2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Nykyään tekoälyn nopean kehityksen myötä tehokkaiden ja erinomaisten kielimallien tavoittelu on saanut Google DeepMind -tiimin kehittämään läpimurtomallin RecurrentGemma. Tämä uusi malli, joka on kuvattu yksityiskohtaisesti julkaisussa "RecurrentGemma: Efficient Open Language Models Beyond Transformers", lupaa määritellä uudelleen kielenkäsittelyn standardit yhdistämällä lineaarisen rekursion ja paikalliset huomiomekanismit.
RecurrentGemma-mallin arkkitehtuuri on sen tehokkaan suorituskyvyn ydin. Se perustuu Google DeepMindin ehdottamaan Griffin-arkkitehtuuriin. Tämä arkkitehtuuri tarjoaa uusia mahdollisuuksia kielitehtävien käsittelyyn yhdistämällä lineaarisen rekursion ja paikalliset huomiomekanismit. Sukeltaessamme RecurrentGemman malliarkkitehtuuriin meidän on ensin ymmärrettävä Griffin-arkkitehtuurin perusta ja kuinka RecurrentGemma innovoi ja optimoi sen pohjalta.
RecurrentGemma tekee keskeisen muokkauksen Griffin-arkkitehtuuriin, joka sisältää syötteiden upotusten käsittelyn. Mallin syöte upotus kerrotaan vakiolla, joka on yhtä suuri kuin mallin leveyden neliöjuuri. Tämä käsittely säätää mallin syöttöpuolta, mutta ei muuta lähtöpuolta, koska tulosteen upottaminen ei käytä tätä kerroin. Tämän säädön avulla malli pystyy käsittelemään tietoja tehokkaammin säilyttäen samalla johdonmukaisuuden mallien leveydellä. Tällä modifikaatiolla on tärkeä rooli mallin matemaattisessa ilmaisussa ja tiedonkulussa. Se ei ainoastaan optimoi mallin syöttötietojen alkukäsittelyä, vaan myös auttaa mallia paremmin sieppaamaan ja esittämään kielen ominaisuuksia säätämällä upotuksen mittakaavaa.
RecurrentGemma-mallin suorituskyky ja tehokkuus määräytyvät suurelta osin sen hyperparametrien perusteella. Nämä hyperparametrit ovat keskeinen osa mallin määritelmää, ja ne sisältävät, mutta eivät rajoitu, seuraavat näkökohdat:
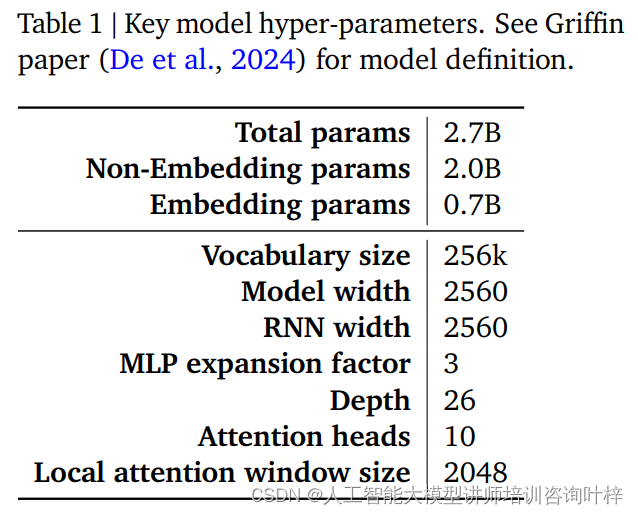
Taulukossa 1 on yhteenveto näistä keskeisistä hyperparametreistä, ja yksityiskohtaisempi mallin määritelmä löytyy De et al.:n Griffin-paperista. Yhdessä nämä hyperparametrit muodostavat perustan RecurrentGemma-mallille, mikä mahdollistaa pitkien sekvenssien tehokkaan käsittelyn säilyttäen samalla pienen muistin jalanjäljen.
Griffin-arkkitehtuuriin tehtyjen huolellisten muutosten ja hyperparametrien huolellisen säädön avulla RecurrentGemma-malli ei ainoastaan osoita edistymistään teoriassa, vaan myös todistaa tehokkuutensa ja tehokkaat kielenkäsittelykykynsä käytännön sovelluksissa.
RecurrentGemma-2B:n esikoulutus käyttää 2 biljoonaa merkkiä. Vaikka tämä tietomäärä on pienempi kuin Gemma-2B:n käyttämät 3 biljoonaa merkkiä, se muodostaa silti valtavan tietojoukon ja tarjoaa runsaasti kielitietoa mallille.
Esikoulutuksen tietolähteet ovat pääasiassa englanninkielisiä verkkodokumentteja, matematiikkaa ja koodeja. Nämä tiedot kattavat laajan valikoiman aiheita ja alueita, mutta ne myös suodatetaan ja puhdistetaan huolellisesti ei-toivotun tai vaarallisen sisällön vähentämiseksi ja henkilökohtaisten tai arkaluonteisten tietojen poistamiseksi. Lisäksi arvioinnin oikeudenmukaisuuden varmistamiseksi kaikki arviointisarjat jätetään pois koulutusta edeltävästä tietojoukosta.
RecurrentGemma-2B käyttää ensin suurta yleistä dataseosta esikoulutuksessa ja siirtyy sitten pienempiin, mutta laadukkaampiin tietokokonaisuuksiin jatkokoulutusta varten. Tämä vaiheittainen harjoittelutapa auttaa mallia oppimaan yleisen kielen esityksen laajalle valikoimalle dataa ja sitten tarkentamaan ja optimoimaan sitä erikoistuneemmilla tiedoilla.
Esiharjoittelun jälkeen RecurrentGemma-2B hienosäädettiin ohjevirityksen ja RLHF-algoritmin avulla. Tämän prosessin tavoitteena on optimoida malli, jotta se voi paremmin noudattaa ohjeita ja tuottaa vastauksia korkealla palkkiolla.
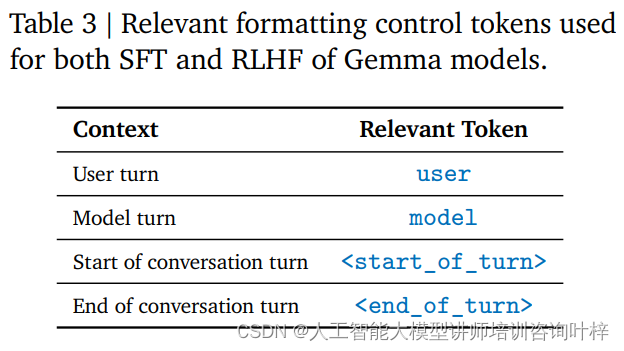
Ohjeen viritys on koulutusmenetelmä, jonka avulla malli pystyy ymmärtämään tiettyä ohjemuotoa ja reagoimaan siihen. RecurrentGemma-2B on koulutettu noudattamaan tiettyä keskustelumuotoa, joka on määritelty erityisillä ohjaustunnisteilla, kuten käyttäjän syötteet ja mallin tuotokset tunnistetaan eri tunnisteilla.
RLHF-algoritmi on edistynyt hienosäätötekniikka, joka optimoi mallin tulostuksen vahvistusoppimiskehyksen avulla. RLHF:ssä mallin tuotto arvioidaan ihmisten palautteen perusteella ja mukautetaan arvioinnin tulosten perusteella tuotoksen ja palkkioiden laadun parantamiseksi. Tämän algoritmin avulla malli oppii luomaan sopivampia vastauksia eri yhteyksissä.
Ohjeiden säädön ja RLHF-hienosäädön ansiosta RecurrentGemma-2B ei ainoastaan pysty tuottamaan korkealaatuista kielitulostusta, vaan toimii myös hyvin keskustelussa ja ohjeiden noudattamisessa. Tämä koulutusmenetelmä tarjoaa mallille joustavuutta ja mukautumiskykyä, mikä mahdollistaa sen toiminnan useissa sovellusskenaarioissa.

Tällä tavalla RecurrentGemma-2B:stä tulee tehokas kielimalli, joka pystyy tarjoamaan tehokkaan ja tarkan kielenkäsittelyn erilaisissa tehtävissä ja ympäristöissä.
Automaattinen benchmarking on ensimmäinen askel RecurrentGemma-2B:n suorituskyvyn arvioinnissa. Nämä testit kattavat useita suosittuja loppupään tehtäviä, mukaan lukien mutta ei rajoittuen kysymyksiin vastaaminen, tekstin yhteenveto, kielellinen päättely ja paljon muuta. RecurrentGemma-2B:n suorituskykyä näissä tehtävissä verrataan Gemma-2B:hen, ja tulokset osoittavat, että vaikka RecurrentGemma-2B:tä on koulutettu pienemmällä määrällä tokeneita, sen suorituskyky on verrattavissa Gemma-2B:hen.
RecurrentGemma-2B:n suorituskyky useissa akateemisissa benchmarkissa, kuten MMLU 5-shot, HellaSwag 0-shot, PIQA 0-shot jne., on samanlainen kuin Gemma-2B, joka todistaa sen monipuolisuuden ja tehokkuuden erilaisissa tehtävissä. Nämä testitulokset eivät ainoastaan osoita mallin syvällistä kielen ymmärtämistä, vaan myös heijastavat sen potentiaalia käytännön sovelluksissa.

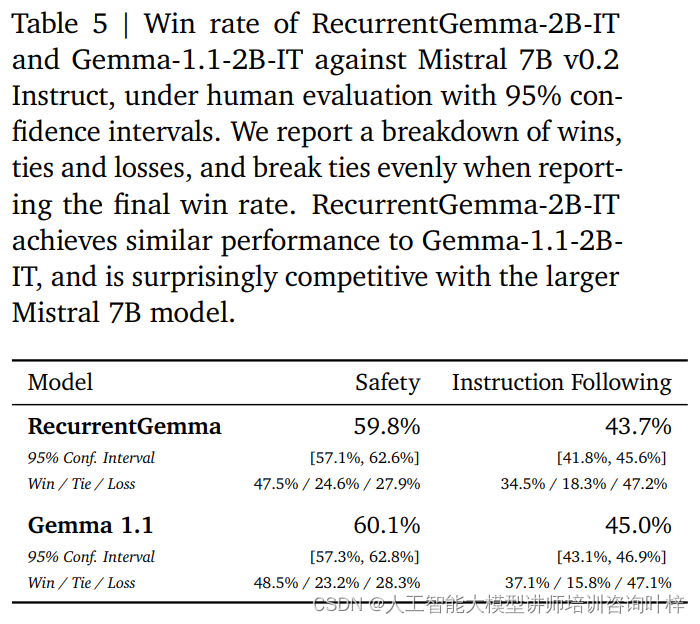
Automaattisten vertailuarvojen lisäksi RecurrentGemma-2B on testattu ihmisen arvioinnissa. Ihmisten arviointi on kriittinen vaihe arvioitaessa, voiko kielimalli tuottaa vastauksia, jotka vastaavat ihmisten odotuksia. Tässä prosessissa RecurrentGemma-2B:n (RecurrentGemma-2B-IT) käskyviritettyä varianttia verrattiin Mistral 7B v0.2 Instruct -malliin.
Ihmisarvioinnit käyttävät noin 1 000 ohjeen kokoelmaa, joita noudatetaan luovissa kirjoitus- ja koodaustehtävissä. RecurrentGemma-2B-IT suoriutui vaikuttavasti tässä sarjassa ja saavutti 43,7 %:n voittoprosentin, joka on vain hieman pienempi kuin Gemma-1.1-2B-IT:n 45,0 %. Tämä tulos osoittaa, että RecurrentGemma-2B:n kyky ymmärtää ja suorittaa monimutkaisia käskyjä on verrattavissa olemassa oleviin kehittyneisiin malleihin.
RecurrentGemma-2B-IT arvioitiin myös noin 400 kehotteen kokoelmalla, jossa testattiin perustietoturvaprotokollia ja saavutettiin 59,8 %:n voittoprosentti, mikä osoittaa mallin paremman turvallisuusohjeiden noudattamisen.
RecurrentGemma-2B:n suorituskyky testattiin kattavasti automaattisten vertailuarvojen ja ihmisen arvioinnin yhdistelmällä. Automaattinen testaus antaa kvantitatiivisen arvion mallin suorituskyvystä erilaisissa kielitehtävissä, kun taas ihmisen arviointi tarjoaa laadullisen käsityksen mallin tuotoksen laadusta. Tämä kattava arviointimenetelmä varmistaa, että RecurrentGemma-2B ei toimi vain hyvin teoriassa, vaan tarjoaa myös korkealaatuista kielentuotantoa ja ymmärrystä käytännön sovelluksissa.
Päätelmänopeus on yksi tärkeimmistä mittareista kielimallin hyödyllisyyden mittaamiseksi, etenkin kun käsitellään pitkiä jaksotietoja. RecurrentGemma-2B:n päättelynopeuden optimointi on kohokohta, joka erottaa sen perinteisestä Transformer-mallista. Perinteisessä Transformer-mallissa tehokkaan sekvenssikäsittelyn vuoksi mallin on noudettava ja ladattava avainarvo-välimuisti (KV) laitteen muistiin. Sekvenssin pituuden kasvaessa myös KV-välimuistin koko kasvaa lineaarisesti, mikä ei ainoastaan lisää muistin käyttöä, vaan myös rajoittaa mallin kykyä käsitellä pitkiä sekvenssejä. Vaikka välimuistin kokoa voidaan pienentää paikallisten huomiomekanismien avulla, tämä tapahtuu yleensä jonkin verran suorituskyvyn kustannuksella.
RecurrentGemma-2B ratkaisee yllä mainitut ongelmat innovatiivisella arkkitehtonisella suunnittelullaan. Se pakkaa syöttösekvenssin kiinteän kokoiseen tilaan sen sijaan, että luottaisi KV-välimuistiin, joka kasvaa sekvenssin pituuden mukana. Tämä muotoilu vähentää merkittävästi muistin käyttöä ja mahdollistaa mallin ylläpitävän tehokkaan päättelynopeuden pitkiä sarjoja käsiteltäessä.
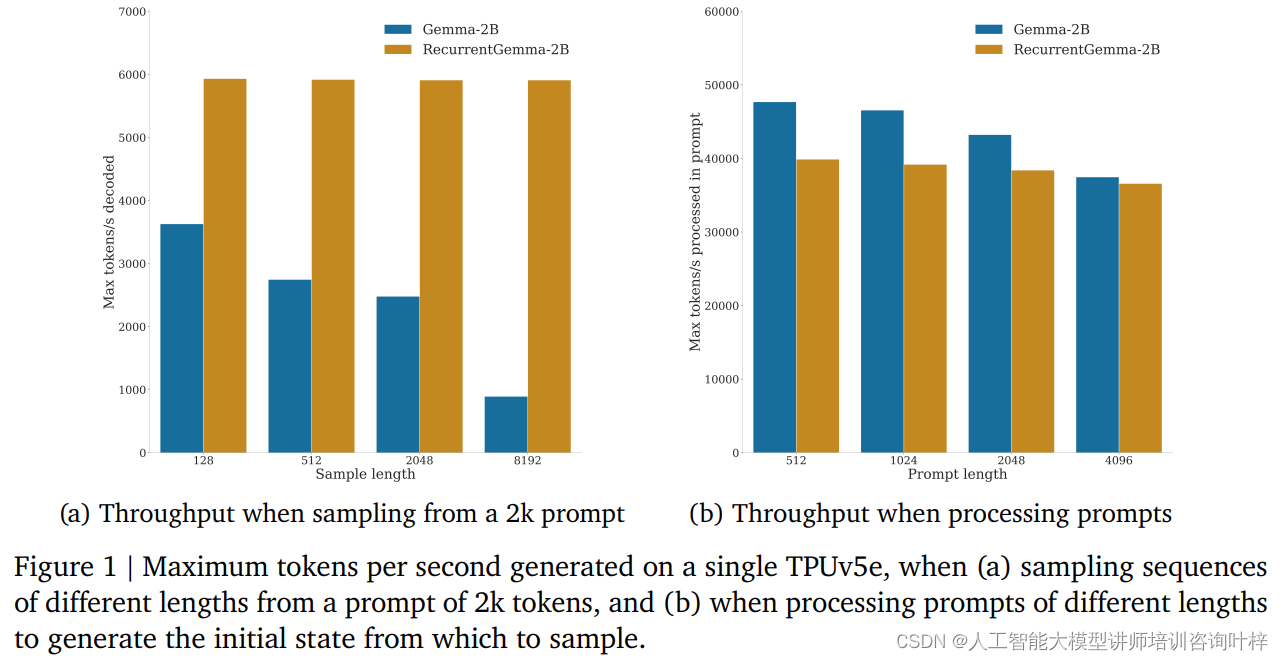
Vertailutesteissä RecurrentGemma-2B osoitti merkittäviä suorituskykyetuja. Kuten kuvasta 1a näkyy, yhdellä TPUv5e-laitteella RecurrentGemma-2B pystyy saavuttamaan jopa 6 000 tokenin sekuntinopeuden, kun se ottaa eripituisia sekvenssejä 2 000 tokenin vihjeestä, kun taas Gemma-malli kasvaa välimuistin kasvaessa. Suorituskyky pienenee.
RecurrentGemma-2B:n kiinteä tilakoko on avain sen tehokkaaseen päättelyyn. Verrattuna Gemma-malliin RecurrentGemma-2B:n tila ei kasva sekvenssin pituuden mukana, mikä tarkoittaa, että se voi tuottaa minkä tahansa pituisia sekvenssejä ilman isäntämuistin koon rajoittamista. Tämä on erityisen tärkeää pitkän sekvenssin käsittelyssä, koska sen avulla malli voi käsitellä pidempää tekstidataa säilyttäen samalla korkean suorituskyvyn.
Päättelynopeuden parantaminen ei ole vain teoriassa suuri merkitys, vaan se osoittaa sen arvon myös käytännön sovelluksissa. RecurrentGemma-2B:n suuri suorituskyky ja pieni muistitila tekevät siitä ihanteellisen valinnan resurssirajoitteisissa ympäristöissä, kuten mobiililaitteissa tai reunalaskentalaitteissa. Lisäksi tehokas päättelynopeus mahdollistaa myös sen, että malli vastaa käyttäjien pyyntöihin nopeammin ja tarjoaa sujuvamman interaktiivisen kokemuksen.
Tekoälyn alalla mallien käyttöönotto ei ole vain teknologian toteuttamista, vaan myös turvallisuuden ja eettisten vastuiden ottamista. RecurrentGemma-2B:n käyttöönottostrategia heijastaa täysin näiden avaintekijöiden painotusta.
Ennen mallin käyttöönottoa RecurrentGemma-2B:lle tehtiin sarja standardeja akateemisia tietoturvatestejä, jotka on suunniteltu arvioimaan mallin mahdollisia väärinkäytöksiä tai harhaa. Näiden testien avulla kehitystiimi pystyy tunnistamaan ja vähentämään mahdollisia riskejä varmistaen, että malli on turvallinen julkiseen käyttöön.

Automaattisen tietoturva-benchmarkingin lisäksi RecurrentGemma-2B kävi läpi eettisen ja turvallisuusarvioinnin riippumattoman tiimin toimesta. Tämä prosessi sisältää mallin kattavan tarkastelun, mukaan lukien, mutta ei rajoittuen, sen oikeudenmukaisuus tiettyjä ryhmiä kohtaan, sen kyky välttää haitallisia tuloksia ja sen käyttäjien yksityisyyden suoja.
Tiukasta testauksesta ja arvioinnista huolimatta kehitystiimi korostaa, että kaikkia mahdollisia käyttötapauksia on mahdotonta kattaa, koska RecurrentGemma-2B:tä voidaan soveltaa monissa eri skenaarioissa. Siksi he suosittelevat, että kaikki käyttäjät suorittavat lisätietoturvatestauksen omien käyttötapaustensa perusteella ennen mallien käyttöönottoa. Tämä suositus kuvastaa käyttäjien vastuun painottamista sen varmistamiseksi, että jokainen käyttöönotto on hyvin harkittu ja räätälöity.
Vastuullinen käyttöönotto sisältää myös läpinäkyvyyden mallin suorituskyvystä ja rajoituksista. Kehitystiimi tarjoaa yksityiskohtaista malliarkkitehtuuria ja koulutusyksityiskohtia, jotta käyttäjät ja tutkijat ymmärtävät mallin toimivuuden ja mahdolliset rajoitukset. Lisäksi tiimi on sitoutunut jatkuvaan seurantaan ja mallin parantamiseen uusiin riskeihin ja haasteisiin vastaamiseksi.
Vastuullinen käyttöönotto edellyttää myös yhteistyötä laajemman tekoälyyhteisön ja useiden sidosryhmien kanssa. Jakamalla tutkimustuloksia, käymällä avointa keskustelua ja ottamalla vastaan ulkopuolista palautetta RecurrentGemman kehitystiimi osoittaa sitoutumisensa avoimeen tieteeseen ja yhteistyöhön.
Tekoälyn alan laajentuessa edelleen, RecurrentGemma toimii mallina, jossa yhdistyvät innovatiiviset arkkitehtoniset suunnittelukonseptit, tiukat koulutus- ja arviointiprosessit, mikä osoittaa potentiaalin ylittää kielten ymmärtämisen ja sukupolven rajoja.
Paperilinkki: https://arxiv.org/abs/2404.07839

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten
