Condivisione pratica di AsiaInfo Technology su Apache SeaTunnel
Autointroduzione
Ciao compagni studenti, sono onorato di condividere e comunicare con voi attraverso la comunità Apache SeaTunnel. Sono Pan Zhihong di AsiaInfo Technology e sono principalmente responsabile dello sviluppo dei prodotti per data center interni dell'azienda.
L'argomento di questa condivisione è la pratica di integrazione di Apache SeaTunnel in AsiaInfo Technology. Nello specifico, parleremo di come il nostro data center integra SeaTunnel.
Condividi la panoramica dei contenuti
In questa condivisione mi concentrerò sui seguenti aspetti:
Perché scegliere SeaTunnel
Come integrare SeaTunnel
Problemi riscontrati durante l'integrazione di SeaTunnel
Sviluppo secondario di SeaTunnel
Aspettative per SeaTunnel
Perché scegliere SeaTunnel
Prima di tutto, lasciatemi introdurre che sono principalmente responsabile dello sviluppo iterativo del prodotto per data center DATAOS di AsiaInfo. DATAOS è un prodotto per data center relativamente standard, che copre moduli funzionali come integrazione dei dati, sviluppo dei dati, governance dei dati e apertura dei dati. La cosa principale relativa a SeaTunnel è il modulo di integrazione dei dati, che è principalmente responsabile dell'integrazione dei dati.
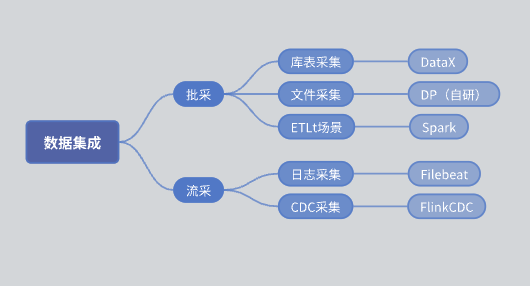
Prima dell'introduzione di SeaTunnel, l'architettura funzionale del nostro modulo di integrazione dati era la seguente:
acquisto in batch: Diviso in raccolta di tabelle della biblioteca e raccolta di file.
Raccolta di tabelle di libreria: implementata principalmente utilizzando DataX.
Raccolta file: motore DP autosviluppato.
Raccolta ETLt: motore di raccolta ETLt sviluppato autonomamente. DataX preferisce ELT (estrazione, caricamento, conversione), adatto per conversioni complesse dopo l'estrazione e l'archiviazione dei dati. Tuttavia, in alcuni scenari, è richiesto EL small T (estrazione, caricamento, conversione semplice) e DataX non è adatto. Pertanto, abbiamo sviluppato un motore basato su Spark SQL.
Liucai: la raccolta dei registri si basa principalmente su Filebeat e la raccolta CDC si basa principalmente su Flink CDC.
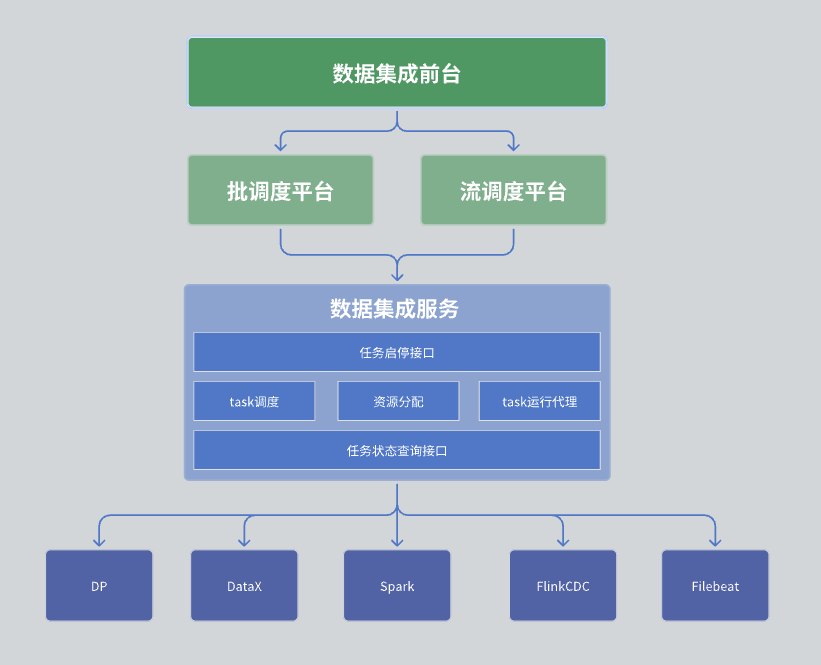
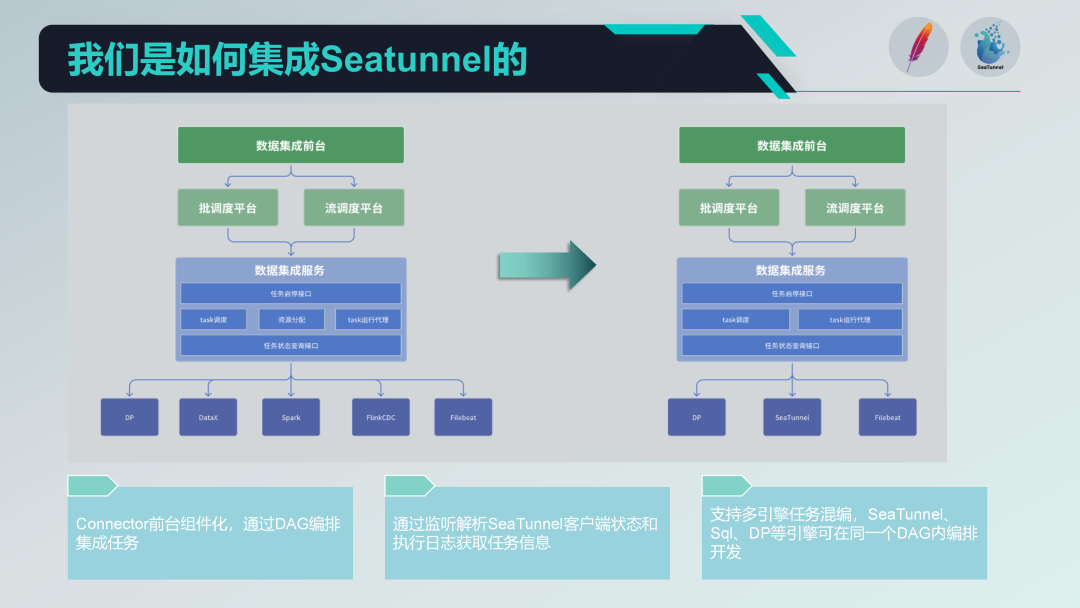
Nel nostro modulo di integrazione dei dati, l'architettura complessiva è divisa in tre livelli, ovvero front desk di integrazione dei dati, piattaforma di pianificazione e servizio di integrazione dei dati.
Di seguito è riportata una descrizione dettagliata di ciascun livello:
Il primo livello: front desk per l'integrazione dei dati
Il front desk di integrazione dei dati è principalmente responsabile della gestione delle attività di integrazione dei dati. Nello specifico, include lo sviluppo delle attività, lo sviluppo della pianificazione e il monitoraggio delle operazioni. Questi compiti combinano diversi operatori integrati attraverso DAG (Directed Acyclic Graph) per implementare processi complessi di elaborazione dei dati. L'interfaccia front-end fornisce un'intuitiva interfaccia di gestione delle attività, consentendo agli utenti di configurare e monitorare facilmente le attività di integrazione dei dati.
Secondo livello: piattaforma di pianificazione
La piattaforma di pianificazione è responsabile della pianificazione e della gestione delle operazioni delle attività. Supporta sia la modalità di elaborazione batch che quella di elaborazione stream e può richiamare attività corrispondenti in base alle dipendenze delle attività e alle strategie di pianificazione.
Il terzo livello: servizio di integrazione dati
Il servizio di integrazione dati è il cuore dell’intero servizio data center, che prevede una serie di funzioni chiave:
Interfaccia di gestione delle attività: Comprese funzioni come la creazione, l'eliminazione, l'aggiornamento e la query di attività.
Interfaccia di avvio e arresto delle attività: consente agli utenti di avviare o interrompere attività specifiche.
Interfaccia di query sullo stato dell'attività: interroga le informazioni sullo stato corrente dell'attività per facilitare il monitoraggio e la gestione.
Il servizio di integrazione dati è responsabile anche dell'esecuzione specifica dei compiti. Poiché la nostra attività di raccolta può includere più motori, ciò richiede il coordinamento e la pianificazione di più motori quando l'attività è in esecuzione.
Processo di esecuzione dell'attività
L'esecuzione dell'attività prevede principalmente i seguenti passaggi:
Pianificazione delle attività: In base alla strategia di pianificazione e alle dipendenze predeterminate, la piattaforma di pianificazione richiama le attività corrispondenti.
Esecuzione dell'attività: Durante l'esecuzione dell'attività, ciascun operatore viene eseguito in sequenza in base alla configurazione DAG dell'attività.
Coordinamento multimotore: per le attività che contengono più motori (come le attività ibride DataX e Spark), è necessario coordinare il funzionamento di ciascun motore durante il processo di esecuzione per garantire la corretta esecuzione dell'attività.
Assegnazione delle risorse
Allo stesso tempo, per consentire a DataX, un'attività autonoma, di funzionare meglio in modo distribuito e ottenere il riutilizzo delle risorse, abbiamo ottimizzato l'allocazione delle risorse per l'attività DataX:
Schedulazione distribuita: attraverso il meccanismo di allocazione delle risorse, le attività DataX vengono distribuite per essere eseguite su più nodi per evitare colli di bottiglia a punto singolo e migliorare il parallelismo delle attività e l'efficienza di esecuzione.
Riutilizzo delle risorse: Attraverso ragionevoli strategie di gestione e allocazione delle risorse, garantire un riutilizzo efficiente delle risorse per compiti diversi e ridurre gli sprechi di risorse.
agente in esecuzione dell'attività
Implementiamo agenti di esecuzione delle attività corrispondenti per ciascun motore di esecuzione per ottenere una gestione e un monitoraggio unificati delle attività:
agente del motore di esecuzione : Nel servizio di integrazione dati, l'agente gestisce diversi motori di esecuzione, come DataX, Spark, Flink CDC, ecc. L'agente è responsabile dell'avvio, dell'arresto e del monitoraggio dello stato delle attività.
interfaccia unificata: Fornisce un'interfaccia di gestione delle attività unificata in modo che le attività di diversi motori possano essere gestite attraverso la stessa interfaccia, semplificando il lavoro di funzionamento, manutenzione e gestione.
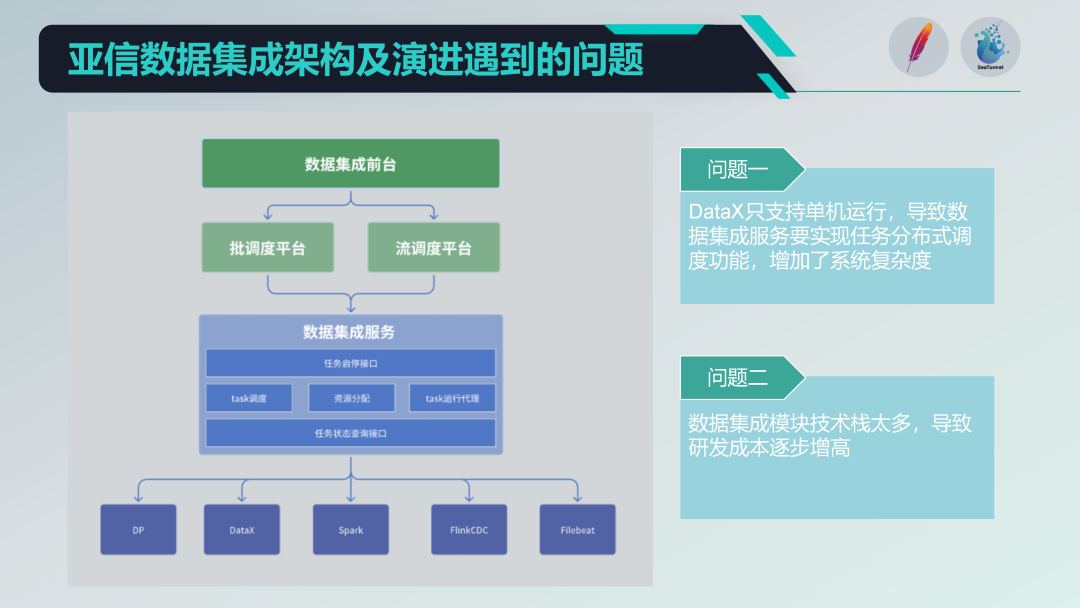
Alcuni problemi con la vecchia architettura di integrazione dei dati
Abbiamo integrato alcuni progetti open source, come DataX, Spark, Flink CDC, Filebeat, ecc., per formare una potente piattaforma di servizi di integrazione dei dati. Ma dobbiamo anche affrontare alcuni problemi:
Restrizioni per il funzionamento di una sola macchina: DataX supporta solo il funzionamento su una sola macchina, il che richiede l'implementazione di funzioni di pianificazione distribuita sulla base, il che aumenta la complessità del sistema.
Lo stack tecnologico è troppo diversificato: L'introduzione di più stack tecnologici (come Spark e Flink), sebbene ricchi di funzioni, comporta anche elevati costi di ricerca e sviluppo. Ogni volta che vengono sviluppate nuove funzioni, è necessario affrontare problemi di compatibilità e integrazione di più stack tecnologici.
Evoluzione dell'architettura
Per ottimizzare l'architettura e ridurre la complessità, abbiamo evoluto l'architettura esistente:
Integra funzionalità multi-motore: Dopo aver introdotto SeaTunnel, possiamo unificare le funzioni di più motori e ottenere più capacità di elaborazione dei dati su un'unica piattaforma.
Semplificare la gestione delle risorse: La funzione di gestione delle risorse di SeaTunnel semplifica la pianificazione distribuita di attività autonome come DataX e riduce la complessità dell'allocazione e della gestione delle risorse.
Ridurre i costi di ricerca e sviluppo: Attraverso l'architettura unificata e la progettazione dell'interfaccia, i costi di sviluppo e manutenzione causati da più stack tecnologici vengono ridotti e la scalabilità e la facilità di manutenzione del sistema vengono migliorate.
Attraverso l'ottimizzazione e l'evoluzione dell'architettura, abbiamo risolto con successo i problemi legati alle limitazioni operative di DataX su una singola macchina e agli elevati costi di ricerca e sviluppo causati da più stack tecnologici.
Dopo aver introdotto SeaTunnel, siamo stati in grado di implementare più funzioni di elaborazione dati su un'unica piattaforma, semplificando al tempo stesso la gestione delle risorse e la pianificazione delle attività e migliorando l'efficienza e la stabilità complessive del sistema.
Perché scegliere SeaTunnel?
Il nostro contatto con SeaTunnel può essere fatto risalire al periodo Waterdrop e abbiamo svolto molte pratiche applicative per Waterdrop.
L'anno scorso SeaTunnel ha lanciato il motore Zeta, ha supportato l'architettura distribuita ed è diventato un progetto Apache di alto livello. Ciò ci ha permesso di trovare un punto temporale adatto l'anno scorso, condurre ricerche approfondite e decidere di introdurre SeaTunnel.
Ecco alcuni dei motivi principali per cui abbiamo scelto SeaTunnel:
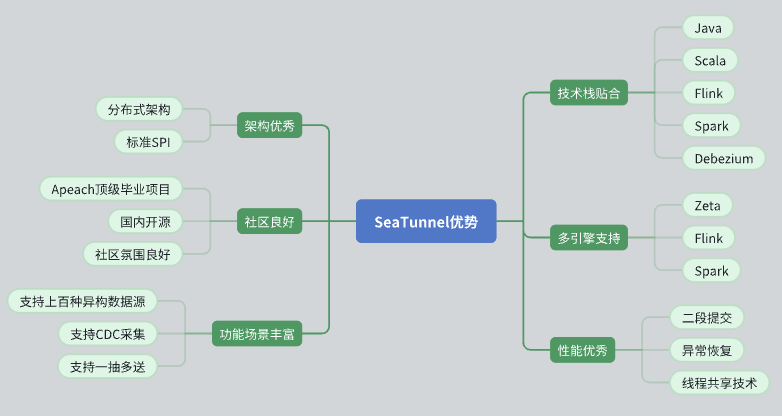
Ottimo disegno architettonico
SeaTunnel ha un'architettura distribuita che funziona bene per le nostre esigenze.
Il suo design API è standardizzato e adotta la modalità SPI (Service Provider Interface) per facilitare l'espansione e l'integrazione.
Supporto attivo della comunità
SeaTunnel è un progetto Apache di alto livello con una buona atmosfera comunitaria. Gli sviluppatori attivi e i gruppi di utenti forniscono un forte supporto per la risoluzione dei problemi e l'espansione delle funzioni.
Il background dei progetti open source nazionali rende la nostra comunicazione e collaborazione più fluida.
Funzionalità avanzate e supporto dell'origine dati
SeaTunnel supporta più origini dati e dispone di ricche funzioni per soddisfare le nostre diverse esigenze di elaborazione dei dati.
Supporta CDC (Change Data Capture), consentendo la sincronizzazione e l'elaborazione dei dati in tempo reale.
Supporta la modalità di trasmissione dati uno-a-molti, migliorando la flessibilità della trasmissione dati.
Adattamento dello stack tecnologico
SeaTunnel è compatibile con Java e supporta Flink e Spark, permettendoci di integrarlo e applicarlo perfettamente allo stack tecnologico esistente.
Utilizzando Debezium per l'acquisizione dei dati CDC, la tecnologia è matura e stabile.
Supporto multi-motore
SeaTunnel supporta una varietà di motori di calcolo, tra cui Zeta, Flink e Spark, e può selezionare il motore più adatto per il calcolo in base alle esigenze specifiche.
Questo è molto importante perché ci permette di scegliere la modalità di calcolo ottimale in diversi scenari, migliorando la flessibilità e l'efficienza del sistema.
Performance eccellente
SeaTunnel ha progettato meccanismi di ottimizzazione delle prestazioni come commit a due fasi, ripristino con tolleranza agli errori e condivisione dei thread per garantire un'elaborazione dei dati efficiente e stabile.
Problemi risolti dopo l'introduzione di SeaTunnel
SeaTunnel risolve i due problemi principali di cui abbiamo parlato prima:
Schedulazione distribuita
DataX può essere eseguito solo su una singola macchina ed è necessario implementare ulteriori funzioni di pianificazione distribuita. SeaTunnel supporta intrinsecamente l'architettura distribuita. Sia che utilizzi Zeta, Flink o Spark come motore di calcolo, può facilmente implementare l'elaborazione distribuita dei dati, semplificando notevolmente il nostro lavoro.
Integrazione dello stack tecnologico
In precedenza abbiamo utilizzato una varietà di stack tecnologici, tra cui DataX, Spark, Flink CDC, ecc., che rendevano elevati i costi di ricerca e sviluppo e complessi il sistema. Incapsulando in modo uniforme questi stack tecnologici, SeaTunnel fornisce una piattaforma integrata in grado di supportare sia i processi ELT che ETL, semplificando notevolmente l'architettura del sistema e riducendo i costi di sviluppo e manutenzione.
Come integrare SeaTunnel
Prima dell'integrazione di SeaTunnel, la nostra vecchia architettura esisteva ed era operativa da tempo. Era divisa in tre livelli: front desk, piattaforma di pianificazione e servizio di integrazione dei dati. Il front desk è responsabile della gestione e dello sviluppo delle attività, la piattaforma di pianificazione è responsabile della pianificazione delle attività e della gestione delle dipendenze e il servizio di integrazione dei dati è la parte principale dell'esecuzione e della gestione di tutte le attività di integrazione dei dati.
Quella che segue è la nostra nuova architettura dopo l'integrazione di SeaTunnel.
Innanzitutto, abbiamo eliminato la parte di allocazione delle risorse della vecchia architettura che coinvolgeva DataX. Poiché SeaTunnel stesso supporta l'architettura distribuita, non è più necessaria un'ulteriore gestione dell'allocazione delle risorse. Questa modifica semplifica notevolmente la nostra architettura.
Sostituzione dello stack tecnologico
Abbiamo gradualmente sostituito il vecchio stack tecnologico con SeaTunnel. I passaggi specifici sono i seguenti:
Sostituzione delle attività di elaborazione batch: abbiamo innanzitutto sostituito la parte della vecchia architettura che utilizzava DataX e Spark per l'elaborazione batch ETL.
Sostituisci l'attività di elaborazione del flusso: successivamente, sostituiremo gradualmente la parte utilizzando Flink CDC per l'elaborazione del flusso. Adottando questo approccio graduale, possiamo garantire che il sistema rimanga stabile durante tutta la transizione graduale.
Connettore SeaTunnel componibile
Abbiamo condotto una progettazione basata su componenti basata sul connettore SeaTunnel e abbiamo eseguito la configurazione e l'orchestrazione del DAG tramite moduli nel front-end. Sebbene anche SeaTunnel Web stia svolgendo un lavoro simile, abbiamo personalizzato lo sviluppo in base alle nostre esigenze per integrarlo meglio con i sistemi esistenti.
agente in esecuzione dell'attività
In termini di agenti che eseguono attività, inviamo attività tramite il client SeaTunnel e monitoriamo lo stato e i registri di esecuzione del client SeaTunnel. Analizzando questi registri, possiamo ottenere informazioni sullo stato di esecuzione delle attività e garantire il monitoraggio e la tracciabilità dell'esecuzione delle attività.
Sviluppo ibrido multimotore
Supportiamo lo sviluppo ibrido multi-motore e possiamo eseguire l'orchestrazione DAG multi-motore su un'attività di pianificazione nella prima pagina. In questo modo, possiamo utilizzare diversi motori (come il motore SQL e il motore DP) in un'attività di pianificazione contemporaneamente per lo sviluppo delle attività, migliorando la flessibilità e la scalabilità del sistema.
Problemi riscontrati durante l'integrazione di SeaTunnel
Nel processo di integrazione di SeaTunnel, abbiamo riscontrato alcuni problemi. Di seguito sono riportati diversi problemi rappresentativi e le relative soluzioni:
Domanda 1: gestione degli errori
Durante l'utilizzo di SeaTunnel, abbiamo riscontrato alcune segnalazioni di errori relative al codice del framework. Poiché non ci sono istruzioni pertinenti nei documenti ufficiali, ci siamo uniti al gruppo WeChat della community e abbiamo chiesto aiuto agli sviluppatori del gruppo e abbiamo risolto il problema in tempo.
Domanda 2: Ripartizione delle attività
Le nostre vecchie attività di raccolta sono state implementate utilizzando DataX Quando le sostituiamo con SeaTunnel, dobbiamo considerare i problemi di interruzione delle attività.
Lo risolviamo attraverso le seguenti soluzioni:
Progettazione di componenti : Le nostre attività di raccolta dati nel middle office sono progettate in modo basato sui componenti ed esiste un livello di conversione tra i componenti front-end e il motore di esecuzione back-end. Il frontend configura il modulo e il backend genera il file JSON che DataX deve eseguire attraverso il livello di conversione.
Generazione di file JSON simile : La configurazione di SeaTunnel è simile a quella di DataX. Anche il frontend viene configurato tramite un modulo e il file JSON che SeaTunnel deve eseguire viene generato nel backend. In questo modo, possiamo trasferire senza problemi le vecchie attività sulla nuova piattaforma SeaTunnel, garantendo una transizione graduale delle attività.
Conversione di script SQL : Scrivi script SQL per pulire e convertire le vecchie attività DataX in modo che possano adattarsi a SeaTunnel. Questo metodo è più flessibile e adattabile, poiché SeaTunnel verrà aggiornato frequentemente e scrivere direttamente l'hard coding per la compatibilità non è una soluzione a lungo termine. Attraverso la conversione degli script, le attività possono essere trasferite in modo più efficiente per adattarsi agli aggiornamenti SeaTunnel.
Domanda 3: gestione delle versioni
Abbiamo riscontrato problemi di gestione delle versioni durante l'utilizzo di SeaTunnel. SeaTunnel viene aggiornato frequentemente e il nostro team deve monitorare continuamente l'ultima versione per la seconda versione. Ecco la nostra soluzione:
Gestione filiale locale : Abbiamo creato un ramo locale basato su SeaTunnel versione 2.3.2 e condotto uno sviluppo secondario su di esso, inclusa la correzione di requisiti personalizzati e correzioni temporanee di bug. Per ridurre al minimo la quantità di codice gestito localmente, conserviamo solo le modifiche necessarie e proviamo a utilizzare la versione più recente della community per altre parti.
Aggiornamenti della community regolarmente incorporati : Uniamo regolarmente le nuove versioni della community al ramo locale, soprattutto per aggiornarle e renderle compatibili con le parti che abbiamo modificato. Sebbene questo metodo sia goffo, garantisce di rimanere aggiornati con le ultime funzionalità e correzioni della community.
Restituire alla comunità : Al fine di gestire e mantenere meglio il codice, prevediamo di presentare alla comunità alcune delle nostre modifiche e requisiti personalizzati per lottare per l'accettazione e il supporto della comunità. Ciò non solo aiuta a ridurre i nostri lavori di manutenzione locale, ma aiuta anche la comunità a svilupparsi insieme.
Sviluppo secondario e pratica di SeaTunnel
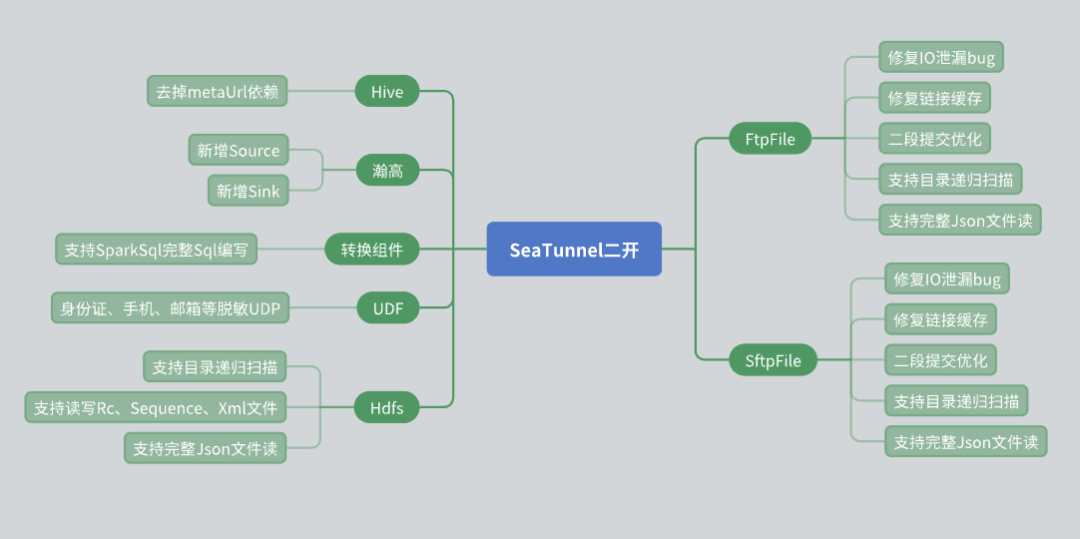
Durante l'utilizzo di SeaTunnel, abbiamo condotto una serie di sviluppi secondari basati sulle effettive esigenze aziendali, soprattutto a livello di connettore. Di seguito sono riportati i problemi e le soluzioni che abbiamo riscontrato durante lo sviluppo secondario.
Ristrutturazione del connettore Hive
Il SeaTunnel Hive Connector originale si basa sul Meta URL per ottenere i metadati. Tuttavia, nelle applicazioni reali, molti utenti di terze parti non sono in grado di fornire Meta URL a causa di problemi di sicurezza. Per far fronte a questa situazione, abbiamo apportato le seguenti modifiche:
Utilizza l'interfaccia JDBC di Hive Server 2 per ottenere le informazioni sui metadati della tabella, evitando così la dipendenza dal Meta URL.
In questo modo, possiamo fornire agli utenti la possibilità di leggere e scrivere i dati Hive in modo più flessibile, garantendo al tempo stesso la sicurezza dei dati.
Supporto del database Hangao
Il database Hangao è ampiamente utilizzato nei nostri progetti, quindi abbiamo aggiunto il supporto per la lettura e la scrittura dell'origine dati per il database Hangao. Allo stesso tempo, abbiamo sviluppato componenti di conversione per soddisfare alcune esigenze speciali del database Hangao:
Supporta operazioni di conversione complesse come riga in colonna e colonna in riga.
Ha scritto una varietà di UDF (funzioni definite dall'utente) per la desensibilizzazione dei dati e altre operazioni.
Modifica del connettore del file
Il connettore del file system svolge un ruolo importante nel nostro utilizzo, quindi gli abbiamo apportato diverse modifiche:
Connettore HDFS: aggiunta la funzione di ricorsione della directory e di scansione delle espressioni regolari dei file, supportando al contempo la lettura e la scrittura di più formati di file (come RC, Sequence, XML, JSON).
Connettori FTP e SFTP: Risolto il bug di perdita di I/O e ottimizzato il meccanismo di memorizzazione nella cache della connessione per garantire l'indipendenza tra diversi account con lo stesso IP.
Ottimizzazione del meccanismo di presentazione in due fasi
Nel processo di utilizzo di SeaTunnel, abbiamo una conoscenza approfondita del suo meccanismo di invio in due fasi per garantire la coerenza dei dati. Di seguito sono riportati i problemi e le soluzioni che abbiamo riscontrato durante questo processo:
Descrizione del problema : Quando si utilizzano FTP e SFTP per scrivere file, un messaggio di errore indica che non è disponibile il permesso di scrittura. Dall'indagine è emerso che, per garantire la coerenza dei dati, SeaTunnel prima scriverà il file nella directory temporanea e poi lo sposterà.
Tuttavia, la scrittura non è riuscita a causa delle impostazioni di autorizzazione di diversi account nella directory temporanea.
soluzione : quando crei una directory temporanea, imposta autorizzazioni maggiori (come 777) per garantire che tutti gli account abbiano il permesso di scrivere. Allo stesso tempo, risolve il problema dell'errore del comando di ridenominazione dovuto ai file system incrociati durante lo spostamento dei file. Creando una directory temporanea nello stesso file system, vengono evitate le operazioni tra file system.
Gestione dello sviluppo secondario
Durante il processo di sviluppo secondario, abbiamo affrontato il problema di come gestire e sincronizzare la nuova versione di SeaTunnel. La nostra soluzione è la seguente:
Gestione filiale locale: estratto un ramo locale basato sulla versione SeaTunnel 2.3.2
Aggiornamenti della community regolarmente incorporati: unisci regolarmente le nuove versioni della community nelle filiali locali per garantire di poter ricevere nuove funzionalità e correzioni dalla community in modo tempestivo.
Restituire alla comunità: Abbiamo intenzione di presentare alcune delle nostre modifiche e requisiti personalizzati alla comunità al fine di ottenere l'accettazione e il supporto della comunità, riducendo così il carico di lavoro della manutenzione locale.
Integrazione e applicazioni SeaTunnel
Nel processo di integrazione di SeaTunnel, ci concentriamo principalmente sui seguenti punti:
Ottimizzazione dell'allocazione delle risorse: L'utilizzo dell'architettura distribuita di SeaTunnel semplifica il problema dell'allocazione delle risorse e non richiede più ulteriori funzioni di pianificazione distribuita.
Integrazione dello stack tecnologico: Integra le funzioni di diversi stack tecnologici come DataX, Spark e FlinkCDC in SeaTunnel e incapsulali in modo uniforme per ottenere l'integrazione di ETL ed ELT.
Attraverso i passaggi e le strategie sopra indicati, abbiamo integrato con successo SeaTunnel nel nostro servizio di integrazione dati, risolto alcuni problemi chiave del vecchio sistema e ottimizzato le prestazioni e la stabilità del sistema.
Durante questo processo, partecipiamo attivamente alla comunità, cerchiamo aiuto e forniamo feedback sulle questioni per garantire il regolare svolgimento del lavoro di integrazione. Questa interazione positiva non solo migliora il nostro livello tecnico, ma promuove anche lo sviluppo della comunità SeaTunnel.
Esperienza nella partecipazione alla comunità open source
Nel processo di partecipazione a SeaTunnel, ho le seguenti esperienze:
È il momento giusto : Abbiamo scelto questo progetto durante la fase di rapido sviluppo di SeaTunnel e i tempi sono stati ottimi. Lo sviluppo di SeaTunnel ci dà molta fiducia che ci sia molto da fare.
obiettivi personali: Mi sono posto l'obiettivo di partecipare alla comunità open source all'inizio di quest'anno e di metterlo attivamente in atto.
cordialità della comunità : La community di SeaTunnel è molto amichevole, tutti comunicano senza problemi e si aiutano a vicenda. Questa atmosfera positiva rende molto utile per me farne parte.
Per quelli di voi che hanno sempre desiderato partecipare alla comunità open source ma non hanno ancora fatto il primo passo, voglio incoraggiarvi a fare il salto. La cosa più importante di una comunità sono le sue persone. Finché ti unisci, sei una parte indispensabile della comunità.
Aspettative per SeaTunnel
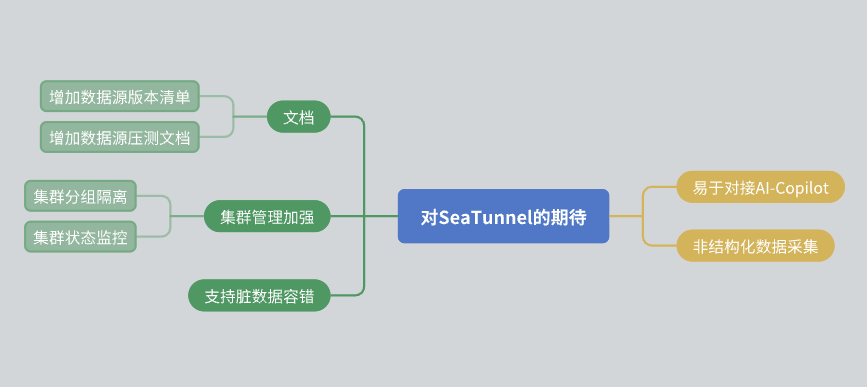
Infine, vorrei condividere alcune aspettative per SeaTunnel:
Miglioramenti alla documentazione: Spero che la community possa migliorare ulteriormente la documentazione, incluso l'elenco delle versioni delle origini dati e i rapporti sugli stress test.
Gestione dei cluster: Si spera che SeaTunnel possa ottenere l'isolamento delle risorse all'interno del cluster e fornire informazioni più complete sul monitoraggio dello stato del cluster.
Tolleranza agli errori dei dati: Sebbene SeaTunnel disponga già di un meccanismo di tolleranza agli errori, speriamo che possa essere ulteriormente ottimizzato in futuro.
Integrazione dell'intelligenza artificiale: Spero che SeaTunnel possa fornire più interfacce per facilitare l'accesso assistito dall'intelligenza artificiale.
Grazie a tutti i membri della comunità SeaTunnel per il vostro duro lavoro. Questo è tutto ciò che condivido, grazie a tutti!