моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Сегодня, в условиях быстрого развития искусственного интеллекта, стремление к эффективным и превосходным языковым моделям побудило команду Google DeepMind разработать революционную модель RecurrentGemma. Эта новая модель, подробно описанная в статье «RecurrentGemma: Efficient Open Language Models Beyond Transformers», обещает переопределить стандарты языковой обработки путем объединения механизмов линейной рекурсии и локального внимания.
Архитектура модели RecurrentGemma является основой ее эффективной работы. Она основана на архитектуре Griffin, предложенной Google DeepMind. Эта архитектура предоставляет новые возможности для обработки языковых задач за счет сочетания механизмов линейной рекурсии и локального внимания. Углубляясь в архитектуру модели RecurrentGemma, нам сначала необходимо понять основу архитектуры Griffin и то, как RecurrentGemma внедряет инновации и оптимизирует на ее основе.
RecurrentGemma вносит ключевую модификацию в архитектуру Griffin, которая включает обработку входных вложений. Входные данные модели умножаются на константу, равную квадратному корню из ширины модели. Эта обработка корректирует входную часть модели, но не меняет выходную сторону, поскольку при выходном внедрении этот коэффициент умножения не применяется. Эта настройка позволяет модели более эффективно обрабатывать информацию, сохраняя при этом согласованность по ширине модели. Эта модификация играет важную роль в математическом выражении и информационном потоке модели. Он не только оптимизирует первоначальную обработку входных данных моделью, но также помогает модели лучше фиксировать и представлять характеристики языка путем настройки масштаба внедрения.
Производительность и эффективность модели RecurrentGemma во многом определяются ее гиперпараметрами. Эти гиперпараметры являются ключевой частью определения модели и включают, помимо прочего, следующие аспекты:
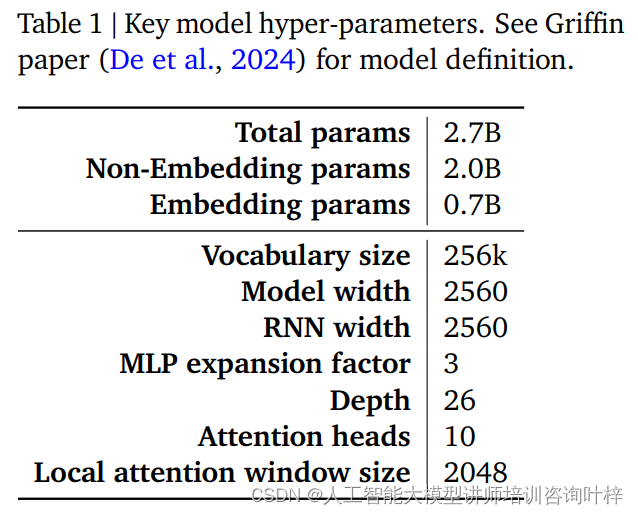
В таблице 1 представлено краткое описание этих ключевых гиперпараметров, а более подробное определение модели можно найти в статье Гриффина De et al. Вместе эти гиперпараметры составляют основу модели RecurrentGemma, позволяя добиться эффективной обработки длинных последовательностей при небольшом объеме памяти.
Благодаря тщательным изменениям архитектуры Griffin и тщательной настройке гиперпараметров модель RecurrentGemma не только демонстрирует свое теоретическое развитие, но также доказывает свою эффективность и мощные возможности обработки языка в практических приложениях.
Предварительное обучение RecurrentGemma-2B использует 2 триллиона токенов. Хотя этот объем данных меньше, чем 3 триллиона токенов, используемых Gemma-2B, он по-прежнему представляет собой огромный набор данных и предоставляет богатую языковую информацию для модели.
Источниками данных для предварительного обучения являются в основном английские онлайн-документы, математика и коды. Эти данные не только охватывают широкий спектр тем и областей, но также тщательно фильтруются и очищаются, чтобы уменьшить количество нежелательного или небезопасного контента и исключить личные или конфиденциальные данные. Кроме того, чтобы обеспечить справедливость оценки, все наборы оценок исключены из набора данных перед обучением.
RecurrentGemma-2B сначала использует большую общую смесь данных при предварительном обучении, а затем переходит к меньшим, но более качественным наборам данных для дальнейшего обучения. Этот поэтапный подход к обучению помогает модели изучить общее языковое представление широкого спектра данных, а затем уточнить и оптимизировать его с использованием более специализированных данных.
После предварительного обучения RecurrentGemma-2B был доработан с помощью настройки инструкций и алгоритма RLHF. Этот процесс направлен на оптимизацию модели, чтобы она могла лучше следовать инструкциям и генерировать ответы с высоким вознаграждением.
Настройка инструкций — это метод обучения, который позволяет модели понимать определенный формат инструкций и реагировать на них. RecurrentGemma-2B обучен придерживаться определенного формата диалога, который определяется конкретными тегами управления, например, пользовательский ввод и вывод модели идентифицируются разными тегами.
Алгоритм RLHF — это усовершенствованный метод тонкой настройки, который оптимизирует выходные данные модели с помощью структуры обучения с подкреплением. В RLHF выходные данные модели оцениваются на основе отзывов людей и корректируются на основе результатов оценки для улучшения качества результатов и вознаграждений. Этот алгоритм позволяет модели научиться генерировать более подходящие ответы в различных контекстах.
Благодаря настройке инструкций и точной настройке RLHF RecurrentGemma-2B не только способен производить высококачественный языковой вывод, но также хорошо работает в разговоре и выполнении инструкций. Этот метод обучения обеспечивает модели гибкость и адаптируемость, позволяя ей функционировать в различных сценариях применения.

Таким образом, RecurrentGemma-2B становится мощной языковой моделью, способной обеспечить эффективную и точную языковую обработку в различных задачах и средах.
Автоматизированный бенчмаркинг — это первый шаг в оценке производительности RecurrentGemma-2B. Эти тесты охватывают множество популярных последующих задач, включая, помимо прочего, ответы на вопросы, обобщение текста, лингвистическое рассуждение и многое другое. Производительность RecurrentGemma-2B в этих задачах сравнивается с Gemma-2B, и результаты показывают, что хотя RecurrentGemma-2B обучается на меньшем количестве токенов, ее производительность сравнима с Gemma-2B.
Производительность RecurrentGemma-2B в нескольких академических тестах, таких как MMLU 5-shot, HellaSwag 0-shot, PIQA 0-shot и т. д., аналогична производительности Gemma-2B, что доказывает ее универсальность и эффективность при решении различных задач. Результаты этих тестов не только демонстрируют глубокое понимание языка моделью, но и отражают ее потенциал в практическом применении.

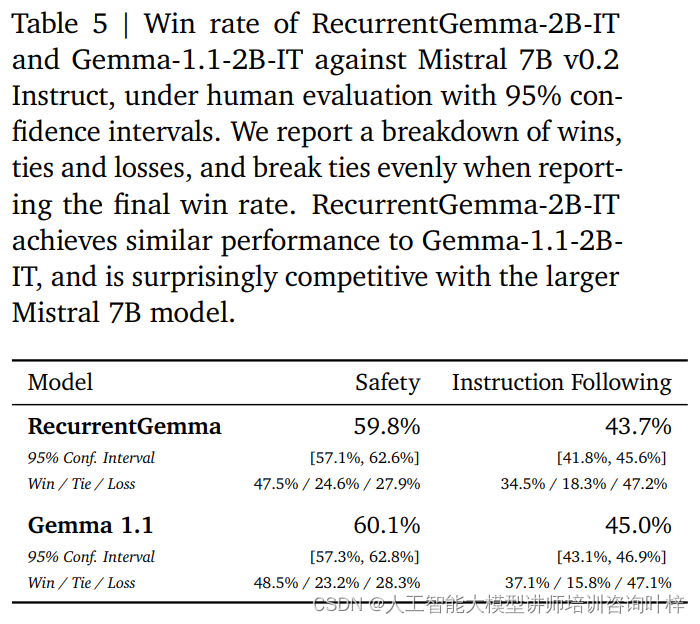
В дополнение к автоматическим тестам RecurrentGemma-2B был протестирован на людях. Человеческая оценка является важным шагом в оценке того, может ли языковая модель генерировать ответы, соответствующие человеческим ожиданиям. В этом процессе вариант RecurrentGemma-2B (RecurrentGemma-2B-IT) с настройкой инструкций сравнивался с моделью Mistral 7B v0.2 Instruct.
При человеческом оценивании используется набор из примерно 1000 инструкций, которым необходимо следовать при выполнении задач по творческому письму и кодированию. RecurrentGemma-2B-IT показала впечатляющие результаты в этом наборе, достигнув показателя выигрыша 43,7%, что лишь немного ниже, чем у Gemma-1.1-2B-IT (45,0%). Этот результат демонстрирует, что способность RecurrentGemma-2B понимать и выполнять сложные инструкции сравнима с существующими продвинутыми моделями.
RecurrentGemma-2B-IT также была оценена по набору примерно из 400 запросов при тестировании основных протоколов безопасности, в результате чего процент побед составил 59,8%, что продемонстрировало превосходство модели в соблюдении правил безопасности.
Производительность RecurrentGemma-2B была всесторонне проверена с помощью сочетания автоматизированных тестов и человеческой оценки. Автоматизированное тестирование обеспечивает количественную оценку производительности модели при выполнении различных языковых задач, а человеческая оценка обеспечивает качественное понимание качества результатов модели. Такой комплексный подход к оценке гарантирует, что RecurrentGemma-2B не только хорошо работает в теории, но также обеспечивает высококачественную генерацию и понимание языка в практических приложениях.
Скорость вывода — один из ключевых показателей для измерения полезности языковой модели, особенно при работе с данными длинных последовательностей. Оптимизация скорости вывода RecurrentGemma-2B является основным моментом, который отличает ее от традиционной модели Transformer. В традиционной модели Transformer для эффективной обработки последовательностей модели необходимо извлечь и загрузить кэш ключ-значение (KV) в память устройства. По мере увеличения длины последовательности размер KV-кеша также будет расти линейно, что не только увеличивает использование памяти, но и ограничивает способность модели обрабатывать длинные последовательности. Хотя размер кэша можно уменьшить с помощью механизмов локального внимания, обычно это достигается за счет некоторого снижения производительности.
RecurrentGemma-2B решает вышеуказанные проблемы благодаря своему инновационному архитектурному дизайну. Он сжимает входную последовательность до состояния фиксированного размера, а не полагается на KV-кэш, который растет с длиной последовательности. Такая конструкция значительно снижает использование памяти и позволяет модели поддерживать эффективную скорость вывода при обработке длинных последовательностей.
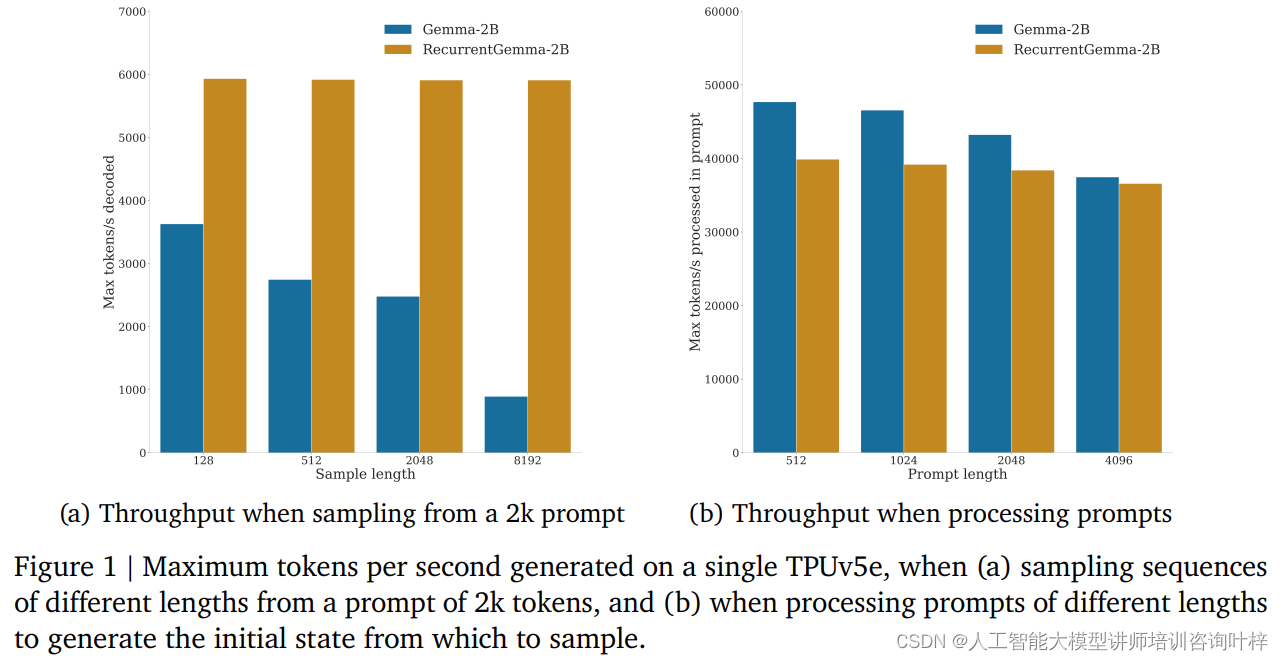
В тестах производительности RecurrentGemma-2B продемонстрировала значительные преимущества в пропускной способности. Как показано на рисунке 1a, на одном устройстве TPUv5e RecurrentGemma-2B способна достигать пропускной способности до 6 тыс. токенов в секунду при выборке последовательностей разной длины из намека на 2 тыс. токенов, в то время как модель Gemma растет по мере роста кэша. . Пропускная способность снижается.
Фиксированный размер состояния RecurrentGemma-2B является ключом к его эффективному выводу. По сравнению с моделью Gemma, состояние RecurrentGemma-2B не растет с длиной последовательности, а это означает, что она может генерировать последовательности любой длины, не ограничиваясь размером памяти хоста. Это особенно важно при обработке длинных последовательностей, поскольку позволяет модели обрабатывать более длинные текстовые данные, сохраняя при этом высокую производительность.
Улучшение скорости рассуждения имеет большое значение не только в теории, но и показывает свою ценность в практических приложениях. Высокая пропускная способность и малый объем памяти RecurrentGemma-2B делают его идеальным выбором в средах с ограниченными ресурсами, таких как мобильные устройства или периферийные вычислительные устройства. Кроме того, эффективная скорость вывода также позволяет модели быстрее реагировать на запросы пользователей и обеспечивать более плавный интерактивный опыт.
В области искусственного интеллекта внедрение моделей — это не только реализация технологий, но и принятие на себя ответственности за безопасность и этические нормы. Стратегия развертывания RecurrentGemma-2B полностью отражает акцент на этих ключевых факторах.
Перед развертыванием модели RecurrentGemma-2B прошла серию стандартных академических тестов безопасности, предназначенных для оценки возможных неправомерных действий или предвзятости модели. Благодаря этим тестам команда разработчиков может выявить и снизить потенциальные риски, гарантируя, что модель безопасна для публичного использования.

Помимо автоматического тестирования безопасности, RecurrentGemma-2B прошла оценку этики и безопасности независимой командой. Этот процесс включает в себя всесторонний анализ модели, включая, помимо прочего, ее справедливость по отношению к конкретным группам, ее способность избегать вредных результатов и защиту конфиденциальности пользователей.
Несмотря на тщательное тестирование и оценку, команда разработчиков подчеркивает, что невозможно охватить все возможные варианты использования, учитывая, что RecurrentGemma-2B может применяться во многих различных сценариях. Поэтому они рекомендуют всем пользователям перед развертыванием моделей выполнить дополнительное тестирование безопасности на основе их конкретных сценариев использования. Эта рекомендация отражает акцент на ответственности пользователя за то, чтобы каждое развертывание было хорошо продуманным и настроенным.
Ответственное развертывание также включает прозрачность производительности и ограничений модели. Команда разработчиков предоставляет подробную архитектуру модели и детали обучения, чтобы пользователи и исследователи могли понять, как работает модель и потенциальные ограничения. Кроме того, команда стремится к постоянному мониторингу и совершенствованию модели для устранения возникающих рисков и проблем.
Ответственное развертывание также предполагает сотрудничество с более широким сообществом ИИ и множеством заинтересованных сторон. Делясь результатами исследований, участвуя в открытых дискуссиях и принимая внешние отзывы, команда разработчиков RecurrentGemma демонстрирует свою приверженность открытой науке и сотрудничеству.
Поскольку область искусственного интеллекта продолжает расширяться, RecurrentGemma служит моделью, которая сочетает в себе инновационные концепции архитектурного проектирования, строгие процессы обучения и оценки, демонстрируя потенциал, позволяющий раздвинуть границы возможного в понимании и генерации языка.
Ссылка на статью: https://arxiv.org/abs/2404.07839.

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com