AsiaInfo Technology の Apache SeaTunnel に基づく二次開発とアプリケーションの実践
2024-07-12
한어 Русский язык English Français Indonesian Sanskrit 日本語 Deutsch Português Ελληνικά español Italiano Suomalainen Latina
学生の皆さん、Apache SeaTunnel コミュニティを通じて皆さんと情報を共有し、コミュニケーションできることを光栄に思います。私は AsiaInfo Technology の Pan Zhihong です。私は主に社内データセンター製品の開発を担当しています。
この共有のトピックは、AsiaInfo Technology における Apache SeaTunnel の統合実践であり、具体的には、当社のデータセンターが SeaTunnel をどのように統合するかについて説明します。
この共有では、次の側面に焦点を当てます。
SeaTunnelを選ぶ理由 SeaTunnel を統合する方法 SeaTunnel の統合中に発生した問題 SeaTunnelの二次開発 SeaTunnelへの期待 まず最初に、私は AsiaInfo のデータセンター製品 DATAOS の反復開発を主に担当していることをご紹介します。 DATAOS は比較的標準的なデータセンター製品であり、データ統合、データ開発、データ ガバナンス、データ オープン性などの機能モジュールをカバーしています。 SeaTunnel に関連する主なものは、主にデータ統合を担当するデータ統合モジュールです。
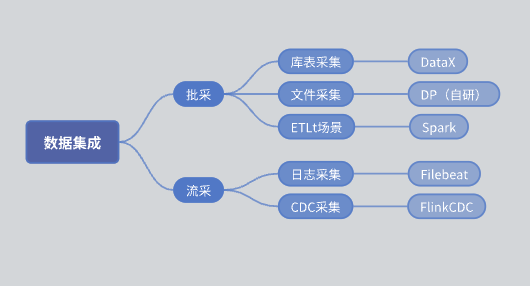
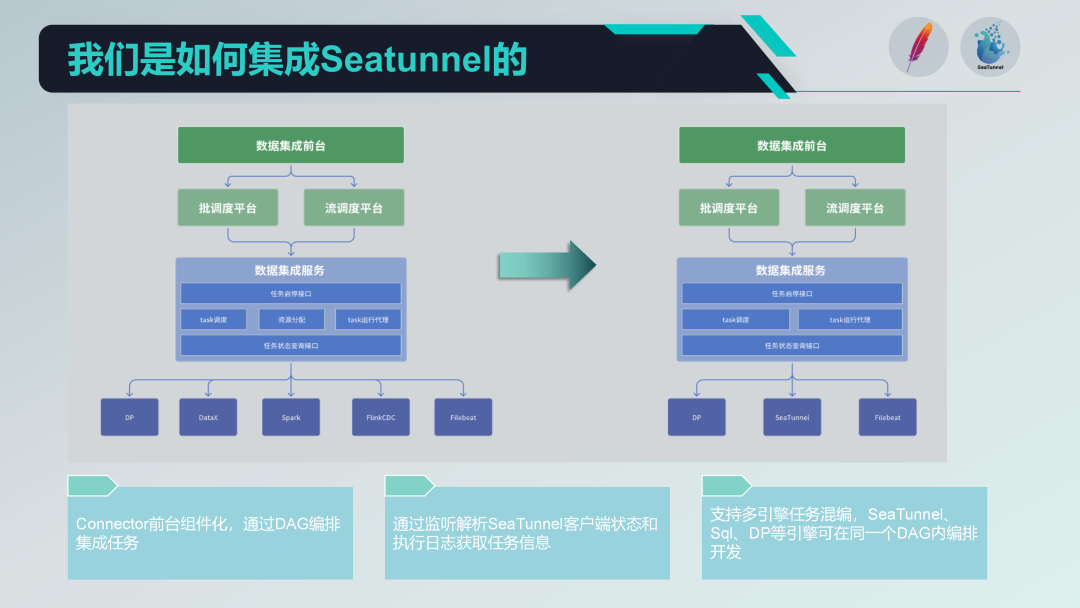
SeaTunnel の導入前、データ統合モジュールの機能アーキテクチャは次のとおりでした。
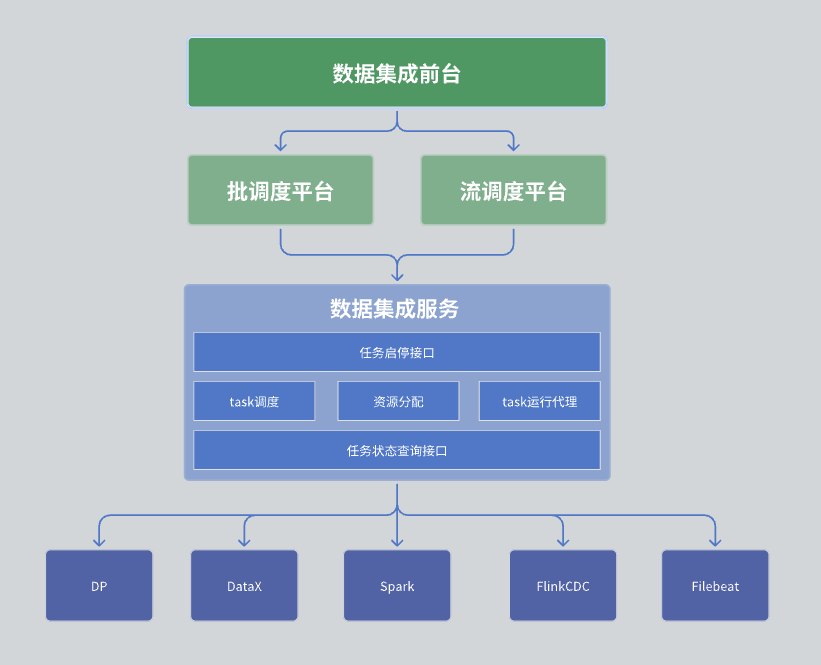
一括購入 :ライブラリテーブルコレクションとファイルコレクションに分かれています。 ライブラリ テーブル コレクション: 主に DataX を使用して実装されます。 ファイルコレクション:自社開発のDPエンジン。 ETLt コレクション: 自社開発の ETLt コレクション エンジン。 DataX は、データの抽出と保存後の複雑な変換に適した ELT (抽出、読み込み、変換) を優先します。ただし、シナリオによっては、EL の小さな T (抽出、読み込み、単純な変換) が必要であり、DataX は適していません。そこで、Spark SQL をベースにしたエンジンを開発しました。 リウカイ : ログ収集は主に Filebeat に基づいており、CDC 収集は主に Flink CDC に基づいています。データ統合モジュールでは、全体のアーキテクチャがデータ統合フロント デスク、スケジューリング プラットフォーム、データ統合サービスの 3 つの層に分かれています。
以下に各レイヤーの詳細を説明します。
第 1 層: データ統合フロント デスク
データ統合フロントデスクは主にデータ統合タスクの管理を担当します。具体的には、タスク開発、スケジュール開発、運用監視などが挙げられます。これらのタスクは、DAG (有向非巡回グラフ) を介してさまざまな統合オペレーターを組み合わせて、複雑なデータ処理プロセスを実装します。フロントエンド インターフェイスは直感的なタスク管理インターフェイスを提供し、ユーザーがデータ統合タスクを簡単に設定および監視できるようにします。
第 2 層: スケジューリング プラットフォーム
スケジューリング プラットフォームは、タスク操作のスケジューリングと管理を担当します。バッチ処理モードとストリーム処理モードの両方をサポートし、タスクの依存関係とスケジューリング戦略に基づいて対応するタスクを取得できます。
第 3 層: データ統合サービス
データ統合サービスはデータセンター サービス全体の中核であり、一連の主要な機能を提供します。
タスク管理インターフェース : タスクの作成、削除、更新、クエリなどの機能が含まれます。タスクの開始および停止インターフェイス : ユーザーが特定のタスクを開始または停止できるようにします。タスクステータスクエリインターフェース : タスクの現在のステータス情報をクエリして、監視と管理を容易にします。データ統合サービスは、特定のタスクの実行も担当します。収集タスクには複数のエンジンが含まれる場合があるため、タスクの実行時に複数のエンジンの調整とスケジューリングが必要になります。
タスク実行プロセス
タスクの実行には主に次の手順が含まれます。
タスクのスケジュール設定 : 所定のスケジューリング戦略と依存関係に従って、スケジューリング プラットフォームは対応するタスクを取得します。タスクの実行 : タスクの実行中、各オペレーターはタスクの DAG 構成に従って順番に実行されます。マルチエンジン連携 : 複数のエンジンを含むタスク (DataX や Spark ハイブリッド タスクなど) の場合、タスクがスムーズに実行されるように、実行プロセス中に各エンジンの動作を調整する必要があります。資源の配分
同時に、スタンドアロン タスクである DataX を分散方法でより適切に実行し、リソースの再利用を実現できるようにするために、DataX タスクのリソース割り当てを最適化しました。
分散スケジューリング : リソース割り当てメカニズムを通じて、DataX タスクは複数のノードで実行されるように分散され、単一点のボトルネックを回避し、タスクの並列処理と実行効率を向上させます。リソースの再利用 : 合理的なリソース管理と割り当て戦略を通じて、さまざまなタスクにリソースを効率的に再利用し、リソースの無駄を削減します。タスク実行エージェント
タスクの統合管理と監視を実現するために、各実行エンジンに対応するタスク実行エージェントを実装します。
実行エンジンエージェント : データ統合サービスでは、エージェントは DataX、Spark、Flink CDC などのさまざまな実行エンジンを管理します。エージェントは、タスクの開始、停止、ステータス監視を担当します。統合インターフェース : 統一されたタスク管理インターフェイスを提供し、異なるエンジンのタスクを同じインターフェイスで管理できるため、運用、保守、管理作業が簡素化されます。
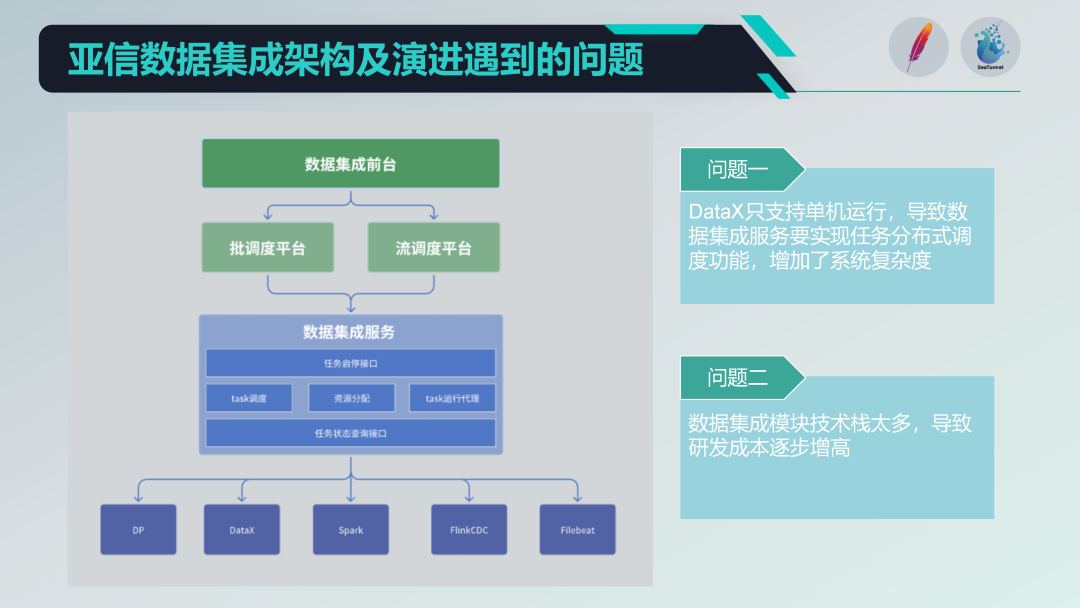
古いデータ統合アーキテクチャに関するいくつかの問題
DataX、Spark、Flink CDC、Filebeat などのいくつかのオープン ソース プロジェクトを統合して、強力なデータ統合サービス プラットフォームを形成しました。しかし、次のような問題にも直面しています。
単体マシンの動作制限 : DataX は単一マシンの操作のみをサポートしているため、それに基づいて分散スケジューリング機能を実装する必要があり、システムの複雑さが増加します。テクノロジースタックが多様すぎる : 複数のテクノロジー スタック (Spark や Flink など) の導入は、機能は豊富ですが、新しい機能が開発されるたびに、複数のテクノロジー スタックの互換性と統合の問題に対処する必要があります。アーキテクチャの進化
アーキテクチャを最適化し、複雑さを軽減するために、既存のアーキテクチャを進化させました。
マルチエンジン機能を統合する : SeaTunnel の導入後、複数のエンジンの機能を統合し、単一のプラットフォーム上で複数のデータ処理機能を実現できます。リソース管理を簡素化する : SeaTunnel のリソース管理機能は、DataX などのスタンドアロン タスクの分散スケジューリングを簡素化し、リソースの割り当てと管理の複雑さを軽減します。研究開発コストの削減 :統一されたアーキテクチャとインターフェース設計により、複数のテクノロジースタックによって発生する開発コストと保守コストが削減され、システムの拡張性と保守の容易さが向上します。アーキテクチャの最適化と進化により、DataX の単一マシン操作の制限と、複数のテクノロジー スタックによって引き起こされる高額な研究開発コストの問題を解決することに成功しました。
SeaTunnel の導入後、リソース管理とタスクのスケジューリングを簡素化し、システム全体の効率と安定性を向上させながら、複数のデータ処理機能を 1 つのプラットフォームに実装することができました。
SeaTunnel を選ぶ理由
SeaTunnel との関わりは Waterdrop の時代にまで遡り、Waterdrop のアプリケーションを数多く実践してきました。
昨年、SeaTunnel は Zeta エンジンを立ち上げ、分散アーキテクチャをサポートし、トップレベルの Apache プロジェクトとなったことにより、昨年は適切な時点を見つけ、詳細な調査を実施し、SeaTunnel の導入を決定することができました。
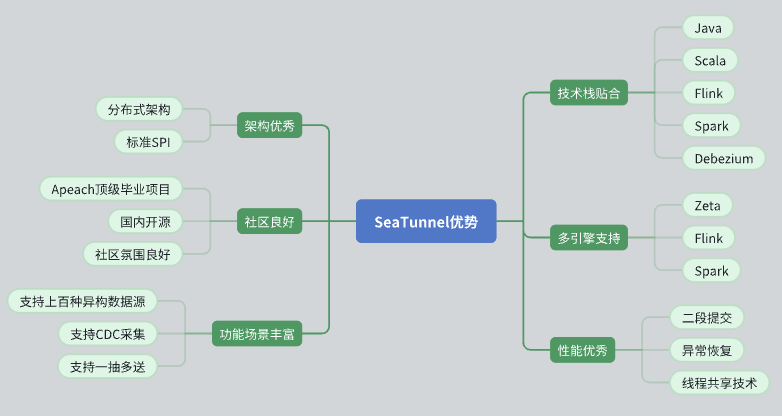
SeaTunnel を選択した主な理由は次のとおりです。
優れた建築デザイン
SeaTunnel は、私たちのニーズに適した分散アーキテクチャを備えています。 API 設計は標準化されており、拡張と統合を容易にするために SPI (Service Provider Interface) モードを採用しています。 積極的なコミュニティサポート
SeaTunnel は、活発な開発者およびユーザー グループが問題解決と機能拡張を強力にサポートする、優れたコミュニティ雰囲気を持つトップレベルの Apache プロジェクトです。 国内のオープンソースプロジェクトの背景により、コミュニケーションとコラボレーションがよりスムーズになります。 豊富な機能とデータソースのサポート
SeaTunnel は複数のデータ ソースをサポートし、多様なデータ処理ニーズを満たす豊富な機能を備えています。 CDC (Change Data Capture) をサポートし、リアルタイムのデータ同期と処理を可能にします。 1対多のデータ送信モードをサポートし、データ送信の柔軟性を向上させます。 テクノロジースタックフィット
SeaTunnel は Java と互換性があり、Flink と Spark をサポートしているため、既存のテクノロジー スタックにシームレスに統合して適用できます。 CDC データのキャプチャに Debezium を使用するこのテクノロジーは成熟しており、安定しています。 マルチエンジンのサポート
SeaTunnel は、Zeta、Flink、Spark などのさまざまなコンピューティング エンジンをサポートしており、特定のニーズに応じて計算に最適なエンジンを選択できます。 これは、さまざまなシナリオで最適なコンピューティング モードを選択できるようになり、システムの柔軟性と効率が向上するため、非常に重要です。 素晴らしい演技
SeaTunnel は、効率的で安定したデータ処理を保証するために、2 フェーズ コミット、フォールト トレランス リカバリ、スレッド共有などのパフォーマンス最適化メカニズムを設計しました。 SeaTunnel導入後に解決した問題点
SeaTunnel は、前述した 2 つの主な問題を解決します。
分散スケジューリング
DataX は 1 台のマシン上でのみ実行できるため、追加の分散スケジューリング機能を実装する必要があります。 SeaTunnel は本質的に分散アーキテクチャをサポートしており、コンピューティング エンジンとして Zeta、Flink、または Spark を使用する場合でも、分散データ処理を簡単に実装でき、作業が大幅に簡素化されます。 テクノロジースタックの統合
当社はこれまで、DataX、Spark、Flink CDC などのさまざまなテクノロジー スタックを使用してきましたが、そのため研究開発コストが高額になり、システムが複雑になってしまいました。これらのテクノロジー スタックを均一にカプセル化することで、SeaTunnel は ELT プロセスと ETL プロセスの両方をサポートできる統合プラットフォームを提供し、システム アーキテクチャを大幅に簡素化し、開発およびメンテナンスのコストを削減します。 SeaTunnel を統合する前は、古いアーキテクチャが存在し、しばらくの間、フロント デスク、スケジューリング プラットフォーム、データ統合サービスの 3 つの層に分かれていました。フロント デスクはタスクの管理と開発を担当し、スケジューリング プラットフォームはタスクのスケジューリングと依存関係の管理を担当し、データ統合サービスはすべてのデータ統合タスクの実行と管理の中核部分です。
以下は、SeaTunnel を統合した後の新しいアーキテクチャです。
まず、DataX に関連する古いアーキテクチャのリソース割り当て部分を削除しました。 SeaTunnel 自体は分散アーキテクチャをサポートしているため、追加のリソース割り当て管理は必要ありません。この調整により、アーキテクチャが大幅に簡素化されます。
テクノロジースタックの置き換え
私たちは古いテクノロジー スタックを SeaTunnel に徐々に置き換えました。具体的な手順は次のとおりです。
バッチ処理タスクの置き換え: まず、バッチ処理 ETL に DataX と Spark を使用する古いアーキテクチャの部分を置き換えました。 ストリーム処理タスクの置き換え: 次に、ストリーム処理に Flink CDC を使用する部分を徐々に置き換えます。 この段階的なアプローチを採用することで、段階的な移行中もシステムが安定した状態を維持できるようになります。 コンポーネント化された SeaTunnel コネクタ
SeaTunnel のコネクタに基づいてコンポーネントベースの設計を実施し、フロントエンドのフォームを通じて構成と DAG オーケストレーションを実行しました。 SeaTunnel Web も同様の作業を行っていますが、既存のシステムとより適切に統合するために、独自のニーズに従って開発をカスタマイズしました。
タスク実行エージェント
タスク実行エージェントに関しては、SeaTunnel クライアントを通じてタスクを送信し、SeaTunnel クライアントのステータスと実行ログを監視します。これらのログを解析することで、タスクの実行ステータス情報を取得し、タスク実行の監視可能性と追跡可能性を確保できます。
マルチエンジンハイブリッド開発
マルチエンジン ハイブリッド開発をサポートしており、フロント ページのスケジュール タスクでマルチエンジン DAG オーケストレーションを実行できます。このようにして、タスク開発のために 1 つのスケジューリング タスクで異なるエンジン (SQL エンジンや DP エンジンなど) を同時に使用できるため、システムの柔軟性と拡張性が向上します。
SeaTunnel を統合する過程で、いくつかの問題が発生しました。次に、いくつかの代表的な問題とその解決策を示します。
質問 1: エラー処理
SeaTunnel を使用する過程で、フレームワークのコードに関連するいくつかのエラー レポートが発生しました。公式文書には関連する指示がないため、コミュニティ WeChat グループに参加し、グループ内の開発者に助けを求め、問題は時間内に解決されました。
質問 2: タスクのカットオーバー
古い収集タスクは DataX を使用して実装されていました。それらを SeaTunnel に置き換える場合は、タスクのカットオーバーの問題を考慮する必要があります。
私たちは次のソリューションを通じてそれを解決します。
コンポーネント設計 : ミドル オフィスでのデータ収集タスクはコンポーネント ベースの方法で設計されており、フロントエンド コンポーネントとバックエンド実行エンジンの間に変換レイヤーがあります。フロントエンドはフォームを構成し、バックエンドは DataX が変換レイヤーを通じて実行する必要がある JSON ファイルを生成します。同様のJSONファイルの生成 : SeaTunnel の構成は DataX の構成と似ています。フロントエンドもフォームを通じて構成され、SeaTunnel が実行する必要がある JSON ファイルはバックエンドで生成されます。このようにして、古いタスクを新しい SeaTunnel プラットフォームにシームレスに転送でき、タスクのスムーズな移行が保証されます。SQLスクリプトの変換 : SQL スクリプトを作成して古い DataX タスクをクリーンアップして変換し、SeaTunnel に適応できるようにします。 SeaTunnel は頻繁に更新され、互換性のためにハード コーディングを直接記述することは長期的な解決策ではないため、この方法はより柔軟で適応性があります。スクリプト変換により、タスクをより効率的に移行して SeaTunnel アップデートに適応させることができます。質問 3: バージョン管理
SeaTunnel の使用中にバージョン管理の問題が発生しました。 SeaTunnel は頻繁に更新されるため、私たちのチームは 2 番目のバージョンに向けて最新バージョンを継続的にフォローアップする必要があります。私たちの解決策は次のとおりです。
地方支店の管理 : SeaTunnel バージョン 2.3.2 に基づいてローカル ブランチをプルし、パーソナライズされた要件の修正や一時的なバグ修正を含む二次開発を実施しました。ローカルで保守されるコードの量を最小限に抑えるために、必要な変更のみを保持し、他の部分にはコミュニティからの最新バージョンを使用するようにしています。
コミュニティの最新情報を定期的に組み込む : 特に更新し、変更した部分と互換性を持たせるために、コミュニティから新しいバージョンをローカル ブランチに定期的にマージします。この方法は不器用ですが、コミュニティからの最新の機能と修正を常に最新の状態に保つことができます。
コミュニティに還元する : コードをより適切に管理および保守するために、コミュニティの受け入れとサポートを得るために、変更の一部と個別の要件をコミュニティに提出する予定です。これは、地域のメンテナンス作業を軽減するだけでなく、コミュニティが共に発展するのにも役立ちます。
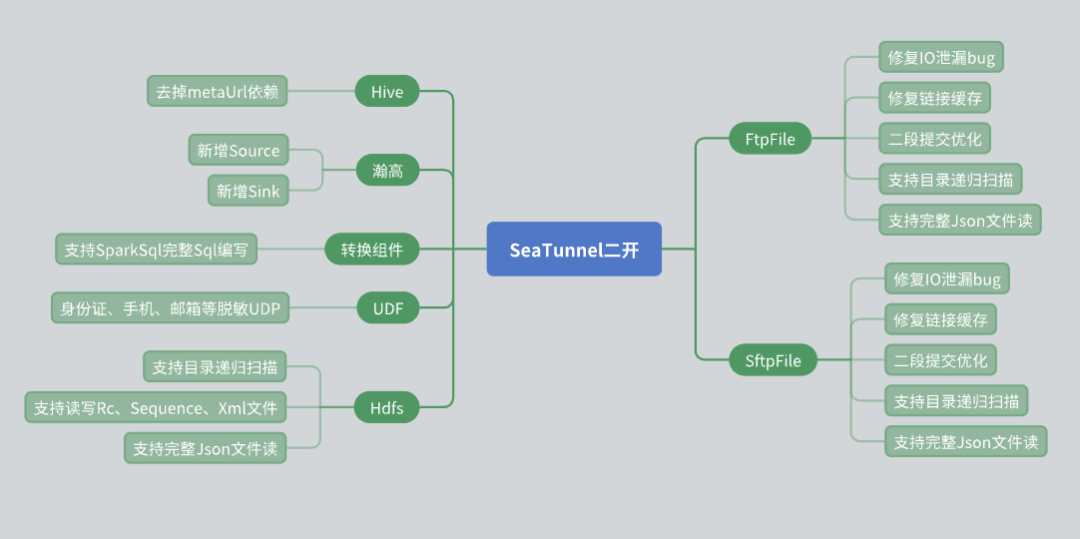
SeaTunnel の使用中に、実際のビジネス ニーズに基づいて、特にコネクタ レベルで多数の二次開発を実施しました。二次開発中に遭遇した問題とその解決策は次のとおりです。
Hiveコネクタの改修
オリジナルの SeaTunnel Hive コネクタは、メタデータを取得するためにメタ URL に依存しています。ただし、実際のアプリケーションでは、セキュリティの問題により、多くのサードパーティ ユーザーがメタ URL を提供できません。この状況に対処するため、以下の変更を加えました。 Hive Server 2 の JDBC インターフェイスを使用してテーブルのメタデータ情報を取得し、メタ URL への依存を回避します。 このようにして、データのセキュリティを確保しながら、より柔軟に Hive データの読み取りと書き込みを行う機能をユーザーに提供できます。 Hangao データベースのサポート
Hangao データベースは私たちのプロジェクトで広く使用されているため、Hangao データベースに対するデータ ソースの読み取りと書き込みのサポートを追加しました。同時に、Hangao データベースのいくつかの特別なニーズを満たす変換コンポーネントを開発しました。 行から列、列から行などの複雑な変換操作をサポートします。 データの感度解除やその他の操作のためにさまざまな UDF (ユーザー定義関数) を作成しました。 ファイルコネクタの修正
ファイル システム コネクタは使用において重要な役割を果たすため、これにいくつかの変更を加えました。 HDFS コネクタ : 複数のファイル形式 (RC、Sequence、XML、JSON など) の読み書きをサポートしながら、ディレクトリ再帰とファイルの正規表現スキャンの機能を追加しました。FTP および SFTP コネクタ : I/O リークのバグを修正し、同じ IP を持つ異なるアカウント間の独立性を確保するために接続キャッシュ メカニズムを最適化しました。2 段階の送信メカニズムの最適化 SeaTunnel を使用する過程で、私たちはデータの一貫性を確保するための 2 段階の送信メカニズムを深く理解しました。このプロセス中に遭遇した問題と解決策は次のとおりです。
問題の説明 : FTP および SFTP を使用してファイルを書き込むと、書き込み権限がないことを示すエラー メッセージが表示されます。調査の結果、データの一貫性を確保するために、SeaTunnel は最初にファイルを一時ディレクトリに書き込んでから、それを移動することが判明しました。
しかし、一時ディレクトリに別のアカウントの権限設定があったため、書き込みに失敗しました。
解決 注: 一時ディレクトリを作成するときは、すべてのアカウントに書き込み権限があることを確認するために、より大きな権限 (777 など) を設定します。同時に、ファイル移動中のファイル システム間での名前変更コマンドの失敗の問題も解決します。同じファイル システム内に一時ディレクトリを作成することで、ファイル システム間での操作が回避されます。
二次開発管理
二次開発プロセス中に、新しいバージョンの SeaTunnel を管理および同期する方法という問題に直面しました。私たちの解決策は次のとおりです。
地方支店の管理 : SeaTunnel 2.3.2 バージョンに基づいてローカル ブランチをプルしましたコミュニティの最新情報を定期的に組み込む : コミュニティの新しいバージョンを定期的にローカル ブランチにマージして、コミュニティから新しい機能や修正をタイムリーに入手できるようにします。コミュニティに還元する : コミュニティの受け入れとサポートを得るために、変更と個別の要件の一部をコミュニティに提出し、それによってローカル メンテナンスの作業負荷を軽減する予定です。SeaTunnel の統合とアプリケーション
SeaTunnel を統合するプロセスでは、主に次の点に重点を置きます。
リソース割り当ての最適化 : SeaTunnel の分散アーキテクチャを利用すると、リソース割り当ての問題が簡素化され、追加の分散スケジューリング機能は必要なくなります。テクノロジースタックの統合 : DataX、Spark、FlinkCDC などのさまざまなテクノロジー スタックの機能を SeaTunnel に統合し、それらを均一にカプセル化して、ETL と ELT の統合を実現します。上記の手順と戦略を通じて、SeaTunnel をデータ統合サービスに統合することに成功し、古いシステムのいくつかの重要な問題を解決し、システムのパフォーマンスと安定性を最適化しました。
このプロセス中、私たちはコミュニティに積極的に参加し、支援を求め、問題に関するフィードバックを提供して、統合作業がスムーズに進むようにします。この積極的な交流により、技術レベルが向上するだけでなく、SeaTunnel コミュニティの発展も促進されます。
SeaTunnel に参加する過程で、私は次のような経験をしました。
時が来ました : SeaTunnel の急速な開発段階でこのプロジェクトを選択しましたが、タイミングが非常に良かったです。 SeaTunnel の開発は、できることがたくさんあるという大きな自信を私たちに与えてくれます。個人的な目標 :私は今年の初めにオープンソースコミュニティに参加するという目標を立て、積極的に行動に移しました。コミュニティへの親しみやすさ : SeaTunnel コミュニティは非常にフレンドリーで、誰もがスムーズにコミュニケーションをとり、お互いに助け合っています。このポジティブな雰囲気は、私にとってその一員であることに非常に価値があります。オープンソース コミュニティに参加したいとずっと思っていたものの、まだ最初の一歩を踏み出せていない人には、ぜひ踏み出すことをお勧めします。コミュニティで最も重要なのは、参加している限り、あなたはコミュニティの不可欠な一員です。
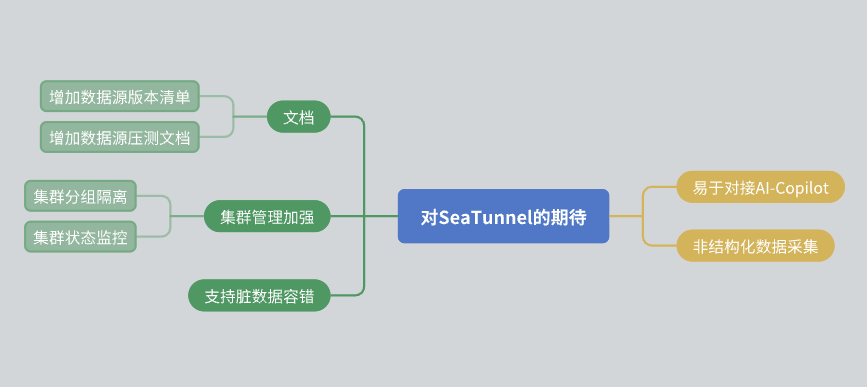
最後に、SeaTunnel に対する期待をいくつか共有したいと思います。
ドキュメントの改善 : コミュニティがデータ ソースのバージョン リストやストレス テスト レポートなどのドキュメントをさらに改善できることを願っています。クラスター管理 : SeaTunnel がクラスタ内でリソースの分離を実現し、より豊富なクラスタ ステータス監視情報を提供できることが期待されています。データフォールトトレランス : SeaTunnel にはすでにフォールト トレラント メカニズムが備わっていますが、将来的にはさらに最適化できることを期待しています。AIの統合 : SeaTunnel が AI 支援アクセスを容易にするためのより多くのインターフェイスを提供できることを願っています。 SeaTunnel コミュニティのメンバーの皆様のご尽力に感謝いたします。私からのシェアは以上です、皆さんありがとうございました!
この記事を書いているのは、 Beluga オープンソース テクノロジー 出版サポートあり!