minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Hoje, com o rápido desenvolvimento da inteligência artificial, a busca por modelos de linguagem eficientes e excelentes levou a equipe do Google DeepMind a desenvolver o modelo inovador RecurrentGemma. Este novo modelo, detalhado no artigo "RecurrentGemma: Efficient Open Language Models Beyond Transformers", promete redefinir os padrões de processamento de linguagem, combinando recursão linear e mecanismos de atenção local.
A arquitetura do modelo RecurrentGemma é o núcleo de seu desempenho eficiente. É baseada na arquitetura Griffin proposta pelo Google DeepMind. Esta arquitetura oferece novas possibilidades para o processamento de tarefas de linguagem, combinando recursão linear e mecanismos de atenção local. Ao nos aprofundarmos na arquitetura do modelo RecurrentGemma, primeiro precisamos entender a base da arquitetura Griffin e como o RecurrentGemma inova e otimiza com base nela.
RecurrentGemma faz uma modificação importante na arquitetura Griffin, que envolve o processamento de incorporações de entrada. A incorporação de entrada do modelo é multiplicada por uma constante igual à raiz quadrada da largura do modelo. Este tratamento ajusta o lado de entrada do modelo, mas não altera o lado de saída porque a incorporação de saída não aplica este fator de multiplicação. Esse ajuste permite que o modelo processe informações com mais eficiência, mantendo a consistência entre as larguras do modelo. Esta modificação desempenha um papel importante na expressão matemática e no fluxo de informações do modelo. Ele não apenas otimiza o processamento inicial dos dados de entrada do modelo, mas também ajuda o modelo a capturar e representar melhor as características da linguagem, ajustando a escala da incorporação.
O desempenho e a eficiência de um modelo RecurrentGemma são amplamente determinados por seus hiperparâmetros. Esses hiperparâmetros são uma parte fundamental da definição do modelo e incluem, mas não estão limitados aos seguintes aspectos:
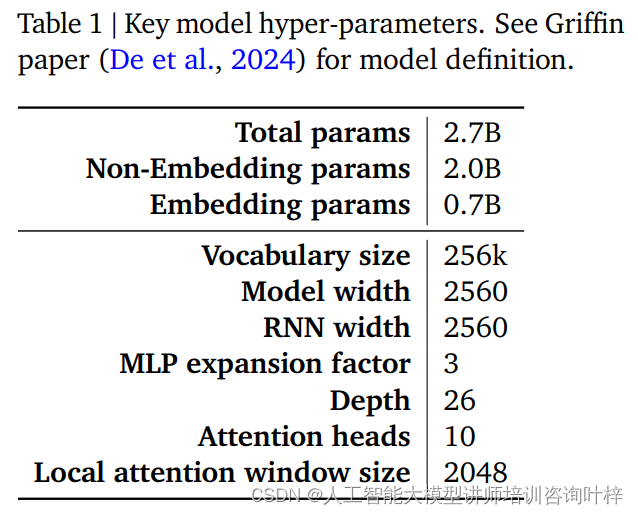
A Tabela 1 fornece um resumo desses hiperparâmetros principais, e uma definição mais detalhada do modelo pode ser encontrada no artigo Griffin de De et al. Juntos, esses hiperparâmetros formam a base do modelo RecurrentGemma, permitindo obter processamento eficiente de sequências longas, mantendo um pequeno consumo de memória.
Através de modificações cuidadosas na arquitetura Griffin e ajustes cuidadosos de hiperparâmetros, o modelo RecurrentGemma não apenas demonstra seu avanço na teoria, mas também prova sua eficiência e poderosas capacidades de processamento de linguagem em aplicações práticas.
O pré-treinamento do RecurrentGemma-2B usa 2 trilhões de tokens. Embora essa quantidade de dados seja menor que os 3 trilhões de tokens usados pelo Gemma-2B, ainda constitui um enorme conjunto de dados e fornece informações de linguagem ricas para o modelo.
As fontes de dados para a pré-formação são principalmente documentos online em inglês, matemática e códigos. Esses dados não apenas cobrem uma ampla variedade de tópicos e áreas, mas também são cuidadosamente filtrados e limpos para reduzir conteúdo indesejado ou inseguro e excluir dados pessoais ou confidenciais. Além disso, para garantir a imparcialidade da avaliação, todos os conjuntos de avaliação são excluídos do conjunto de dados pré-formação.
O RecurrentGemma-2B primeiro usa uma grande mistura de dados genéricos no pré-treinamento e, em seguida, passa para conjuntos de dados menores, mas de maior qualidade, para treinamento adicional. Essa abordagem de treinamento em etapas ajuda o modelo a aprender uma representação de linguagem geral em uma ampla variedade de dados e, em seguida, refiná-la e otimizá-la com dados mais especializados.
Após o pré-treinamento, o RecurrentGemma-2B foi ajustado por meio do ajuste de instruções e do algoritmo RLHF. Este processo visa otimizar o modelo para que ele siga melhor as instruções e gere respostas com altas recompensas.
O ajuste de instrução é um método de treinamento que permite que um modelo compreenda e responda a um formato de instrução específico. RecurrentGemma-2B é treinado para aderir a um formato de conversa específico, que é definido por tags de controle específicas, como entrada do usuário e saída do modelo, cada uma identificada com tags diferentes.
O algoritmo RLHF é uma técnica avançada de ajuste fino que otimiza a saída do modelo por meio de uma estrutura de aprendizagem por reforço. No RLHF, o resultado do modelo é avaliado com base no feedback humano e ajustado com base nos resultados da avaliação para melhorar a qualidade do resultado e das recompensas. Este algoritmo permite que o modelo aprenda como gerar respostas mais adequadas em diferentes contextos.
Através do ajuste de instruções e do ajuste fino de RLHF, o RecurrentGemma-2B não só é capaz de produzir resultados de linguagem de alta qualidade, mas também tem um bom desempenho na conversação e no seguimento de instruções. Este método de treinamento fornece flexibilidade e adaptabilidade ao modelo, permitindo que ele funcione em uma variedade de cenários de aplicação.
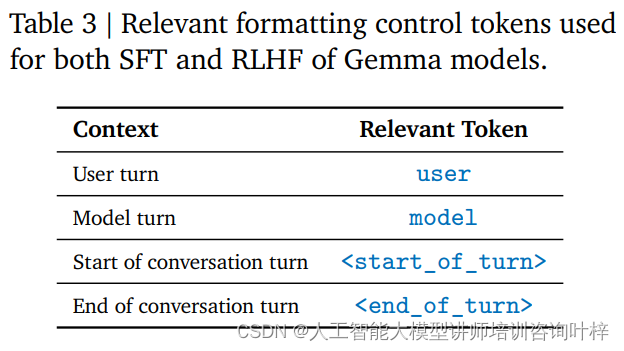

Desta forma, o RecurrentGemma-2B se torna um poderoso modelo de linguagem capaz de fornecer processamento de linguagem eficiente e preciso em uma variedade de tarefas e ambientes.
O benchmarking automatizado é o primeiro passo na avaliação do desempenho do RecurrentGemma-2B. Esses testes cobrem uma variedade de tarefas posteriores populares, incluindo, entre outras, resposta a perguntas, resumo de texto, raciocínio linguístico e muito mais. O desempenho do RecurrentGemma-2B nessas tarefas é comparado ao do Gemma-2B, e os resultados mostram que, embora o RecurrentGemma-2B seja treinado em um número menor de tokens, seu desempenho é comparável ao do Gemma-2B.
O desempenho do RecurrentGemma-2B em vários benchmarks acadêmicos, como MMLU 5-shot, HellaSwag 0-shot, PIQA 0-shot, etc. é semelhante ao Gemma-2B, o que comprova sua versatilidade e eficácia em diferentes tarefas. Os resultados dos testes não apenas demonstram o profundo conhecimento da linguagem do modelo, mas também refletem seu potencial em aplicações práticas.

Além de benchmarks automatizados, o RecurrentGemma-2B foi testado contra avaliação humana. A avaliação humana é uma etapa crítica para avaliar se um modelo de linguagem pode gerar respostas que atendam às expectativas humanas. Neste processo, uma variante ajustada por instrução do RecurrentGemma-2B (RecurrentGemma-2B-IT) foi comparada com o modelo Mistral 7B v0.2 Instruct.
As avaliações humanas usam uma coleção de aproximadamente 1.000 instruções a serem seguidas para tarefas criativas de escrita e codificação. RecurrentGemma-2B-IT teve um desempenho impressionante neste conjunto, alcançando uma taxa de vitória de 43,7%, apenas um pouco inferior aos 45,0% de Gemma-1.1-2B-IT. Este resultado demonstra que a capacidade do RecurrentGemma-2B de compreender e executar instruções complexas é comparável aos modelos avançados existentes.
O RecurrentGemma-2B-IT também foi avaliado em uma coleção de aproximadamente 400 prompts testando protocolos básicos de segurança, alcançando uma taxa de vitória de 59,8%, demonstrando a superioridade do modelo em seguir as diretrizes de segurança.
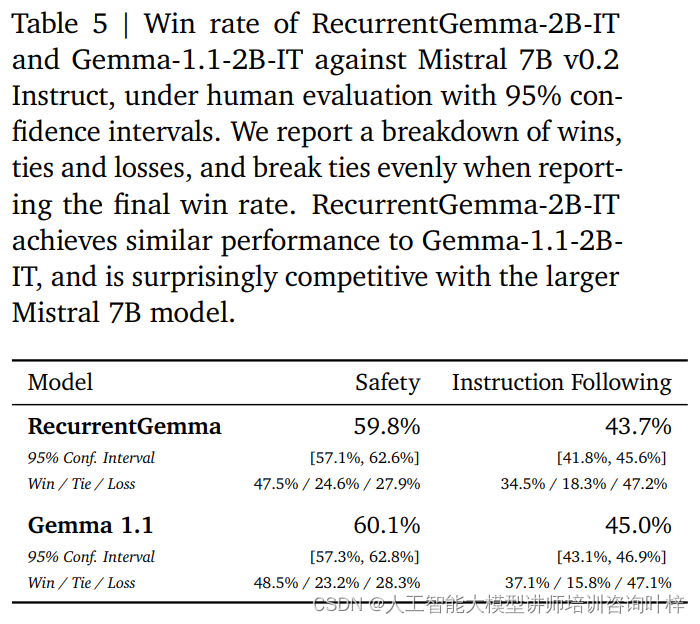
O desempenho do RecurrentGemma-2B foi exaustivamente testado por meio de uma combinação de benchmarks automatizados e avaliação humana. Os testes automatizados fornecem uma avaliação quantitativa do desempenho do modelo em diversas tarefas linguísticas, enquanto a avaliação humana fornece uma compreensão qualitativa da qualidade do resultado do modelo. Esta abordagem de avaliação abrangente garante que o RecurrentGemma-2B não apenas tenha um bom desempenho na teoria, mas também forneça geração e compreensão de linguagem de alta qualidade em aplicações práticas.
A velocidade de inferência é uma das principais métricas para medir a utilidade de um modelo de linguagem, especialmente quando se trata de dados de sequência longa. A otimização da velocidade de inferência do RecurrentGemma-2B é um destaque que o diferencia do modelo tradicional do Transformer. No modelo tradicional do Transformer, para um processamento de sequência eficiente, o modelo precisa recuperar e carregar o cache de valor-chave (KV) na memória do dispositivo. À medida que o comprimento da sequência aumenta, o tamanho do cache KV também aumentará linearmente, o que não apenas aumenta o uso de memória, mas também limita a capacidade do modelo de lidar com sequências longas. Embora o tamanho do cache possa ser reduzido por meio de mecanismos de atenção local, isso geralmente ocorre às custas de algum desempenho.
RecurrentGemma-2B resolve os problemas acima através de seu design arquitetônico inovador. Ele comprime a sequência de entrada em um estado de tamanho fixo, em vez de depender de um cache KV que cresce com o comprimento da sequência. Esse design reduz significativamente o uso de memória e permite que o modelo mantenha uma velocidade de inferência eficiente ao processar sequências longas.
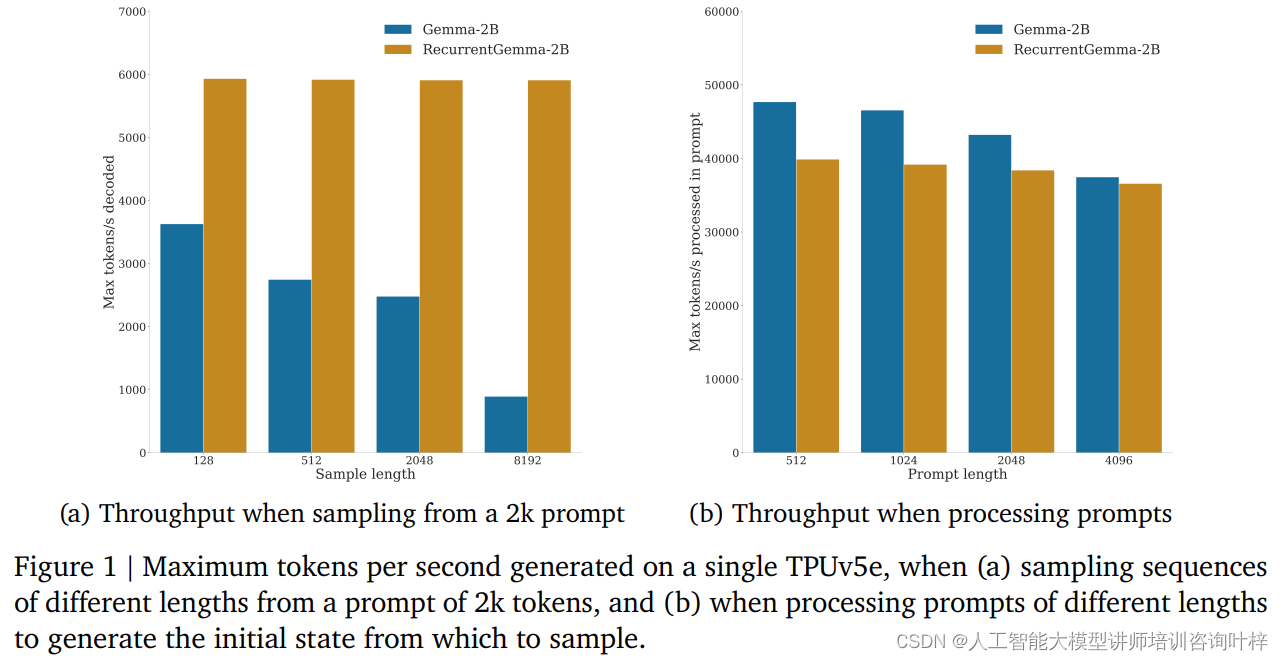
Em testes de benchmark, o RecurrentGemma-2B demonstrou vantagens significativas de rendimento. Conforme mostrado na Figura 1a, em um único dispositivo TPUv5e, o RecurrentGemma-2B é capaz de atingir uma taxa de transferência de até 6 mil tokens por segundo ao amostrar sequências de diferentes comprimentos a partir de uma sugestão de 2 mil tokens, enquanto o modelo Gemma cresce à medida que o cache cresce. A produtividade diminui.
O tamanho fixo do estado do RecurrentGemma-2B é fundamental para sua inferência eficiente. Comparado com o modelo Gemma, o estado do RecurrentGemma-2B não cresce com o comprimento da sequência, o que significa que ele pode gerar sequências de qualquer comprimento sem ser limitado pelo tamanho da memória do host. Isto é particularmente importante no processamento de sequências longas, pois permite que o modelo processe dados de texto mais longos, mantendo ao mesmo tempo um alto desempenho.
A melhoria na velocidade de raciocínio não é apenas de grande importância na teoria, mas também mostra o seu valor em aplicações práticas. Em ambientes com recursos limitados, como dispositivos móveis ou dispositivos de computação de ponta, o alto rendimento e o baixo consumo de memória do RecurrentGemma-2B o tornam a escolha ideal. Além disso, a velocidade de inferência eficiente também permite que o modelo responda às solicitações do usuário com mais rapidez e forneça uma experiência interativa mais suave.
No campo da inteligência artificial, a implantação de modelos não é apenas a realização da tecnologia, mas também a assunção de responsabilidades éticas e de segurança. A estratégia de implantação do RecurrentGemma-2B reflete plenamente a ênfase nestes fatores-chave.
Antes da implantação do modelo, o RecurrentGemma-2B foi submetido a uma série de benchmarks de segurança acadêmica padrão projetados para avaliar possível má conduta ou preconceito do modelo. Por meio desses testes, a equipe de desenvolvimento consegue identificar e mitigar riscos potenciais, garantindo que o modelo seja seguro para uso público.

Além do benchmarking de segurança automatizado, o RecurrentGemma-2B passou por uma avaliação de ética e segurança por uma equipe independente. Este processo envolve uma revisão abrangente do modelo, incluindo, entre outros, a sua justiça para grupos específicos, a sua capacidade de evitar resultados prejudiciais e a proteção da privacidade do utilizador.
Apesar dos rigorosos testes e avaliações, a equipe de desenvolvimento enfatiza que é impossível cobrir todos os casos de uso possíveis, considerando que o RecurrentGemma-2B pode ser aplicado em muitos cenários diferentes. Portanto, eles recomendam que todos os usuários realizem testes de segurança adicionais com base em seus casos de uso específicos antes de implantar modelos. Esta recomendação reflete a ênfase na responsabilidade do usuário para garantir que cada implantação seja bem pensada e personalizada.
A implantação responsável também inclui transparência sobre o desempenho e as limitações do modelo. A equipe de desenvolvimento fornece arquitetura detalhada do modelo e detalhes de treinamento para permitir que usuários e pesquisadores entendam como o modelo funciona e possíveis limitações. Além disso, a equipe está comprometida com o monitoramento e aprimoramento contínuos do modelo para enfrentar riscos e desafios emergentes.
A implantação responsável também envolve a colaboração com a comunidade mais ampla de IA e diversas partes interessadas. Ao partilhar resultados de investigação, envolver-se em discussões abertas e aceitar feedback externo, a equipa de desenvolvimento da RecurrentGemma demonstra o seu compromisso com a ciência aberta e a colaboração.
À medida que o campo da inteligência artificial continua a se expandir, o RecurrentGemma serve como um modelo que combina conceitos inovadores de design arquitetônico, treinamento rigoroso e processos de avaliação, demonstrando o potencial de ultrapassar os limites do que é possível na compreensão e geração de linguagem.
Link do artigo: https://arxiv.org/abs/2404.07839

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]