recursos, garantizar la reutilización eficiente de los recursos para diferentes tareas y reducir el desperdicio de recursos.
agente de ejecución de tareas
Implementamos agentes de ejecución de tareas correspondientes para cada motor de ejecución para lograr una gestión y seguimiento unificado de tareas:
agente del motor de ejecución : En el servicio de integración de datos, el agente gestiona varios motores de ejecución, como DataX, Spark, Flink CDC, etc. El agente es responsable de iniciar, detener y monitorear el estado de las tareas.
interfaz unificada: Proporciona una interfaz de gestión de tareas unificada para que las tareas de diferentes motores se puedan gestionar a través de la misma interfaz, simplificando el trabajo de operación, mantenimiento y gestión.
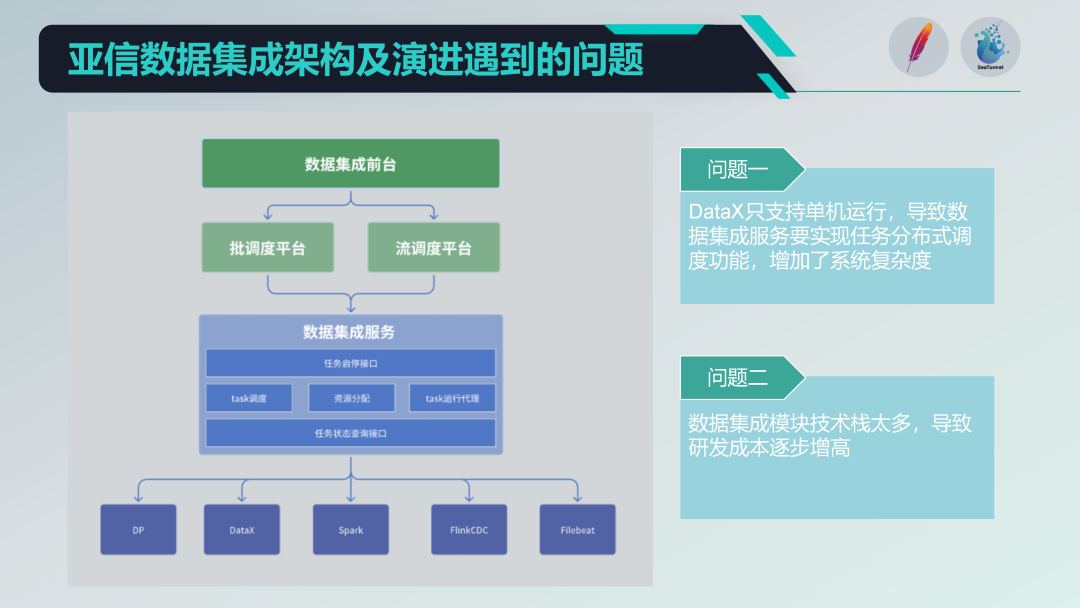
Algunos problemas con la antigua arquitectura de integración de datos
Hemos integrado algunos proyectos de código abierto, como DataX, Spark, Flink CDC, Filebeat, etc., para formar una potente plataforma de servicios de integración de datos. Pero también nos enfrentamos a algunos problemas:
Restricciones de operación de una sola máquina: DataX solo admite la operación de una sola máquina, lo que requiere que implementemos funciones de programación distribuida sobre su base, lo que aumenta la complejidad del sistema.
La pila de tecnología es demasiado diversa: La introducción de múltiples pilas de tecnología (como Spark y Flink), aunque tiene muchas funciones, también genera altos costos de investigación y desarrollo. Cada vez que se desarrollan nuevas funciones, es necesario abordar los problemas de compatibilidad e integración de múltiples pilas de tecnología.
Evolución de la arquitectura
Para optimizar la arquitectura y reducir la complejidad, evolucionamos la arquitectura existente:
Integre la funcionalidad multimotor: Después de presentar SeaTunnel, podemos unificar las funciones de múltiples motores y lograr múltiples capacidades de procesamiento de datos en una sola plataforma.
Simplifique la gestión de recursos: La función de gestión de recursos de SeaTunnel simplifica la programación distribuida de tareas independientes como DataX y reduce la complejidad de la asignación y gestión de recursos.
Reducir los costos de I+D: A través de la arquitectura unificada y el diseño de interfaz, se reducen los costos de desarrollo y mantenimiento causados por múltiples pilas de tecnología y se mejora la escalabilidad y la facilidad de mantenimiento del sistema.
A través de la optimización y evolución de la arquitectura, hemos resuelto con éxito los problemas de las limitaciones de operación de una sola máquina de DataX y los altos costos de I + D causados por múltiples pilas de tecnología.
Después de presentar SeaTunnel, pudimos implementar múltiples funciones de procesamiento de datos en una plataforma, al tiempo que simplificamos la gestión de recursos y la programación de tareas, y mejoramos la eficiencia y estabilidad general del sistema.
¿Por qué elegir SeaTunnel?
Nuestro contacto con SeaTunnel se remonta al período Waterdrop y hemos llevado a cabo muchas prácticas de aplicación para Waterdrop.
El año pasado, SeaTunnel lanzó el motor Zeta, admitió una arquitectura distribuida y se convirtió en un proyecto Apache de alto nivel. Esto nos permitió encontrar un momento adecuado el año pasado, realizar una investigación en profundidad y decidir introducir SeaTunnel.
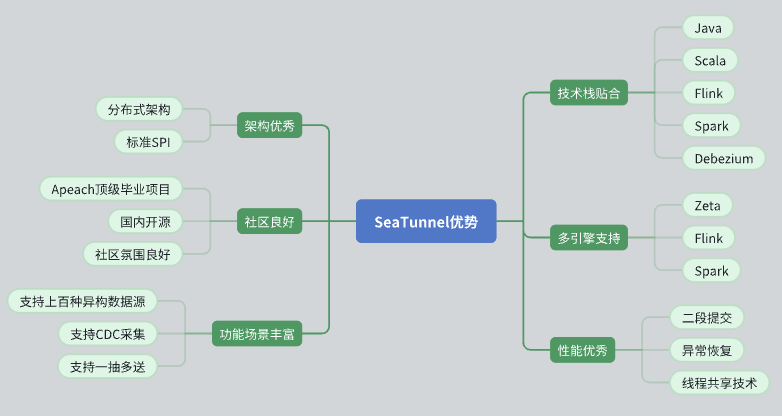
Estas son algunas de las razones principales por las que elegimos SeaTunnel:
Excelente diseño arquitectónico
SeaTunnel tiene una arquitectura distribuida que funciona bien para nuestras necesidades.
Su diseño API está estandarizado y adopta el modo SPI (Service Provider Interface) para facilitar la expansión e integración.
Apoyo activo de la comunidad
SeaTunnel es un proyecto Apache de alto nivel con un buen ambiente comunitario. Los grupos activos de desarrolladores y usuarios brindan un fuerte apoyo para la resolución de problemas y la expansión de funciones.
El trasfondo de los proyectos nacionales de código abierto hace que nuestra comunicación y colaboración sean más fluidas.
Amplia funcionalidad y soporte de fuentes de datos
SeaTunnel admite múltiples fuentes de datos y tiene funciones completas para satisfacer nuestras diversas necesidades de procesamiento de datos.
Admite CDC (Change Data Capture), lo que permite la sincronización y el procesamiento de datos en tiempo real.
Admite el modo de transmisión de datos uno a muchos, mejorando la flexibilidad de la transmisión de datos.
Ajuste de la pila de tecnología
SeaTunnel es compatible con Java y admite Flink y Spark, lo que nos permite integrarlo y aplicarlo sin problemas en la pila de tecnología existente.
Al utilizar Debezium para la captura de datos de los CDC, la tecnología es madura y estable.
Soporte multimotor
SeaTunnel admite una variedad de motores informáticos, incluidos Zeta, Flink y Spark, y puede seleccionar el motor más adecuado para el cálculo según las necesidades específicas.
Esto es muy importante porque nos permite elegir el modo de computación óptimo en diferentes escenarios, mejorando la flexibilidad y eficiencia del sistema.
Excelente actuación
SeaTunnel ha diseñado mecanismos de optimización del rendimiento, como el compromiso en dos fases, la recuperación con tolerancia a fallos y el intercambio de subprocesos, para garantizar un procesamiento de datos eficiente y estable.
Problemas resueltos tras la introducción de SeaTunnel
SeaTunnel resuelve los dos problemas principales que mencionamos anteriormente:
Programación distribuida
DataX solo se puede ejecutar en una sola máquina y necesitamos implementar funciones de programación distribuida adicionales. SeaTunnel admite inherentemente la arquitectura distribuida, ya sea que utilice Zeta, Flink o Spark como motor informático, puede implementar fácilmente el procesamiento de datos distribuidos, lo que simplifica enormemente nuestro trabajo.
Integración de la pila de tecnología
Anteriormente hemos utilizado una variedad de pilas de tecnología, incluidas DataX, Spark, Flink CDC, etc., lo que hizo que los costos de I + D fueran altos y el sistema complejo. Al encapsular uniformemente estas pilas de tecnología, SeaTunnel proporciona una plataforma integrada que puede admitir procesos ELT y ETL, simplificando enormemente la arquitectura del sistema y reduciendo los costos de desarrollo y mantenimiento.
Cómo integrar SeaTunnel
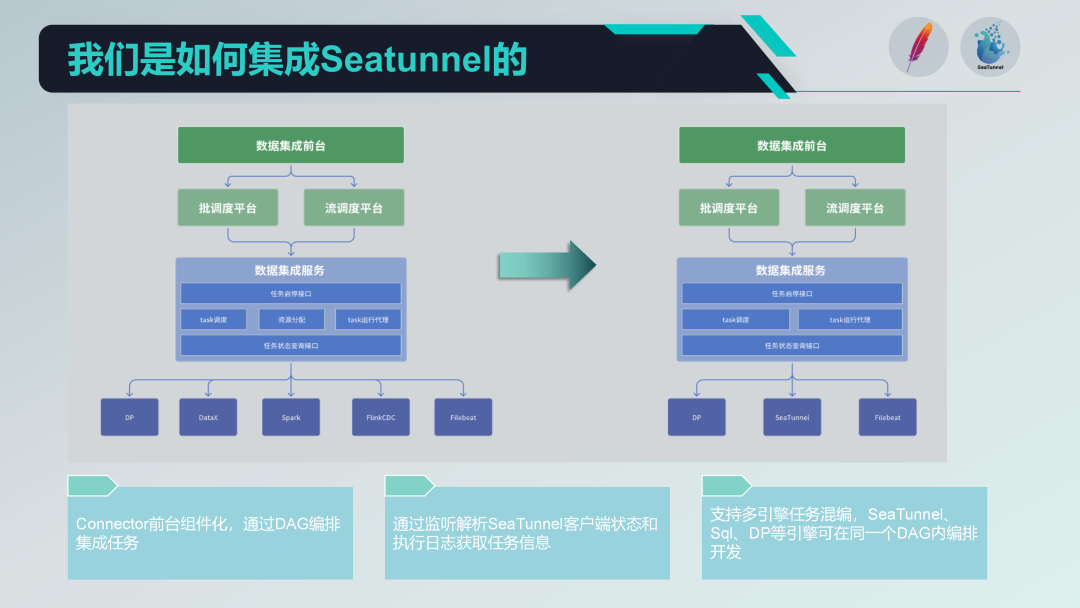
Antes de integrar SeaTunnel, nuestra antigua arquitectura existía y funcionaba desde hacía algún tiempo. Estaba dividida en tres capas: recepción, plataforma de programación y servicio de integración de datos. La recepción es responsable de la gestión y el desarrollo de tareas, la plataforma de programación es responsable de la programación de tareas y la gestión de dependencias, y el servicio de integración de datos es la parte central de la ejecución y gestión de todas las tareas de integración de datos.
La siguiente es nuestra nueva arquitectura después de integrar SeaTunnel.
Primero, eliminamos la parte de asignación de recursos de la arquitectura anterior que involucraba DataX. Dado que SeaTunnel admite una arquitectura distribuida, ya no se requiere una gestión de asignación de recursos adicional. Este ajuste simplifica enormemente nuestra arquitectura.
Reemplazo de pila de tecnología
Reemplazamos gradualmente la antigua tecnología por SeaTunnel. Los pasos específicos son los siguientes:
Reemplazo de tareas de procesamiento por lotes: primero reemplazamos la parte de la arquitectura anterior que usaba DataX y Spark para el procesamiento por lotes ETL.
Reemplace la tarea de procesamiento de transmisión: a continuación, reemplazaremos gradualmente la parte usando Flink CDC para el procesamiento de transmisión. Al adoptar este enfoque paso a paso, podemos garantizar que el sistema permanezca estable durante toda la transición gradual.
Conector SeaTunnel por componentes
Realizamos un diseño basado en componentes basado en SeaTunnel's Connector y realizamos la configuración y orquestación DAG a través de formularios en el front-end. Aunque SeaTunnel Web también está haciendo un trabajo similar, hemos personalizado el desarrollo según nuestras propias necesidades para integrarlo mejor con los sistemas existentes.
agente de ejecución de tareas
En términos de agentes de ejecución de tareas, enviamos tareas a través del cliente SeaTunnel y monitoreamos el estado y los registros de ejecución del cliente SeaTunnel. Al analizar estos registros, podemos obtener información sobre el estado de ejecución de la tarea y garantizar la monitorización y trazabilidad de la ejecución de la tarea.
Desarrollo híbrido multimotor
Admitimos el desarrollo híbrido de múltiples motores y podemos realizar la orquestación DAG de múltiples motores en una tarea de programación en la página principal. De esta manera, podemos utilizar diferentes motores (como el motor SQL y el motor DP) en una tarea de programación al mismo tiempo para el desarrollo de tareas, mejorando la flexibilidad y escalabilidad del sistema.
Problemas encontrados durante la integración de SeaTunnel
En el proceso de integración de SeaTunnel, encontramos algunos problemas. Los siguientes son varios problemas representativos y sus soluciones:
Pregunta 1: manejo de errores
En el proceso de uso de SeaTunnel, encontramos algunos informes de errores relacionados con el código del marco. Como no hay instrucciones relevantes en los documentos oficiales, nos unimos al grupo comunitario de WeChat, pedimos ayuda a los desarrolladores del grupo y resolvimos el problema a tiempo.
Pregunta 2: transferencia de tareas
Nuestras antiguas tareas de recopilación se implementaron utilizando DataX. Al reemplazarlas con SeaTunnel, debemos considerar los problemas de transferencia de tareas.
Lo solucionamos mediante las siguientes soluciones:
Diseño de componentes : Nuestras tareas de recopilación de datos en el middle office están diseñadas en función de componentes y existe una capa de conversión entre los componentes front-end y el motor de ejecución back-end. El frontend configura el formulario y el backend genera el archivo JSON que DataX necesita ejecutar a través de la capa de conversión.
Generación de archivos JSON similares : La configuración de SeaTunnel es similar a la de DataX. El frontend también se configura a través de un formulario y el archivo JSON que SeaTunnel necesita ejecutar se genera en el backend. De esta manera, podemos transferir sin problemas tareas antiguas a la nueva plataforma SeaTunnel, garantizando una transición de tareas sin problemas.
conversión de secuencias de comandos SQL : Escriba scripts SQL para limpiar y convertir tareas DataX antiguas para que puedan adaptarse a SeaTunnel. Este método es más flexible y adaptable, porque SeaTunnel se actualizará con frecuencia y escribir directamente codificación física para compatibilidad no es una solución a largo plazo. Mediante la conversión de scripts, las tareas se pueden migrar de manera más eficiente para adaptarse a las actualizaciones de SeaTunnel.
Pregunta 3: Gestión de versiones
Encontramos problemas de gestión de versiones al utilizar SeaTunnel. SeaTunnel se actualiza con frecuencia y nuestro equipo necesita realizar un seguimiento continuo de la última versión para la segunda versión. Aquí está nuestra solución:
Gestión de sucursales locales : Creamos una sucursal local basada en SeaTunnel versión 2.3.2 y realizamos un desarrollo secundario en ella, incluida la corrección de requisitos personalizados y correcciones de errores temporales. Para minimizar la cantidad de código mantenido localmente, solo conservamos los cambios necesarios e intentamos utilizar la última versión de la comunidad para otras partes.
Actualizaciones comunitarias incorporadas periódicamente : Regularmente fusionamos nuevas versiones de la comunidad en la sucursal local, especialmente para actualizarlas y hacerlas compatibles con las partes que hemos cambiado. Aunque este método es complicado, garantiza que nos mantengamos actualizados con las últimas funciones y correcciones de la comunidad.
Devolver a la comunidad : Para administrar y mantener mejor el código, planeamos enviar algunos de nuestros cambios y requisitos personalizados a la comunidad para esforzarnos por lograr la aceptación y el apoyo de la comunidad. Esto no sólo ayuda a reducir nuestro trabajo de mantenimiento local, sino que también ayuda a que la comunidad se desarrolle junta.
Desarrollo y práctica secundaria de SeaTunnel.
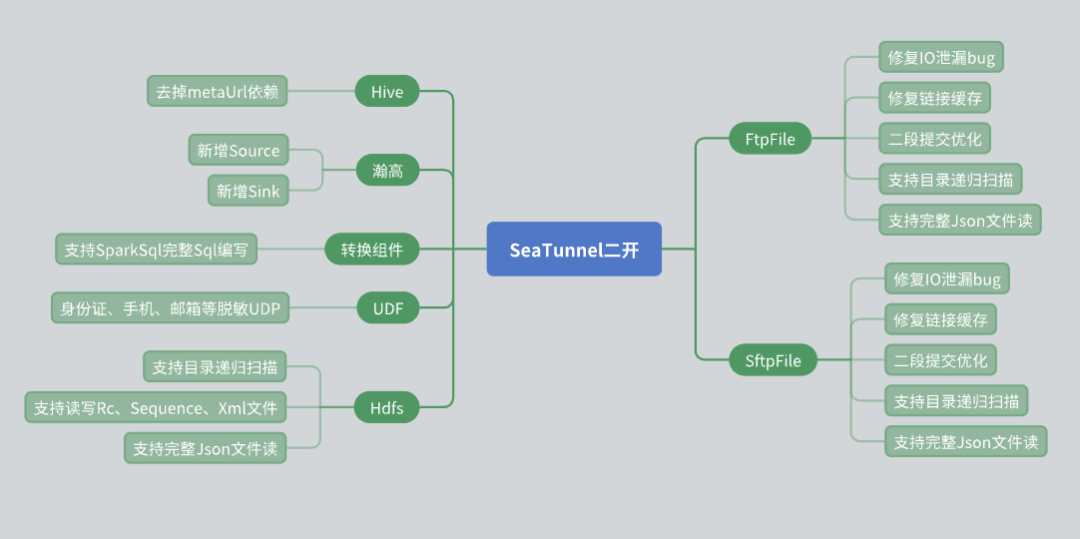
Durante el uso de SeaTunnel, llevamos a cabo una serie de desarrollos secundarios basados en las necesidades comerciales reales, especialmente a nivel de conector. Los siguientes son los problemas y soluciones que encontramos durante el desarrollo secundario.
Renovación del conector Hive
El SeaTunnel Hive Connector original se basa en la Meta URL para obtener metadatos. Sin embargo, en aplicaciones reales, muchos usuarios de terceros no pueden proporcionar Meta URL debido a problemas de seguridad. Para hacer frente a esta situación, hemos realizado los siguientes cambios:
Utilice la interfaz JDBC de Hive Server 2 para obtener la información de metadatos de la tabla, evitando así la dependencia de la Meta URL.
De esta manera, podemos brindar a los usuarios la capacidad de leer y escribir datos de Hive de manera más flexible y al mismo tiempo garantizar la seguridad de los datos.
Soporte de base de datos Hangao
La base de datos Hangao se utiliza ampliamente en nuestros proyectos, por lo que hemos agregado soporte de lectura y escritura de fuentes de datos para la base de datos Hangao. Al mismo tiempo, hemos desarrollado componentes de conversión para satisfacer algunas necesidades especiales de la base de datos Hangao:
Admite operaciones de conversión complejas, como fila a columna y columna a fila.
Escribió una variedad de UDF (funciones definidas por el usuario) para desensibilización de datos y otras operaciones.
Modificación del conector de archivos.
El conector del sistema de archivos juega un papel importante en nuestro uso, por lo que le hemos realizado varios cambios:
Conector HDFS: Se agregó la función de recursividad de directorios y escaneo de archivos con expresiones regulares, al tiempo que se admite la lectura y escritura de múltiples formatos de archivos (como RC, Sequence, XML, JSON).
Conectores FTP y SFTP: Se corrigió el error de fuga de E/S y se optimizó el mecanismo de almacenamiento en caché de la conexión para garantizar la independencia entre diferentes cuentas con la misma IP.
Optimización del mecanismo de envío de dos etapas.
En el proceso de uso de SeaTunnel, conocemos en profundidad su mecanismo de envío de dos etapas para garantizar la coherencia de los datos. Los siguientes son los problemas y soluciones que encontramos durante este proceso:
Descripción del problema : Cuando se utiliza FTP y SFTP para escribir archivos, un mensaje de error indica que no hay permiso de escritura. La investigación encontró que para garantizar la coherencia de los datos, SeaTunnel primero escribirá el archivo en el directorio temporal y luego lo moverá.
Sin embargo, la escritura falló debido a la configuración de permisos de diferentes cuentas en el directorio temporal.
solución : Al crear un directorio temporal, establezca permisos mayores (como 777) para garantizar que todas las cuentas tengan permiso para escribir. Al mismo tiempo, resuelve el problema de la falla del comando de cambio de nombre debido a sistemas de archivos cruzados durante el movimiento de archivos. Al crear un directorio temporal en el mismo sistema de archivos, se evitan las operaciones entre sistemas de archivos.
Gestión de desarrollo secundario.
Durante el proceso de desarrollo secundario, nos enfrentamos al problema de cómo gestionar y sincronizar la nueva versión de SeaTunnel. Nuestra solución es la siguiente:
Gestión de sucursales locales: Se eliminó una sucursal local basada en la versión SeaTunnel 2.3.2.
Actualizaciones comunitarias incorporadas periódicamente: fusionamos periódicamente nuevas versiones de la comunidad en sucursales locales para garantizar que podamos obtener nuevas funciones y correcciones de la comunidad de manera oportuna.
Devolver a la comunidad: Planeamos enviar algunos de nuestros cambios y requisitos personalizados a la comunidad para obtener la aceptación y el apoyo de la comunidad, reduciendo así la carga de trabajo del mantenimiento local.
Integración y aplicaciones de SeaTunnel
En el proceso de integración de SeaTunnel, nos centramos principalmente en los siguientes puntos:
Optimización de la asignación de recursos: La utilización de la arquitectura distribuida de SeaTunnel simplifica el problema de asignación de recursos y ya no requiere funciones de programación distribuida adicionales.
Integración de la pila de tecnología: Integre las funciones de diferentes pilas de tecnología como DataX, Spark y FlinkCDC en SeaTunnel y encapsúlelas de manera uniforme para lograr la integración de ETL y ELT.
A través de los pasos y estrategias anteriores, integramos con éxito SeaTunnel en nuestro servicio de integración de datos, resolvimos algunos problemas clave en el sistema anterior y optimizamos el rendimiento y la estabilidad del sistema.
Durante este proceso, participamos activamente en la comunidad, buscamos ayuda y brindamos retroalimentación sobre los problemas para garantizar el buen progreso del trabajo de integración. Esta interacción positiva no sólo mejora nuestro nivel técnico, sino que también promueve el desarrollo de la comunidad SeaTunnel.
Experiencia en participación en la comunidad de código abierto.
En el proceso de participación en SeaTunnel, tengo las siguientes experiencias:
es el momento adecuado : Elegimos este proyecto durante la etapa de rápido desarrollo de SeaTunnel y el momento fue muy bueno. El desarrollo de SeaTunnel nos da mucha confianza en que hay mucho por hacer.
metas personales: Me propuse el objetivo de participar en la comunidad de código abierto a principios de este año y lo puse en práctica activamente.
amistad comunitaria : La comunidad SeaTunnel es muy amigable, todos se comunican fluidamente y se ayudan unos a otros. Esta atmósfera positiva hace que valga la pena para mí ser parte de ello.
Para aquellos de ustedes que siempre han querido participar en la comunidad de código abierto pero aún no han dado el primer paso, quiero animarlos a que den el salto. Lo más importante de una comunidad es su gente. Mientras te unas, eres una parte indispensable de la comunidad.
Expectativas para SeaTunnel
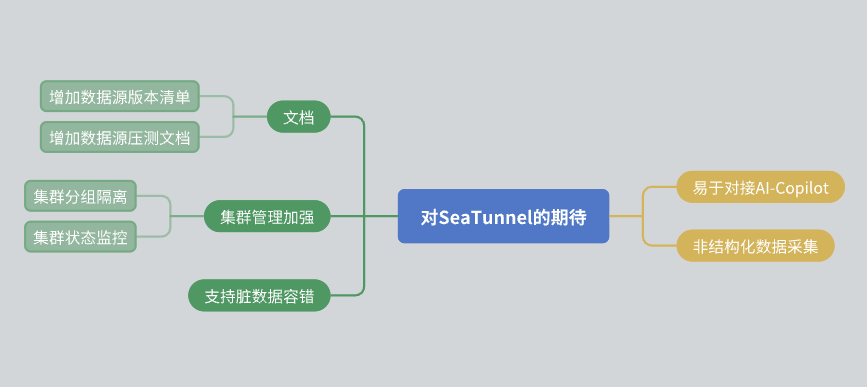
Finalmente, me gustaría compartir algunas expectativas para SeaTunnel:
Mejoras en la documentación: Espero que la comunidad pueda mejorar aún más la documentación, incluida la lista de versiones de fuentes de datos y los informes de pruebas de estrés.
Gestión de clústeres: Se espera que SeaTunnel pueda lograr el aislamiento de recursos dentro del clúster y proporcionar información de monitoreo del estado del clúster más rica.
Tolerancia a fallos de datos: Aunque SeaTunnel ya tiene un mecanismo tolerante a fallas, esperamos que pueda optimizarse aún más en el futuro.
Integración de IA: Espero que SeaTunnel pueda proporcionar más interfaces para facilitar el acceso asistido por IA.
Gracias a todos los miembros de la comunidad SeaTunnel por su arduo trabajo. Eso es todo lo que comparto, ¡gracias a todos!