AsiaInfo Technologyn käytännön jako Apache SeaTunnelissa
Itsensä esittely
Hei opiskelijatoverit, minulla on kunnia jakaa ja kommunikoida kanssanne Apache SeaTunnel -yhteisön kautta. Olen Pan Zhihong AsiaInfo Technologysta. Vastaan pääasiassa yrityksen sisäisten datakeskustuotteiden kehittämisestä.
Tämän jakamisen aiheena on Apache SeaTunnelin integrointikäytäntö AsiaInfo Technologyssa. Puhumme erityisesti siitä, kuinka datakeskuksemme integroi SeaTunnelin.
Jaa sisällön yleiskatsaus
Tässä jakamisessa keskityn seuraaviin näkökohtiin:
Miksi valita SeaTunnel
Kuinka integroida SeaTunnel
SeaTunnelin integroinnin aikana havaitut ongelmat
SeaTunnelin toissijainen kehitys
Odotukset SeaTunnelille
Miksi valita SeaTunnel
Ensinnäkin haluan esitellä, että olen pääosin vastuussa AsiaInfon datakeskustuotteen DATAOSin iteratiivisesta kehityksestä. DATAOS on suhteellisen tavallinen konesalituote, joka kattaa toiminnalliset moduulit, kuten tiedon integroinnin, tiedonkehityksen, tiedonhallinnan ja tiedon avoimuuden. SeaTunneliin liittyvä tärkein asia on tiedon integrointimoduuli, joka vastaa pääosin tiedon integroinnista.
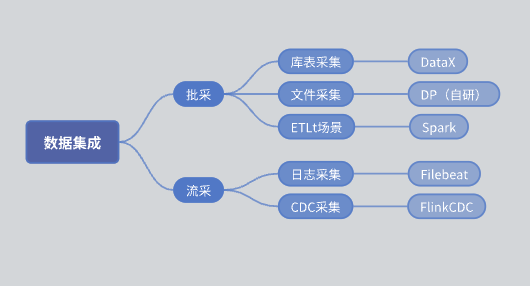
Ennen SeaTunnelin käyttöönottoa dataintegrointimoduulimme toiminnallinen arkkitehtuuri oli seuraava:
erän osto: Jaettu kirjastotaulukkokokoelmaan ja tiedostokokoelmaan.
Kirjastotaulukkokokoelma: toteutettu pääasiassa DataX:llä.
Tiedostokokoelma: itse kehitetty DP-moottori.
ETLt-kokoelma: itse kehitetty ETLt-keräysmoottori. DataX suosii ELT:tä (purkaminen, lataus, muuntaminen), joka soveltuu monimutkaiseen muuntamiseen tietojen purkamisen ja tallennuksen jälkeen. Joissakin skenaarioissa tarvitaan kuitenkin EL Small T (purkaminen, lataus, yksinkertainen muuntaminen) ja DataX ei sovellu. Siksi kehitimme Spark SQL:ään perustuvan moottorin.
Liucai: Lokikokoelma perustuu pääosin Filebeatiin ja CDC-kokoelma perustuu pääosin Flink CDC:hen.
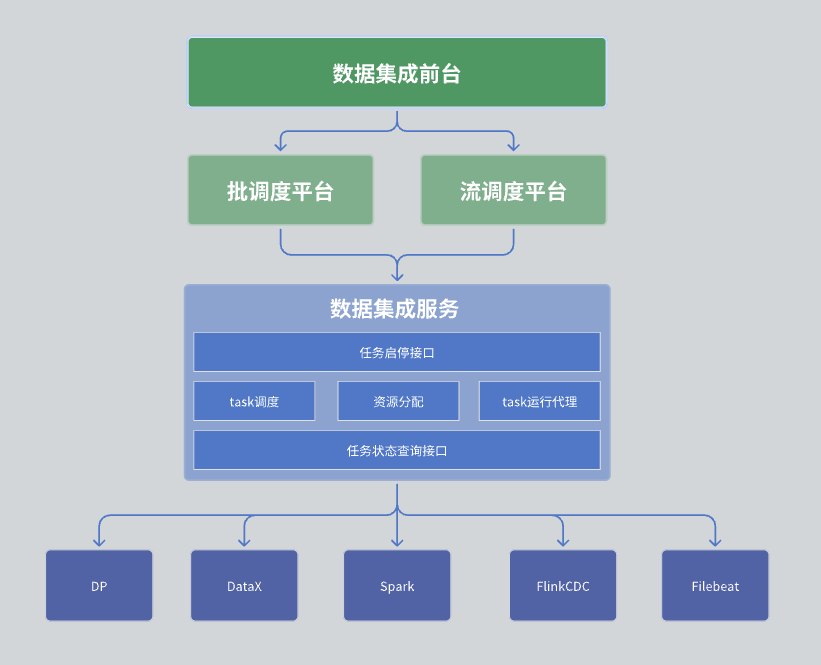
Tietojen integrointimoduulissamme kokonaisarkkitehtuuri on jaettu kolmeen kerrokseen, jotka ovat tiedon integrointivastaanotto, aikataulutusalusta ja dataintegraatiopalvelu.
Alla on yksityiskohtainen kuvaus jokaisesta kerroksesta:
Ensimmäinen kerros: tietojen integroinnin vastaanotto
Tietojen integroinnin vastaanotto vastaa pääosin tiedon integrointitehtävien hallinnasta. Erityisesti se sisältää tehtävien kehittämisen, aikataulujen kehittämisen ja toiminnan seurannan. Nämä tehtävät yhdistävät useita integroituja operaattoreita DAG:n (Directed Acyclic Graph) kautta monimutkaisten tietojenkäsittelyprosessien toteuttamiseksi. Käyttöliittymä tarjoaa intuitiivisen tehtävienhallintaliittymän, jonka avulla käyttäjät voivat helposti määrittää ja valvoa tietojen integrointitehtäviä.
Toinen kerros: Aikataulutusalusta
Aikataulutusalusta vastaa tehtävätoimintojen ajoittamisesta ja hallinnasta. Se tukee sekä eräkäsittely- että stream-käsittelytiloja ja voi noutaa vastaavia tehtäviä tehtävien riippuvuuksien ja ajoitusstrategioiden perusteella.
Kolmas kerros: tietojen integrointipalvelu
Tietojen integrointipalvelu on koko konesalipalvelun ydin, joka tarjoaa joukon avaintoimintoja:
Tehtävienhallinnan käyttöliittymä: Sisältää toimintoja, kuten tehtävien luomisen, poistamisen, päivityksen ja kyselyn.
Tehtävän aloitus- ja lopetusliittymä: Antaa käyttäjien aloittaa tai lopettaa tiettyjä tehtäviä.
Tehtävän tilakyselyn käyttöliittymä: Pyydä tehtävän nykyiset tilatiedot valvonnan ja hallinnan helpottamiseksi.
Tietojen integrointipalvelu vastaa myös tehtävien erityisestä suorittamisesta. Koska keräystehtävämme voi sisältää useita moottoreita, tämä vaatii usean moottorin koordinointia ja aikataulutusta tehtävän ollessa käynnissä.
Tehtävän suoritusprosessi
Tehtävän suorittaminen sisältää pääasiassa seuraavat vaiheet:
Tehtävien ajoitus: Ennalta määrätyn ajoitusstrategian ja riippuvuuksien mukaisesti ajoitusalusta nostaa vastaavat tehtävät.
Tehtävän suoritus: Tehtävän suorittamisen aikana jokainen operaattori suoritetaan järjestyksessä tehtävän DAG-konfiguraation mukaisesti.
Monimoottorinen koordinointi: Tehtävissä, jotka sisältävät useita moottoreita (kuten DataX- ja Spark-hybriditehtävät), on tarpeen koordinoida kunkin moottorin toimintaa suoritusprosessin aikana tehtävän sujuvan suorittamisen varmistamiseksi.
Resurssien kohdentaminen
Samaan aikaan, jotta DataX, itsenäinen tehtävä, voisi toimia paremmin hajautetusti ja saavuttaa resurssien uudelleenkäytön, olemme optimoineet resurssien allokoinnin DataX-tehtävälle:
Hajautettu aikataulu: Resurssien allokointimekanismin avulla DataX-tehtävät hajautetaan toimimaan useissa solmuissa, jotta vältetään yksittäiset pullonkaulat ja parannetaan tehtävien rinnakkaisuutta ja suoritustehokkuutta.
Resurssien uudelleenkäyttö: Varmista resurssien tehokas uudelleenkäyttö eri tehtäviin ja vähennä resurssien tuhlausta järkevällä resurssien hallinnan ja allokointistrategioiden avulla.
tehtävän suorittava agentti
Toteutamme vastaavat tehtävänsuoritusagentit kullekin suoritusmoottorille tehtävien yhtenäisen hallinnan ja seurannan saavuttamiseksi:
suoritusmoottorin agentti : Tietojen integrointipalvelussa agentti hallitsee erilaisia suoritusmoottoreita, kuten DataX, Spark, Flink CDC jne. Agentti vastaa tehtävien käynnistämisestä, pysäyttämisestä ja tilan seurannasta.
yhtenäinen käyttöliittymä: Tarjoaa yhtenäisen tehtävänhallintaliittymän, jotta eri moottoreiden tehtäviä voidaan hallita saman käyttöliittymän kautta, mikä yksinkertaistaa käyttöä, ylläpitoa ja hallintatyötä.
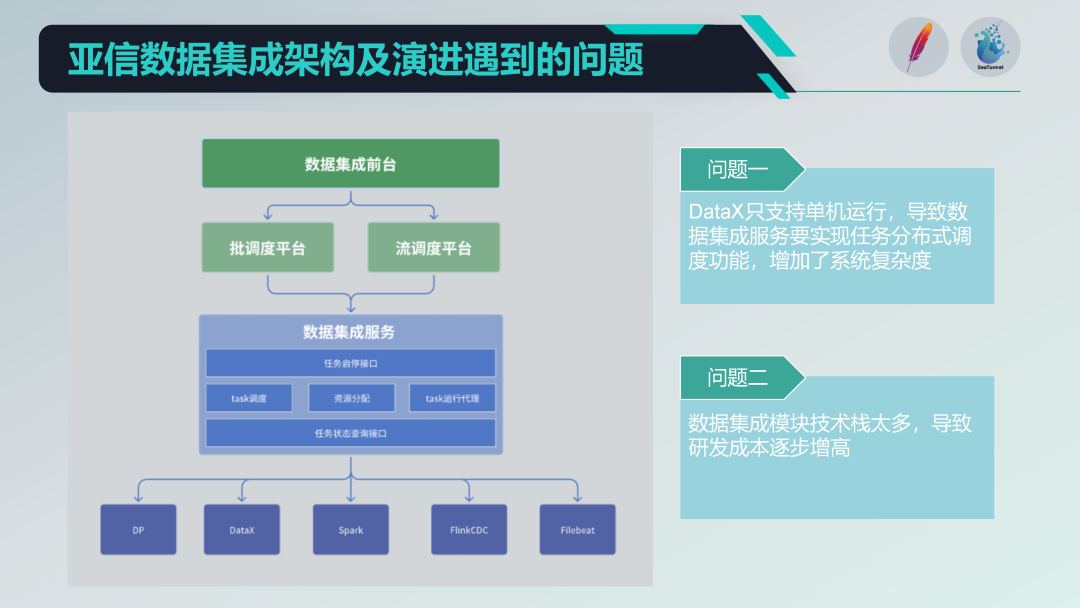
Joitakin ongelmia vanhassa tietojen integrointiarkkitehtuurissa
Olemme integroineet joitain avoimen lähdekoodin projekteja, kuten DataX, Spark, Flink CDC, Filebeat jne., muodostamaan tehokkaan datan integrointipalvelualustan. Mutta meillä on myös joitain ongelmia:
Yhden koneen käyttörajoitukset: DataX tukee vain yhden koneen toimintaa, mikä edellyttää meidän toteuttavan hajautettuja ajoitustoimintoja sen perusteella, mikä lisää järjestelmän monimutkaisuutta.
Teknologiapino on liian monipuolinen: Useiden teknologiapinojen (kuten Spark ja Flink) käyttöönotto johtaa myös korkeisiin tutkimus- ja kehityskustannuksiin Joka kerta kun uusia toimintoja kehitetään, useiden teknologiapinojen yhteensopivuus- ja integrointiongelmat on käsiteltävä.
Arkkitehtuurin evoluutio
Arkkitehtuurin optimoimiseksi ja monimutkaisuuden vähentämiseksi kehitimme olemassa olevaa arkkitehtuuria:
Integroi usean moottorin toiminnallisuus: SeaTunnelin käyttöönoton jälkeen voimme yhdistää useiden moottorien toiminnot ja saavuttaa useita tietojenkäsittelyominaisuuksia yhdellä alustalla.
Yksinkertaista resurssien hallintaa: SeaTunnelin resurssienhallintatoiminto yksinkertaistaa itsenäisten tehtävien, kuten DataX:n, hajautettua ajoitusta ja vähentää resurssien allokoinnin ja hallinnan monimutkaisuutta.
Vähennä T&K-kustannuksia: Yhtenäisen arkkitehtuurin ja käyttöliittymäsuunnittelun ansiosta useiden teknologiapinojen aiheuttamat kehitys- ja ylläpitokustannukset pienenevät ja järjestelmän skaalautuvuus ja ylläpidon helppous paranevat.
Arkkitehtuurin optimoinnin ja kehityksen avulla olemme onnistuneesti ratkaisseet ongelmat, jotka liittyvät DataX:n yhden koneen toiminnan rajoituksiin ja useiden teknologiapinojen aiheuttamiin korkeisiin tutkimus- ja kehityskustannuksiin.
SeaTunnelin käyttöönoton jälkeen pystyimme toteuttamaan useita tietojenkäsittelytoimintoja yhdelle alustalle, yksinkertaistamalla resurssien hallintaa ja tehtävien ajoitusta sekä parantaen järjestelmän yleistä tehokkuutta ja vakautta.
Miksi valita SeaTunnel?
Yhteytemme SeaTunneliin voidaan jäljittää Waterdrop-kaudelle, ja olemme toteuttaneet monia sovelluskäytäntöjä Waterdropille.
Viime vuonna SeaTunnel lanseerasi Zeta-moottorin, tuki hajautettua arkkitehtuuria ja siitä tuli huipputason Apache-projekti. Tämä antoi meille mahdollisuuden löytää sopiva aikapiste viime vuonna, tehdä perusteellista tutkimusta ja päättää ottaa käyttöön SeaTunnel.
Tässä on joitain tärkeimmistä syistä, miksi valitsimme SeaTunnelin:
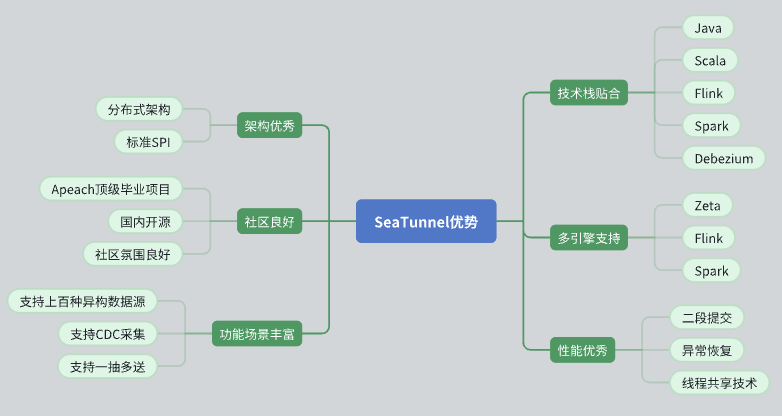
Erinomainen arkkitehtoninen suunnittelu
SeaTunnelilla on hajautettu arkkitehtuuri, joka toimii hyvin tarpeisiimme.
Sen API-suunnittelu on standardoitu ja ottaa käyttöön SPI (Service Provider Interface) -tilan laajentamisen ja integroinnin helpottamiseksi.
Aktiivinen yhteisön tuki
SeaTunnel on huipputason Apache-projekti, jossa on hyvä yhteisöllinen ilmapiiri. Aktiiviset kehittäjät ja käyttäjäryhmät tukevat vahvasti ongelmanratkaisua ja toimintojen laajentamista.
Kotimaisten avoimen lähdekoodin projektien tausta tekee viestinnästämme ja yhteistyöstämme sujuvampaa.
Runsas toiminnallisuus ja tietolähteiden tuki
SeaTunnel tukee useita tietolähteitä ja sisältää monipuoliset toiminnot erilaisiin tietojenkäsittelytarpeisiimme.
Tukee CDC:tä (Change Data Capture), mikä mahdollistaa reaaliaikaisen tietojen synkronoinnin ja käsittelyn.
Tukee yksi-moneen tiedonsiirtotilaa, mikä parantaa tiedonsiirron joustavuutta.
Tekniikkapinon istuvuus
SeaTunnel on yhteensopiva Javan kanssa ja tukee Flinkiä ja Sparkia, minkä ansiosta voimme integroida ja soveltaa sitä saumattomasti olemassa olevaan teknologiapinoon.
Käyttämällä Debeziumia CDC-tietojen talteenottoon, tekniikka on kypsä ja vakaa.
Usean moottorin tuki
SeaTunnel tukee useita laskentamoottoreita, mukaan lukien Zeta, Flink ja Spark, ja voi valita sopivimman moottorin laskentaan erityistarpeiden mukaan.
Tämä on erittäin tärkeää, koska sen avulla voimme valita optimaalisen laskentatavan eri skenaarioissa, mikä parantaa järjestelmän joustavuutta ja tehokkuutta.
Erinomainen suoritus
SeaTunnel on suunnitellut suorituskyvyn optimointimekanismeja, kuten kaksivaiheisen vahvistuksen, vikasietoisuuden palautuksen ja säikeiden jakamisen varmistaakseen tehokkaan ja vakaan tietojenkäsittelyn.
Ongelmat ratkaistu SeaTunnelin käyttöönoton jälkeen
SeaTunnel ratkaisee aiemmin mainitsemamme kaksi pääongelmaa:
Hajautettu aikataulu
DataX voi toimia vain yhdessä koneessa, ja meidän on otettava käyttöön lisää hajautettuja ajoitustoimintoja. SeaTunnel tukee luonnostaan hajautettua arkkitehtuuria riippumatta siitä, käytetäänkö Zetaa, Flinkiä tai Sparkia laskentamoottorina, se voi helposti toteuttaa hajautetun tiedonkäsittelyn, mikä yksinkertaistaa huomattavasti työtämme.
Teknologiapinon integrointi
Olemme aiemmin käyttäneet erilaisia teknologiapinoja, mukaan lukien DataX, Spark, Flink CDC jne., mikä teki T&K-kustannuksista korkeita ja järjestelmästä monimutkaisen. Kapseloimalla nämä teknologiapinot yhtenäisesti SeaTunnel tarjoaa integroidun alustan, joka tukee sekä ELT- että ETL-prosesseja, mikä yksinkertaistaa huomattavasti järjestelmäarkkitehtuuria ja vähentää kehitys- ja ylläpitokustannuksia.
Kuinka integroida SeaTunnel
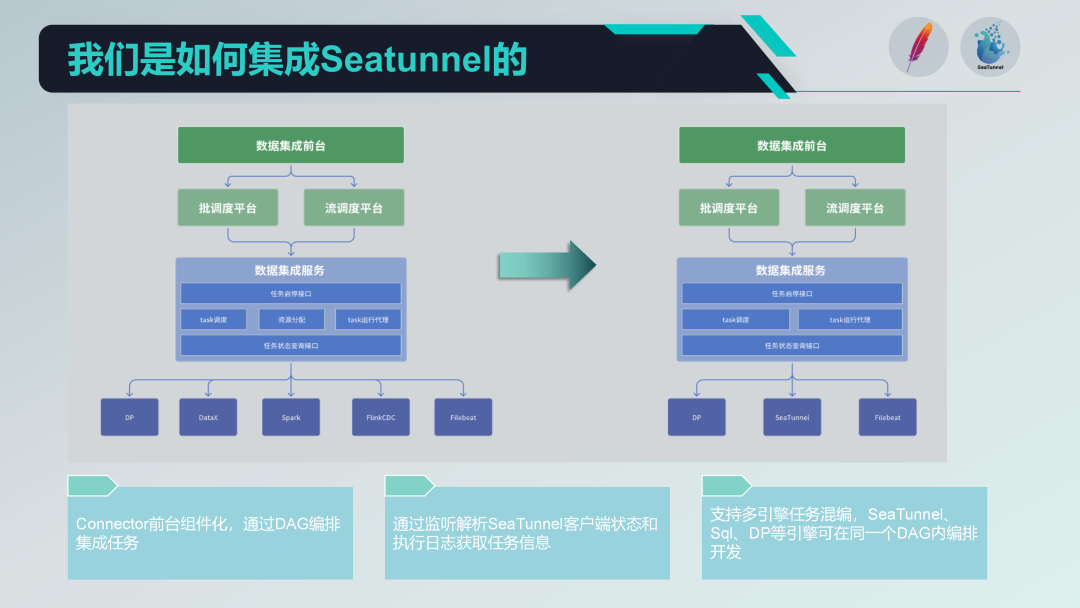
Ennen SeaTunnelin integrointia vanha arkkitehtuurimme oli olemassa ja toiminut jo jonkin aikaa. Se oli jaettu kolmeen kerrokseen: vastaanotto, aikataulutusalusta ja dataintegraatiopalvelu. Vastaanotto vastaa tehtävien hallinnasta ja kehittämisestä, ajoitusalusta vastaa tehtävien ajoituksesta ja riippuvuuksien hallinnasta, ja tiedon integrointipalvelu on ydinosa kaikkien dataintegrointitehtävien suorittamisessa ja hallinnassa.
Seuraava on uusi arkkitehtuurimme SeaTunnelin integroinnin jälkeen.
Ensin poistimme resurssien allokoinnin osan vanhasta DataX-arkkitehtuurista. Koska SeaTunnel itse tukee hajautettua arkkitehtuuria, ylimääräistä resurssien allokoinnin hallintaa ei enää tarvita. Tämä säätö yksinkertaistaa arkkitehtuuriamme huomattavasti.
Tekniikkapinon vaihto
Vaihdoimme vähitellen vanhan teknologiapinon SeaTunnelilla. Tarkat vaiheet ovat seuraavat:
Eräkäsittelytehtävien korvaaminen: Vaihdoimme ensin vanhan arkkitehtuurin osan, joka käytti DataX:ää ja Sparkia eräkäsittelyyn ETL:ään.
Vaihda virrankäsittelytehtävä: Seuraavaksi vaihdamme osan asteittain käyttämällä Flink CDC:tä streamin käsittelyyn. Ottamalla tämän vaiheittaisen lähestymistavan voimme varmistaa, että järjestelmä pysyy vakaana koko asteittaisen siirtymän ajan.
Komponentoitu SeaTunnel-liitin
Teimme SeaTunnelin liittimeen perustuvan komponenttipohjaisen suunnittelun ja suoritimme konfiguroinnin ja DAG-orkesteroinnin etupään lomakkeiden avulla. Vaikka myös SeaTunnel Web tekee vastaavaa työtä, olemme räätälöineet kehitystä omien tarpeidemme mukaan integroitumaan paremmin olemassa oleviin järjestelmiin.
tehtävän suorittava agentti
Tehtäväagenttien osalta lähetämme tehtäviä SeaTunnel-asiakkaan kautta ja seuraamme SeaTunnel-asiakkaan tilaa ja suorituslokeja. Jäsentämällä näitä lokeja voimme saada tehtävien suorittamisen tilatiedot ja varmistaa tehtävien suorittamisen seurattavuuden ja jäljitettävyyden.
Monimoottorinen hybridikehitys
Tuemme monimoottorista hybridikehitystä ja voimme suorittaa monimoottorisen DAG-orkesteroinnin etusivun aikataulutehtävässä. Näin voimme käyttää eri moottoreita (kuten SQL-moottoria ja DP-moottoria) yhdessä aikataulutehtävässä samanaikaisesti tehtävien kehittämiseen, mikä parantaa järjestelmän joustavuutta ja skaalautuvuutta.
SeaTunnelin integroinnin aikana havaitut ongelmat
SeaTunnelin integroinnissa törmäsimme ongelmiin. Seuraavassa on useita edustavia ongelmia ja niiden ratkaisuja:
Kysymys 1: Virheiden käsittely
SeaTunnelin käytön aikana törmäsimme virheraportteihin, jotka liittyivät viitekehyksen koodiin. Koska virallisissa asiakirjoissa ei ole asiaankuuluvia ohjeita, liittyimme yhteisön WeChat-ryhmään ja pyysimme ryhmän kehittäjiltä apua ja ratkaisimme ongelman ajoissa.
Kysymys 2: Tehtävän katkaisu
Vanhat keräystehtävämme toteutettiin DataX:llä. Kun korvaamme niitä SeaTunnelilla, meidän on otettava huomioon tehtävien leikkaamiseen liittyvät ongelmat.
Ratkaisemme sen seuraavilla ratkaisuilla:
Komponenttisuunnittelu : Tiedonkeruutehtävämme keskitoimistossa on suunniteltu komponenttipohjaisesti, ja käyttöliittymäkomponenttien ja taustan suoritusmoottorin välillä on muunnoskerros. Käyttöliittymä määrittää lomakkeen ja taustaosa luo JSON-tiedoston, joka DataX:n on suoritettava muunnoskerroksen kautta.
Samanlainen JSON-tiedostojen luominen : SeaTunnelin kokoonpano on samanlainen kuin DataX:n käyttöliittymä määritetään myös lomakkeen kautta, ja JSON-tiedosto, joka SeaTunnelin on suoritettava, luodaan taustajärjestelmässä. Näin voimme siirtää vanhat tehtävät saumattomasti uudelle SeaTunnel-alustalle varmistaen tehtävien sujuvan siirtymisen.
SQL-skriptin muuntaminen : Kirjoita SQL-skriptejä vanhojen DataX-tehtävien puhdistamiseksi ja muuntamiseksi, jotta ne voivat mukautua SeaTunneliin. Tämä menetelmä on joustavampi ja mukautuvampi, koska SeaTunnelia päivitetään usein, eikä suoraan koodauksen kirjoittaminen yhteensopivuuden varmistamiseksi ole pitkän aikavälin ratkaisu. Komentosarjojen muuntamisen avulla tehtäviä voidaan siirtää tehokkaammin mukautumaan SeaTunnelin päivityksiin.
Kysymys 3: Versionhallinta
Kohtasimme versionhallintaongelmia käyttäessämme SeaTunnelia. SeaTunnelia päivitetään usein, ja tiimimme on jatkuvasti seurattava uusinta versiota toista versiota varten. Tässä on ratkaisumme:
Paikallinen haaratoimisto : Otimme SeaTunnelin versioon 2.3.2 perustuvan paikallisen haaran ja teimme sille toissijaisen kehitystyön, mukaan lukien henkilökohtaisten vaatimusten ja väliaikaisten virheenkorjausten korjaamisen. Minimoidaksemme paikallisesti ylläpidetyn koodin määrän säilytämme vain tarpeelliset muutokset ja yritämme käyttää yhteisön uusinta versiota muihin osiin.
Säännöllisesti sisällytetyt yhteisöpäivitykset : Yhdistämme säännöllisesti uusia versioita yhteisöstä paikalliseen haaraan erityisesti päivittääksemme ja tehdäksemme niistä yhteensopivia muuttamiemme osien kanssa. Vaikka tämä menetelmä on kömpelö, se varmistaa, että pysymme ajan tasalla yhteisön uusimpien ominaisuuksien ja korjausten kanssa.
Anna takaisin yhteisölle : Voidaksemme hallita ja ylläpitää koodia paremmin, aiomme lähettää joitakin muutoksiamme ja henkilökohtaisia vaatimuksiamme yhteisölle pyrkiäksemme yhteisön hyväksymiseen ja tukemiseen. Tämä ei ainoastaan vähennä paikallista kunnossapitotyötämme, vaan auttaa myös yhteisöä kehittymään yhdessä.
SeaTunnelin toissijainen kehitys ja harjoittelu
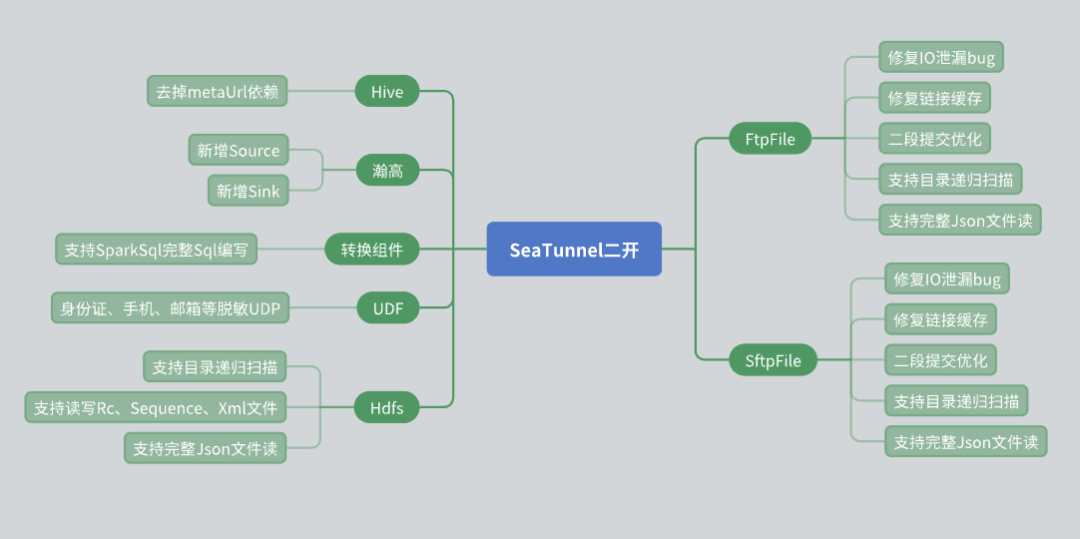
SeaTunnelin käytön aikana teimme useita toissijaisia kehitystarpeita todellisten liiketoiminnan tarpeiden perusteella, erityisesti liitintasolla. Seuraavat ovat ongelmat ja ratkaisut, joita kohtasimme toissijaisen kehityksen aikana.
Hive Connectorin uusiminen
Alkuperäinen SeaTunnel Hive Connector luottaa meta-URL-osoitteeseen metatietojen hankkimiseen. Varsinaisissa sovelluksissa monet kolmannen osapuolen käyttäjät eivät kuitenkaan pysty antamaan meta-URL-osoitteita tietoturvaongelmien vuoksi. Tämän tilanteen ratkaisemiseksi olemme tehneet seuraavat muutokset:
Käytä Hive Server 2:n JDBC-liitäntää saadaksesi taulukon metatietotiedot välttäen näin riippuvuuden meta-URL-osoitteesta.
Tällä tavoin voimme tarjota käyttäjille mahdollisuuden lukea ja kirjoittaa Hive-tietoja joustavammin ja samalla varmistaa tietoturvan.
Hangao-tietokannan tuki
Hangao-tietokanta on laajasti käytössä projekteissamme, joten olemme lisänneet tietolähteiden luku- ja kirjoitustuen Hangao-tietokantaan. Samaan aikaan olemme kehittäneet muunnoskomponentteja vastaamaan joitain Hangao-tietokannan erityistarpeita:
Tukee monimutkaisia muunnostoimintoja, kuten rivistä sarakkeeseen ja sarakkeesta riviin.
Kirjoitti erilaisia UDF-tiedostoja (käyttäjän määrittämiä toimintoja) tietojen herkkyyden poistamiseen ja muihin toimintoihin.
Tiedostoliittimen muokkaus
Tiedostojärjestelmäliittimellä on tärkeä rooli käytössämme, joten olemme tehneet siihen useita muutoksia:
HDFS-liitin: Lisätty hakemistorekursio- ja säännöllisten lausekkeiden skannaustoiminto, samalla kun se tukee useiden tiedostomuotojen (kuten RC, Sequence, XML, JSON) lukemista ja kirjoittamista.
FTP- ja SFTP-liittimet: Korjattu I/O-vuotovirhe ja optimoitu yhteyden välimuistimekanismi varmistaakseen riippumattomuuden eri tilien välillä, joilla on sama IP.
Kaksivaiheisen toimitusmekanismin optimointi
SeaTunnelin käytön aikana ymmärrämme syvällisesti sen kaksivaiheisen lähetysmekanismin tietojen johdonmukaisuuden varmistamiseksi. Seuraavat ovat ongelmat ja ratkaisut, joita kohtasimme tämän prosessin aikana:
Ongelman kuvaus : Kun tiedostojen kirjoittamiseen käytetään FTP:tä ja SFTP:tä, virhesanoma ilmaisee, että kirjoitusoikeutta ei ole. Tutkimuksessa havaittiin, että tietojen johdonmukaisuuden varmistamiseksi SeaTunnel kirjoittaa tiedoston ensin väliaikaiseen hakemistoon ja siirtää sen sitten.
Kirjoitus kuitenkin epäonnistui väliaikaisen hakemiston eri tilien käyttöoikeusasetusten vuoksi.
ratkaisu : Kun luot väliaikaista hakemistoa, aseta suuremmat käyttöoikeudet (kuten 777) varmistaaksesi, että kaikilla tileillä on kirjoitusoikeus. Samalla se ratkaisee tiedostojen välisestä siirrosta johtuvan uudelleennimeämiskomennon epäonnistumisen Luomalla väliaikaisen hakemiston saman tiedostojärjestelmän alle, vältetään tiedostojen väliset toiminnot.
Toissijainen kehitysjohtaminen
Toissijaisen kehitysprosessin aikana kohtasimme ongelman, kuinka hallita ja synkronoida SeaTunnelin uutta versiota. Ratkaisumme on seuraava:
Paikallinen haaratoimisto: veti paikallisen haaran SeaTunnel 2.3.2 -version perusteella
Säännöllisesti sisällytetyt yhteisöpäivitykset: Yhdistä säännöllisesti uusia yhteisön versioita paikallisiin sivukonttoreihin varmistaaksemme, että saamme uusia ominaisuuksia ja korjauksia yhteisöltä ajoissa.
Anna takaisin yhteisölle: Aiomme toimittaa osan muutoksistamme ja henkilökohtaisista vaatimuksistamme yhteisölle saadaksemme yhteisön hyväksynnän ja tuen, mikä vähentää paikallisen ylläpidon työtaakkaa.
SeaTunnel-integraatio ja sovellukset
SeaTunnelin integrointiprosessissa keskitymme pääasiassa seuraaviin kohtiin:
Resurssien allokoinnin optimointi: SeaTunnelin hajautetun arkkitehtuurin hyödyntäminen yksinkertaistaa resurssien allokointiongelmaa eikä enää vaadi hajautettuja aikataulutustoimintoja.
Teknologiapinon integrointi: Integroi eri teknologiapinojen, kuten DataX, Spark ja FlinkCDC, toiminnot SeaTunneliin ja kapseloi ne yhtenäisesti saavuttaaksesi ETL:n ja ELT:n integroinnin.
Yllä olevien vaiheiden ja strategioiden avulla integroimme SeaTunnelin onnistuneesti tietointegrointipalveluumme, ratkaisimme joitakin vanhan järjestelmän keskeisiä ongelmia ja optimoimme järjestelmän suorituskyvyn ja vakauden.
Tämän prosessin aikana osallistumme aktiivisesti yhteisön toimintaan, etsimme apua ja annamme palautetta ongelmissa varmistaaksemme integraatiotyön sujuvan etenemisen. Tämä myönteinen vuorovaikutus ei ainoastaan nosta teknistä tasoamme, vaan edistää myös SeaTunnel-yhteisön kehitystä.
Kokemusta avoimen lähdekoodin yhteisöön osallistumisesta
Osallistuessani SeaTunneliin minulla on seuraavat kokemukset:
Aika on oikea : Valitsimme tämän projektin SeaTunnelin nopean kehitysvaiheen aikana, ja ajoitus oli erittäin hyvä. SeaTunnelin kehitys antaa meille paljon luottamusta siihen, että paljon voidaan tehdä.
henkilökohtaiset tavoitteet: Asetin tavoitteeksi osallistua avoimen lähdekoodin yhteisöön tämän vuoden alussa ja panin sen aktiivisesti toimeen.
yhteisöystävällisyys : SeaTunnel-yhteisö on erittäin ystävällinen, kaikki kommunikoivat sujuvasti ja auttavat toisiaan. Tämä myönteinen ilmapiiri tekee minulle erittäin arvokasta olla osa sitä.
Niille teistä, jotka ovat aina halunneet osallistua avoimen lähdekoodin yhteisöön, mutta eivät ole vielä ottaneet ensimmäistä askelta, haluan rohkaista teitä ottamaan harppauksen. Kaikkein tärkeintä yhteisössä ovat sen ihmiset Niin kauan kuin liityt, olet välttämätön osa yhteisöä.
Odotukset SeaTunnelille
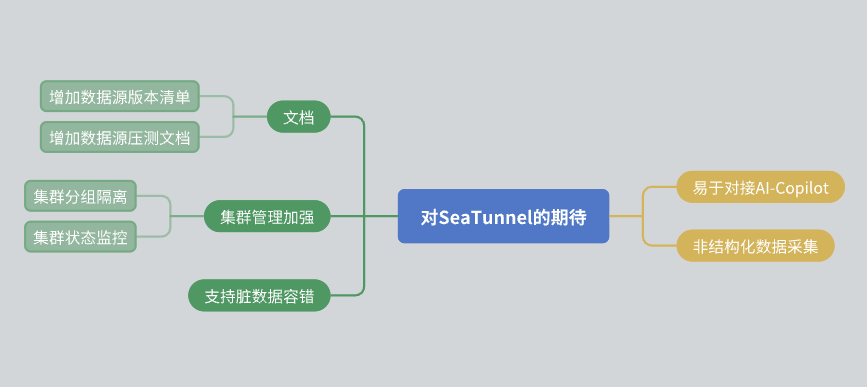
Lopuksi haluaisin jakaa joitain odotuksia SeaTunnelista:
Parannuksia dokumentaatioon: Toivon, että yhteisö voi parantaa dokumentaatiota, mukaan lukien tietolähteiden versioluetteloa ja stressitestiraportteja.
Klusterin hallinta: Toivotaan, että SeaTunnel pystyy saavuttamaan resurssieristyksen klusterin sisällä ja tarjoamaan monipuolisempia klusterin tilan seurantatietoja.
Tietojen vikasietoisuus: Vaikka SeaTunnelilla on jo vikasietoinen mekanismi, toivomme, että sitä voidaan optimoida edelleen tulevaisuudessa.
AI integraatio: Toivon, että SeaTunnel pystyy tarjoamaan lisää käyttöliittymiä tekoälyavusteisen käytön helpottamiseksi.
Kiitos jokaiselle SeaTunnel-yhteisön jäsenelle kovasta työstänne. Siinä kaikki jakamani, kiitos kaikille!