Compartilhamento prático da AsiaInfo Technology no Apache SeaTunnel
Auto-apresentação
Olá colegas, tenho a honra de compartilhar e me comunicar com vocês por meio da comunidade Apache SeaTunnel. Sou Pan Zhihong, da AsiaInfo Technology. Sou o principal responsável pelo desenvolvimento dos produtos de data center interno da empresa.
O tópico deste compartilhamento é a prática de integração do Apache SeaTunnel na AsiaInfo Technology. Especificamente, falaremos sobre como nosso data center integra o SeaTunnel.
Compartilhar visão geral do conteúdo
Nesta partilha vou focar-me nos seguintes aspectos:
Por que escolher o SeaTunnel
Como integrar o SeaTunnel
Problemas encontrados durante a integração do SeaTunnel
Desenvolvimento secundário do SeaTunnel
Expectativas para o SeaTunnel
Por que escolher o SeaTunnel
Em primeiro lugar, deixe-me apresentar que sou o principal responsável pelo desenvolvimento iterativo do produto de data center DATAOS da AsiaInfo. DATAOS é um produto de data center relativamente padrão, abrangendo módulos funcionais como integração de dados, desenvolvimento de dados, governança de dados e abertura de dados. O principal relacionado ao SeaTunnel é o módulo de integração de dados, que é o principal responsável pela integração de dados.
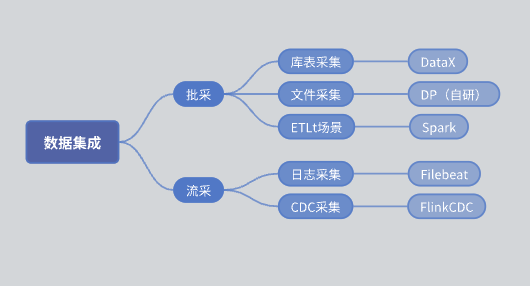
Antes da introdução do SeaTunnel, a arquitetura funcional do nosso módulo de integração de dados era a seguinte:
compra em lote: Dividido em coleção de tabelas de biblioteca e coleção de arquivos.
Coleção de tabelas de biblioteca: implementada principalmente usando DataX.
Coleção de arquivos: mecanismo DP autodesenvolvido.
Coleta ETLt: mecanismo de coleta ETLt autodesenvolvido. DataX prefere ELT (extração, carregamento, conversão), que é adequado para conversões complexas após extração e armazenamento de dados. No entanto, em alguns cenários, EL pequeno T (extração, carregamento, conversão simples) é necessário e DataX não é adequado. Portanto, desenvolvemos um motor baseado em Spark SQL.
Liucai: A coleta de log é baseada principalmente no Filebeat e a coleta de CDC é baseada principalmente no Flink CDC.
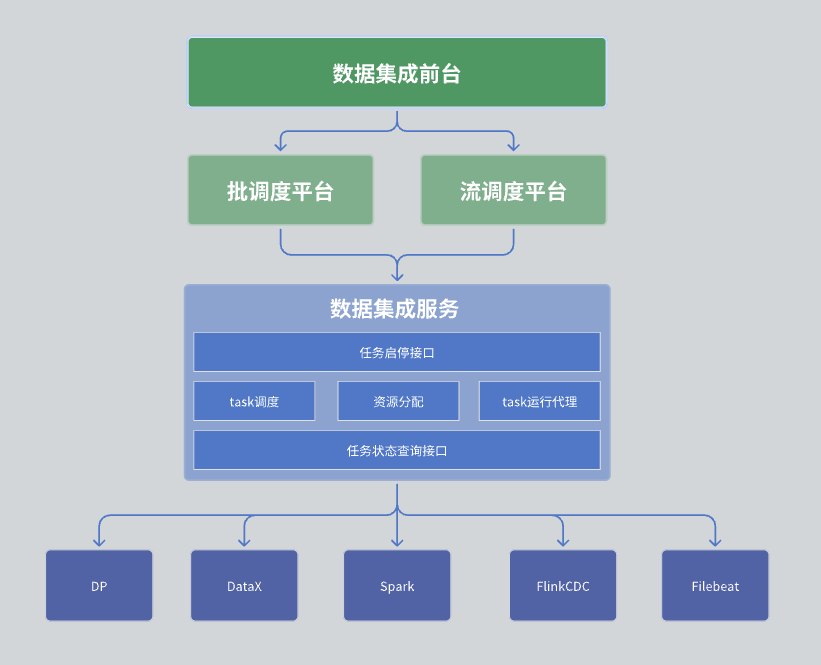
Em nosso módulo de integração de dados, a arquitetura geral é dividida em três camadas, ou seja, recepção de integração de dados, plataforma de agendamento e serviço de integração de dados.
Abaixo está uma descrição detalhada de cada camada:
A primeira camada: recepção de integração de dados
O front desk de integração de dados é o principal responsável pelo gerenciamento das tarefas de integração de dados. Especificamente, inclui desenvolvimento de tarefas, desenvolvimento de agendamento e monitoramento de operações. Essas tarefas combinam vários operadores integrados por meio de DAG (Directed Acíclico Graph) para implementar processos complexos de processamento de dados. A interface front-end fornece uma interface intuitiva de gerenciamento de tarefas, permitindo aos usuários configurar e monitorar facilmente tarefas de integração de dados.
Segunda camada: plataforma de agendamento
A plataforma de agendamento é responsável pelo agendamento e gerenciamento das operações de tarefas. Ele oferece suporte aos modos de processamento em lote e processamento de fluxo e pode gerar tarefas correspondentes com base em dependências de tarefas e estratégias de agendamento.
A terceira camada: serviço de integração de dados
O serviço de integração de dados é o núcleo de todo o serviço de data center, que fornece uma série de funções principais:
Interface de gerenciamento de tarefas: Incluindo funções como criação, exclusão, atualização e consulta de tarefas.
Interface de início e parada de tarefas: permite que os usuários iniciem ou interrompam tarefas específicas.
Interface de consulta de status de tarefa: consulte as informações de status atual da tarefa para facilitar o monitoramento e o gerenciamento.
O serviço de integração de dados também é responsável pela execução específica de tarefas. Como nossa tarefa de coleta pode incluir vários mecanismos, isso requer coordenação e agendamento de vários mecanismos quando a tarefa estiver em execução.
Processo de execução de tarefas
A execução da tarefa inclui principalmente as seguintes etapas:
Agendamento de tarefas: De acordo com a estratégia de agendamento e dependências predeterminadas, a plataforma de agendamento puxa as tarefas correspondentes.
Execução de tarefas: Durante a execução da tarefa, cada operador é executado em sequência de acordo com a configuração DAG da tarefa.
Coordenação multimotor: Para tarefas que contêm vários mecanismos (como tarefas híbridas DataX e Spark), é necessário coordenar a operação de cada mecanismo durante o processo de execução para garantir a execução suave da tarefa.
Alocação de recursos
Ao mesmo tempo, para permitir que o DataX, uma tarefa autônoma, funcione melhor de maneira distribuída e consiga a reutilização de recursos, otimizamos a alocação de recursos para a tarefa DataX:
Agendamento distribuído: por meio do mecanismo de alocação de recursos, as tarefas do DataX são distribuídas para execução em vários nós para evitar gargalos de ponto único e melhorar o paralelismo de tarefas e a eficiência de execução.
Reutilização de recursos: Através de estratégias razoáveis de gestão e alocação de recursos, garantir a reutilização eficiente de recursos para diferentes tarefas e reduzir o desperdício de recursos.
agente de execução de tarefas
Implementamos agentes de execução de tarefas correspondentes para cada mecanismo de execução para obter gerenciamento e monitoramento unificado de tarefas:
agente do mecanismo de execução : No serviço de integração de dados, o agente gerencia diversos mecanismos de execução, como DataX, Spark, Flink CDC, etc. O agente é responsável por iniciar, parar e monitorar o status das tarefas.
interface unificada: Fornece uma interface unificada de gerenciamento de tarefas para que tarefas de diferentes motores possam ser gerenciadas através da mesma interface, simplificando o trabalho de operação, manutenção e gerenciamento.
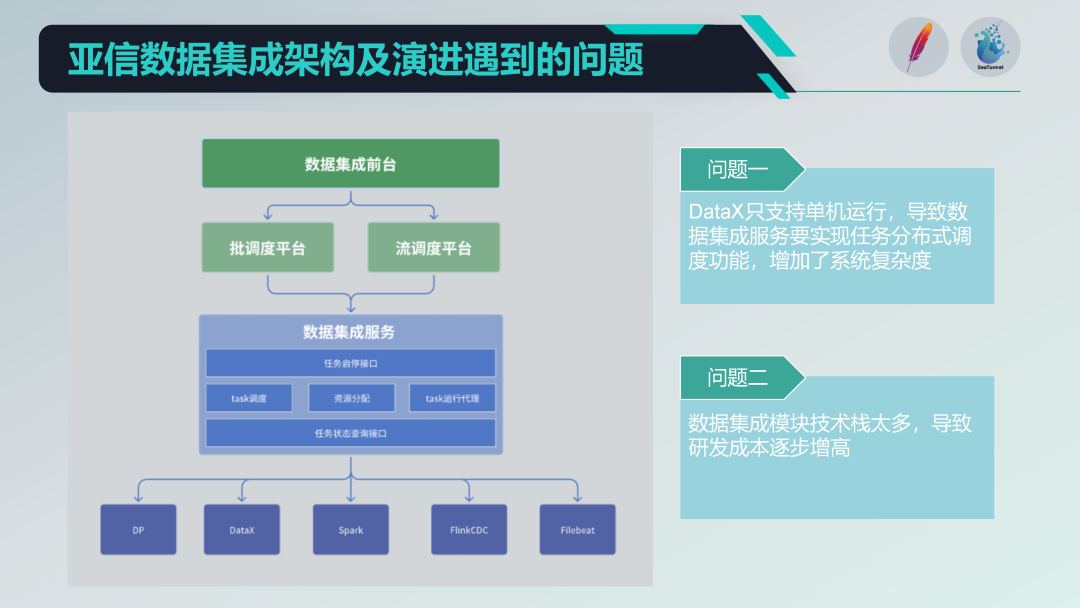
Alguns problemas com a antiga arquitetura de integração de dados
Integramos alguns projetos de código aberto, como DataX, Spark, Flink CDC, Filebeat, etc., para formar uma poderosa plataforma de serviços de integração de dados. Mas também enfrentamos alguns problemas:
Restrições de operação de máquina única: O DataX oferece suporte apenas à operação em uma única máquina, o que exige a implementação de funções de agendamento distribuídas em sua base, o que aumenta a complexidade do sistema.
A pilha de tecnologia é muito diversificada: A introdução de múltiplas pilhas de tecnologia (como Spark e Flink), embora ricas em funções, também leva a altos custos de pesquisa e desenvolvimento. Cada vez que novas funções são desenvolvidas, é necessário lidar com problemas de compatibilidade e integração de múltiplas pilhas de tecnologia.
Evolução da arquitetura
Para otimizar a arquitetura e reduzir a complexidade, evoluímos a arquitetura existente:
Integre a funcionalidade multimotor: Após a introdução do SeaTunnel, podemos unificar as funções de vários motores e obter vários recursos de processamento de dados em uma única plataforma.
Simplifique o gerenciamento de recursos: A função de gerenciamento de recursos do SeaTunnel simplifica o agendamento distribuído de tarefas autônomas, como DataX, e reduz a complexidade da alocação e gerenciamento de recursos.
Reduza os custos de P&D: Por meio de arquitetura unificada e design de interface, os custos de desenvolvimento e manutenção causados por múltiplas pilhas de tecnologia são reduzidos e a escalabilidade e facilidade de manutenção do sistema são melhoradas.
Através da otimização e evolução da arquitetura, resolvemos com sucesso os problemas de limitações de operação de máquina única DataX e altos custos de P&D causados por múltiplas pilhas de tecnologia.
Após a introdução do SeaTunnel, conseguimos implementar múltiplas funções de processamento de dados em uma plataforma, simplificando ao mesmo tempo o gerenciamento de recursos e o agendamento de tarefas, além de melhorar a eficiência geral e a estabilidade do sistema.
Por que escolher o SeaTunnel?
Nosso contato com o SeaTunnel remonta ao período Waterdrop, e realizamos muitas práticas de aplicação para Waterdrop.
No ano passado, o SeaTunnel lançou o mecanismo Zeta, apoiou a arquitetura distribuída e se tornou um projeto Apache de nível superior. Isso nos permitiu encontrar um ponto de tempo adequado no ano passado, realizar pesquisas aprofundadas e decidir introduzir o SeaTunnel.
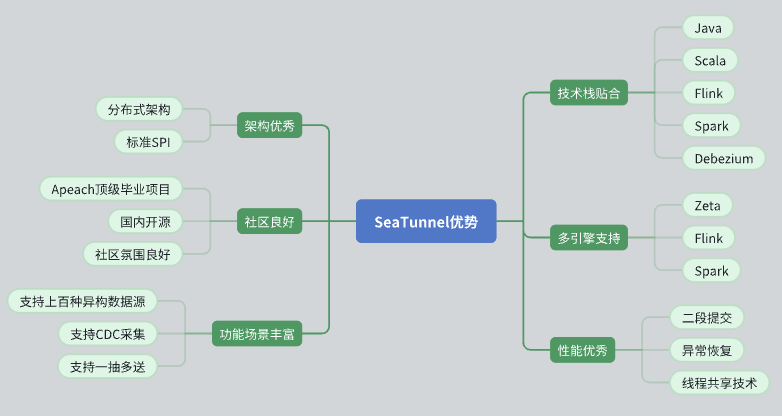
Aqui estão algumas das principais razões pelas quais escolhemos o SeaTunnel:
Excelente projeto arquitetônico
SeaTunnel possui uma arquitetura distribuída que funciona bem para nossas necessidades.
Seu design de API é padronizado e adota o modo SPI (Service Provider Interface) para facilitar a expansão e integração.
Apoio comunitário ativo
SeaTunnel é um projeto Apache de nível superior com uma boa atmosfera de comunidade. Os grupos ativos de desenvolvedores e usuários fornecem forte suporte para resolução de problemas e expansão de funções.
O histórico de projetos nacionais de código aberto torna nossa comunicação e colaboração mais fáceis.
Funcionalidade avançada e suporte a fontes de dados
SeaTunnel suporta múltiplas fontes de dados e possui funções avançadas para atender às nossas diversas necessidades de processamento de dados.
Suporta CDC (Change Data Capture), permitindo sincronização e processamento de dados em tempo real.
Suporta modo de transmissão de dados um para muitos, melhorando a flexibilidade da transmissão de dados.
Ajuste da pilha de tecnologia
SeaTunnel é compatível com Java e suporta Flink e Spark, permitindo-nos integrá-lo e aplicá-lo perfeitamente na pilha de tecnologia existente.
Usando Debezium para captura de dados CDC, a tecnologia está madura e estável.
Suporte multimotor
SeaTunnel oferece suporte a uma variedade de mecanismos de computação, incluindo Zeta, Flink e Spark, e pode selecionar o mecanismo mais adequado para cálculo de acordo com necessidades específicas.
Isto é muito importante porque nos permite escolher o modo de computação ideal em diferentes cenários, melhorando a flexibilidade e eficiência do sistema.
Excelente desempenho
SeaTunnel projetou mecanismos de otimização de desempenho, como confirmação de duas fases, recuperação de tolerância a falhas e compartilhamento de thread para garantir processamento de dados eficiente e estável.
Problemas resolvidos após a introdução do SeaTunnel
SeaTunnel resolve os dois problemas principais que mencionamos anteriormente:
Agendamento distribuído
O DataX só pode ser executado em uma única máquina e precisamos implementar funções adicionais de agendamento distribuído. SeaTunnel suporta inerentemente arquitetura distribuída Seja usando Zeta, Flink ou Spark como mecanismo de computação, ele pode implementar facilmente o processamento de dados distribuído, simplificando bastante nosso trabalho.
Integração da pilha de tecnologia
Anteriormente, usamos uma variedade de pilhas de tecnologia, incluindo DataX, Spark, Flink CDC, etc., o que tornou os custos de P&D altos e o sistema complexo. Ao encapsular uniformemente essas pilhas de tecnologia, o SeaTunnel fornece uma plataforma integrada que pode suportar processos ELT e ETL, simplificando bastante a arquitetura do sistema e reduzindo os custos de desenvolvimento e manutenção.
Como integrar o SeaTunnel
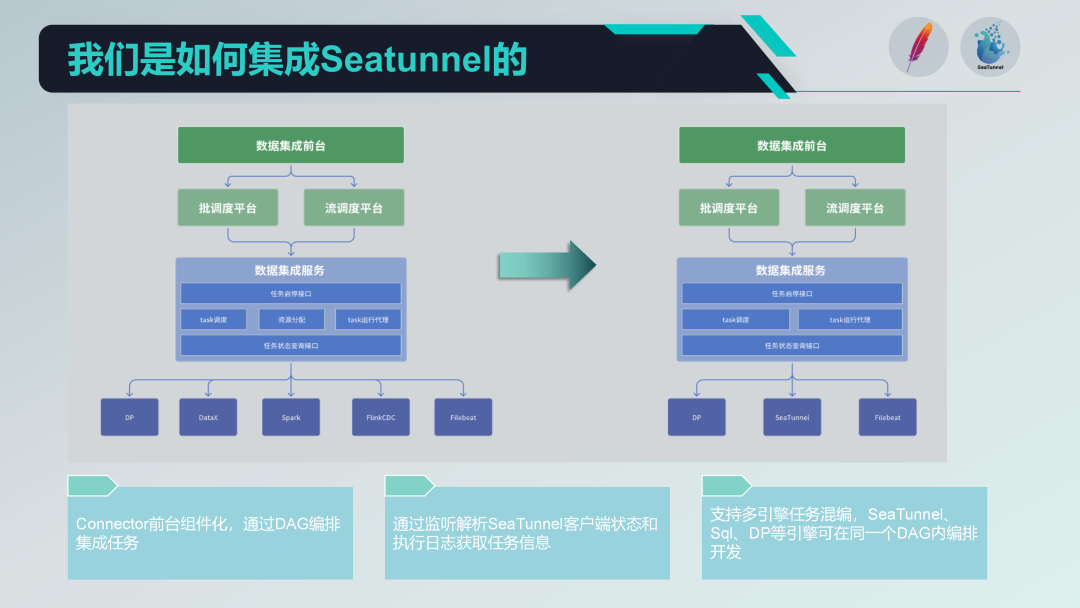
Antes de integrar o SeaTunnel, nossa arquitetura antiga já existia e funcionava há algum tempo. Ela era dividida em três camadas: recepção, plataforma de agendamento e serviço de integração de dados. A recepção é responsável pelo gerenciamento e desenvolvimento de tarefas, a plataforma de agendamento é responsável pelo agendamento de tarefas e gerenciamento de dependências, e o serviço de integração de dados é a parte central da execução e gerenciamento de todas as tarefas de integração de dados.
A seguir está nossa nova arquitetura após a integração do SeaTunnel.
Primeiro, eliminamos a parte de alocação de recursos da arquitetura antiga envolvendo DataX. Como o próprio SeaTunnel suporta arquitetura distribuída, o gerenciamento adicional de alocação de recursos não é mais necessário. Esse ajuste simplifica muito nossa arquitetura.
Substituição da pilha de tecnologia
Gradualmente substituímos a antiga pilha de tecnologia pelo SeaTunnel. As etapas específicas são as seguintes:
Substituição de tarefas de processamento em lote: primeiro substituímos a parte da arquitetura antiga que usava DataX e Spark para ETL de processamento em lote.
Substitua a tarefa de processamento de fluxo: A seguir, substituiremos gradualmente a peça usando o Flink CDC para processamento de fluxo. Ao adotar esta abordagem passo a passo, podemos garantir que o sistema permaneça estável durante a transição gradual.
Conector SeaTunnel Componentizado
Conduzimos um design baseado em componentes baseado no Connector do SeaTunnel e realizamos configuração e orquestração de DAG por meio de formulários no front-end. Embora o SeaTunnel Web também esteja fazendo um trabalho semelhante, customizamos o desenvolvimento de acordo com nossas próprias necessidades para melhor integração com os sistemas existentes.
agente de execução de tarefas
Em termos de agentes de execução de tarefas, enviamos tarefas através do cliente SeaTunnel e monitoramos o status e os logs de execução do cliente SeaTunnel. Ao analisar esses logs, podemos obter informações sobre o status de execução da tarefa e garantir a monitorabilidade e rastreabilidade da execução da tarefa.
Desenvolvimento híbrido multimotor
Oferecemos suporte ao desenvolvimento híbrido multimotor e podemos realizar orquestração DAG multimotor em uma tarefa de agendamento na primeira página. Desta forma, podemos utilizar diferentes motores (como motor SQL e motor DP) em uma tarefa de agendamento ao mesmo tempo para desenvolvimento de tarefas, melhorando a flexibilidade e escalabilidade do sistema.
Problemas encontrados durante a integração do SeaTunnel
No processo de integração do SeaTunnel, encontramos alguns problemas. A seguir estão vários problemas representativos e suas soluções:
Pergunta 1: Tratamento de erros
No processo de utilização do SeaTunnel, encontramos alguns relatórios de erros relacionados ao código do framework. Como não há instruções relevantes nos documentos oficiais, nos juntamos ao grupo WeChat da comunidade e pedimos ajuda aos desenvolvedores do grupo, e resolvemos o problema a tempo.
Pergunta 2: Transferência de tarefas
Nossas tarefas de coleta antigas foram implementadas usando DataX. Ao substituí-las pelo SeaTunnel, precisamos considerar problemas de transferência de tarefas.
Resolvemos isso através das seguintes soluções:
Projeto de componentes : Nossas tarefas de coleta de dados no middle office são projetadas com base em componentes e há uma camada de conversão entre os componentes front-end e o mecanismo de execução back-end. O frontend configura o formulário e o backend gera o arquivo JSON que o DataX precisa para executar por meio da camada de conversão.
Geração de arquivo JSON semelhante : A configuração do SeaTunnel é semelhante à do DataX. O frontend também é configurado por meio de um formulário, e o arquivo JSON que o SeaTunnel precisa executar é gerado no backend. Desta forma, podemos transferir facilmente tarefas antigas para a nova plataforma SeaTunnel, garantindo uma transição suave de tarefas.
Conversão de script SQL : Escreva scripts SQL para limpar e converter tarefas antigas do DataX para que possam se adaptar ao SeaTunnel. Este método é mais flexível e adaptável, porque o SeaTunnel será atualizado com frequência e escrever diretamente o código rígido para compatibilidade não é uma solução de longo prazo. Através da conversão de scripts, as tarefas podem ser migradas com mais eficiência para se adaptarem às atualizações do SeaTunnel.
Pergunta 3: Gerenciamento de versões
Encontramos problemas de gerenciamento de versão ao usar o SeaTunnel. O SeaTunnel é atualizado com frequência e nossa equipe precisa acompanhar continuamente a versão mais recente para a segunda versão. Aqui está a nossa solução:
Gerenciamento de filial local : Extraímos uma filial local baseada no SeaTunnel versão 2.3.2 e conduzimos o desenvolvimento secundário nela, incluindo a correção de requisitos personalizados e correções temporárias de bugs. Para minimizar a quantidade de código mantido localmente, retemos apenas as alterações necessárias e tentamos usar a versão mais recente da comunidade para outras partes.
Atualizações da comunidade incorporadas regularmente : Mesclamos regularmente novas versões da comunidade na filial local, especialmente para atualizá-las e torná-las compatíveis com as partes que alteramos. Embora esse método seja desajeitado, ele garante que nos manteremos atualizados com os recursos e correções mais recentes da comunidade.
Devolva à comunidade : Para melhor gerenciar e manter o código, planejamos enviar algumas de nossas alterações e requisitos personalizados à comunidade para buscar aceitação e apoio da comunidade. Isto não só ajuda a reduzir o nosso trabalho de manutenção local, mas também ajuda a comunidade a desenvolver-se em conjunto.
Desenvolvimento e prática secundária do SeaTunnel
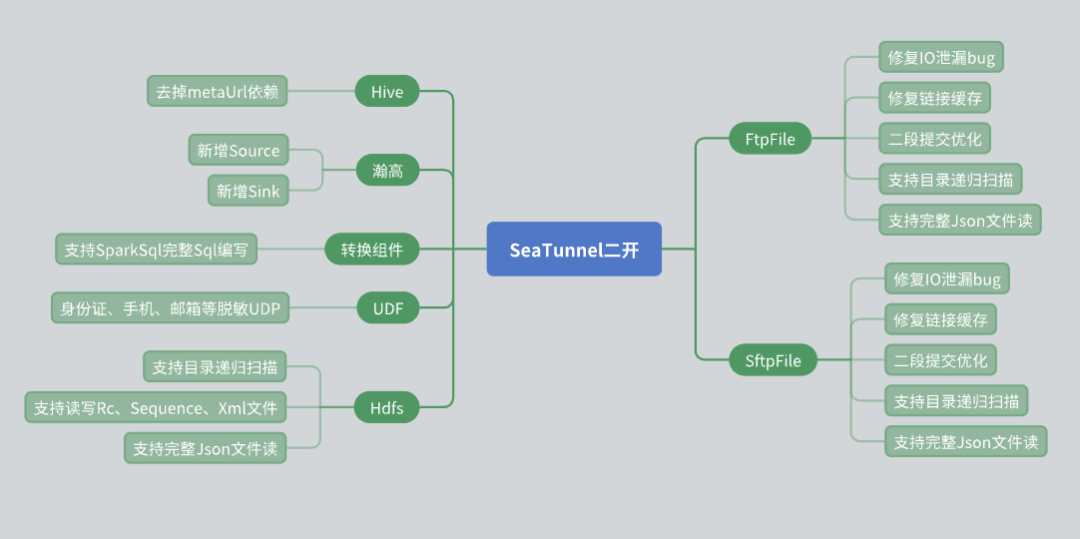
Durante o uso do SeaTunnel, conduzimos uma série de desenvolvimentos secundários com base nas necessidades reais do negócio, especialmente no nível do conector. A seguir estão os problemas e soluções que encontramos durante o desenvolvimento secundário.
Renovação do conector Hive
O SeaTunnel Hive Connector original depende do Meta URL para obter metadados. No entanto, em aplicações reais, muitos usuários terceiros não conseguem fornecer Meta URLs devido a problemas de segurança. Para lidar com esta situação, fizemos as seguintes alterações:
Utilize a interface JDBC do Hive Server 2 para obter as informações de metadados da tabela, evitando assim a dependência da Meta URL.
Dessa forma, podemos fornecer aos usuários a capacidade de ler e gravar dados do Hive com mais flexibilidade e, ao mesmo tempo, garantir a segurança dos dados.
Suporte ao banco de dados Hangao
O banco de dados Hangao é amplamente utilizado em nossos projetos, por isso adicionamos suporte de leitura e gravação de fontes de dados para o banco de dados Hangao. Ao mesmo tempo, desenvolvemos componentes de conversão para atender algumas necessidades especiais do banco de dados Hangao:
Suporta operações de conversão complexas, como linha para coluna e coluna para linha.
Escreveu uma variedade de UDFs (funções definidas pelo usuário) para dessensibilização de dados e outras operações.
Modificação do conector de arquivo
O File System Connector desempenha um papel importante em nosso uso, por isso fizemos várias alterações nele:
Conector HDFS: Adicionada a função de recursão de diretório e verificação de expressão regular de arquivos, ao mesmo tempo em que oferece suporte à leitura e gravação de vários formatos de arquivo (como RC, Sequence, XML, JSON).
Conectores FTP e SFTP: Corrigido o bug de vazamento de E/S e otimizado o mecanismo de cache de conexão para garantir a independência entre diferentes contas com o mesmo IP.
Otimização do mecanismo de envio em duas etapas
No processo de utilização do SeaTunnel, temos um conhecimento profundo de seu mecanismo de envio em dois estágios para garantir a consistência dos dados. A seguir estão os problemas e soluções que encontramos durante este processo:
Descrição do Problema : Ao usar FTP e SFTP para gravar arquivos, uma mensagem de erro indica que não há permissão de gravação. A investigação descobriu que, para garantir a consistência dos dados, o SeaTunnel primeiro gravará o arquivo no diretório temporário e depois o moverá.
No entanto, a gravação falhou devido às configurações de permissão de diferentes contas no diretório temporário.
solução : Ao criar um diretório temporário, defina permissões maiores (como 777) para garantir que todas as contas tenham permissão para gravação. Ao mesmo tempo, ele resolve o problema de falha no comando de renomeação devido a sistemas de arquivos cruzados durante a movimentação de arquivos. Ao criar um diretório temporário no mesmo sistema de arquivos, as operações entre sistemas de arquivos são evitadas.
Gestão de desenvolvimento secundário
Durante o processo de desenvolvimento secundário, enfrentamos o problema de como gerenciar e sincronizar a nova versão do SeaTunnel. Nossa solução é a seguinte:
Gerenciamento de filial local: Puxou uma filial local com base na versão SeaTunnel 2.3.2
Atualizações da comunidade incorporadas regularmente: Mescle regularmente novas versões da comunidade em filiais locais para garantir que possamos obter novos recursos e correções da comunidade em tempo hábil.
Devolva à comunidade: Planejamos submeter algumas de nossas alterações e requisitos personalizados à comunidade, a fim de obter aceitação e apoio da comunidade, reduzindo assim a carga de trabalho de manutenção local.
Integração e aplicativos SeaTunnel
No processo de integração do SeaTunnel, focamos principalmente nos seguintes pontos:
Otimização de alocação de recursos: utilizar a arquitetura distribuída do SeaTunnel simplifica o problema de alocação de recursos e não requer mais funções adicionais de agendamento distribuído.
Integração da pilha de tecnologia: Integre as funções de diferentes pilhas de tecnologia, como DataX, Spark e FlinkCDC, ao SeaTunnel e encapsule-as uniformemente para obter a integração de ETL e ELT.
Através das etapas e estratégias acima, integramos com sucesso o SeaTunnel ao nosso serviço de integração de dados, resolvemos alguns problemas importantes no sistema antigo e otimizamos o desempenho e a estabilidade do sistema.
Durante esse processo, participamos ativamente da comunidade, buscamos ajuda e fornecemos feedback sobre as questões para garantir o bom andamento do trabalho de integração. Esta interação positiva não só melhora o nosso nível técnico, mas também promove o desenvolvimento da comunidade SeaTunnel.
Experiência em participar da comunidade de código aberto
No processo de participação no SeaTunnel, tive as seguintes experiências:
A hora é certa : Escolhemos este projeto durante a fase de rápido desenvolvimento do SeaTunnel e o momento foi muito bom. O desenvolvimento do SeaTunnel nos dá muita confiança de que há muito que pode ser feito.
objetivos pessoais: Estabeleci uma meta de participar da comunidade de código aberto no início deste ano e a coloquei ativamente em ação.
simpatia da comunidade : A comunidade SeaTunnel é muito amigável, todos se comunicam sem problemas e se ajudam. Essa atmosfera positiva faz com que valha a pena fazer parte disso.
Para aqueles que sempre quiseram participar da comunidade de código aberto, mas ainda não deram o primeiro passo, quero encorajá-los a dar o salto. A coisa mais importante sobre uma comunidade são as suas pessoas. Contanto que você participe, você será uma parte indispensável da comunidade.
Expectativas para o SeaTunnel
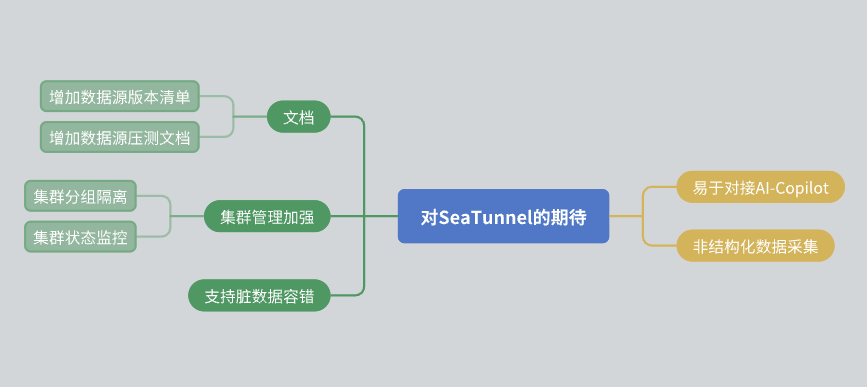
Por fim, gostaria de compartilhar algumas expectativas para o SeaTunnel:
Melhorias na documentação: Espero que a comunidade possa melhorar ainda mais a documentação, incluindo a lista de versões de fontes de dados e relatórios de testes de estresse.
Gerenciamento de cluster: Espera-se que o SeaTunnel possa alcançar o isolamento de recursos dentro do cluster e fornecer informações mais ricas de monitoramento do status do cluster.
Tolerância a falhas de dados: Embora o SeaTunnel já possua um mecanismo de tolerância a falhas, esperamos que ele possa ser otimizado ainda mais no futuro.
Integração de IA: Espero que o SeaTunnel possa fornecer mais interfaces para facilitar o acesso assistido por IA.
Obrigado a todos os membros da comunidade SeaTunnel pelo seu trabalho árduo. Essa é toda a minha partilha, obrigado a todos!