2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Aujourd'hui, avec le développement rapide de l'intelligence artificielle, la recherche de modèles linguistiques efficaces et excellents a incité l'équipe Google DeepMind à développer le modèle révolutionnaire RecurrentGemma. Ce nouveau modèle, détaillé dans l'article « RecurrentGemma : Efficient Open Language Models Beyond Transformers », promet de redéfinir les normes du traitement du langage en combinant récursivité linéaire et mécanismes d'attention locale.
L'architecture du modèle RecurrentGemma est au cœur de ses performances efficaces. Elle est basée sur l'architecture Griffin proposée par Google DeepMind. Cette architecture offre de nouvelles possibilités de traitement des tâches de langage en combinant récursion linéaire et mécanismes d'attention locale. Lorsque nous examinons l'architecture du modèle de RecurrentGemma, nous devons d'abord comprendre les fondements de l'architecture Griffin et comment RecurrentGemma innove et optimise sur cette base.
RecurrentGemma apporte une modification clé à l'architecture Griffin, qui implique le traitement des intégrations d'entrée. L'intégration d'entrée du modèle est multipliée par une constante égale à la racine carrée de la largeur du modèle. Ce traitement ajuste le côté entrée du modèle mais ne modifie pas le côté sortie car l'intégration de sortie n'applique pas ce facteur de multiplication. Cet ajustement permet au modèle de traiter les informations plus efficacement tout en maintenant la cohérence sur toutes les largeurs du modèle. Cette modification joue un rôle important dans l'expression mathématique et le flux d'informations du modèle. Il optimise non seulement le traitement initial des données d'entrée par le modèle, mais aide également le modèle à mieux capturer et représenter les caractéristiques du langage en ajustant l'échelle de l'intégration.
Les performances et l'efficacité d'un modèle RecurrentGemma sont largement déterminées par ses hyperparamètres. Ces hyperparamètres constituent un élément clé de la définition du modèle et incluent, sans toutefois s'y limiter, les aspects suivants :
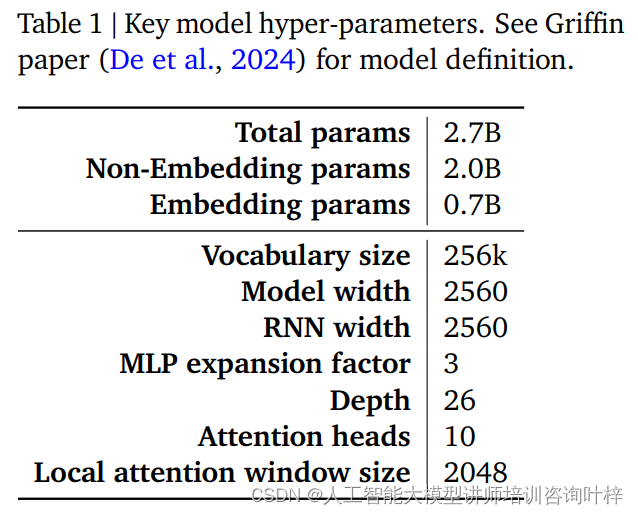
Le tableau 1 fournit un résumé de ces hyperparamètres clés, et une définition plus détaillée du modèle peut être trouvée dans l'article Griffin de De et al. Ensemble, ces hyperparamètres constituent la base du modèle RecurrentGemma, lui permettant de réaliser un traitement efficace de longues séquences tout en conservant une faible empreinte mémoire.
Grâce à des modifications minutieuses de l'architecture Griffin et à un ajustement minutieux des hyperparamètres, le modèle RecurrentGemma démontre non seulement ses progrès en théorie, mais prouve également son efficacité et ses puissantes capacités de traitement du langage dans des applications pratiques.
La pré-formation de RecurrentGemma-2B utilise 2 000 milliards de jetons. Bien que cette quantité de données soit inférieure aux 3 000 milliards de jetons utilisés par Gemma-2B, elle constitue néanmoins un énorme ensemble de données et fournit des informations linguistiques riches pour le modèle.
Les sources de données pour la pré-formation sont principalement des documents en ligne en anglais, des mathématiques et des codes. Non seulement ces données couvrent un large éventail de sujets et de domaines, mais elles sont également soigneusement filtrées et nettoyées pour réduire les contenus indésirables ou dangereux et exclure les données personnelles ou sensibles. De plus, pour garantir l'équité de l'évaluation, tous les ensembles d'évaluation sont exclus de l'ensemble de données de pré-formation.
RecurrentGemma-2B utilise d'abord un large mélange de données génériques lors de la pré-formation, puis passe à des ensembles de données plus petits mais de meilleure qualité pour une formation ultérieure. Cette approche de formation par étapes aide le modèle à apprendre une représentation linguistique générale sur un large éventail de données, puis à l'affiner et à l'optimiser avec des données plus spécialisées.
Après la pré-formation, RecurrentGemma-2B a été affiné grâce au réglage des instructions et à l'algorithme RLHF. Ce processus vise à optimiser le modèle afin qu'il puisse mieux suivre les instructions et générer des réponses avec des récompenses élevées.
Le réglage des instructions est une méthode de formation qui permet à un modèle de comprendre et de répondre à un format d'instruction spécifique. RecurrentGemma-2B est formé pour adhérer à un format de conversation spécifique, défini par des balises de contrôle spécifiques, de sorte que les entrées de l'utilisateur et les sorties du modèle soient chacune identifiées par des balises différentes.
L'algorithme RLHF est une technique avancée de réglage fin qui optimise la sortie du modèle grâce à un cadre d'apprentissage par renforcement. Dans RLHF, la sortie du modèle est évaluée sur la base des commentaires humains et ajustée en fonction des résultats de l'évaluation pour améliorer la qualité de la sortie et des récompenses. Cet algorithme permet au modèle d'apprendre à générer des réponses plus appropriées dans différents contextes.
Grâce à l'ajustement des instructions et au réglage fin du RLHF, RecurrentGemma-2B est non seulement capable de produire une sortie linguistique de haute qualité, mais il fonctionne également bien dans les conversations et dans le suivi des instructions. Cette méthode de formation confère au modèle flexibilité et adaptabilité, lui permettant de fonctionner dans une variété de scénarios d'application.

De cette manière, RecurrentGemma-2B devient un modèle de langage puissant capable de fournir un traitement linguistique efficace et précis dans une variété de tâches et d'environnements.
L'analyse comparative automatisée est la première étape dans l'évaluation des performances de RecurrentGemma-2B. Ces tests couvrent une variété de tâches populaires en aval, notamment la réponse aux questions, le résumé de texte, le raisonnement linguistique, etc. Les performances de RecurrentGemma-2B sur ces tâches sont comparées à celles de Gemma-2B, et les résultats montrent que bien que RecurrentGemma-2B soit formé sur un plus petit nombre de jetons, ses performances sont comparables à celles de Gemma-2B.
Les performances de RecurrentGemma-2B dans plusieurs benchmarks académiques tels que MMLU 5-shot, HellaSwag 0-shot, PIQA 0-shot, etc. sont similaires à celles de Gemma-2B, ce qui prouve sa polyvalence et son efficacité sur différentes tâches. Ces résultats de tests démontrent non seulement la compréhension approfondie du langage du modèle, mais reflètent également son potentiel dans des applications pratiques.

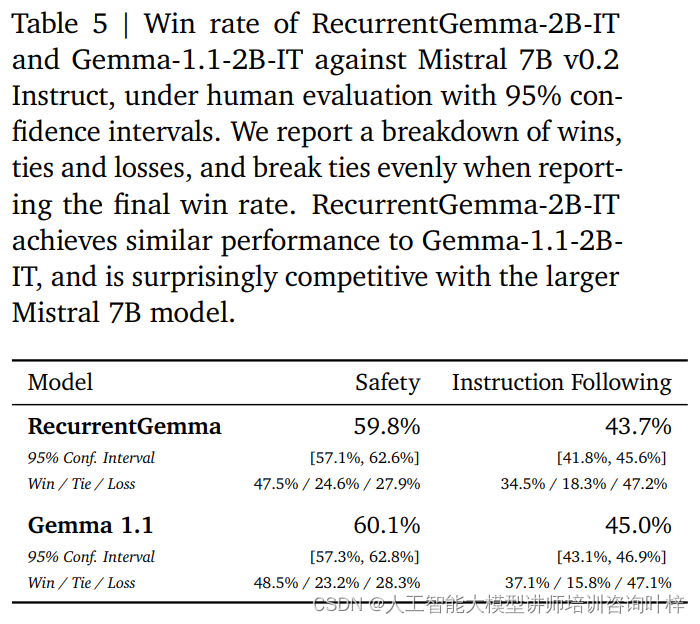
En plus des benchmarks automatisés, RecurrentGemma-2B a été testé par rapport à une évaluation humaine. L'évaluation humaine est une étape cruciale pour déterminer si un modèle de langage peut générer des réponses qui répondent aux attentes humaines. Dans ce processus, une variante optimisée par les instructions de RecurrentGemma-2B (RecurrentGemma-2B-IT) a été comparée au modèle Mistral 7B v0.2 Instruct.
Les évaluations humaines utilisent une collection d’environ 1 000 instructions à suivre pour les tâches d’écriture créative et de codage. RecurrentGemma-2B-IT a réalisé des performances impressionnantes sur cet ensemble, atteignant un taux de victoire de 43,7 %, à peine inférieur aux 45,0 % de Gemma-1.1-2B-IT. Ce résultat démontre que la capacité de RecurrentGemma-2B à comprendre et à exécuter des instructions complexes est comparable aux modèles avancés existants.
RecurrentGemma-2B-IT a également été évalué sur une collection d'environ 400 invites testant les protocoles de sécurité de base, atteignant un taux de réussite de 59,8 %, démontrant la supériorité du modèle dans le respect des directives de sécurité.
Les performances de RecurrentGemma-2B ont été examinées de manière approfondie grâce à une combinaison de tests de référence automatisés et d'évaluation humaine. Les tests automatisés fournissent une évaluation quantitative des performances du modèle sur diverses tâches linguistiques, tandis que l'évaluation humaine fournit une compréhension qualitative de la qualité du résultat du modèle. Cette approche d'évaluation complète garantit que RecurrentGemma-2B non seulement fonctionne bien en théorie, mais offre également une génération et une compréhension linguistiques de haute qualité dans des applications pratiques.
La vitesse d'inférence est l'une des mesures clés pour mesurer l'utilité d'un modèle de langage, en particulier lorsqu'il s'agit de données de longue séquence. L'optimisation de la vitesse d'inférence de RecurrentGemma-2B est un point fort qui le distingue du modèle Transformer traditionnel. Dans le modèle Transformer traditionnel, pour un traitement de séquence efficace, le modèle doit récupérer et charger le cache clé-valeur (KV) dans la mémoire de l'appareil. À mesure que la longueur de la séquence augmente, la taille du cache KV augmente également de manière linéaire, ce qui non seulement augmente l'utilisation de la mémoire, mais limite également la capacité du modèle à gérer de longues séquences. Bien que la taille du cache puisse être réduite grâce à des mécanismes d’attention locaux, cela se fait généralement au détriment de certaines performances.
RecurrentGemma-2B résout les problèmes ci-dessus grâce à sa conception architecturale innovante. Il compresse la séquence d'entrée dans un état de taille fixe plutôt que de s'appuyer sur un cache KV qui augmente avec la longueur de la séquence. Cette conception réduit considérablement l'utilisation de la mémoire et permet au modèle de maintenir une vitesse d'inférence efficace lors du traitement de longues séquences.
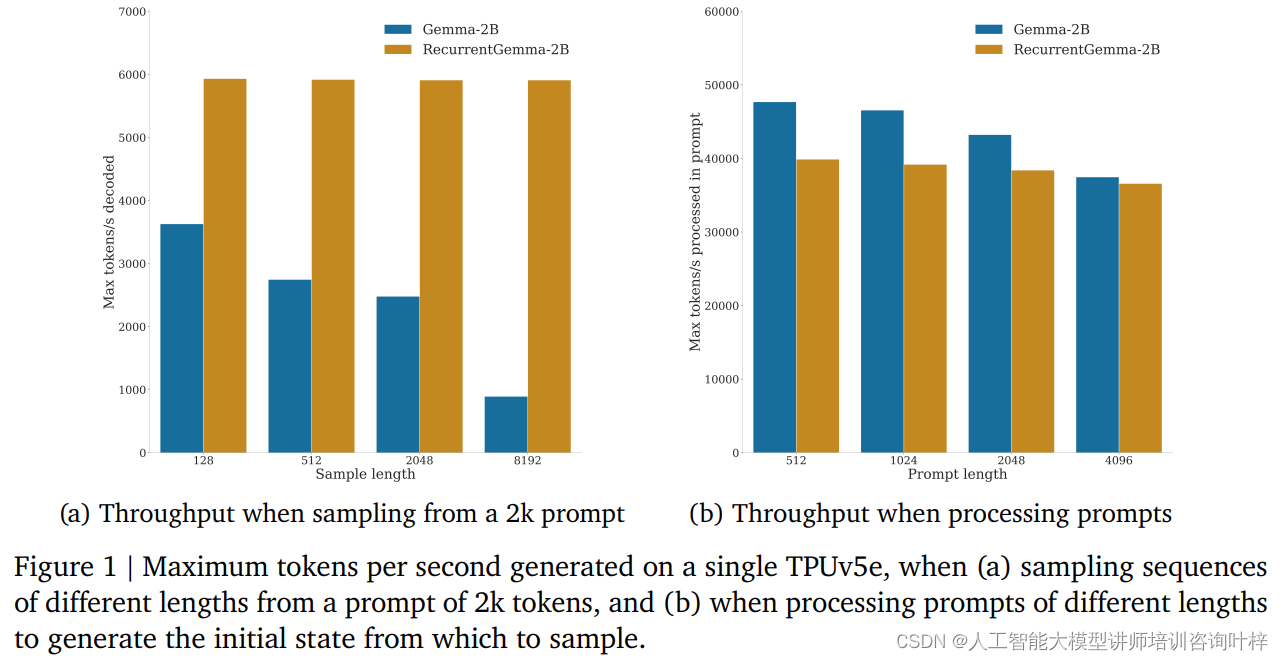
Lors de tests de référence, RecurrentGemma-2B a démontré des avantages significatifs en matière de débit. Comme le montre la figure 1a, sur un seul appareil TPUv5e, RecurrentGemma-2B est capable d'atteindre un débit allant jusqu'à 6 000 jetons par seconde lors de l'échantillonnage de séquences de différentes longueurs à partir d'un soupçon de 2 000 jetons, tandis que le modèle Gemma grandit à mesure que le cache grandit. . Le débit diminue.
La taille d’état fixe de RecurrentGemma-2B est la clé de son inférence efficace. Par rapport au modèle Gemma, l'état de RecurrentGemma-2B n'augmente pas avec la longueur de la séquence, ce qui signifie qu'il peut générer des séquences de n'importe quelle longueur sans être limité par la taille de la mémoire hôte. Ceci est particulièrement important dans le traitement de séquences longues, car cela permet au modèle de traiter des données textuelles plus longues tout en conservant des performances élevées.
L’amélioration de la vitesse de raisonnement n’est pas seulement d’une grande importance en théorie, mais montre également sa valeur dans les applications pratiques. Le débit élevé et la faible empreinte mémoire de RecurrentGemma-2B en font un choix idéal dans les environnements aux ressources limitées, tels que les appareils mobiles ou les appareils informatiques de pointe. De plus, la vitesse d'inférence efficace permet également au modèle de répondre plus rapidement aux demandes des utilisateurs et d'offrir une expérience interactive plus fluide.
Dans le domaine de l'intelligence artificielle, le déploiement de modèles n'est pas seulement la réalisation de la technologie, mais aussi la prise en charge de responsabilités en matière de sécurité et d'éthique. La stratégie de déploiement de RecurrentGemma-2B reflète pleinement l’accent mis sur ces facteurs clés.
Avant le déploiement du modèle, RecurrentGemma-2B a été soumis à une série de tests de sécurité académiques standard conçus pour évaluer les éventuelles fautes ou biais du modèle. Grâce à ces tests, l'équipe de développement est en mesure d'identifier et d'atténuer les risques potentiels, garantissant ainsi que le modèle est sûr pour un usage public.

En plus de l'analyse comparative automatisée de la sécurité, RecurrentGemma-2B a fait l'objet d'une évaluation d'éthique et de sécurité par une équipe indépendante. Ce processus implique un examen complet du modèle, y compris, mais sans s'y limiter, son équité envers des groupes spécifiques, sa capacité à éviter les résultats préjudiciables et sa protection de la vie privée des utilisateurs.
Malgré des tests et des évaluations rigoureux, l'équipe de développement souligne qu'il est impossible de couvrir tous les cas d'utilisation possibles, étant donné que RecurrentGemma-2B peut être appliqué dans de nombreux scénarios différents. Par conséquent, ils recommandent à tous les utilisateurs d’effectuer des tests de sécurité supplémentaires en fonction de leurs cas d’utilisation spécifiques avant de déployer des modèles. Cette recommandation reflète l'accent mis sur la responsabilité des utilisateurs pour garantir que chaque déploiement est bien pensé et personnalisé.
Un déploiement responsable inclut également la transparence sur les performances et les limites du modèle. L'équipe de développement fournit une architecture détaillée du modèle et des détails de formation pour permettre aux utilisateurs et aux chercheurs de comprendre le fonctionnement du modèle et ses limites potentielles. De plus, l’équipe s’engage à surveiller et à améliorer continuellement le modèle pour faire face aux risques et défis émergents.
Un déploiement responsable implique également une collaboration avec la communauté plus large de l’IA et de multiples parties prenantes. En partageant les résultats de la recherche, en s'engageant dans des discussions ouvertes et en acceptant les commentaires externes, l'équipe de développement de RecurrentGemma démontre son engagement en faveur de la science ouverte et de la collaboration.
Alors que le domaine de l'intelligence artificielle continue de se développer, RecurrentGemma sert de modèle combinant des concepts de conception architecturale innovants, des processus de formation et d'évaluation rigoureux, démontrant le potentiel de repousser les limites de ce qui est possible en matière de compréhension et de génération de langues.
Lien papier : https://arxiv.org/abs/2404.07839

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
