Partage pratique d'AsiaInfo Technology sur Apache SeaTunnel
Présentation personnelle
Bonjour chers étudiants, j'ai l'honneur de partager et de communiquer avec vous via la communauté Apache SeaTunnel. Je m'appelle Pan Zhihong d'AsiaInfo Technology. Je suis principalement responsable du développement des produits de centre de données internes de l'entreprise.
Le sujet de ce partage est la pratique d'intégration d'Apache SeaTunnel dans AsiaInfo Technology. Plus précisément, nous parlerons de la façon dont notre centre de données intègre SeaTunnel.
Partager un aperçu du contenu
Dans ce partage, je me concentrerai sur les aspects suivants :
Pourquoi choisir SeaTunnel
Comment intégrer SeaTunnel
Problèmes rencontrés lors de l'intégration de SeaTunnel
Développement secondaire de SeaTunnel
Attentes pour SeaTunnel
Pourquoi choisir SeaTunnel
Tout d'abord, permettez-moi de vous présenter que je suis principalement responsable du développement itératif du produit de centre de données DATAOS d'AsiaInfo. DATAOS est un produit de centre de données relativement standard, couvrant des modules fonctionnels tels que l'intégration de données, le développement de données, la gouvernance des données et l'ouverture des données. L'élément principal lié à SeaTunnel est le module d'intégration de données, qui est principalement responsable de l'intégration des données.
Avant l'introduction de SeaTunnel, l'architecture fonctionnelle de notre module d'intégration de données était la suivante :
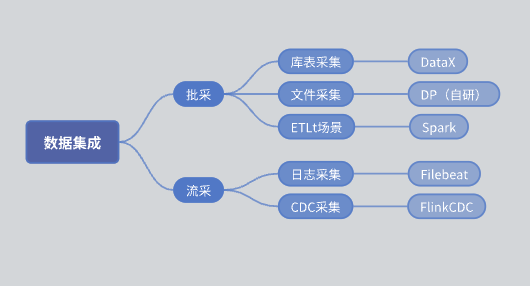
achat par lots: Divisé en collection de tables de bibliothèque et collection de fichiers.
Collection de tables de bibliothèque : principalement implémentée à l’aide de DataX.
Collection de fichiers : moteur DP auto-développé.
Collection ETLt : moteur de collecte ETLt auto-développé. DataX préfère ELT (extraction, chargement, conversion), qui convient à une conversion complexe après extraction et stockage de données. Cependant, dans certains scénarios, EL small T (extraction, chargement, conversion simple) est requis et DataX ne convient pas. Nous avons donc développé un moteur basé sur Spark SQL.
Liucai: La collecte de journaux est principalement basée sur Filebeat et la collecte CDC est principalement basée sur Flink CDC.
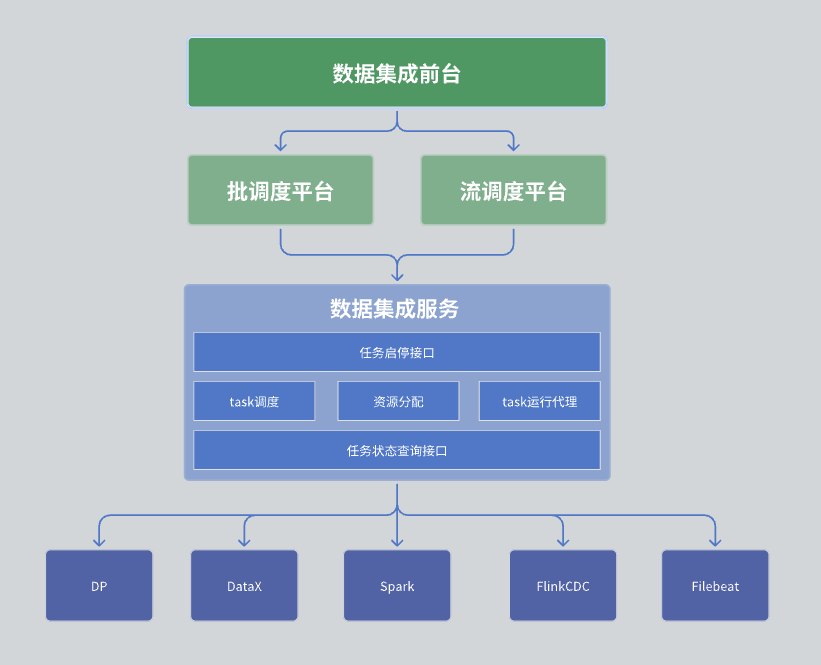
Dans notre module d'intégration de données, l'architecture globale est divisée en trois couches, à savoir la réception d'intégration de données, la plateforme de planification et le service d'intégration de données.
Vous trouverez ci-dessous une description détaillée de chaque couche :
La première couche : la réception de l'intégration des données
La réception d'intégration de données est principalement responsable de la gestion des tâches d'intégration de données. Plus précisément, cela comprend le développement des tâches, l’élaboration des plannings et le suivi des opérations. Ces tâches combinent divers opérateurs intégrés via DAG (Directed Acyclic Graph) pour mettre en œuvre des processus de traitement de données complexes. L'interface frontale fournit une interface de gestion de tâches intuitive, permettant aux utilisateurs de configurer et de surveiller facilement les tâches d'intégration de données.
Deuxième couche : plateforme de planification
La plateforme de planification est responsable de la planification et de la gestion des opérations de tâches. Il prend en charge les modes de traitement par lots et de traitement par flux et peut extraire les tâches correspondantes en fonction des dépendances des tâches et des stratégies de planification.
La troisième couche : le service d'intégration de données
Le service d'intégration de données est au cœur de l'ensemble du service de centre de données, qui fournit une série de fonctions clés :
Interface de gestion des tâches: Y compris des fonctions telles que la création, la suppression, la mise à jour et la requête de tâches.
Interface de démarrage et d'arrêt des tâches: Permet aux utilisateurs de démarrer ou d'arrêter des tâches spécifiques.
Interface de requête sur l'état des tâches: interrogez les informations d'état actuel de la tâche pour faciliter la surveillance et la gestion.
Le service d'intégration de données est également responsable de l'exécution spécifique des tâches. Étant donné que notre tâche de collecte peut inclure plusieurs moteurs, cela nécessite une coordination et une planification multi-moteurs lorsque la tâche est en cours d'exécution.
Processus d'exécution de tâche
Le déroulement de la tâche comprend principalement les étapes suivantes :
Planification des tâches: Selon la stratégie de planification et les dépendances prédéterminées, la plateforme de planification extrait les tâches correspondantes.
Exécution des tâches: Lors de l'exécution de la tâche, chaque opérateur est exécuté en séquence selon la configuration DAG de la tâche.
Coordination multimoteur: Pour les tâches qui contiennent plusieurs moteurs (telles que les tâches hybrides DataX et Spark), il est nécessaire de coordonner le fonctionnement de chaque moteur pendant le processus d'exécution pour assurer le bon déroulement de la tâche.
Allocation des ressources
Dans le même temps, afin de permettre à DataX, une tâche autonome, de mieux fonctionner de manière distribuée et de réaliser une réutilisation des ressources, nous avons optimisé l'allocation des ressources pour la tâche DataX :
Planification distribuée: Grâce au mécanisme d'allocation des ressources, les tâches DataX sont distribuées pour s'exécuter sur plusieurs nœuds afin d'éviter les goulots d'étranglement en un seul point et d'améliorer le parallélisme des tâches et l'efficacité d'exécution.
Réutilisation des ressources: Grâce à des stratégies raisonnables de gestion et d'allocation des ressources, assurer une réutilisation efficace des ressources pour différentes tâches et réduire le gaspillage des ressources.
agent d'exécution de tâches
Nous implémentons des agents d'exécution de tâches correspondants pour chaque moteur d'exécution afin d'obtenir une gestion et un suivi unifiés des tâches :
agent du moteur d'exécution : Dans le service d'intégration de données, l'agent gère différents moteurs d'exécution, tels que DataX, Spark, Flink CDC, etc. L'agent est responsable du démarrage, de l'arrêt et de la surveillance de l'état des tâches.
interface unifiée: Fournit une interface de gestion des tâches unifiée afin que les tâches de différents moteurs puissent être gérées via la même interface, simplifiant ainsi les travaux d'exploitation, de maintenance et de gestion.
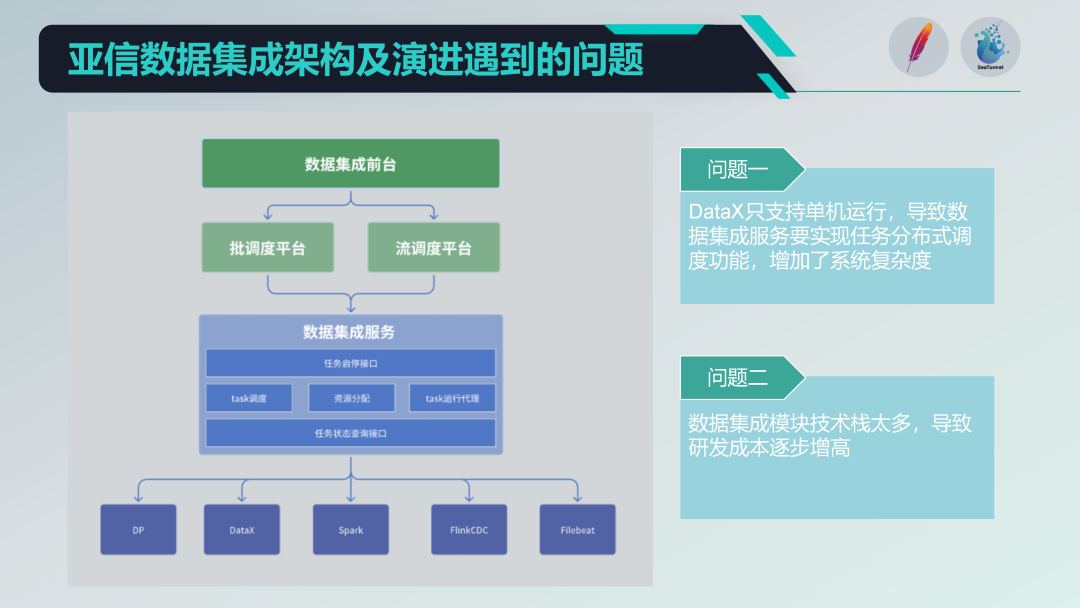
Quelques problèmes avec l'ancienne architecture d'intégration de données
Nous avons intégré certains projets open source, tels que DataX, Spark, Flink CDC, Filebeat, etc., pour former une puissante plateforme de services d'intégration de données. Mais nous sommes également confrontés à certains problèmes :
Restrictions de fonctionnement d'une seule machine: DataX ne prend en charge que le fonctionnement d'une seule machine, ce qui nous oblige à implémenter des fonctions de planification distribuée sur sa base, ce qui augmente la complexité du système.
La pile technologique est trop diversifiée: L'introduction de plusieurs piles technologiques (telles que Spark et Flink), bien que riches en fonctionnalités, entraîne également des coûts de recherche et de développement élevés. Chaque fois que de nouvelles fonctions sont développées, des problèmes de compatibilité et d'intégration de plusieurs piles technologiques doivent être résolus.
Évolution de l'architecture
Afin d'optimiser l'architecture et de réduire la complexité, nous avons fait évoluer l'architecture existante :
Intégrer des fonctionnalités multimoteurs: Après avoir introduit SeaTunnel, nous pouvons unifier les fonctions de plusieurs moteurs et obtenir plusieurs capacités de traitement de données sur une seule plate-forme.
Simplifiez la gestion des ressources: La fonction de gestion des ressources de SeaTunnel simplifie la planification distribuée de tâches autonomes telles que DataX et réduit la complexité de l'allocation et de la gestion des ressources.
Réduire les coûts de R&D: Grâce à une architecture unifiée et à une conception d'interface, les coûts de développement et de maintenance causés par plusieurs piles technologiques sont réduits, et l'évolutivité et la facilité de maintenance du système sont améliorées.
Grâce à l'optimisation et à l'évolution de l'architecture, nous avons résolu avec succès les problèmes de limitations de fonctionnement de DataX sur une seule machine et les coûts élevés de R&D causés par plusieurs piles technologiques.
Après avoir introduit SeaTunnel, nous avons pu implémenter plusieurs fonctions de traitement de données sur une seule plateforme, tout en simplifiant la gestion des ressources et la planification des tâches, et en améliorant l'efficacité et la stabilité globales du système.
Pourquoi choisir SeaTunnel ?
Notre contact avec SeaTunnel remonte à la période Waterdrop, et nous avons réalisé de nombreuses pratiques d'application pour Waterdrop.
L'année dernière, SeaTunnel a lancé le moteur Zeta, pris en charge l'architecture distribuée et est devenu un projet Apache de haut niveau. Cela nous a permis de trouver un moment approprié l'année dernière, de mener des recherches approfondies et de décider d'introduire SeaTunnel.
Voici quelques-unes des principales raisons pour lesquelles nous avons choisi SeaTunnel :
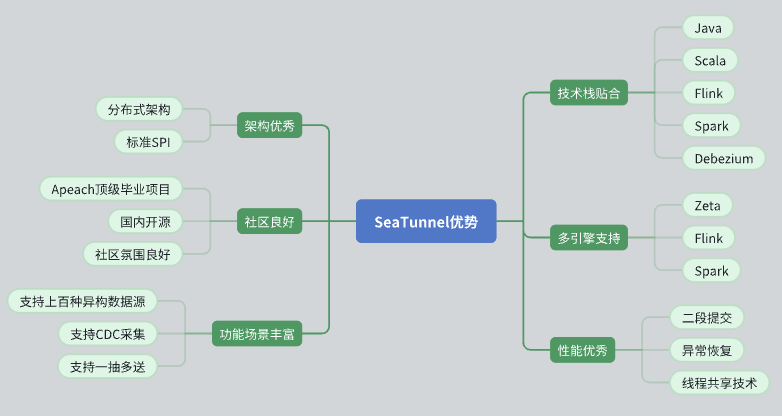
Excellente conception architecturale
SeaTunnel dispose d'une architecture distribuée qui répond bien à nos besoins.
Sa conception API est standardisée et adopte le mode SPI (Service Provider Interface) pour faciliter l'expansion et l'intégration.
Soutien communautaire actif
SeaTunnel est un projet Apache de haut niveau avec une bonne atmosphère communautaire. Les groupes de développeurs et d'utilisateurs actifs fournissent un soutien solide pour la résolution de problèmes et l'expansion des fonctions.
L’arrière-plan des projets open source nationaux rend notre communication et notre collaboration plus fluides.
Fonctionnalités riches et prise en charge des sources de données
SeaTunnel prend en charge plusieurs sources de données et dispose de fonctions riches pour répondre à nos divers besoins en matière de traitement de données.
Prend en charge CDC (Change Data Capture), permettant la synchronisation et le traitement des données en temps réel.
Prend en charge le mode de transmission de données un à plusieurs, améliorant la flexibilité de la transmission de données.
Ajustement de la pile technologique
SeaTunnel est compatible avec Java et prend en charge Flink et Spark, nous permettant de l'intégrer et de l'appliquer de manière transparente sur la pile technologique existante.
En utilisant Debezium pour la capture de données CDC, la technologie est mature et stable.
Prise en charge multimoteur
SeaTunnel prend en charge une variété de moteurs de calcul, notamment Zeta, Flink et Spark, et peut sélectionner le moteur de calcul le plus approprié en fonction de besoins spécifiques.
Ceci est très important car cela nous permet de choisir le mode de calcul optimal dans différents scénarios, améliorant ainsi la flexibilité et l'efficacité du système.
Performance excellente
SeaTunnel a conçu des mécanismes d'optimisation des performances tels que la validation en deux phases, la récupération avec tolérance aux pannes et le partage de threads pour garantir un traitement des données efficace et stable.
Problèmes résolus après l'introduction de SeaTunnel
SeaTunnel résout les deux principaux problèmes mentionnés précédemment :
Planification distribuée
DataX ne peut fonctionner que sur une seule machine et nous devons implémenter des fonctions de planification distribuée supplémentaires. SeaTunnel prend intrinsèquement en charge l'architecture distribuée. Qu'il utilise Zeta, Flink ou Spark comme moteur informatique, il peut facilement mettre en œuvre un traitement de données distribué, simplifiant considérablement notre travail.
Intégration de la pile technologique
Nous avions auparavant utilisé diverses piles technologiques, notamment DataX, Spark, Flink CDC, etc., ce qui rendait les coûts de R&D élevés et le système complexe. En encapsulant uniformément ces piles technologiques, SeaTunnel fournit une plate-forme intégrée qui peut prendre en charge les processus ELT et ETL, simplifiant considérablement l'architecture du système et réduisant les coûts de développement et de maintenance.
Comment intégrer SeaTunnel
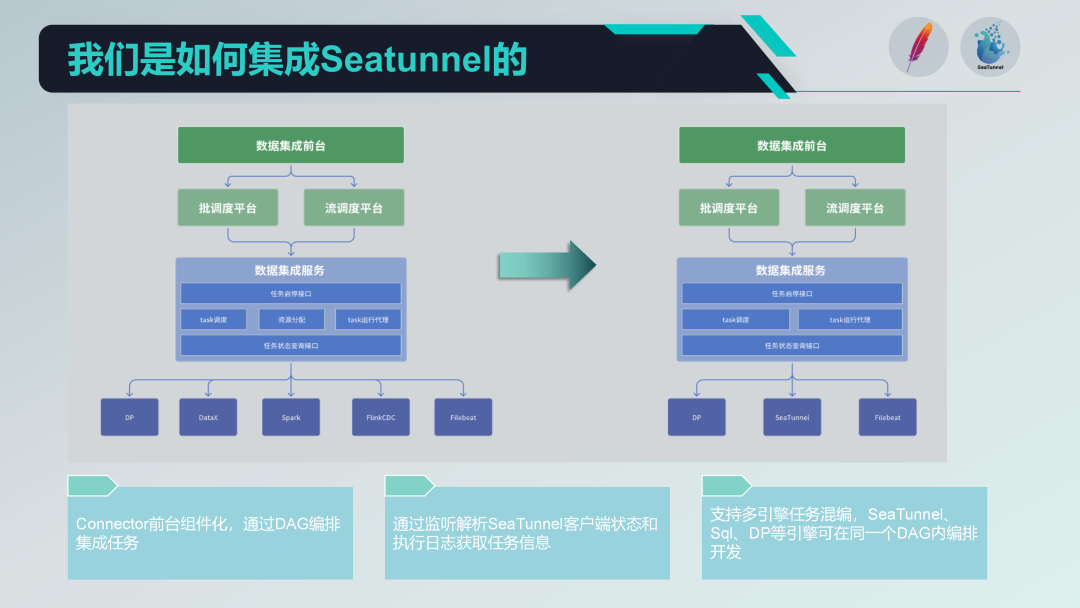
Avant d'intégrer SeaTunnel, notre ancienne architecture existait et fonctionnait depuis un certain temps. Elle était divisée en trois couches : réception, plateforme de planification et service d'intégration de données. La réception est responsable de la gestion et du développement des tâches, la plate-forme de planification est responsable de la planification des tâches et de la gestion des dépendances, et le service d'intégration de données est l'élément central de l'exécution et de la gestion de toutes les tâches d'intégration de données.
Voici notre nouvelle architecture après l'intégration de SeaTunnel.
Premièrement, nous avons éliminé la partie allocation des ressources de l’ancienne architecture impliquant DataX. Étant donné que SeaTunnel lui-même prend en charge l'architecture distribuée, une gestion supplémentaire de l'allocation des ressources n'est plus nécessaire. Cet ajustement simplifie grandement notre architecture.
Remplacement de la pile technologique
Nous avons progressivement remplacé l'ancienne pile technologique par SeaTunnel. Les étapes spécifiques sont les suivantes :
Remplacement des tâches de traitement par lots : Nous avons d'abord remplacé la partie de l'ancienne architecture qui utilisait DataX et Spark pour le traitement par lots ETL.
Remplacer la tâche de traitement de flux : Ensuite, nous remplacerons progressivement la partie utilisant Flink CDC pour le traitement de flux. En adoptant cette approche étape par étape, nous pouvons garantir que le système reste stable tout au long de la transition progressive.
Connecteur SeaTunnel composé de composants
Nous avons mené une conception basée sur des composants basée sur le connecteur de SeaTunnel et effectué la configuration et l'orchestration DAG via des formulaires au niveau du front-end. Bien que SeaTunnel Web effectue également un travail similaire, nous avons personnalisé le développement en fonction de nos propres besoins afin de mieux s'intégrer aux systèmes existants.
agent d'exécution de tâches
En termes d'agents d'exécution de tâches, nous soumettons des tâches via le client SeaTunnel et surveillons l'état et les journaux d'exécution du client SeaTunnel. En analysant ces journaux, nous pouvons obtenir des informations sur l'état d'exécution des tâches et garantir la surveillance et la traçabilité de l'exécution des tâches.
Développement hybride multimoteur
Nous prenons en charge le développement hybride multi-moteurs et pouvons effectuer une orchestration DAG multi-moteurs sur une tâche de planification sur la première page. De cette façon, nous pouvons utiliser différents moteurs (tels que le moteur SQL et le moteur DP) dans une même tâche de planification en même temps pour le développement des tâches, améliorant ainsi la flexibilité et l'évolutivité du système.
Problèmes rencontrés lors de l'intégration de SeaTunnel
Lors du processus d'intégration de SeaTunnel, nous avons rencontré quelques problèmes. Voici plusieurs problèmes représentatifs et leurs solutions :
Question 1 : Gestion des erreurs
Lors du processus d'utilisation de SeaTunnel, nous avons rencontré des rapports d'erreurs liés au code du framework. Comme il n'y a pas d'instructions pertinentes dans les documents officiels, nous avons rejoint le groupe communautaire WeChat et avons demandé de l'aide aux développeurs du groupe, et avons résolu le problème à temps.
Question 2 : basculement des tâches
Nos anciennes tâches de collecte ont été implémentées à l'aide de DataX. Lors de leur remplacement par SeaTunnel, nous devons prendre en compte les problèmes de transfert de tâches.
Nous le résolvons grâce aux solutions suivantes :
Conception des composants : Nos tâches de collecte de données au middle office sont conçues de manière basée sur des composants, et il existe une couche de conversion entre les composants front-end et le moteur d'exécution back-end. Le frontend configure le formulaire et le backend génère le fichier JSON que DataX doit exécuter via la couche de conversion.
Génération de fichiers JSON similaire : La configuration de SeaTunnel est similaire à celle de DataX. Le frontend est également configuré via un formulaire, et le fichier JSON que SeaTunnel doit exécuter est généré dans le backend. De cette manière, nous pouvons transférer en toute transparence les anciennes tâches vers la nouvelle plateforme SeaTunnel, garantissant ainsi une transition fluide des tâches.
Conversion de scripts SQL : Écrivez des scripts SQL pour nettoyer et convertir les anciennes tâches DataX afin qu'elles puissent s'adapter à SeaTunnel. Cette méthode est plus flexible et adaptable, car SeaTunnel sera mis à jour fréquemment et écrire directement du code en dur pour la compatibilité n'est pas une solution à long terme. Grâce à la conversion de scripts, les tâches peuvent être migrées plus efficacement pour s'adapter aux mises à jour de SeaTunnel.
Question 3 : Gestion des versions
Nous avons rencontré des problèmes de gestion de versions lors de l'utilisation de SeaTunnel. SeaTunnel est fréquemment mis à jour et notre équipe doit suivre en permanence la dernière version pour la deuxième version. Voici notre solution :
Gestion d'agence locale : Nous avons créé une branche locale basée sur SeaTunnel version 2.3.2 et y avons effectué un développement secondaire, notamment en corrigeant des exigences personnalisées et des corrections de bugs temporaires. Afin de minimiser la quantité de code maintenu localement, nous ne conservons que les modifications nécessaires et essayons d'utiliser la dernière version de la communauté pour les autres parties.
Mises à jour de la communauté régulièrement intégrées : Nous fusionnons régulièrement les nouvelles versions de la communauté dans la branche locale, notamment pour les mettre à jour et les rendre compatibles avec les parties que nous avons modifiées. Bien que cette méthode soit maladroite, elle garantit que nous restons à jour avec les dernières fonctionnalités et correctifs de la communauté.
Redonner à la communauté : Afin de mieux gérer et maintenir le code, nous prévoyons de soumettre certaines de nos modifications et exigences personnalisées à la communauté afin de lutter pour l'acceptation et le soutien de la communauté. Cela permet non seulement de réduire nos travaux d'entretien locaux, mais aide également la communauté à se développer ensemble.
Développement et pratique secondaires de SeaTunnel
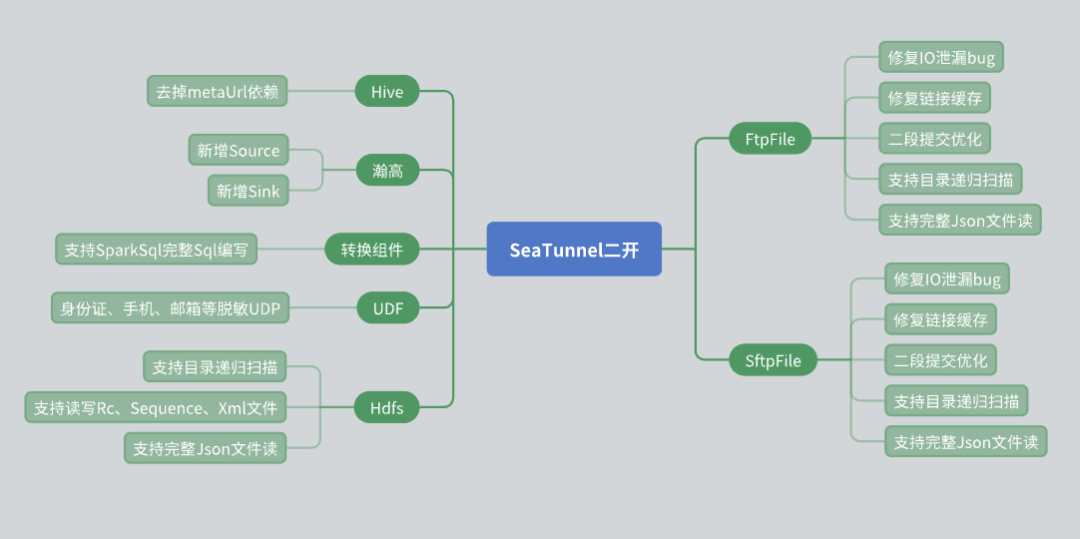
Lors de l'utilisation de SeaTunnel, nous avons réalisé un certain nombre de développements secondaires basés sur les besoins réels de l'entreprise, notamment au niveau des connecteurs. Voici les problèmes et les solutions que nous avons rencontrés lors du développement secondaire.
Rénovation du connecteur de la ruche
Le connecteur SeaTunnel Hive d'origine s'appuie sur l'URL méta pour obtenir des métadonnées. Cependant, dans les applications réelles, de nombreux utilisateurs tiers ne sont pas en mesure de fournir des méta-URL en raison de problèmes de sécurité. Afin de faire face à cette situation, nous avons apporté les modifications suivantes :
Utilisez l'interface JDBC de Hive Server 2 pour obtenir les informations de métadonnées de la table, évitant ainsi la dépendance à l'égard de l'URL méta.
De cette manière, nous pouvons offrir aux utilisateurs la possibilité de lire et d'écrire des données Hive de manière plus flexible tout en garantissant la sécurité des données.
Prise en charge de la base de données Hangao
La base de données Hangao est largement utilisée dans nos projets, nous avons donc ajouté la prise en charge de la lecture et de l'écriture des sources de données pour la base de données Hangao. Parallèlement, nous avons développé des composants de conversion pour répondre à certains besoins particuliers de la base de données Hangao :
Prend en charge les opérations de conversion complexes telles que ligne en colonne et colonne en ligne.
A écrit une variété d'UDF (fonctions définies par l'utilisateur) pour la désensibilisation des données et d'autres opérations.
Modification du connecteur de fichiers
Le connecteur du système de fichiers joue un rôle important dans notre utilisation, nous y avons donc apporté plusieurs modifications :
Connecteur HDFS: Ajout de la fonction de récursivité de répertoire et d'analyse des expressions régulières des fichiers, tout en prenant en charge la lecture et l'écriture de plusieurs formats de fichiers (tels que RC, Sequence, XML, JSON).
Connecteurs FTP et SFTP: Correction du bug de fuite d'E/S, et optimisation du mécanisme de mise en cache des connexions pour assurer l'indépendance entre les différents comptes avec la même IP.
Optimisation du mécanisme de soumission en deux étapes
Dans le processus d'utilisation de SeaTunnel, nous avons une compréhension approfondie de son mécanisme de soumission en deux étapes pour garantir la cohérence des données. Voici les problèmes et solutions que nous avons rencontrés au cours de ce processus :
Description du problème : Lors de l'utilisation de FTP et SFTP pour écrire des fichiers, un message d'erreur indique qu'il n'y a pas d'autorisation d'écriture. L'enquête a révélé que afin de garantir la cohérence des données, SeaTunnel écrira d'abord le fichier dans le répertoire temporaire, puis le déplacera.
Cependant, l'écriture a échoué en raison des paramètres d'autorisation de différents comptes sur le répertoire temporaire.
solution : lors de la création d'un répertoire temporaire, définissez des autorisations plus élevées (telles que 777) pour garantir que tous les comptes ont l'autorisation d'écrire. En même temps, cela résout le problème de l'échec de la commande de renommage dû à des systèmes de fichiers croisés lors du déplacement de fichiers. En créant un répertoire temporaire sous le même système de fichiers, les opérations entre systèmes de fichiers sont évitées.
Gestion du développement secondaire
Au cours du processus de développement secondaire, nous avons été confrontés au problème de savoir comment gérer et synchroniser la nouvelle version de SeaTunnel. Notre solution est la suivante :
Gestion d'agence locale: Extraction d'une branche locale basée sur la version SeaTunnel 2.3.2
Mises à jour de la communauté régulièrement intégrées: Fusionnez régulièrement les nouvelles versions de la communauté dans les branches locales pour garantir que nous pouvons obtenir de nouvelles fonctionnalités et correctifs de la communauté en temps opportun.
Redonner à la communauté: Nous prévoyons de soumettre certains de nos changements et exigences personnalisées à la communauté afin d'obtenir l'acceptation et le soutien de la communauté, réduisant ainsi la charge de travail de la maintenance locale.
Intégration et applications SeaTunnel
Dans le processus d'intégration de SeaTunnel, nous nous concentrons principalement sur les points suivants :
Optimisation de l'allocation des ressources: L'utilisation de l'architecture distribuée de SeaTunnel simplifie le problème d'allocation des ressources et ne nécessite plus de fonctions de planification distribuée supplémentaires.
Intégration de la pile technologique: Intégrez les fonctions de différentes piles technologiques telles que DataX, Spark et FlinkCDC dans SeaTunnel et encapsulez-les uniformément pour réaliser l'intégration d'ETL et d'ELT.
Grâce aux étapes et stratégies ci-dessus, nous avons intégré avec succès SeaTunnel dans notre service d'intégration de données, résolu certains problèmes clés de l'ancien système et optimisé les performances et la stabilité du système.
Au cours de ce processus, nous participons activement à la communauté, recherchons de l'aide et fournissons des commentaires sur les problèmes afin d'assurer le bon déroulement du travail d'intégration. Cette interaction positive améliore non seulement notre niveau technique, mais favorise également le développement de la communauté SeaTunnel.
Expérience de participation à la communauté open source
En train de participer à SeaTunnel, j'ai les expériences suivantes :
Le moment est venu : Nous avons choisi ce projet lors de la phase de développement rapide de SeaTunnel, et le timing était très bon. Le développement de SeaTunnel nous donne la certitude que beaucoup de choses peuvent être faites.
buts personnels: Je me suis fixé comme objectif de participer à la communauté open source au début de cette année et je l'ai activement mis en œuvre.
convivialité communautaire : La communauté SeaTunnel est très conviviale, tout le monde communique facilement et s'entraide. Cette atmosphère positive fait que cela vaut vraiment la peine pour moi d’en faire partie.
Pour ceux d'entre vous qui ont toujours voulu participer à la communauté open source mais qui n'ont pas encore fait le premier pas, je souhaite vous encourager à franchir le pas. La chose la plus importante dans une communauté, ce sont ses membres. Tant que vous en faites partie, vous êtes un élément indispensable de la communauté.
Attentes pour SeaTunnel
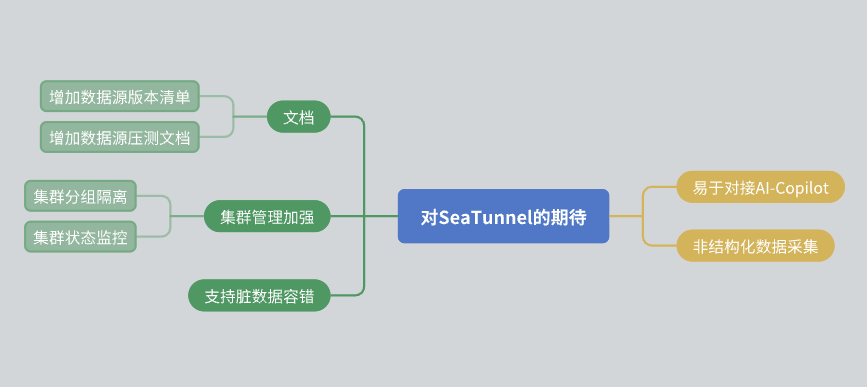
Enfin, je voudrais partager quelques attentes concernant SeaTunnel :
Améliorations de la documentation: J'espère que la communauté pourra améliorer encore la documentation, y compris la liste des versions des sources de données et les rapports de tests de résistance.
Gestion des clusters: On espère que SeaTunnel pourra parvenir à isoler les ressources au sein du cluster et fournir des informations de surveillance de l'état du cluster plus riches.
Tolérance aux pannes de données: Bien que SeaTunnel dispose déjà d'un mécanisme de tolérance aux pannes, nous espérons qu'il pourra être encore optimisé à l'avenir.
Intégration de l'IA: J'espère que SeaTunnel pourra fournir plus d'interfaces pour faciliter l'accès assisté par l'IA.
Merci à tous les membres de la communauté SeaTunnel pour votre travail acharné. C'est tout mon partage, merci à tous !