2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Angesichts der rasanten Entwicklung der künstlichen Intelligenz hat das Streben nach effizienten und hervorragenden Sprachmodellen das Google DeepMind-Team heute dazu veranlasst, das bahnbrechende Modell RecurrentGemma zu entwickeln. Dieses neue Modell, das im Artikel „RecurrentGemma: Efficient Open Language Models Beyond Transformers“ detailliert beschrieben wird, verspricht, die Standards der Sprachverarbeitung durch die Kombination von linearer Rekursion und lokalen Aufmerksamkeitsmechanismen neu zu definieren.
Die Architektur des RecurrentGemma-Modells ist der Kern seiner effizienten Leistung. Sie basiert auf der von Google DeepMind vorgeschlagenen Architektur. Diese Architektur bietet neue Möglichkeiten für die Verarbeitung von Sprachaufgaben, indem sie lineare Rekursion und lokale Aufmerksamkeitsmechanismen kombiniert. Wenn wir uns mit der Modellarchitektur von RecurrentGemma befassen, müssen wir zunächst die Grundlagen der Griffin-Architektur verstehen und wissen, wie RecurrentGemma auf dieser Grundlage Innovationen und Optimierungen vornimmt.
RecurrentGemma nimmt eine wichtige Änderung an der Griffin-Architektur vor, die die Verarbeitung von Eingabeeinbettungen umfasst. Die Eingabeeinbettung des Modells wird mit einer Konstante multipliziert, die der Quadratwurzel der Modellbreite entspricht. Diese Behandlung passt die Eingabeseite des Modells an, ändert jedoch nicht die Ausgabeseite, da die Ausgabeeinbettung diesen Multiplikationsfaktor nicht anwendet. Durch diese Anpassung kann das Modell Informationen effizienter verarbeiten und gleichzeitig die Konsistenz über alle Modellbreiten hinweg wahren. Diese Modifikation spielt eine wichtige Rolle im mathematischen Ausdruck und Informationsfluss des Modells. Es optimiert nicht nur die anfängliche Verarbeitung der Eingabedaten durch das Modell, sondern hilft dem Modell auch dabei, die Merkmale der Sprache besser zu erfassen und darzustellen, indem der Maßstab der Einbettung angepasst wird.
Die Leistung und Effizienz eines RecurrentGemma-Modells werden weitgehend durch seine Hyperparameter bestimmt. Diese Hyperparameter sind ein wichtiger Bestandteil der Modelldefinition und umfassen unter anderem die folgenden Aspekte:
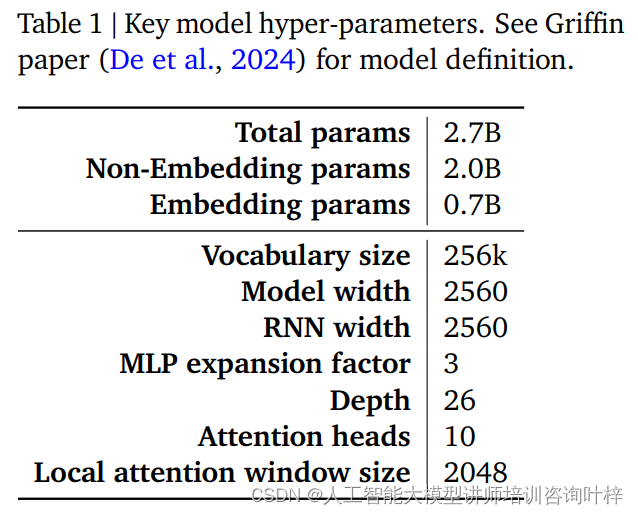
Tabelle 1 bietet eine Zusammenfassung dieser wichtigen Hyperparameter. Eine detailliertere Modelldefinition finden Sie im Griffin-Artikel von De et al. Zusammen bilden diese Hyperparameter die Grundlage des RecurrentGemma-Modells und ermöglichen eine effiziente Verarbeitung langer Sequenzen bei gleichzeitig geringem Speicherbedarf.
Durch sorgfältige Modifikationen der Griffin-Architektur und sorgfältige Anpassung der Hyperparameter demonstriert das RecurrentGemma-Modell nicht nur seinen theoretischen Fortschritt, sondern beweist auch seine Effizienz und leistungsstarken Sprachverarbeitungsfähigkeiten in praktischen Anwendungen.
Das Vortraining von RecurrentGemma-2B verwendet 2 Billionen Token. Obwohl diese Datenmenge kleiner ist als die von Gemma-2B verwendeten 3 Billionen Token, stellt sie dennoch einen riesigen Datensatz dar und liefert umfangreiche Sprachinformationen für das Modell.
Die Datenquellen für das Vortraining sind hauptsächlich englische Online-Dokumente, Mathematik und Codes. Diese Daten decken nicht nur ein breites Spektrum an Themen und Bereichen ab, sondern werden auch sorgfältig gefiltert und bereinigt, um unerwünschte oder unsichere Inhalte zu reduzieren und persönliche oder sensible Daten auszuschließen. Um die Fairness der Bewertung sicherzustellen, werden außerdem alle Bewertungssätze aus dem Datensatz vor dem Training ausgeschlossen.
RecurrentGemma-2B verwendet zunächst eine große generische Datenmischung im Vortraining und wechselt dann für das weitere Training zu kleineren, aber qualitativ hochwertigeren Datensätzen. Dieser abgestufte Trainingsansatz hilft dem Modell, eine allgemeine Sprachdarstellung für eine Vielzahl von Daten zu erlernen und diese dann mit spezielleren Daten zu verfeinern und zu optimieren.
Nach dem Vortraining wurde RecurrentGemma-2B durch Befehlsoptimierung und den RLHF-Algorithmus verfeinert. Dieser Prozess zielt darauf ab, das Modell so zu optimieren, dass es Anweisungen besser befolgen und Antworten mit hohen Belohnungen generieren kann.
Instruction Tuning ist eine Trainingsmethode, die es einem Modell ermöglicht, ein bestimmtes Anweisungsformat zu verstehen und darauf zu reagieren. RecurrentGemma-2B ist darauf trainiert, ein bestimmtes Konversationsformat einzuhalten, das durch bestimmte Steuer-Tags definiert wird, z. B. Benutzereingaben und Modellausgaben, die jeweils mit unterschiedlichen Tags gekennzeichnet sind.
Der RLHF-Algorithmus ist eine fortschrittliche Feinabstimmungstechnik, die die Ausgabe des Modells durch ein Reinforcement-Learning-Framework optimiert. In RLHF wird die Ausgabe des Modells auf der Grundlage menschlichen Feedbacks bewertet und auf der Grundlage der Bewertungsergebnisse angepasst, um die Qualität der Ausgabe und Belohnungen zu verbessern. Dieser Algorithmus ermöglicht es dem Modell zu lernen, wie es in verschiedenen Kontexten passendere Antworten generiert.
Durch die Anpassung der Anweisungen und die RLHF-Feinabstimmung ist RecurrentGemma-2B nicht nur in der Lage, qualitativ hochwertige Sprachausgaben zu erzeugen, sondern schneidet auch bei Gesprächen und beim Befolgen von Anweisungen gut ab. Diese Trainingsmethode verleiht dem Modell Flexibilität und Anpassungsfähigkeit, sodass es in einer Vielzahl von Anwendungsszenarien funktionieren kann.

Auf diese Weise wird RecurrentGemma-2B zu einem leistungsstarken Sprachmodell, das eine effiziente und genaue Sprachverarbeitung für eine Vielzahl von Aufgaben und Umgebungen ermöglicht.
Automatisiertes Benchmarking ist der erste Schritt zur Bewertung der Leistung von RecurrentGemma-2B. Diese Tests decken eine Vielzahl beliebter nachgelagerter Aufgaben ab, darunter unter anderem die Beantwortung von Fragen, Textzusammenfassung, sprachliches Denken und mehr. Die Leistung von RecurrentGemma-2B bei diesen Aufgaben wird mit Gemma-2B verglichen, und die Ergebnisse zeigen, dass RecurrentGemma-2B zwar auf einer geringeren Anzahl von Token trainiert wird, seine Leistung jedoch mit Gemma-2B vergleichbar ist.
Die Leistung von RecurrentGemma-2B in mehreren akademischen Benchmarks wie MMLU 5-Schuss, HellaSwag 0-Schuss, PIQA 0-Schuss usw. ähnelt der von Gemma-2B, was seine Vielseitigkeit und Effektivität bei verschiedenen Aufgaben unter Beweis stellt. Diese Testergebnisse belegen nicht nur das tiefe Sprachverständnis des Modells, sondern spiegeln auch sein Potenzial in praktischen Anwendungen wider.

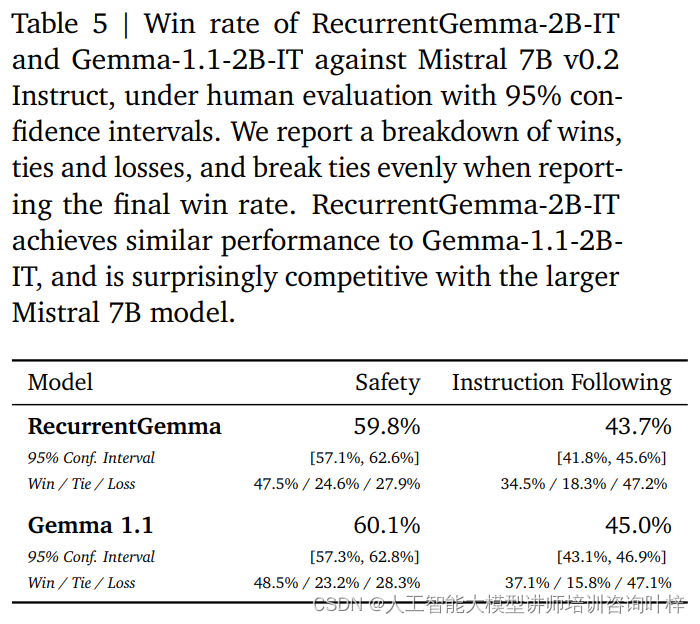
Zusätzlich zu automatisierten Benchmarks wurde RecurrentGemma-2B anhand menschlicher Bewertungen getestet. Die menschliche Bewertung ist ein entscheidender Schritt bei der Beurteilung, ob ein Sprachmodell Antworten erzeugen kann, die den menschlichen Erwartungen entsprechen. In diesem Prozess wurde eine auf Anweisungen abgestimmte Variante von RecurrentGemma-2B (RecurrentGemma-2B-IT) mit dem Instruct-Modell Mistral 7B v0.2 verglichen.
Bei menschlichen Beurteilungen wird eine Sammlung von etwa 1.000 Anweisungen für kreative Schreib- und Codierungsaufgaben verwendet. RecurrentGemma-2B-IT zeigte in diesem Set eine beeindruckende Leistung und erreichte eine Siegesquote von 43,7 %, die nur geringfügig unter der von Gemma-1.1-2B-IT mit 45,0 % liegt. Dieses Ergebnis zeigt, dass die Fähigkeit von RecurrentGemma-2B, komplexe Anweisungen zu verstehen und auszuführen, mit bestehenden fortgeschrittenen Modellen vergleichbar ist.
RecurrentGemma-2B-IT wurde auch anhand einer Sammlung von etwa 400 Eingabeaufforderungen zum Testen grundlegender Sicherheitsprotokolle evaluiert und erreichte eine Erfolgsquote von 59,8 %, was die Überlegenheit des Modells bei der Einhaltung von Sicherheitsrichtlinien demonstriert.
Die Leistung von RecurrentGemma-2B wurde umfassend durch eine Kombination aus automatisierten Benchmarks und menschlicher Bewertung getestet. Automatisierte Tests ermöglichen eine quantitative Bewertung der Leistung des Modells bei verschiedenen Sprachaufgaben, während die menschliche Bewertung ein qualitatives Verständnis der Qualität der Modellausgabe liefert. Dieser umfassende Evaluierungsansatz stellt sicher, dass RecurrentGemma-2B nicht nur theoretisch gute Leistungen erbringt, sondern auch in der Praxis eine qualitativ hochwertige Sprachgenerierung und Sprachverständlichkeit liefert.
Die Inferenzgeschwindigkeit ist eine der Schlüsselmetriken zur Messung der Nützlichkeit eines Sprachmodells, insbesondere beim Umgang mit Daten mit langen Sequenzen. Die Optimierung der Inferenzgeschwindigkeit von RecurrentGemma-2B ist ein Highlight, das es vom traditionellen Transformer-Modell unterscheidet. Im herkömmlichen Transformer-Modell muss das Modell für eine effiziente Sequenzverarbeitung den Schlüsselwert-Cache (KV) abrufen und in den Gerätespeicher laden. Mit zunehmender Sequenzlänge wächst auch die Größe des KV-Cache linear, was nicht nur die Speichernutzung erhöht, sondern auch die Fähigkeit des Modells zur Verarbeitung langer Sequenzen einschränkt. Obwohl die Größe des Caches durch lokale Aufmerksamkeitsmechanismen reduziert werden kann, geht dies normalerweise zu Lasten der Leistung.
RecurrentGemma-2B löst die oben genannten Probleme durch sein innovatives Architekturdesign. Es komprimiert die Eingabesequenz in einen Zustand fester Größe, anstatt sich auf einen KV-Cache zu verlassen, der mit der Sequenzlänge wächst. Dieses Design reduziert die Speichernutzung erheblich und ermöglicht es dem Modell, bei der Verarbeitung langer Sequenzen eine effiziente Inferenzgeschwindigkeit aufrechtzuerhalten.
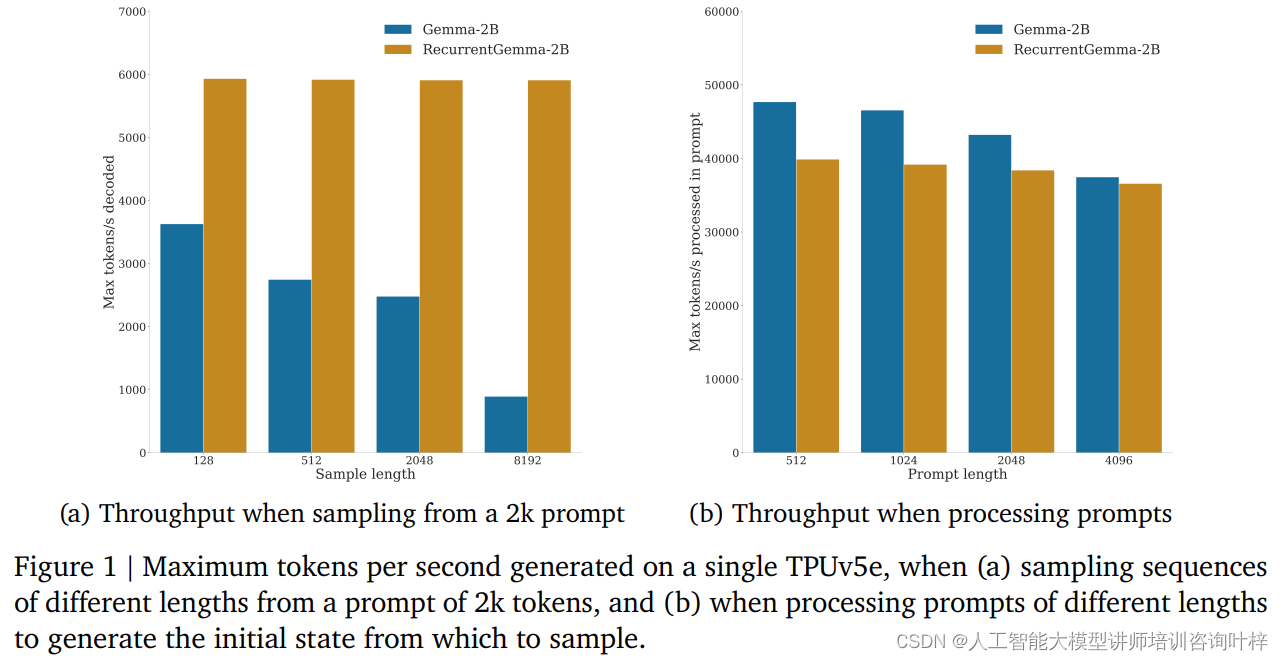
In Benchmark-Tests zeigte RecurrentGemma-2B erhebliche Durchsatzvorteile. Wie in Abbildung 1a dargestellt, kann RecurrentGemma-2B auf einem einzelnen TPUv5e-Gerät einen Durchsatz von bis zu 6.000 Token pro Sekunde erreichen, wenn Sequenzen unterschiedlicher Länge aus einem Hinweis von 2.000 Token abgetastet werden, während das Gemma-Modell mit dem Cache wächst . Der Durchsatz nimmt ab.
Die feste Zustandsgröße von RecurrentGemma-2B ist der Schlüssel zu seiner effizienten Inferenz. Im Vergleich zum Gemma-Modell wächst der Status von RecurrentGemma-2B nicht mit der Länge der Sequenz, was bedeutet, dass Sequenzen beliebiger Länge generiert werden können, ohne durch die Speichergröße des Hosts eingeschränkt zu sein. Dies ist besonders wichtig bei der Verarbeitung langer Sequenzen, da es dem Modell ermöglicht, längere Textdaten zu verarbeiten und gleichzeitig eine hohe Leistung beizubehalten.
Die Verbesserung der Denkgeschwindigkeit ist nicht nur in der Theorie von großer Bedeutung, sondern zeigt auch ihren Wert in der praktischen Anwendung. In ressourcenbeschränkten Umgebungen wie Mobilgeräten oder Edge-Computing-Geräten ist RecurrentGemma-2B aufgrund seines hohen Durchsatzes und seines geringen Speicherbedarfs die ideale Wahl. Darüber hinaus ermöglicht die effiziente Inferenzgeschwindigkeit dem Modell, schneller auf Benutzeranfragen zu reagieren und ein reibungsloseres interaktives Erlebnis zu bieten.
Im Bereich der künstlichen Intelligenz bedeutet der Einsatz von Modellen nicht nur die Realisierung von Technologie, sondern auch die Übernahme von Sicherheit und ethischer Verantwortung. Die Einsatzstrategie von RecurrentGemma-2B spiegelt die Betonung dieser Schlüsselfaktoren vollständig wider.
Vor dem Einsatz des Modells wurde RecurrentGemma-2B einer Reihe standardmäßiger akademischer Sicherheitsbenchmarks unterzogen, um mögliches Fehlverhalten oder Voreingenommenheit des Modells zu bewerten. Durch diese Tests ist das Entwicklungsteam in der Lage, potenzielle Risiken zu identifizieren und zu mindern und so sicherzustellen, dass das Modell für die öffentliche Nutzung sicher ist.

Zusätzlich zum automatisierten Sicherheits-Benchmarking wurde RecurrentGemma-2B einer Ethik- und Sicherheitsbewertung durch ein unabhängiges Team unterzogen. Dieser Prozess beinhaltet eine umfassende Überprüfung des Modells, einschließlich, aber nicht beschränkt auf seine Fairness gegenüber bestimmten Gruppen, seine Fähigkeit, schädliche Ausgaben zu vermeiden, und seinen Schutz der Privatsphäre der Benutzer.
Trotz strenger Tests und Bewertungen betont das Entwicklungsteam, dass es unmöglich ist, alle möglichen Anwendungsfälle abzudecken, da RecurrentGemma-2B in vielen verschiedenen Szenarien eingesetzt werden kann. Daher empfehlen sie allen Benutzern, vor der Bereitstellung von Modellen zusätzliche Sicherheitstests basierend auf ihren spezifischen Anwendungsfällen durchzuführen. Diese Empfehlung spiegelt die Betonung der Benutzerverantwortung wider, um sicherzustellen, dass jede Bereitstellung gut durchdacht und angepasst ist.
Zu einem verantwortungsvollen Einsatz gehört auch Transparenz über die Leistung und Einschränkungen des Modells. Das Entwicklungsteam stellt detaillierte Modellarchitektur- und Schulungsdetails bereit, damit Benutzer und Forscher die Funktionsweise des Modells und mögliche Einschränkungen verstehen können. Darüber hinaus ist das Team bestrebt, das Modell kontinuierlich zu überwachen und zu verbessern, um aufkommende Risiken und Herausforderungen anzugehen.
Zu einem verantwortungsvollen Einsatz gehört auch die Zusammenarbeit mit der breiteren KI-Community und mehreren Interessengruppen. Durch den Austausch von Forschungsergebnissen, die Teilnahme an offenen Diskussionen und die Annahme von externem Feedback zeigt das Entwicklungsteam von RecurrentGemma sein Engagement für offene Wissenschaft und Zusammenarbeit.
Während das Feld der künstlichen Intelligenz weiter wächst, dient RecurrentGemma als Modell, das innovative architektonische Designkonzepte, strenge Schulungs- und Bewertungsprozesse kombiniert und das Potenzial demonstriert, die Grenzen dessen zu verschieben, was beim Sprachverständnis und bei der Generierung möglich ist.
Link zum Papier: https://arxiv.org/abs/2404.07839

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
