Hello everyone, I am honored to share and communicate with you through the Apache SeaTunnel community. I am Pan Zhihong from AsiaInfo Technologies, and I am mainly responsible for the development of the company's internal data center products.
The theme of this sharing is the integration practice of Apache SeaTunnel in AsiaInfo Technologies, specifically how our data middle platform integrates SeaTunnel.
Sharing content overview
In this sharing, I will focus on the following aspects:
Why choose SeaTunnel
How to integrate SeaTunnel
Problems encountered during SeaTunnel integration
Secondary development of SeaTunnel
Expectations for SeaTunnel
Why choose SeaTunnel
First of all, I am mainly responsible for the iterative development of AsiaInfo's data middle-end product DATAOS. DATAOS is a relatively standard data middle-end product, covering functional modules such as data integration, data development, data governance, and data openness. The main module related to SeaTunnel is the data integration module, which is mainly responsible for data integration.
Before the introduction of SeaTunnel, the functional architecture of our data integration module was as follows:
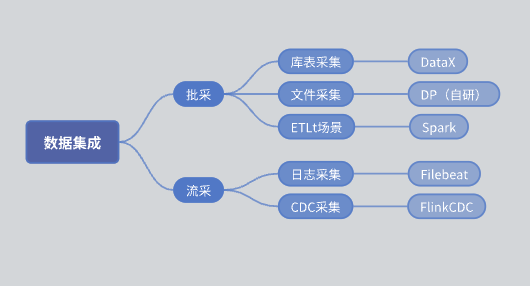
Batch: It is divided into library table collection and file collection.
Database and table collection: mainly implemented using DataX.
File collection: self-developed DP engine.
ETLt collection: self-developed ETLt collection engine. DataX is biased towards ELT (extraction, loading, transformation), which is suitable for complex transformation after data extraction and storage. However, in some scenarios, ELT (extraction, loading, simple transformation) is required, which DataX is not suitable for. Therefore, we developed an engine based on Spark SQL.
Flow: Log collection is mainly based on Filebeat, and CDC collection is mainly based on Flink CDC.
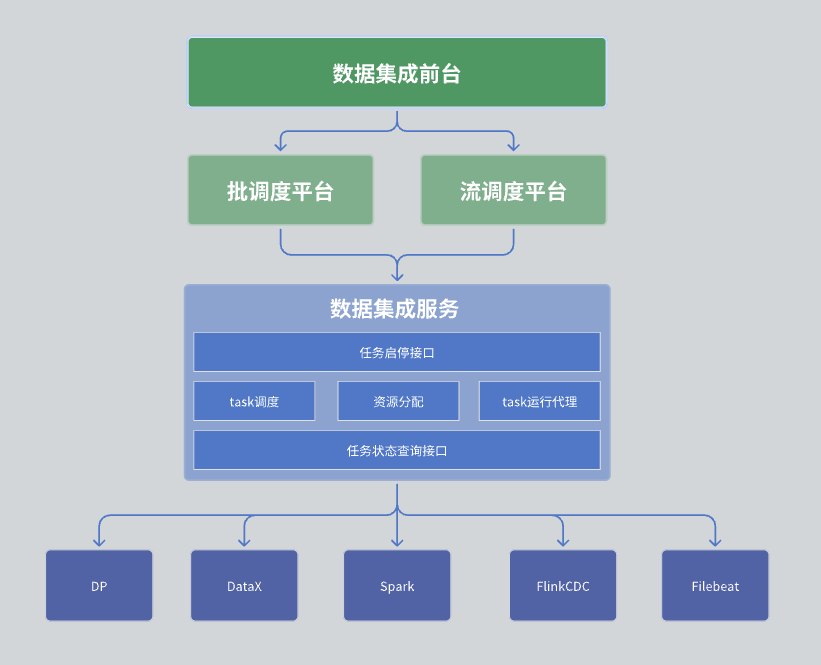
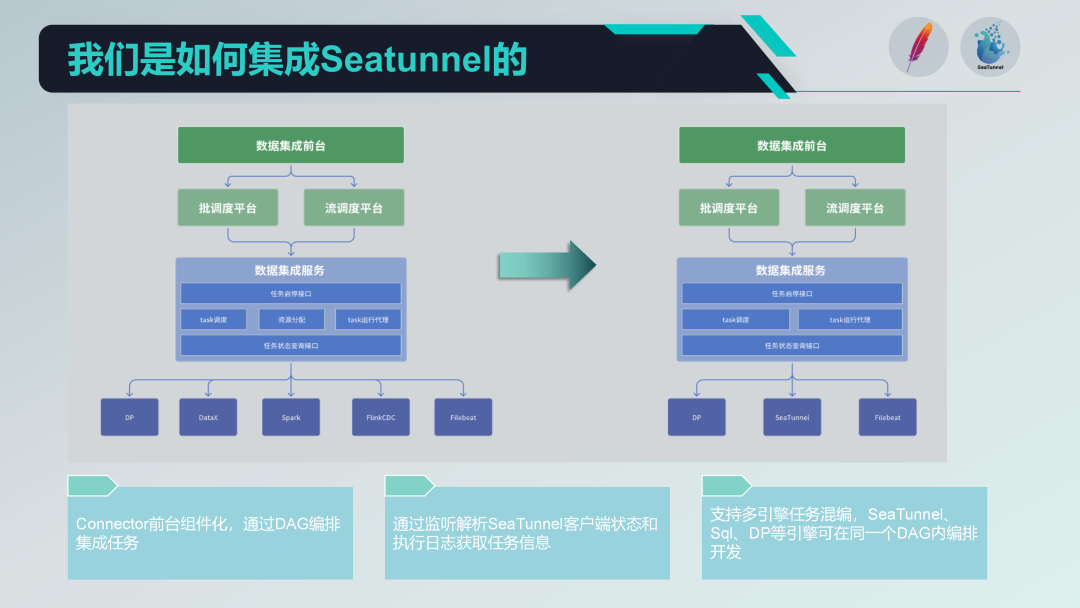
In our data integration module, the overall architecture is divided into three layers: data integration front-end, scheduling platform and data integration service.
Below is a detailed description of each layer:
First layer: data integration front end
The data integration front desk is mainly responsible for the management of data integration tasks. Specifically, it includes task development, scheduling development, and operation monitoring. These tasks combine various integration operators through DAG (directed acyclic graph) to realize complex data processing processes. The front desk interface provides an intuitive task management interface, allowing users to easily configure and monitor data integration tasks.
Second layer: scheduling platform
The scheduling platform is responsible for the scheduling and management of task operations. It supports both batch processing and stream processing modes, and can pull up corresponding tasks based on task dependencies and scheduling strategies.
The third layer: data integration services
Data integration service is the core of the entire data center service, which provides a series of key functions:
Task management interface: Includes functions such as creating, deleting, updating and querying tasks.
Task start and stop interface: Allows the user to start or stop a specific task.
Task status query interface: Query the current status information of the task for easy monitoring and management.
The data integration service is also responsible for the specific operation of the task. Since our collection tasks may involve multiple engines, it is necessary to coordinate and schedule multiple engines when the task is running.
Task operation process
The operation of the task mainly includes the following steps:
Task Scheduling:Based on the predetermined scheduling strategies and dependencies, the scheduling platform launches the corresponding tasks.
Task Execution: During the task execution process, each operator is executed in sequence according to the DAG configuration of the task.
Multi-engine coordination: For tasks that include multiple engines (such as DataX and Spark mixed tasks), it is necessary to coordinate the operation of each engine during the execution process to ensure the smooth execution of the task.
Resource allocation
At the same time, in order to enable single-machine tasks such as DataX to run in a distributed manner and achieve resource reuse, we have optimized the resource allocation of DataX tasks:
Distributed Scheduling: Through the resource allocation mechanism, DataX tasks are distributed to multiple nodes to run, avoiding single-point bottlenecks and improving task parallelism and execution efficiency.
Resource reuse: Through reasonable resource management and allocation strategies, ensure efficient reuse of resources for different tasks and reduce resource waste.
Task Runner Agent
We have implemented a corresponding task execution agent for each execution engine to achieve unified management and monitoring of tasks:
Execution Engine Agent: In the data integration service, the agent manages various execution engines, such as DataX, Spark, Flink CDC, etc. The agent is responsible for starting, stopping, and status monitoring of tasks.
Unified Interface: Provides a unified task management interface so that tasks of different engines can be managed through the same interface, simplifying operation and management work.
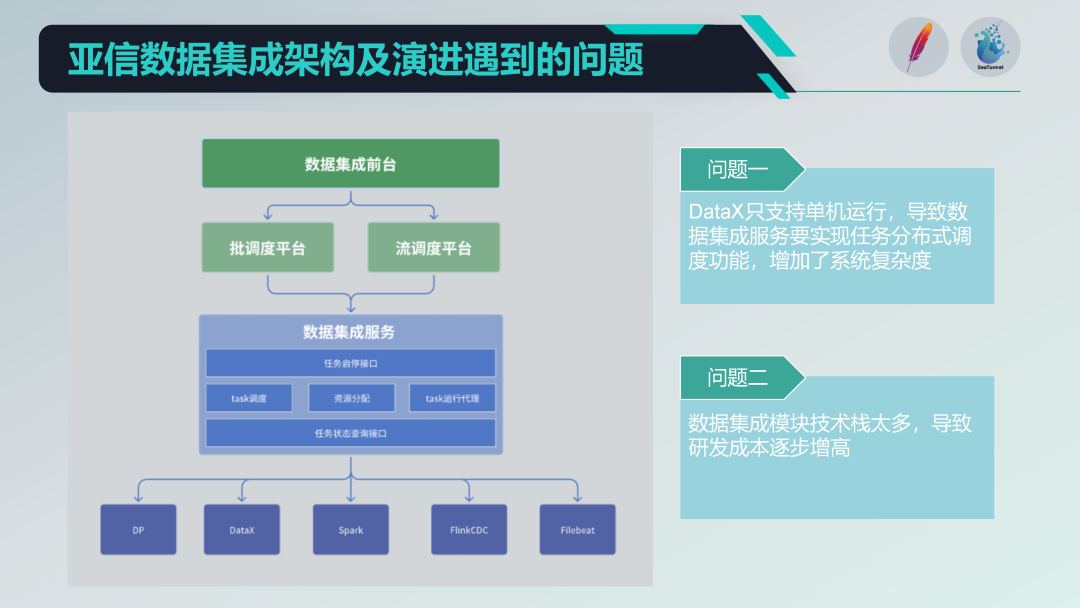
Some problems with the old data integration architecture
We have integrated some open source projects, such as DataX, Spark, Flink CDC, Filebeat, etc., to form a powerful data integration service platform. However, we also face some problems:
Single machine operation restrictions: DataX only supports single-machine operation, which requires us to implement distributed scheduling functions based on it, increasing the complexity of the system.
Too diverse a technology stack: Multiple technology stacks (such as Spark and Flink) have been introduced. Although they are feature-rich, they also lead to high R&D costs. Every time a new function is developed, it is necessary to deal with the compatibility and integration issues of multiple technology stacks.
Architecture Evolution
In order to optimize the architecture and reduce complexity, we evolved the existing architecture:
Integrate multi-engine functions: After introducing SeaTunnel, we can unify the functions of multiple engines and realize multiple data processing capabilities on a single platform.
Simplify resource management: Through SeaTunnel's resource management function, the distributed scheduling of single-machine tasks such as DataX is simplified, reducing the complexity of resource allocation and management.
Reduce R&D costs: Through unified architecture and interface design, the development and maintenance costs brought by multiple technology stacks are reduced, and the scalability and maintainability of the system are improved.
By optimizing and evolving the architecture, we have successfully solved the limitations of DataX’s single-machine operation and the high R&D costs caused by multiple technology stacks.
After introducing SeaTunnel, we were able to implement multiple data processing functions on a single platform, while simplifying resource management and task scheduling, and improving the overall efficiency and stability of the system.
Why choose SeaTunnel?
Our contact with SeaTunnel can be traced back to the Waterdrop period, and we have conducted many application practices for Waterdrop.
Last year, SeaTunnel launched the Zeta engine, which supports distributed architecture and became an Apache top-level project. This enabled us to find a suitable time node last year, conduct in-depth research, and decide to introduce SeaTunnel.
Here are a few main reasons why we chose SeaTunnel:
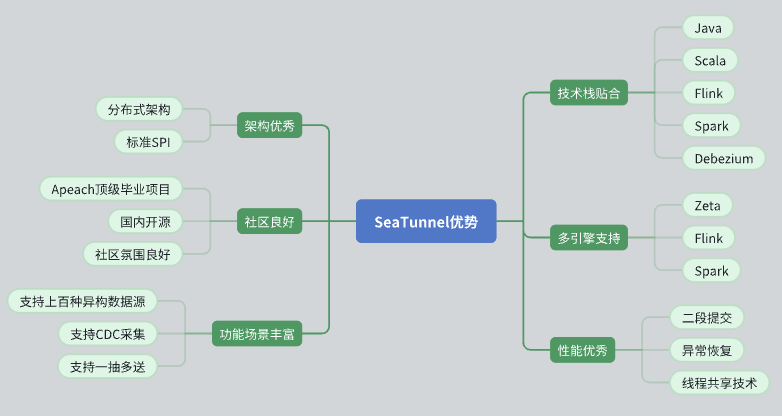
Excellent architectural design
SeaTunnel has a distributed architecture that adapts well to our needs.
Its API design is standardized and adopts the SPI (Service Provider Interface) model, which is easy to expand and integrate.
Active community support
SeaTunnel is an Apache top-level project with a good community atmosphere. Active developers and user groups provide strong support for problem solving and function expansion.
The background of domestic open source projects makes our communication and collaboration smoother.
Rich functions and data source support
SeaTunnel supports multiple data sources and is feature-rich, which can meet our diverse data processing needs.
Supports CDC (Change Data Capture), which enables real-time data synchronization and processing.
Supports one-to-many data transmission mode, which improves the flexibility of data transmission.
Technology stack fit
SeaTunnel is compatible with Java and supports Flink and Spark, allowing us to seamlessly integrate and apply it on the existing technology stack.
Debezium is used for CDC data capture, and the technology is mature and stable.
Multi-engine support
SeaTunnel supports multiple computing engines, including Zeta, Flink, and Spark, and can select the most suitable engine for computing according to specific needs.
This is very important because it allows us to choose the optimal computing mode in different scenarios, improving the flexibility and efficiency of the system.
Excellent performance
SeaTunnel has designed performance optimization mechanisms such as two-phase commit, fault-tolerance recovery, and thread sharing to ensure efficient and stable data processing.
Problems solved after introducing SeaTunnel
SeaTunnel can solve the two main problems we mentioned earlier:
Distributed Scheduling
DataX can only run on a single machine, so we need to implement distributed scheduling functions. However, SeaTunnel naturally supports distributed architecture, and can easily implement distributed data processing whether using Zeta, Flink or Spark as the computing engine, which greatly simplifies our work.
Technology stack integration
We previously used a variety of technology stacks, including DataX, Spark, Flink CDC, etc., which made the R&D cost high and the system complex. SeaTunnel provides an integrated platform by unifying these technology stacks, which can support both ELT and ETL processes, greatly simplifying the system architecture and reducing development and maintenance costs.
How to integrate SeaTunnel
Before integrating SeaTunnel, our old architecture had been in existence and running for a while. It was generally divided into three layers: front-end, scheduling platform, and data integration service. The front-end was responsible for task management and development, the scheduling platform was responsible for task scheduling and dependency management, and the data integration service was the core part for executing and managing all data integration tasks.
The following is our new architecture after integrating SeaTunnel.
First, we removed the resource allocation part involving DataX in the old architecture. Since SeaTunnel itself supports distributed architecture, no additional resource allocation management is required. This adjustment greatly simplified our architecture.
Replacement of technology stack
We gradually replaced the old technology stack with SeaTunnel. The specific steps are as follows:
Replace batch processing tasks: We first replaced the part of the old architecture that used DataX and Spark for batch ETL.
Replace stream processing tasks: Next, we will gradually replace the stream processing parts using Flink CDC. By taking this step-by-step approach, we can ensure that the system remains stable during the gradual transition.
Componentized SeaTunnel Connector
We designed a component-based design based on SeaTunnel's Connector, and configured and orchestrated DAG in a form-based manner on the front end. Although SeaTunnel Web is also doing similar work, we customized it according to our own needs to better integrate with existing systems.
Task Runner Agent
In terms of task running agent, we submit tasks through SeaTunnel client and monitor the status and execution logs of SeaTunnel client. By parsing these logs, we can obtain the execution status information of the task and ensure the monitorability and traceability of task execution.
Multi-engine mixed development
We support multi-engine mixed development, and can perform multi-engine DAG orchestration for a scheduling task on the front page. In this way, we can use different engines (such as SQL engine and DP engine) to develop tasks in a scheduling task at the same time, improving the flexibility and scalability of the system.
Problems encountered during SeaTunnel integration
During the process of integrating SeaTunnel, we encountered some problems. Here are some representative problems and their solutions:
Problem 1: Error handling
When using SeaTunnel, we encountered some errors related to the framework code. Since there was no relevant explanation in the official documentation, we joined the community WeChat group and asked for help from the developers in the group, and solved the problem in time.
Problem 2: Task Cutover
Our old collection tasks were implemented using DataX. When replacing it with SeaTunnel, we needed to consider the issue of task cutover.
We solve this problem through the following solutions:
Component-based design: Our data collection tasks are designed in a componentized way. There is a conversion layer between the front-end components and the back-end execution engine. The front-end configures the form, and the back-end generates the JSON file that DataX needs to execute through the conversion layer.
Similar JSON file generation:SeaTunnel configuration is similar to DataX. The front-end is also configured through a form, and the back-end generates a JSON file that SeaTunnel needs to execute. In this way, we can seamlessly transfer old tasks to the new SeaTunnel platform to ensure a smooth transition of tasks.
SQL script conversion: Write SQL scripts to clean and convert old DataX tasks to adapt them to SeaTunnel. This method is more flexible and adaptable, because SeaTunnel will be updated frequently, and writing hard-coded compatibility is not a long-term solution. Through script conversion, tasks can be migrated more efficiently to adapt to SeaTunnel updates.
Problem 3: Version Management
We encountered version management issues while using SeaTunnel. SeaTunnel is updated frequently, and our team's second version needs to keep up with the latest version. Here is our solution:
Local branch management:We pulled a local branch based on SeaTunnel 2.3.2 and performed secondary development on it, including fixing personalized needs and temporarily fixing bugs. In order to minimize the locally maintained code, we only retain necessary changes and try to use the latest community version for other parts.
Regularly merge community updates:We regularly merge new versions from the community into our local branch, especially to update and be compatible with the parts we modified. Although this method is clumsy, it ensures that we can keep up with the latest features and fixes from the community.
Giving Back to the Community:In order to better manage and maintain the code, we plan to submit some of our changes and personalized requirements to the community and strive for community acceptance and support. This will not only help reduce our local maintenance work, but also contribute to the common development of the community.
SeaTunnel secondary development and practice
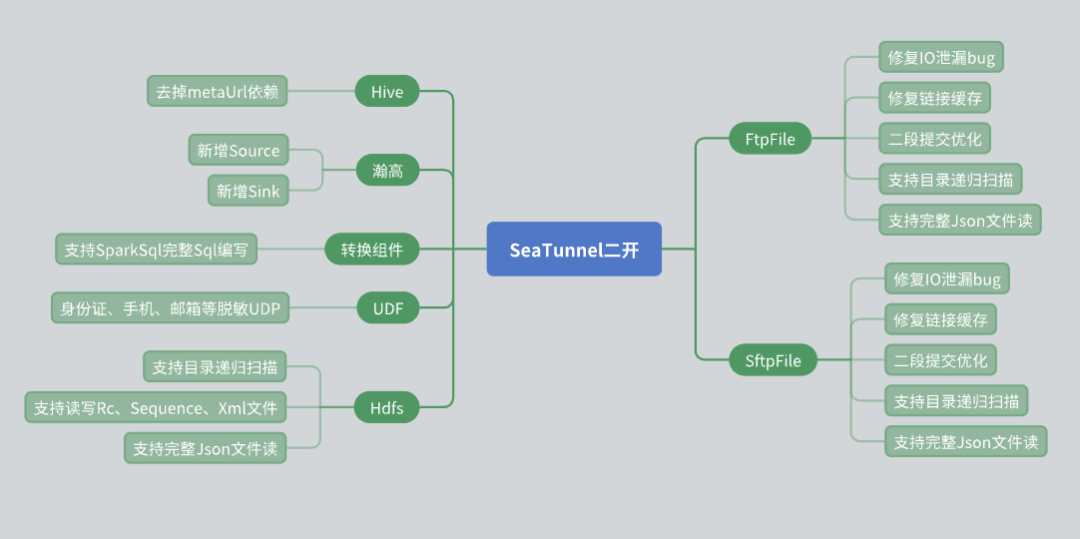
During the use of SeaTunnel, we conducted a number of secondary developments based on actual business needs, especially at the connector level. The following are the problems we encountered in the secondary development and their solutions.
Hive Connector Transformation
The original SeaTunnel Hive Connector needs to rely on Meta URL to obtain metadata. However, in actual applications, many third-party users cannot provide Meta URL due to security issues. To deal with this situation, we have made the following modifications:
Use the JDBC interface of Hive Server 2 to obtain the metadata information of the table, thus avoiding the dependence on the Meta URL.
In this way, we can provide users with more flexible reading and writing capabilities of Hive data while ensuring data security.
Support from Hangao Database
The Hangao database is widely used in our projects, so we have added support for data source reading and writing of the Hangao database. At the same time, we have developed conversion components to meet some special requirements of the Hangao database:
Supports complex conversion operations such as row to column and column to row.
Wrote a variety of UDFs (user-defined functions) for operations such as data masking.
Renovation of file connector
The file system connector plays a large role in our use, so we made several changes to it:
HDFS Connector: Added directory recursion and regular expression scanning file functions, and supports reading and writing multiple file formats (such as RC, Sequence, XML, JSON).
FTP and SFTP Connectors: Fixed the I/O leak bug and optimized the connection cache mechanism to ensure the independence between different accounts of the same IP.
Optimization of the two-phase commit mechanism
In the process of using SeaTunnel, we have a deep understanding of its two-phase commit mechanism to ensure data consistency. The following are the problems we encountered in the process and their solutions:
Problem Description: When using FTP and SFTP to write files, an error message appears indicating that there is no write permission. After investigation, it was found that SeaTunnel writes files to a temporary directory before moving them to ensure data consistency.
However, due to the permission settings of different accounts on the temporary directory, writing failed.
solution: When creating a temporary directory, set a larger permission (such as 777) to ensure that all accounts have permission to write. At the same time, the problem of rename command failure caused by cross-file system during file movement is solved. By creating a temporary directory under the same file system, cross-file system operations are avoided.
Secondary development management
During the secondary development process, we faced the problem of how to manage and synchronize the new version of SeaTunnel. Our solution is as follows:
Local branch management:Based on SeaTunnel 2.3.2 version, a local distribution
Regularly merge community updates: Regularly merge new versions from the community into the local branch to ensure that we can get new features and fixes from the community in a timely manner.
Giving Back to the Community: We plan to submit some of our changes and personalized requirements to the community in the hope of gaining community acceptance and support, thereby reducing the workload of local maintenance.
SeaTunnel Integration and Application
During the SeaTunnel integration process, we focused on the following points:
Resource allocation optimization: Using SeaTunnel's distributed architecture simplifies resource allocation issues and no longer requires additional distributed scheduling functions.
Technology stack integration: Integrate the functions of different technology stacks such as DataX, Spark, FlinkCDC into SeaTunnel, unify the packaging, and realize the integration of ETL and ELT.
Through the above steps and strategies, we successfully integrated SeaTunnel into our data integration service, solved some key problems in the old system, and optimized the performance and stability of the system.
During this process, we actively participated in the community, sought help and reported issues to ensure the smooth progress of the integration. This positive interaction not only improved our technical level, but also promoted the development of the SeaTunnel community.
Experience of participating in the open source community
During my participation in SeaTunnel, I gained the following insights:
The right time: We chose this project when SeaTunnel was developing rapidly, and the timing was very good. The development of SeaTunnel gave us great confidence and made us feel that there were many things we could do.
Personal Goals: I set the goal of participating in the open source community at the beginning of this year and actively took action.
Community Friendliness:The SeaTunnel community is very friendly, everyone communicates smoothly and helps each other. This positive atmosphere makes me feel that it is very worthwhile to participate in it.
For those who have always wanted to participate in the open source community but have not taken the first step, I would like to encourage everyone to take this step bravely. The most important thing about the community is people. As long as you join, you are an indispensable part of the community.
Expectations for SeaTunnel
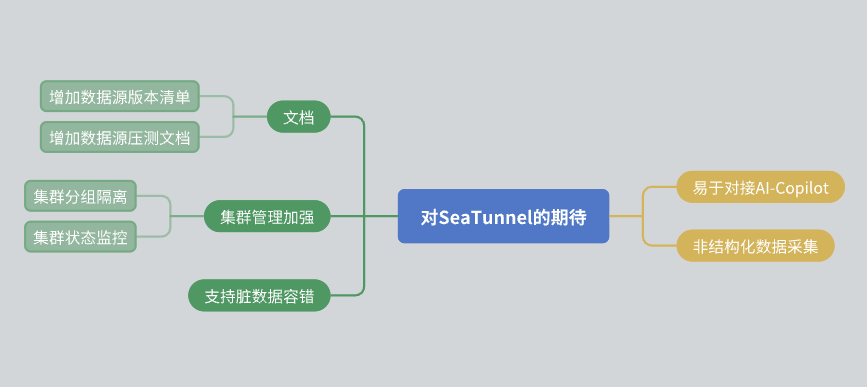
Finally, I would like to share some of my expectations for SeaTunnel:
Documentation improvements: We hope that the community can further improve the documentation, including the version list of data sources and stress testing reports.
Cluster Management: We hope that SeaTunnel can achieve resource isolation within the cluster and provide richer cluster status monitoring information.
Data Fault Tolerance: Although SeaTunnel already has a fault tolerance mechanism, we hope that it can be further optimized in the future.
AI Integration: I hope SeaTunnel can provide more interfaces to facilitate AI-assisted access.
Thanks to every member of the SeaTunnel community for your contribution. That’s all for my sharing. Thank you everyone!