Практический опыт AsiaInfo Technology по Apache SeaTunnel
Самопрезентация
Здравствуйте, сокурсники! Для меня большая честь поделиться с вами информацией и пообщаться с вами через сообщество Apache SeaTunnel. Меня зовут Пан Чжихун из AsiaInfo Technology. Я в основном отвечаю за разработку внутренних продуктов для центров обработки данных компании.
Темой этого обмена является практика интеграции Apache SeaTunnel в AsiaInfo Technology. В частности, мы поговорим о том, как наш центр обработки данных интегрирует SeaTunnel.
Поделиться обзором контента
В этом разделе я остановлюсь на следующих аспектах:
Почему стоит выбрать SeaTunnel
Как интегрировать SeaTunnel
Проблемы, возникшие при интеграции SeaTunnel
Вторичная разработка SeaTunnel
Ожидания от SeaTunnel
Почему стоит выбрать SeaTunnel
Прежде всего, позвольте мне сообщить, что я в основном отвечаю за итеративную разработку продукта DATAOS для центров обработки данных AsiaInfo. DATAOS — это относительно стандартный продукт для центров обработки данных, охватывающий такие функциональные модули, как интеграция данных, разработка данных, управление данными и открытость данных. Главное, что связано с SeaTunnel, — это модуль интеграции данных, который в основном отвечает за интеграцию данных.
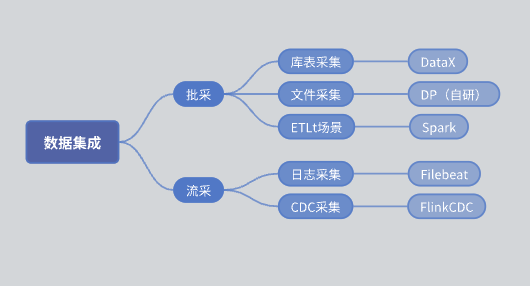
До внедрения SeaTunnel функциональная архитектура нашего модуля интеграции данных была следующей:
пакетная закупка: разделен на коллекцию библиотечных таблиц и коллекцию файлов.
Коллекция таблиц библиотеки: в основном реализована с использованием DataX.
Коллекция файлов: движок DP собственной разработки.
Коллекция ETLt: собственный механизм сбора ETLt. DataX предпочитает ELT (извлечение, загрузка, преобразование), которое подходит для сложного преобразования после извлечения и хранения данных. Однако в некоторых сценариях требуется EL small T (извлечение, загрузка, простое преобразование), и DataX не подходит. Поэтому мы разработали движок на базе Spark SQL.
Люкай: Сбор журналов в основном основан на Filebeat, а сбор CDC — на Flink CDC.
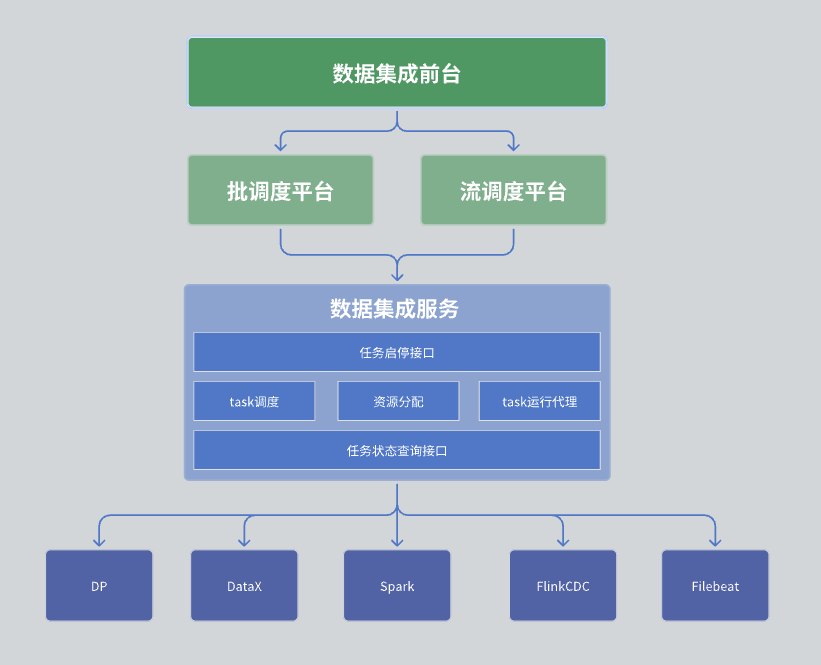
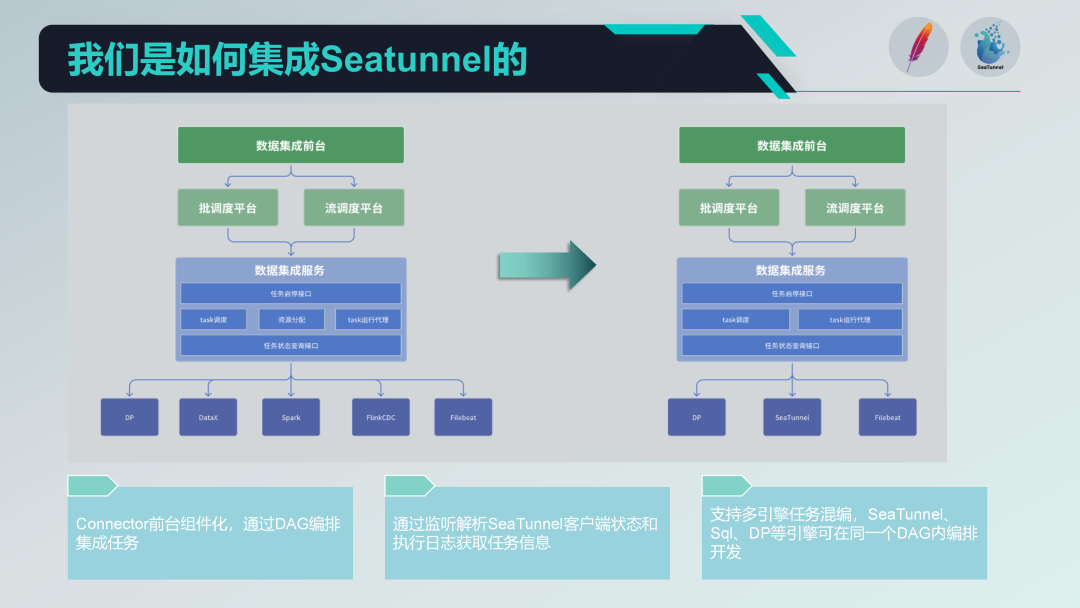
В нашем модуле интеграции данных общая архитектура разделена на три уровня, а именно: стойка регистрации данных, платформа планирования и служба интеграции данных.
Ниже приведено подробное описание каждого слоя:
Первый уровень: стойка интеграции данных
Служба поддержки интеграции данных в основном отвечает за управление задачами по интеграции данных. В частности, он включает в себя разработку задач, составление расписаний и мониторинг операций. Эти задачи объединяют различные интегрированные операторы посредством DAG (Directed Acyclic Graph) для реализации сложных процессов обработки данных. Внешний интерфейс обеспечивает интуитивно понятный интерфейс управления задачами, позволяющий пользователям легко настраивать и отслеживать задачи интеграции данных.
Второй уровень: платформа планирования
Платформа планирования отвечает за планирование и управление операциями задач. Он поддерживает режимы пакетной и потоковой обработки и может вызывать соответствующие задачи на основе зависимостей задач и стратегий планирования.
Третий уровень: сервис интеграции данных
Услуга интеграции данных является ядром всей службы центра обработки данных и обеспечивает ряд ключевых функций:
Интерфейс управления задачами: включая такие функции, как создание, удаление, обновление и запрос задачи.
Интерфейс запуска и остановки задачи: позволяет пользователям запускать или останавливать определенные задачи.
Интерфейс запроса статуса задачи: Запрос информации о текущем состоянии задачи для облегчения мониторинга и управления.
Служба интеграции данных также отвечает за конкретное выполнение задач. Поскольку наша задача сбора данных может включать в себя несколько механизмов, это требует координации и планирования нескольких механизмов во время выполнения задачи.
Процесс выполнения задачи
Выполнение задачи в основном включает в себя следующие этапы:
Планирование задач: В соответствии с заранее определенной стратегией планирования и зависимостями платформа планирования подтягивает соответствующие задачи.
Выполнение задачи: Во время выполнения задачи каждый оператор выполняется последовательно в соответствии с конфигурацией DAG задачи.
Координация нескольких двигателей: Для задач, содержащих несколько механизмов (например, гибридные задачи DataX и Spark), необходимо координировать работу каждого механизма в процессе выполнения, чтобы обеспечить бесперебойное выполнение задачи.
Распределение ресурсов
В то же время, чтобы обеспечить более эффективную распределенную работу автономной задачи DataX и обеспечить повторное использование ресурсов, мы оптимизировали распределение ресурсов для задачи DataX:
Распределенное планирование: Благодаря механизму распределения ресурсов задачи DataX распределяются для выполнения на нескольких узлах, чтобы избежать одноточечных узких мест и улучшить параллелизм задач и эффективность выполнения.
Повторное использование ресурсов: посредством разумного управления ресурсами и стратегий распределения обеспечить эффективное повторное использование ресурсов для различных задач и сократить потери ресурсов.
агент, выполняющий задачи
Мы реализуем соответствующие агенты выполнения задач для каждого механизма выполнения, чтобы обеспечить унифицированное управление и мониторинг задач:
агент механизма выполнения : В сервисе интеграции данных агент управляет различными механизмами выполнения, такими как DataX, Spark, Flink CDC и т. д. Агент отвечает за запуск, остановку и мониторинг состояния задач.
единый интерфейс: Обеспечивает унифицированный интерфейс управления задачами, позволяющий управлять задачами разных модулей через один и тот же интерфейс, что упрощает работу, обслуживание и управление.
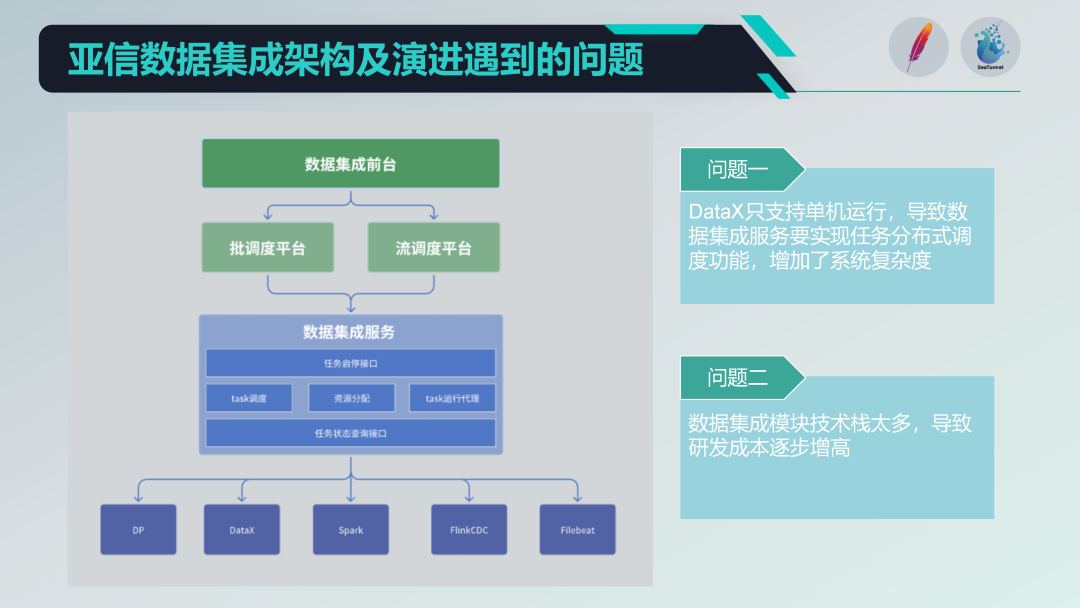
Некоторые проблемы со старой архитектурой интеграции данных
Мы интегрировали некоторые проекты с открытым исходным кодом, такие как DataX, Spark, Flink CDC, Filebeat и т. д., чтобы сформировать мощную платформу службы интеграции данных. Но мы также сталкиваемся с некоторыми проблемами:
Ограничения на работу одной машины: DataX поддерживает только одномашинную работу, что требует от нас реализации на его основе функций распределенного планирования, что увеличивает сложность системы.
Стек технологий слишком разнообразен: Внедрение нескольких стеков технологий (таких как Spark и Flink), хотя и богато функциями, также приводит к высоким затратам на исследования и разработки. Каждый раз, когда разрабатываются новые функции, необходимо решать проблемы совместимости и интеграции нескольких стеков технологий.
Эволюция архитектуры
Чтобы оптимизировать архитектуру и снизить сложность, мы усовершенствовали существующую архитектуру:
Интегрируйте функциональность нескольких движков: После внедрения SeaTunnel мы сможем унифицировать функции нескольких механизмов и реализовать множество возможностей обработки данных на одной платформе.
Упрощение управления ресурсами: Функция управления ресурсами SeaTunnel упрощает распределенное планирование автономных задач, таких как DataX, и снижает сложность распределения ресурсов и управления ими.
Сокращение затрат на исследования и разработки: Благодаря унифицированной архитектуре и дизайну интерфейса затраты на разработку и обслуживание, вызванные использованием нескольких стеков технологий, сокращаются, а масштабируемость и простота обслуживания системы улучшаются.
Благодаря оптимизации и развитию архитектуры мы успешно решили проблемы ограничений работы DataX на одном компьютере и высоких затрат на исследования и разработки, вызванные множеством стеков технологий.
После внедрения SeaTunnel мы смогли реализовать несколько функций обработки данных на одной платформе, упростив при этом управление ресурсами и планирование задач, а также повысив общую эффективность и стабильность системы.
Почему стоит выбрать SeaTunnel?
Наш контакт с SeaTunnel восходит к периоду Waterdrop, и мы провели множество практик применения Waterdrop.
В прошлом году SeaTunnel запустил движок Zeta, поддержал распределенную архитектуру и стал проектом Apache верхнего уровня. Это позволило нам в прошлом году найти подходящий момент времени, провести углубленное исследование и принять решение о внедрении SeaTunnel.
Вот некоторые из основных причин, почему мы выбрали SeaTunnel:
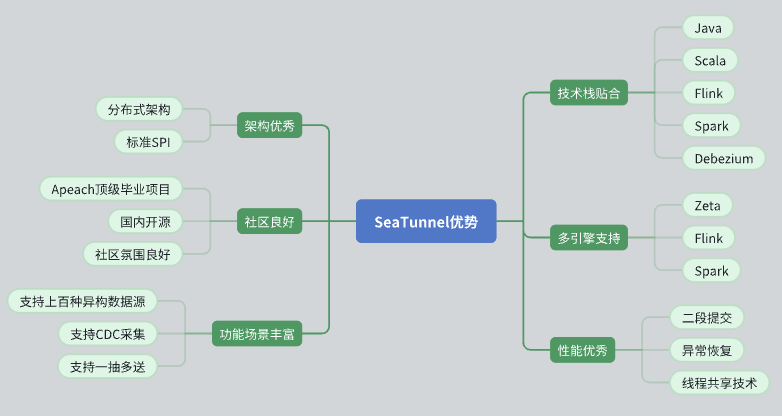
Отличный архитектурный проект
SeaTunnel имеет распределенную архитектуру, которая хорошо подходит для наших нужд.
Его API-интерфейс стандартизирован и использует режим SPI (интерфейс поставщика услуг) для облегчения расширения и интеграции.
Активная поддержка сообщества
SeaTunnel — это проект Apache верхнего уровня с хорошей атмосферой сообщества. Активные группы разработчиков и пользователей оказывают мощную поддержку в решении проблем и расширении функций.
Наличие отечественных проектов с открытым исходным кодом делает наше общение и сотрудничество более гладким.
Богатая функциональность и поддержка источников данных.
SeaTunnel поддерживает несколько источников данных и обладает богатыми функциями для удовлетворения наших разнообразных потребностей в обработке данных.
Поддерживает CDC (Change Data Capture), обеспечивающий синхронизацию и обработку данных в реальном времени.
Поддерживает режим передачи данных «один ко многим», повышая гибкость передачи данных.
Технологический стек подходит
SeaTunnel совместим с Java и поддерживает Flink и Spark, что позволяет нам легко интегрировать и применять его в существующем стеке технологий.
Использование Debezium для сбора данных CDC делает технологию зрелой и стабильной.
Поддержка нескольких двигателей
SeaTunnel поддерживает различные вычислительные механизмы, включая Zeta, Flink и Spark, и может выбрать наиболее подходящую систему для вычислений в соответствии с конкретными потребностями.
Это очень важно, поскольку позволяет нам выбирать оптимальный режим вычислений в разных сценариях, повышая гибкость и эффективность системы.
Превосходное представление
SeaTunnel разработал механизмы оптимизации производительности, такие как двухфазная фиксация, отказоустойчивое восстановление и совместное использование потоков, чтобы обеспечить эффективную и стабильную обработку данных.
Проблемы, решенные после внедрения SeaTunnel
SeaTunnel решает две основные проблемы, о которых мы упоминали ранее:
Распределенное планирование
DataX может работать только на одной машине, и нам необходимо реализовать дополнительные функции распределенного планирования. SeaTunnel по своей сути поддерживает распределенную архитектуру. Независимо от того, используете ли вы в качестве вычислительного механизма Zeta, Flink или Spark, он может легко реализовать распределенную обработку данных, что значительно упрощает нашу работу.
Интеграция стека технологий
Ранее мы использовали различные технологические стеки, включая DataX, Spark, Flink CDC и т. д., что приводило к высоким затратам на исследования и разработки и усложняло систему. Унифицированно инкапсулируя эти стеки технологий, SeaTunnel предоставляет интегрированную платформу, которая может поддерживать как процессы ELT, так и ETL, что значительно упрощает архитектуру системы и снижает затраты на разработку и обслуживание.
Как интегрировать SeaTunnel
До интеграции SeaTunnel наша старая архитектура существовала и работала некоторое время. Она была разделена на три уровня: стойка регистрации, платформа планирования и служба интеграции данных. Стойка регистрации отвечает за управление задачами и их разработку, платформа планирования отвечает за планирование задач и управление зависимостями, а служба интеграции данных является основной частью выполнения и управления всеми задачами интеграции данных.
Ниже представлена наша новая архитектура после интеграции SeaTunnel.
Во-первых, мы исключили часть старой архитектуры, связанную с распределением ресурсов, связанную с DataX. Поскольку сам SeaTunnel поддерживает распределенную архитектуру, дополнительное управление распределением ресурсов больше не требуется. Эта корректировка значительно упрощает нашу архитектуру.
Замена стека технологий
Мы постепенно заменили старый технологический стек на SeaTunnel. Конкретные шаги заключаются в следующем:
Замена задач пакетной обработки. Сначала мы заменили часть старой архитектуры, которая использовала DataX и Spark для пакетной обработки ETL.
Замените задачу обработки потока: Далее постепенно заменим часть, использующую Flink CDC для обработки потока. Применяя этот поэтапный подход, мы можем гарантировать, что система останется стабильной на протяжении всего постепенного перехода.
Компонентный соединитель SeaTunnel
Мы выполнили компонентное проектирование на основе SeaTunnel Connector, а также выполнили настройку и оркестрацию DAG через формы во внешнем интерфейсе. Хотя SeaTunnel Web также выполняет аналогичную работу, мы адаптировали разработку в соответствии с нашими собственными потребностями, чтобы лучше интегрироваться с существующими системами.
агент, выполняющий задачи
Что касается агентов, выполняющих задачи, мы отправляем задачи через клиент SeaTunnel и отслеживаем состояние и журналы выполнения клиента SeaTunnel. Анализируя эти журналы, мы можем получить информацию о состоянии выполнения задач и обеспечить возможность мониторинга и отслеживания выполнения задач.
Разработка многомоторного гибрида
Мы поддерживаем многоядерную гибридную разработку и можем выполнять многоядерную оркестровку DAG для задачи планирования на главной странице. Таким образом, мы можем использовать разные механизмы (например, механизм SQL и механизм DP) в одной задаче планирования одновременно для разработки задач, улучшая гибкость и масштабируемость системы.
Проблемы, возникшие при интеграции SeaTunnel
В процессе интеграции SeaTunnel мы столкнулись с некоторыми проблемами. Ниже приведены несколько типичных проблем и их решения.
Вопрос 1: Обработка ошибок
В процессе использования SeaTunnel мы столкнулись с некоторыми сообщениями об ошибках, связанных с кодом платформы. Поскольку в официальных документах соответствующих инструкций нет, мы присоединились к группе сообщества WeChat, обратились за помощью к разработчикам группы и вовремя решили проблему.
Вопрос 2. Переключение задач
Наши старые задачи сбора были реализованы с использованием DataX. При замене их на SeaTunnel нам необходимо учитывать проблемы переключения задач.
Мы решаем эту проблему с помощью следующих решений:
Компонентный дизайн : Наши задачи по сбору данных в мидл-офисе разработаны на основе компонентов, и между внешними компонентами и внутренним механизмом выполнения существует уровень преобразования. Внешний интерфейс настраивает форму, а серверная часть генерирует файл JSON, который DataX необходимо выполнить через уровень преобразования.
Аналогичное создание файла JSON : Конфигурация SeaTunnel аналогична конфигурации DataX. Внешний интерфейс также настраивается через форму, а файл JSON, который должен выполнить SeaTunnel, создается во внутренней части. Таким образом, мы можем беспрепятственно перенести старые задачи на новую платформу SeaTunnel, обеспечив плавный переход задач.
Преобразование SQL-скрипта : Напишите сценарии SQL для очистки и преобразования старых задач DataX, чтобы их можно было адаптировать к SeaTunnel. Этот метод является более гибким и адаптируемым, поскольку SeaTunnel будет часто обновляться, а прямое написание жесткого кода для обеспечения совместимости не является долгосрочным решением. Благодаря преобразованию сценариев задачи можно более эффективно переносить для адаптации к обновлениям SeaTunnel.
Вопрос 3: Управление версиями
При использовании SeaTunnel мы столкнулись с проблемами управления версиями. SeaTunnel часто обновляется, и нашей команде необходимо постоянно следить за последней версией второй версии. Вот наше решение:
Управление местным филиалом : Мы вытащили локальную ветку на основе SeaTunnel версии 2.3.2 и провели над ней вторичную разработку, включая исправление индивидуальных требований и временные исправления ошибок. Чтобы свести к минимуму объем кода, поддерживаемого локально, мы сохраняем только необходимые изменения и стараемся использовать последнюю версию сообщества для других частей.
Регулярно включаемые обновления сообщества : Мы регулярно объединяем новые версии от сообщества в локальную ветку, специально для того, чтобы обновить и сделать их совместимыми с измененными нами частями. Хотя этот метод неуклюж, он гарантирует, что мы будем в курсе последних функций и исправлений сообщества.
Верните сообществу : Чтобы лучше управлять кодом и поддерживать его, мы планируем представить некоторые из наших изменений и персонализированных требований сообществу, чтобы добиться принятия и поддержки сообщества. Это не только помогает сократить объем работ по техническому обслуживанию на местах, но и помогает сообществу развиваться вместе.
Вторичная разработка и практика SeaTunnel
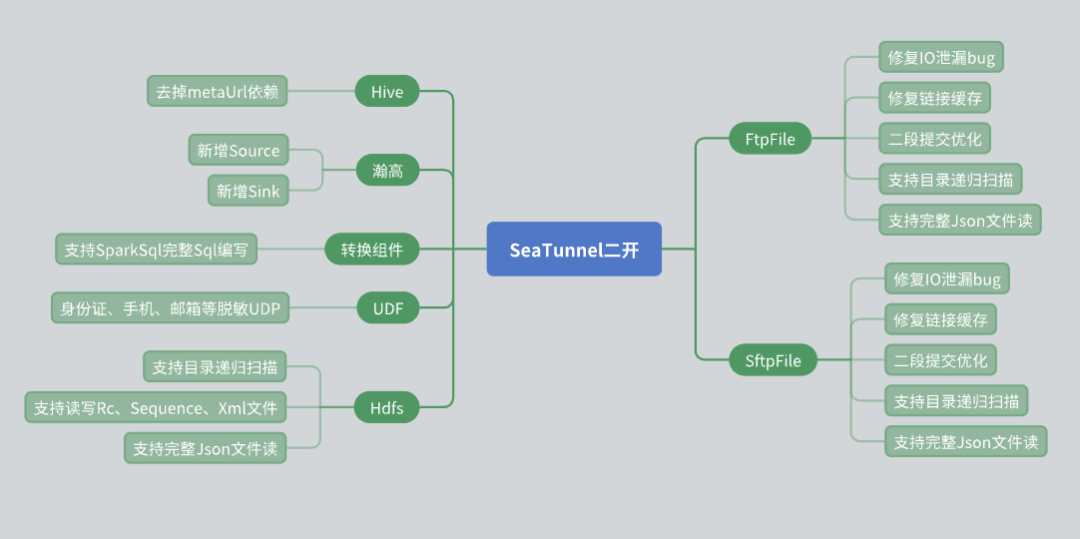
За время использования SeaTunnel мы провели ряд вторичных разработок, исходя из реальных потребностей бизнеса, особенно на уровне разъемов. Ниже приведены проблемы и решения, с которыми мы столкнулись во время вторичной разработки.
Ремонт соединителя улья
Исходный соединитель SeaTunnel Hive Connector использует мета-URL-адрес для получения метаданных. Однако в реальных приложениях многие сторонние пользователи не могут предоставить мета-URL-адреса из-за проблем безопасности. Чтобы справиться с этой ситуацией, мы внесли следующие изменения:
Используйте интерфейс JDBC Hive Server 2 для получения метаданных таблицы, избегая таким образом зависимости от мета-URL.
Таким образом, мы можем предоставить пользователям возможность более гибко читать и записывать данные Hive, обеспечивая при этом безопасность данных.
Поддержка базы данных Хангао
База данных Hangao широко используется в наших проектах, поэтому мы добавили поддержку чтения и записи источников данных для базы данных Hangao. В то же время мы разработали компоненты преобразования для удовлетворения некоторых особых потребностей базы данных Hangao:
Поддерживает сложные операции преобразования, такие как преобразование строки в столбец и столбца в строку.
Написал множество UDF (пользовательских функций) для снижения чувствительности данных и других операций.
Модификация файлового коннектора
Соединитель файловой системы играет важную роль в нашем использовании, поэтому мы внесли в него несколько изменений:
HDFS-коннектор: добавлена функция рекурсии каталогов и сканирования файлов с помощью регулярных выражений, при этом поддерживается чтение и запись файлов нескольких форматов (таких как RC, Sequence, XML, JSON).
Коннекторы FTP и SFTP: исправлена ошибка утечки ввода-вывода и оптимизирован механизм кэширования соединений, чтобы обеспечить независимость между разными учетными записями с одним и тем же IP-адресом.
Оптимизация механизма двухэтапной подачи
В процессе использования SeaTunnel мы хорошо понимаем его двухэтапный механизм отправки, обеспечивающий согласованность данных. Ниже приведены проблемы и решения, с которыми мы столкнулись в ходе этого процесса:
описание проблемы : при использовании FTP и SFTP для записи файлов появляется сообщение об ошибке, указывающее на отсутствие разрешения на запись. Расследование показало, что для обеспечения согласованности данных SeaTunnel сначала записывает файл во временный каталог, а затем перемещает его.
Однако запись не удалась из-за настроек разрешений разных учетных записей во временном каталоге.
решение : При создании временного каталога установите более высокие разрешения (например, 777), чтобы гарантировать, что все учетные записи имеют разрешение на запись. В то же время это решает проблему сбоя команды переименования из-за перекрестных файловых систем во время перемещения файлов. Создавая временный каталог в той же файловой системе, можно избежать операций между файловыми системами.
Управление вторичным развитием
В процессе вторичной разработки мы столкнулись с проблемой управления и синхронизации новой версии SeaTunnel. Наше решение заключается в следующем:
Управление местным филиалом: Вытащил локальную ветку на основе версии SeaTunnel 2.3.2.
Регулярно включаемые обновления сообщества: Регулярно объединяйте новые версии сообщества в местные ветки, чтобы мы могли своевременно получать новые функции и исправления от сообщества.
Верните сообществу: Мы планируем представить некоторые наши изменения и персонализированные требования сообществу, чтобы получить признание и поддержку сообщества, тем самым уменьшая нагрузку на локальное обслуживание.
Интеграция и приложения SeaTunnel
В процессе интеграции SeaTunnel мы в основном фокусируемся на следующих моментах:
Оптимизация распределения ресурсов: Использование распределенной архитектуры SeaTunnel упрощает задачу распределения ресурсов и больше не требует дополнительных функций распределенного планирования.
Интеграция стека технологий: Интегрируйте функции различных стеков технологий, таких как DataX, Spark и FlinkCDC, в SeaTunnel и унифицированно инкапсулируйте их для достижения интеграции ETL и ELT.
Благодаря описанным выше шагам и стратегиям мы успешно интегрировали SeaTunnel в нашу службу интеграции данных, решили некоторые ключевые проблемы в старой системе и оптимизировали производительность и стабильность системы.
В ходе этого процесса мы активно участвуем в жизни сообщества, обращаемся за помощью и предоставляем обратную связь по вопросам, чтобы обеспечить плавный ход интеграционной работы. Это позитивное взаимодействие не только повышает наш технический уровень, но и способствует развитию сообщества SeaTunnel.
Опыт участия в open source сообществе
В процессе участия в SeaTunnel у меня есть следующий опыт:
Время пришло : Мы выбрали этот проект на этапе быстрого развития SeaTunnel, и время было выбрано очень удачно. Развитие SeaTunnel вселяет в нас большую уверенность в том, что еще многое можно сделать.
личные цели: Я поставил перед собой цель поучаствовать в open source сообществе еще в начале этого года и активно реализовал ее.
дружелюбие к сообществу : Сообщество SeaTunnel очень дружелюбное, все слаженно общаются и помогают друг другу. Эта позитивная атмосфера делает для меня очень полезным быть ее частью.
Тех из вас, кто всегда хотел участвовать в сообществе открытого исходного кода, но еще не сделал первого шага, я хочу призвать вас сделать этот шаг. Самое важное в сообществе — это его люди. Пока вы присоединяетесь, вы являетесь незаменимой частью сообщества.
Ожидания от SeaTunnel
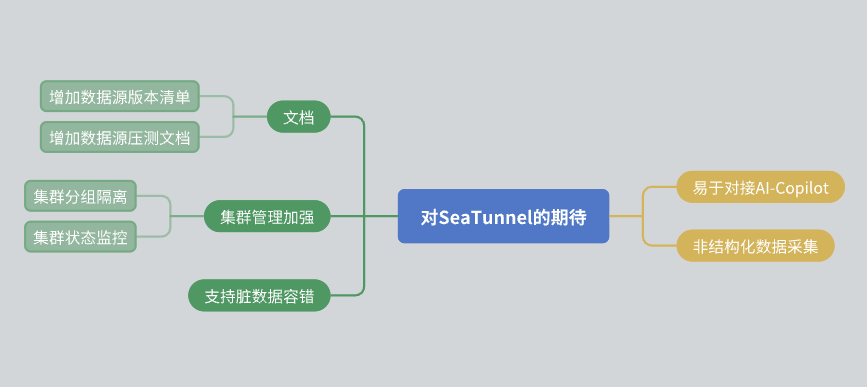
Наконец, я хотел бы поделиться некоторыми ожиданиями от SeaTunnel:
Улучшения документации: Я надеюсь, что сообщество сможет улучшить документацию, включая список версий источников данных и отчеты о стресс-тестах.
Управление кластером: Есть надежда, что SeaTunnel сможет обеспечить изоляцию ресурсов внутри кластера и предоставить более полную информацию для мониторинга состояния кластера.
Отказоустойчивость данных: Хотя в SeaTunnel уже есть отказоустойчивый механизм, мы надеемся, что в будущем его можно будет оптимизировать.
Интеграция ИИ: Я надеюсь, что SeaTunnel сможет предоставить больше интерфейсов для облегчения доступа с помощью искусственного интеллекта.
Спасибо каждому участнику сообщества SeaTunnel за вашу тяжелую работу. Это все, чем я поделился, всем спасибо!