私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
今日、人工知能の急速な発展に伴い、効率的で優れた言語モデルの追求により、Google DeepMind チームは画期的なモデル RecurrentGemma の開発を促しました。この新しいモデルは、論文「RecurrentGemma: Transformers を超えた効率的なオープン言語モデル」で詳しく説明されており、線形再帰とローカル アテンション メカニズムを組み合わせることにより、言語処理の標準を再定義することを約束しています。
RecurrentGemma モデルのアーキテクチャは、Google DeepMind によって提案された Griffin アーキテクチャに基づいており、線形再帰とローカル アテンション メカニズムを組み合わせることで、言語タスクの処理に新しい可能性をもたらします。 RecurrentGemma のモデル アーキテクチャを詳しく調べる場合は、まず Griffin アーキテクチャの基礎と、それに基づいて RecurrentGemma がどのように革新および最適化されるかを理解する必要があります。
RecurrentGemma は、入力埋め込みの処理を含む Griffin アーキテクチャに重要な変更を加えます。モデルの入力埋め込みには、モデルの幅の平方根に等しい定数が乗算されます。この処理ではモデルの入力側が調整されますが、出力の埋め込みではこの乗算係数が適用されないため、出力側は変更されません。この調整により、モデルはモデル幅全体で一貫性を維持しながら、より効率的に情報を処理できるようになります。この変更は、モデルの数式と情報の流れにおいて重要な役割を果たします。これは、モデルによる入力データの初期処理を最適化するだけでなく、埋め込みのスケールを調整することで、モデルが言語の特性をより適切に捉えて表現するのにも役立ちます。
RecurrentGemma モデルのパフォーマンスと効率は、主にそのハイパーパラメーターによって決まります。これらのハイパーパラメータはモデル定義の重要な部分であり、次の側面が含まれますが、これらに限定されません。
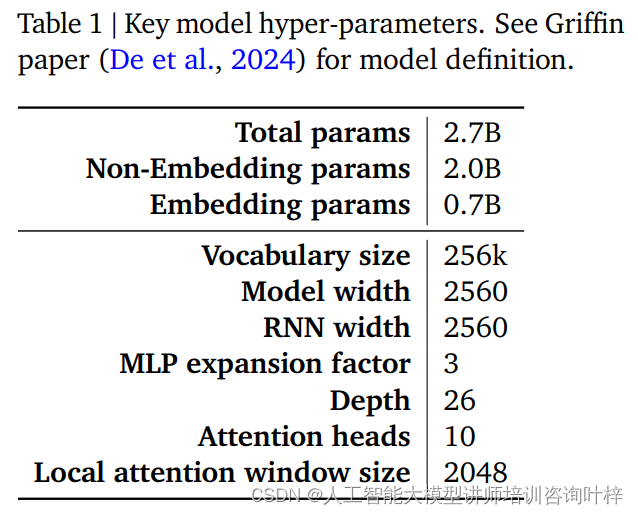
表 1 は、これらの主要なハイパーパラメータの概要を示しています。より詳細なモデル定義は、De らによる Griffin 論文に記載されています。これらのハイパーパラメータは合わせて RecurrentGemma モデルの基礎を形成し、メモリ使用量を小さくしながら長いシーケンスの効率的な処理を実現します。
Griffin アーキテクチャへの慎重な変更とハイパーパラメータの慎重な調整を通じて、RecurrentGemma モデルは理論上の進歩を実証するだけでなく、実際のアプリケーションにおける効率性と強力な言語処理能力も証明します。
RecurrentGemma-2B の事前トレーニングでは 2 兆のトークンが使用されますが、このデータ量は Gemma-2B で使用される 3 兆のトークンよりも少ないですが、それでも巨大なデータ セットを構成し、モデルに豊富な言語情報を提供します。
事前トレーニングのデータ ソースは主に英語のオンライン ドキュメント、数学、コードです。このデータは幅広いトピックや分野をカバーするだけでなく、不要なコンテンツや安全でないコンテンツを減らし、個人データや機密データを除外するために慎重にフィルタリングおよびクリーニングされます。さらに、評価の公平性を確保するために、すべての評価セットが事前トレーニング データセットから除外されます。
RecurrentGemma-2B は、まず事前トレーニングで大規模な汎用データ混合物を使用し、その後、さらなるトレーニングのために小規模だが高品質のデータセットに移行します。この段階的なトレーニング アプローチは、モデルが幅広いデータで一般的な言語表現を学習し、より特殊なデータを使用してそれを洗練し、最適化するのに役立ちます。
事前トレーニング後、RecurrentGemma-2B は命令チューニングと RLHF アルゴリズムを通じて微調整されました。このプロセスの目的は、モデルが指示に従いやすくなり、高い報酬を伴う応答を生成できるようにモデルを最適化することです。
命令チューニングは、モデルが特定の命令形式を理解して応答できるようにするトレーニング方法です。 RecurrentGemma-2B は、ユーザー入力とモデル出力がそれぞれ異なるタグで識別されるなど、特定の制御タグによって定義される特定の会話形式に従うようにトレーニングされています。
RLHF アルゴリズムは、強化学習フレームワークを通じてモデルの出力を最適化する高度な微調整手法です。 RLHF では、モデルの出力は人間のフィードバックに基づいて評価され、評価結果に基づいて調整されて、出力と報酬の品質が向上します。このアルゴリズムにより、モデルはさまざまなコンテキストでより適切な応答を生成する方法を学習できるようになります。
命令の調整と RLHF の微調整により、RecurrentGemma-2B は高品質の言語出力を生成できるだけでなく、会話や命令に従う際にも優れたパフォーマンスを発揮します。このトレーニング方法によりモデルに柔軟性と適応性が与えられ、モデルがさまざまなアプリケーション シナリオで機能できるようになります。

このようにして、RecurrentGemma-2B は、さまざまなタスクや環境で効率的かつ正確な言語処理を提供できる強力な言語モデルになります。
自動ベンチマークは、RecurrentGemma-2B のパフォーマンスを評価するための最初のステップです。これらのテストは、質問応答、テキストの要約、言語的推論などを含むがこれらに限定されない、さまざまな一般的な下流タスクをカバーします。 これらのタスクにおける RecurrentGemma-2B のパフォーマンスを Gemma-2B と比較すると、RecurrentGemma-2B は少数のトークンでトレーニングされているにもかかわらず、そのパフォーマンスは Gemma-2B に匹敵することが結果からわかります。
MMLU 5 ショット、HellaSwag 0 ショット、PIQA 0 ショットなどの複数の学術ベンチマークにおける RecurrentGemma-2B のパフォーマンスは Gemma-2B と同様であり、さまざまなタスクに対する汎用性と有効性が証明されています。これらのテスト結果は、モデルが言語を深く理解していることを実証するだけでなく、実際のアプリケーションにおけるその可能性も反映しています。

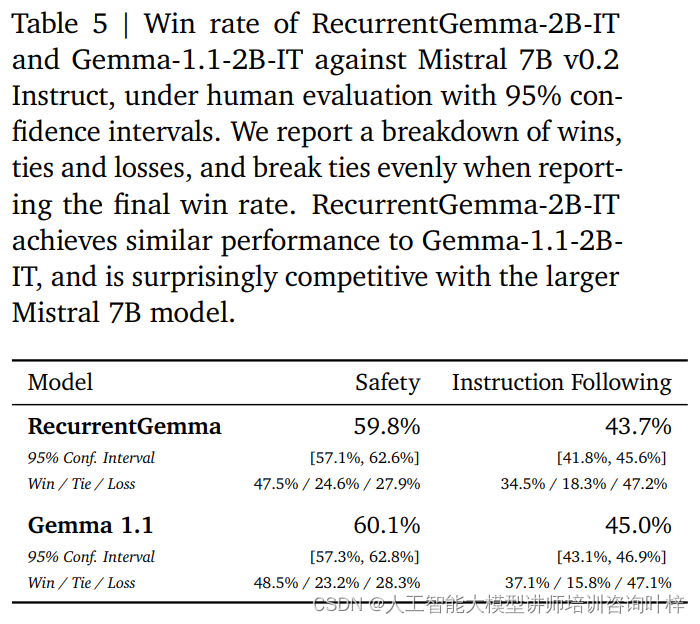
自動ベンチマークに加えて、RecurrentGemma-2B は人間による評価に対してテストされています。人間による評価は、言語モデルが人間の期待に応える応答を生成できるかどうかを評価するための重要なステップです。このプロセスでは、RecurrentGemma-2B の命令調整されたバリアント (RecurrentGemma-2B-IT) が Mistral 7B v0.2 Instruct モデルと比較されました。
人間による評価では、クリエイティブな執筆やコーディングのタスクに従うべき約 1,000 の指示のコレクションが使用されます。 RecurrentGemma-2B-IT はこのセットで印象的なパフォーマンスを示し、勝率 43.7% を達成しましたが、Gemma-1.1-2B-IT の 45.0% よりわずかに低いだけです。この結果は、RecurrentGemma-2B の複雑な命令を理解して実行する能力が既存の高度なモデルと同等であることを示しています。
RecurrentGemma-2B-IT は、基本的なセキュリティ プロトコルをテストする約 400 個のプロンプトのコレクションでも評価され、59.8% の勝率を達成し、セキュリティ ガイドラインに従う点でこのモデルの優位性が実証されました。
RecurrentGemma-2B のパフォーマンスは、自動ベンチマークと人間による評価を組み合わせて包括的にテストされました。自動テストでは、さまざまな言語タスクにおけるモデルのパフォーマンスの定量的評価が提供され、人間による評価では、モデルの出力の品質の定性的理解が提供されます。この包括的な評価アプローチにより、RecurrentGemma-2B は理論的に優れたパフォーマンスを発揮するだけでなく、実際のアプリケーションでも高品質の言語生成と理解が実現します。
推論速度は、特に長いシーケンス データを扱う場合、言語モデルの有用性を測定するための重要な指標の 1 つです。 RecurrentGemma-2B の推論速度の最適化は、従来の Transformer モデルとは異なるハイライトです。従来の Transformer モデルでは、効率的なシーケンス処理のために、モデルはキー/値 (KV) キャッシュを取得してデバイス メモリにロードする必要があります。シーケンスの長さが増加すると、KV キャッシュのサイズも直線的に増加します。これにより、メモリ使用量が増加するだけでなく、長いシーケンスを処理するモデルの能力も制限されます。キャッシュのサイズはローカル アテンション メカニズムによって削減できますが、通常はパフォーマンスがある程度犠牲になります。
RecurrentGemma-2B は、革新的なアーキテクチャ設計により上記の問題を解決します。シーケンスの長さに応じて増大する KV キャッシュに依存するのではなく、入力シーケンスを固定サイズの状態に圧縮します。この設計により、メモリ使用量が大幅に削減され、モデルが長いシーケンスを処理する際に効率的な推論速度を維持できるようになります。
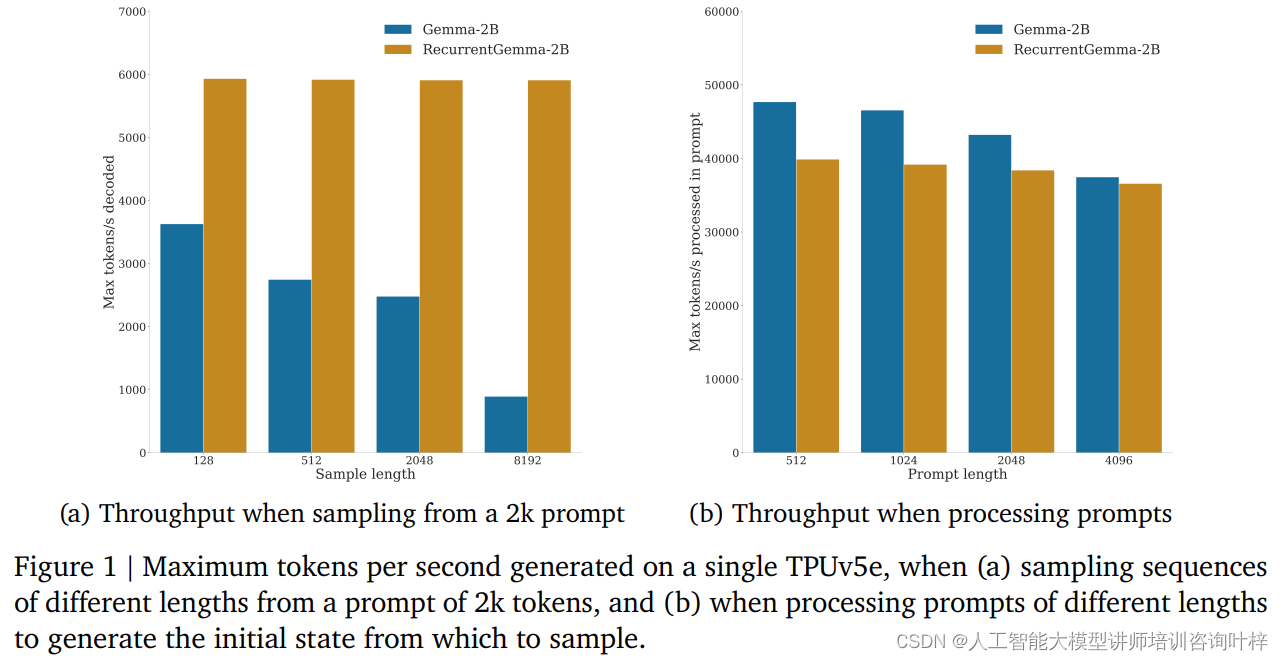
ベンチマーク テストでは、RecurrentGemma-2B がスループットの大幅な利点を実証しました。図 1a に示すように、単一の TPUv5e デバイス上で、RecurrentGemma-2B は、2,000 トークンのヒントからさまざまな長さのシーケンスをサンプリングするときに、1 秒あたり最大 6,000 トークンのスループットを達成できますが、キャッシュの増大に伴って Gemma モデルも増大します。スループットが低下します。
RecurrentGemma-2B の固定状態サイズは、効率的な推論の鍵となります。 Gemma モデルと比較すると、RecurrentGemma-2B の状態はシーケンスの長さとともに増加しません。これは、ホスト メモリ サイズの制限を受けることなく、任意の長さのシーケンスを生成できることを意味します。これは、モデルが高いパフォーマンスを維持しながら長いテキスト データを処理できるようになるため、長いシーケンスの処理において特に重要です。
推論速度の向上は理論的に大きな意味を持つだけでなく、実際の応用でもその価値を発揮します。モバイル デバイスやエッジ コンピューティング デバイスなど、リソースに制約のある環境では、RecurrentGemma-2B の高いスループットと低いメモリ フットプリントにより、理想的な選択肢となります。さらに、効率的な推論速度により、モデルがユーザーのリクエストに迅速に応答し、よりスムーズなインタラクティブ エクスペリエンスを提供できるようになります。
人工知能の分野では、モデルの展開はテクノロジーの実現だけでなく、安全性と倫理的責任も負うことになります。 RecurrentGemma-2B の導入戦略には、これらの重要な要素の重点が完全に反映されています。
モデルの展開に先立って、RecurrentGemma-2B は、モデルからの不正行為やバイアスの可能性を評価するために設計された一連の標準的な学術セキュリティ ベンチマークを受けました。これらのテストを通じて、開発チームは潜在的なリスクを特定して軽減し、モデルが公共の使用に対して安全であることを確認できます。

自動化されたセキュリティ ベンチマークに加えて、RecurrentGemma-2B は独立したチームによる倫理とセキュリティの評価を受けました。このプロセスには、特定のグループに対する公平性、有害な出力を回避する機能、ユーザーのプライバシーの保護など、モデルの包括的なレビューが含まれます。
厳密なテストと評価にもかかわらず、開発チームは、RecurrentGemma-2B がさまざまなシナリオに適用される可能性があることを考慮すると、考えられるすべてのユースケースをカバーすることは不可能であることを強調しています。したがって、モデルを展開する前に、すべてのユーザーが特定のユースケースに基づいて追加のセキュリティ テストを実行することを推奨しています。この推奨事項は、各展開がよく考えられ、カスタマイズされていることを確認するというユーザーの責任を重視していることを反映しています。
責任ある展開には、モデルのパフォーマンスと制限に関する透明性も含まれます。開発チームは、ユーザーや研究者がモデルの仕組みと潜在的な制限を理解できるように、詳細なモデル アーキテクチャとトレーニングの詳細を提供します。さらに、チームは新たなリスクと課題に対処するためにモデルの継続的なモニタリングと改善に取り組んでいます。
責任ある導入には、より広範な AI コミュニティや複数の関係者とのコラボレーションも含まれます。 RecurrentGemma の開発チームは、研究結果を共有し、オープンなディスカッションに参加し、外部フィードバックを受け入れることによって、オープン サイエンスとコラボレーションへの取り組みを示しています。
人工知能の分野が拡大し続ける中、RecurrentGemma は革新的なアーキテクチャ設計コンセプト、厳格なトレーニングおよび評価プロセスを組み合わせたモデルとして機能し、言語の理解と生成において可能なことの限界を押し広げる可能性を実証しています。
論文リンク: https://arxiv.org/abs/2404.07839

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: