le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Oggi, con il rapido sviluppo dell’intelligenza artificiale, la ricerca di modelli linguistici efficienti ed eccellenti ha spinto il team di Google DeepMind a sviluppare il modello rivoluzionario RecurrentGemma. Questo nuovo modello, dettagliato nel documento “RecurrentGemma: Efficient Open Language Models Beyond Transformers”, promette di ridefinire gli standard dell’elaborazione del linguaggio combinando la ricorsione lineare e meccanismi di attenzione locale.
L'architettura del modello RecurrentGemma è il fulcro delle sue prestazioni efficienti. Si basa sull'architettura Griffin proposta da Google DeepMind. Questa architettura offre nuove possibilità per l'elaborazione di compiti linguistici combinando ricorsione lineare e meccanismi di attenzione locale. Quando approfondiamo l'architettura del modello di RecurrentGemma, dobbiamo prima comprendere le basi dell'architettura Griffin e come RecurrentGemma innova e ottimizza sulla sua base.
RecurrentGemma apporta una modifica chiave all'architettura Griffin, che prevede l'elaborazione degli incorporamenti di input. L'incorporamento dell'input del modello viene moltiplicato per una costante pari alla radice quadrata della larghezza del modello. Questo trattamento regola il lato di input del modello ma non modifica il lato di output perché l'incorporamento dell'output non applica questo fattore di moltiplicazione. Questa regolazione consente al modello di elaborare le informazioni in modo più efficiente mantenendo la coerenza tra le larghezze del modello. Questa modifica gioca un ruolo importante nell'espressione matematica e nel flusso di informazioni del modello. Non solo ottimizza l'elaborazione iniziale dei dati di input da parte del modello, ma aiuta anche il modello a catturare e rappresentare meglio le caratteristiche della lingua regolando la scala dell'incorporamento.
Le prestazioni e l'efficienza di un modello RecurrentGemma sono in gran parte determinate dai suoi iperparametri. Questi iperparametri sono una parte fondamentale della definizione del modello e includono, ma non sono limitati ai seguenti aspetti:
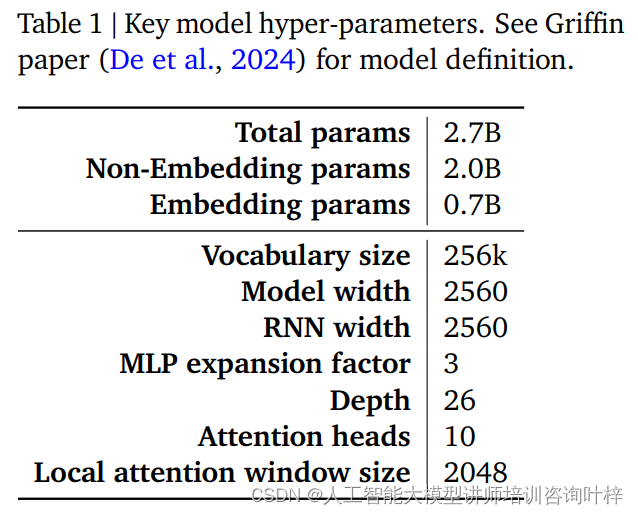
La Tabella 1 fornisce un riepilogo di questi iperparametri chiave e una definizione del modello più dettagliata può essere trovata nel documento Griffin di De et al. Insieme, questi iperparametri costituiscono la base del modello RecurrentGemma, consentendogli di ottenere un'elaborazione efficiente di lunghe sequenze mantenendo un ingombro di memoria ridotto.
Attraverso attente modifiche all'architettura Griffin e un attento aggiustamento degli iperparametri, il modello RecurrentGemma non solo dimostra il suo avanzamento in teoria, ma dimostra anche la sua efficienza e le potenti capacità di elaborazione del linguaggio nelle applicazioni pratiche.
Il pre-addestramento di RecurrentGemma-2B utilizza 2 trilioni di token Sebbene questa quantità di dati sia inferiore ai 3 trilioni di token utilizzati da Gemma-2B, costituisce comunque un enorme set di dati e fornisce ricche informazioni linguistiche per il modello.
Le fonti di dati per la pre-formazione sono principalmente documenti online, matematica e codici inglesi. Questi dati non solo coprono un'ampia gamma di argomenti e aree, ma vengono anche attentamente filtrati e puliti per ridurre i contenuti indesiderati o non sicuri ed escludere dati personali o sensibili. Inoltre, per garantire l'equità della valutazione, tutti i set di valutazione sono esclusi dal set di dati di pre-addestramento.
RecurrentGemma-2B utilizza innanzitutto una grande combinazione di dati generici nella fase preliminare della formazione, quindi passa a set di dati più piccoli ma di qualità superiore per la formazione successiva. Questo approccio di formazione a fasi aiuta il modello ad apprendere una rappresentazione linguistica generale su un'ampia gamma di dati, quindi a perfezionarla e ottimizzarla con dati più specializzati.
Dopo la formazione preliminare, RecurrentGemma-2B è stato messo a punto attraverso la messa a punto delle istruzioni e l'algoritmo RLHF. Questo processo mira a ottimizzare il modello in modo che possa seguire meglio le istruzioni e generare risposte con ricompense elevate.
L'ottimizzazione delle istruzioni è un metodo di training che consente a un modello di comprendere e rispondere a un formato di istruzioni specifico. RecurrentGemma-2B è addestrato per aderire a un formato di conversazione specifico, definito da tag di controllo specifici, ad esempio l'input dell'utente e l'output del modello sono ciascuno identificati con tag diversi.
L'algoritmo RLHF è una tecnica avanzata di messa a punto che ottimizza l'output del modello attraverso un quadro di apprendimento per rinforzo. In RLHF, l'output del modello viene valutato sulla base del feedback umano e adattato in base ai risultati della valutazione per migliorare la qualità dell'output e delle ricompense. Questo algoritmo consente al modello di apprendere come generare risposte più appropriate in diversi contesti.
Attraverso la regolazione delle istruzioni e la messa a punto dell'RLHF, RecurrentGemma-2B non solo è in grado di produrre output linguistici di alta qualità, ma si comporta bene anche nella conversazione e nel seguire le istruzioni. Questo metodo di formazione fornisce al modello flessibilità e adattabilità, consentendogli di funzionare in una varietà di scenari applicativi.
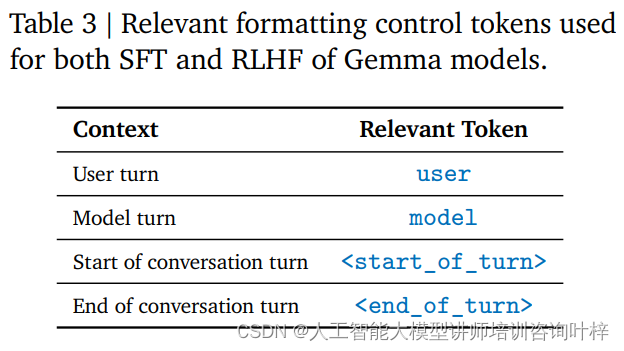

In questo modo, RecurrentGemma-2B diventa un potente modello linguistico in grado di fornire un'elaborazione linguistica efficiente e accurata in una varietà di compiti e ambienti.
Il benchmarking automatizzato è il primo passo nella valutazione delle prestazioni di RecurrentGemma-2B. Questi test coprono una varietà di attività downstream popolari, tra cui, ma non solo, la risposta alle domande, il riepilogo del testo, il ragionamento linguistico e altro ancora. Le prestazioni di RecurrentGemma-2B su questi compiti vengono confrontate con Gemma-2B e i risultati mostrano che, sebbene RecurrentGemma-2B venga addestrato su un numero inferiore di token, le sue prestazioni sono paragonabili a Gemma-2B.
Le prestazioni di RecurrentGemma-2B in molteplici benchmark accademici come MMLU 5-shot, HellaSwag 0-shot, PIQA 0-shot, ecc. sono simili a Gemma-2B, il che dimostra la sua versatilità ed efficacia su diversi compiti. I risultati dei test non solo dimostrano la comprensione approfondita del linguaggio da parte del modello, ma riflettono anche il suo potenziale nelle applicazioni pratiche.

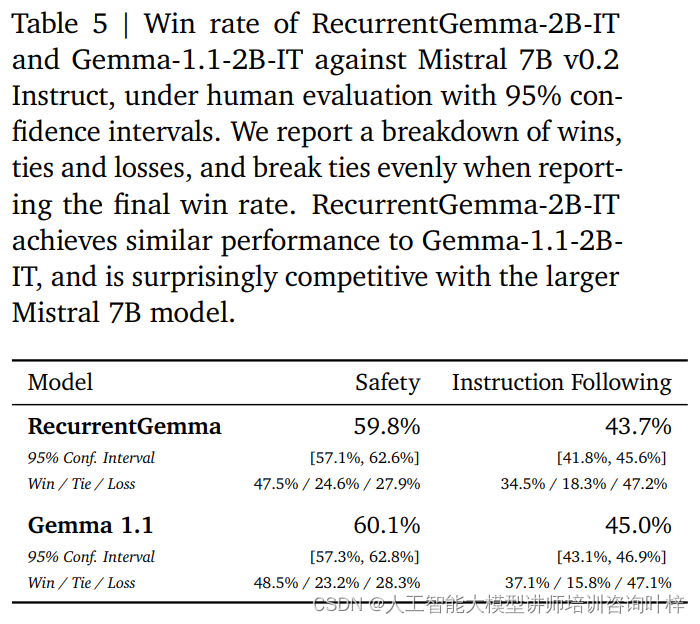
Oltre ai benchmark automatizzati, RecurrentGemma-2B è stato testato rispetto alla valutazione umana. La valutazione umana è un passaggio fondamentale nel valutare se un modello linguistico può generare risposte che soddisfano le aspettative umane. In questo processo, una variante ottimizzata per le istruzioni di RecurrentGemma-2B (RecurrentGemma-2B-IT) è stata confrontata con il modello Mistral 7B v0.2 Instruct.
Le valutazioni umane utilizzano una raccolta di circa 1.000 istruzioni da seguire per attività di scrittura creativa e codifica. RecurrentGemma-2B-IT ha ottenuto risultati impressionanti in questo set, ottenendo un tasso di vincita del 43,7%, solo leggermente inferiore al 45,0% di Gemma-1.1-2B-IT. Questo risultato dimostra che la capacità di RecurrentGemma-2B di comprendere ed eseguire istruzioni complesse è paragonabile ai modelli avanzati esistenti.
RecurrentGemma-2B-IT è stato valutato anche su una raccolta di circa 400 suggerimenti testando i protocolli di sicurezza di base, ottenendo un tasso di successo del 59,8%, dimostrando la superiorità del modello nel seguire le linee guida di sicurezza.
Le prestazioni di RecurrentGemma-2B sono state testate in modo completo attraverso una combinazione di benchmark automatizzati e valutazione umana. I test automatizzati forniscono una valutazione quantitativa delle prestazioni del modello su vari compiti linguistici, mentre la valutazione umana fornisce una comprensione qualitativa della qualità dell'output del modello. Questo approccio di valutazione globale garantisce che RecurrentGemma-2B non solo funzioni bene in teoria, ma fornisca anche generazione e comprensione del linguaggio di alta qualità nelle applicazioni pratiche.
La velocità di inferenza è una delle metriche chiave per misurare l'utilità di un modello linguistico, soprattutto quando si ha a che fare con dati in sequenze lunghe. L'ottimizzazione della velocità di inferenza di RecurrentGemma-2B è un punto forte che lo distingue dal tradizionale modello Transformer. Nel modello Transformer tradizionale, per un'elaborazione efficiente della sequenza, il modello deve recuperare e caricare la cache dei valori-chiave (KV) nella memoria del dispositivo. All'aumentare della lunghezza della sequenza, anche la dimensione della cache KV aumenterà in modo lineare, il che non solo aumenta l'utilizzo della memoria, ma limita anche la capacità del modello di gestire sequenze lunghe. Sebbene la dimensione della cache possa essere ridotta tramite meccanismi di attenzione locale, ciò di solito va a scapito di alcune prestazioni.
RecurrentGemma-2B risolve i problemi di cui sopra attraverso il suo design architettonico innovativo. Comprime la sequenza di input in uno stato di dimensione fissa anziché fare affidamento su una cache KV che cresce con la lunghezza della sequenza. Questo design riduce significativamente l'utilizzo della memoria e consente al modello di mantenere una velocità di inferenza efficiente durante l'elaborazione di sequenze lunghe.
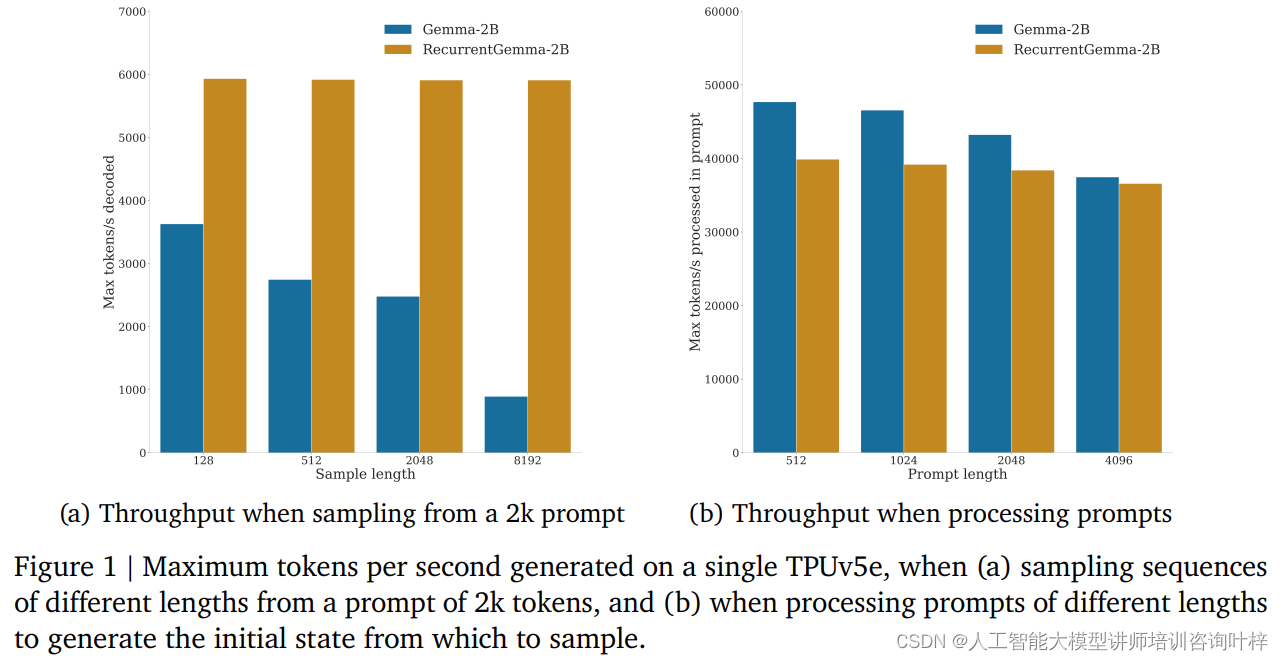
Nei test benchmark, RecurrentGemma-2B ha dimostrato notevoli vantaggi in termini di produttività. Come mostrato nella Figura 1a, su un singolo dispositivo TPUv5e, RecurrentGemma-2B è in grado di raggiungere un throughput fino a 6.000 token al secondo quando campiona sequenze di lunghezze diverse da un accenno di token 2.000, mentre il modello Gemma cresce con la crescita della cache La produttività diminuisce.
La dimensione fissa dello stato di RecurrentGemma-2B è fondamentale per la sua inferenza efficiente. Rispetto al modello Gemma, lo stato di RecurrentGemma-2B non cresce con la lunghezza della sequenza, il che significa che può generare sequenze di qualsiasi lunghezza senza essere limitato dalla dimensione della memoria dell'host. Ciò è particolarmente importante nell'elaborazione di sequenze lunghe, poiché consente al modello di elaborare dati di testo più lunghi mantenendo prestazioni elevate.
Il miglioramento della velocità di ragionamento non è solo di grande importanza in teoria, ma mostra il suo valore anche nelle applicazioni pratiche. In ambienti con risorse limitate, come dispositivi mobili o dispositivi di edge computing, l'elevato throughput e il basso ingombro di memoria di RecurrentGemma-2B lo rendono la scelta ideale. Inoltre, l'efficiente velocità di inferenza consente anche al modello di rispondere più rapidamente alle richieste degli utenti e fornire un'esperienza interattiva più fluida.
Nel campo dell’intelligenza artificiale, l’implementazione di modelli non è solo la realizzazione della tecnologia, ma anche l’assunzione di responsabilità etiche e di sicurezza. La strategia di implementazione di RecurrentGemma-2B riflette pienamente l’enfasi su questi fattori chiave.
Prima dell'implementazione del modello, RecurrentGemma-2B è stato sottoposto a una serie di benchmark di sicurezza accademici standard progettati per valutare possibili comportamenti scorretti o errori del modello. Attraverso questi test, il team di sviluppo è in grado di identificare e mitigare i potenziali rischi, garantendo che il modello sia sicuro per l’uso pubblico.

Oltre al benchmarking automatizzato della sicurezza, RecurrentGemma-2B è stato sottoposto a una valutazione etica e di sicurezza da parte di un team indipendente. Questo processo comporta una revisione completa del modello, inclusa ma non limitata alla sua equità nei confronti di gruppi specifici, alla sua capacità di evitare risultati dannosi e alla protezione della privacy degli utenti.
Nonostante test e valutazioni rigorosi, il team di sviluppo sottolinea che è impossibile coprire tutti i possibili casi d’uso, considerando che RecurrentGemma-2B può essere applicato in molti scenari diversi. Pertanto, consigliano a tutti gli utenti di eseguire ulteriori test di sicurezza in base ai loro casi d'uso specifici prima di distribuire i modelli. Questa raccomandazione riflette l'enfasi sulla responsabilità dell'utente per garantire che ogni distribuzione sia ben pensata e personalizzata.
L'implementazione responsabile include anche la trasparenza sulle prestazioni e sulle limitazioni del modello. Il team di sviluppo fornisce un'architettura dettagliata del modello e dettagli di formazione per consentire a utenti e ricercatori di comprendere come funziona il modello e i potenziali limiti. Inoltre, il team è impegnato nel monitoraggio e nel miglioramento continui del modello per affrontare i rischi e le sfide emergenti.
Un’implementazione responsabile implica anche la collaborazione con la più ampia comunità di IA e molteplici stakeholder. Condividendo i risultati della ricerca, impegnandosi in discussioni aperte e accettando feedback esterni, il team di sviluppo di RecurrentGemma dimostra il proprio impegno verso la scienza aperta e la collaborazione.
Mentre il campo dell’intelligenza artificiale continua ad espandersi, RecurrentGemma funge da modello che combina concetti innovativi di progettazione architettonica, rigorosi processi di formazione e valutazione, dimostrando il potenziale per ampliare i confini di ciò che è possibile nella comprensione e nella generazione del linguaggio.
Link al documento: https://arxiv.org/abs/2404.07839

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]