Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Hoy, con el rápido desarrollo de la inteligencia artificial, la búsqueda de modelos de lenguaje excelentes y eficientes ha llevado al equipo de Google DeepMind a desarrollar el modelo innovador RecurrentGemma. Este nuevo modelo, detallado en el artículo "RecurrentGemma: Efficient Open Language Models Beyond Transformers", promete redefinir los estándares del procesamiento del lenguaje mediante la combinación de recursividad lineal y mecanismos de atención local.
La arquitectura del modelo RecurrentGemma es el núcleo de su rendimiento eficiente. Se basa en la arquitectura Griffin propuesta por Google DeepMind. Esta arquitectura proporciona nuevas posibilidades para procesar tareas del lenguaje mediante la combinación de recursividad lineal y mecanismos de atención local. Al profundizar en la arquitectura modelo de RecurrentGemma, primero debemos comprender la base de la arquitectura Griffin y cómo RecurrentGemma innova y optimiza sobre esta base.
RecurrentGemma realiza una modificación clave en la arquitectura Griffin, que implica el procesamiento de incrustaciones de entrada. La incrustación de entrada del modelo se multiplica por una constante igual a la raíz cuadrada del ancho del modelo. Este tratamiento ajusta el lado de entrada del modelo pero no cambia el lado de salida porque la incorporación de salida no aplica este factor de multiplicación. Este ajuste permite que el modelo procese información de manera más eficiente mientras mantiene la coherencia en todos los anchos del modelo. Esta modificación juega un papel importante en la expresión matemática y el flujo de información del modelo. No solo optimiza el procesamiento inicial de los datos de entrada del modelo, sino que también ayuda al modelo a capturar y representar mejor las características del lenguaje ajustando la escala de la incrustación.
El rendimiento y la eficiencia de un modelo RecurrentGemma están determinados en gran medida por sus hiperparámetros. Estos hiperparámetros son una parte clave de la definición del modelo e incluyen, entre otros, los siguientes aspectos:
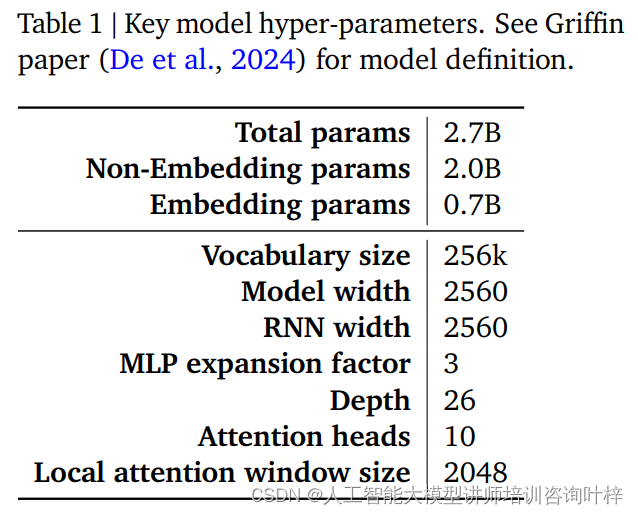
La Tabla 1 proporciona un resumen de estos hiperparámetros clave, y se puede encontrar una definición más detallada del modelo en el artículo de Griffin de De et al. Juntos, estos hiperparámetros forman la base del modelo RecurrentGemma, lo que le permite lograr un procesamiento eficiente de secuencias largas manteniendo una pequeña huella de memoria.
A través de cuidadosas modificaciones a la arquitectura Griffin y un cuidadoso ajuste de los hiperparámetros, el modelo RecurrentGemma no solo demuestra su avance en teoría, sino que también demuestra su eficiencia y poderosas capacidades de procesamiento del lenguaje en aplicaciones prácticas.
El entrenamiento previo de RecurrentGemma-2B utiliza 2 billones de tokens. Aunque esta cantidad de datos es menor que los 3 billones de tokens utilizados por Gemma-2B, aún constituye un conjunto de datos enorme y proporciona información de lenguaje rica para el modelo.
Las fuentes de datos para la formación previa son principalmente documentos, matemáticas y códigos en línea en inglés. Estos datos no solo cubren una amplia gama de temas y áreas, sino que también se filtran y limpian cuidadosamente para reducir el contenido no deseado o inseguro y excluir datos personales o confidenciales. Además, para garantizar la equidad de la evaluación, todos los conjuntos de evaluación se excluyen del conjunto de datos previo al entrenamiento.
RecurrentGemma-2B primero utiliza una gran combinación de datos genéricos en el entrenamiento previo y luego pasa a conjuntos de datos más pequeños pero de mayor calidad para el entrenamiento adicional. Este enfoque de entrenamiento por etapas ayuda al modelo a aprender una representación de lenguaje general en una amplia gama de datos y luego refinarla y optimizarla con datos más especializados.
Después del entrenamiento previo, RecurrentGemma-2B se ajustó mediante el ajuste de instrucciones y el algoritmo RLHF. Este proceso tiene como objetivo optimizar el modelo para que pueda seguir mejor las instrucciones y generar respuestas con altas recompensas.
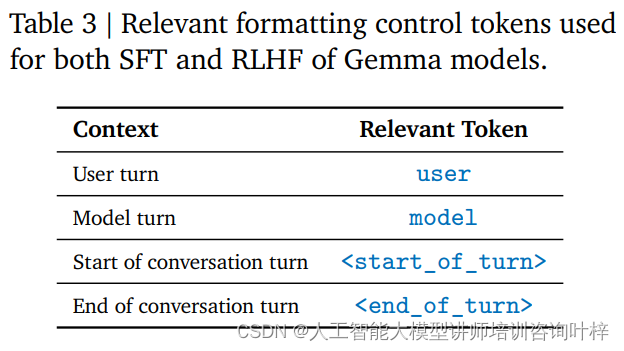
El ajuste de instrucciones es un método de entrenamiento que permite que un modelo comprenda y responda a un formato de instrucción específico. RecurrentGemma-2B está entrenado para adherirse a un formato de conversación específico, que está definido por etiquetas de control específicas, como la entrada del usuario y la salida del modelo, cada una identificada con etiquetas diferentes.
El algoritmo RLHF es una técnica avanzada de ajuste fino que optimiza la salida del modelo a través de un marco de aprendizaje por refuerzo. En RLHF, el resultado del modelo se evalúa en función de la retroalimentación humana y se ajusta en función de los resultados de la evaluación para mejorar la calidad del resultado y las recompensas. Este algoritmo permite que el modelo aprenda a generar respuestas más apropiadas en diferentes contextos.
Mediante el ajuste de instrucciones y el ajuste fino de RLHF, RecurrentGemma-2B no solo puede producir resultados de lenguaje de alta calidad, sino que también se desempeña bien en la conversación y en el seguimiento de instrucciones. Este método de entrenamiento proporciona al modelo flexibilidad y adaptabilidad, permitiéndole funcionar en una variedad de escenarios de aplicación.

De esta manera, RecurrentGemma-2B se convierte en un poderoso modelo de lenguaje capaz de proporcionar un procesamiento del lenguaje eficiente y preciso en una variedad de tareas y entornos.
La evaluación comparativa automatizada es el primer paso para evaluar el rendimiento de RecurrentGemma-2B. Estas pruebas cubren una variedad de tareas posteriores populares, que incluyen, entre otras, la respuesta a preguntas, el resumen de textos, el razonamiento lingüístico y más. El rendimiento de RecurrentGemma-2B en estas tareas se compara con el de Gemma-2B, y los resultados muestran que aunque RecurrentGemma-2B se entrena con una cantidad menor de tokens, su rendimiento es comparable al de Gemma-2B.
El desempeño de RecurrentGemma-2B en múltiples puntos de referencia académicos como MMLU 5-shot, HellaSwag 0-shot, PIQA 0-shot, etc. es similar al de Gemma-2B, lo que demuestra su versatilidad y efectividad en diferentes tareas. Los resultados de estas pruebas no solo demuestran la profunda comprensión del lenguaje por parte del modelo, sino que también reflejan su potencial en aplicaciones prácticas.

Además de los puntos de referencia automatizados, RecurrentGemma-2B ha sido probado con evaluación humana. La evaluación humana es un paso crítico para evaluar si un modelo de lenguaje puede generar respuestas que satisfagan las expectativas humanas. En este proceso, se comparó una variante sintonizada con instrucciones de RecurrentGemma-2B (RecurrentGemma-2B-IT) con el modelo Mistral 7B v0.2 Instruct.
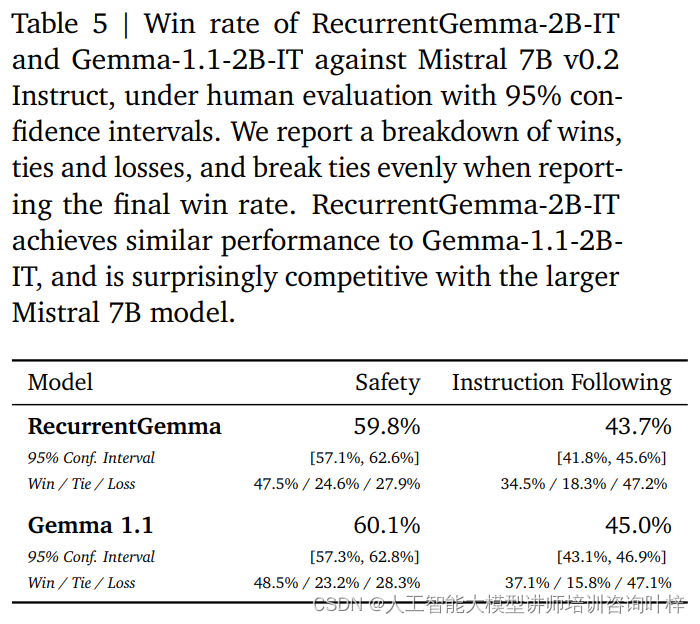
Las evaluaciones humanas utilizan una colección de aproximadamente 1000 instrucciones a seguir para tareas de escritura y codificación creativas. RecurrentGemma-2B-IT tuvo un desempeño impresionante en este conjunto, logrando una tasa de victorias del 43,7%, solo ligeramente inferior al 45,0% de Gemma-1.1-2B-IT. Este resultado demuestra que la capacidad de RecurrentGemma-2B para comprender y ejecutar instrucciones complejas es comparable a los modelos avanzados existentes.
RecurrentGemma-2B-IT también se evaluó en una colección de aproximadamente 400 mensajes que prueban protocolos de seguridad básicos, logrando una tasa de éxito del 59,8 %, lo que demuestra la superioridad del modelo a la hora de seguir las pautas de seguridad.
El rendimiento de RecurrentGemma-2B se probó exhaustivamente mediante una combinación de puntos de referencia automatizados y evaluación humana. Las pruebas automatizadas proporcionan una evaluación cuantitativa del desempeño del modelo en diversas tareas lingüísticas, mientras que la evaluación humana proporciona una comprensión cualitativa de la calidad del resultado del modelo. Este enfoque de evaluación integral garantiza que RecurrentGemma-2B no solo funcione bien en teoría, sino que también brinde generación y comprensión del lenguaje de alta calidad en aplicaciones prácticas.
La velocidad de inferencia es una de las métricas clave para medir la utilidad de un modelo de lenguaje, especialmente cuando se trata de datos de secuencia larga. La optimización de la velocidad de inferencia de RecurrentGemma-2B es un punto destacado que lo distingue del modelo Transformer tradicional. En el modelo Transformer tradicional, para un procesamiento de secuencia eficiente, el modelo necesita recuperar y cargar la caché de valor clave (KV) en la memoria del dispositivo. A medida que aumenta la longitud de la secuencia, el tamaño de la caché KV también crecerá linealmente, lo que no solo aumenta el uso de la memoria, sino que también limita la capacidad del modelo para manejar secuencias largas. Aunque el tamaño de la caché se puede reducir mediante mecanismos de atención local, esto suele producirse a expensas de cierto rendimiento.
RecurrentGemma-2B resuelve los problemas anteriores a través de su innovador diseño arquitectónico. Comprime la secuencia de entrada en un estado de tamaño fijo en lugar de depender de una caché KV que crece con la longitud de la secuencia. Este diseño reduce significativamente el uso de memoria y permite que el modelo mantenga una velocidad de inferencia eficiente al procesar secuencias largas.
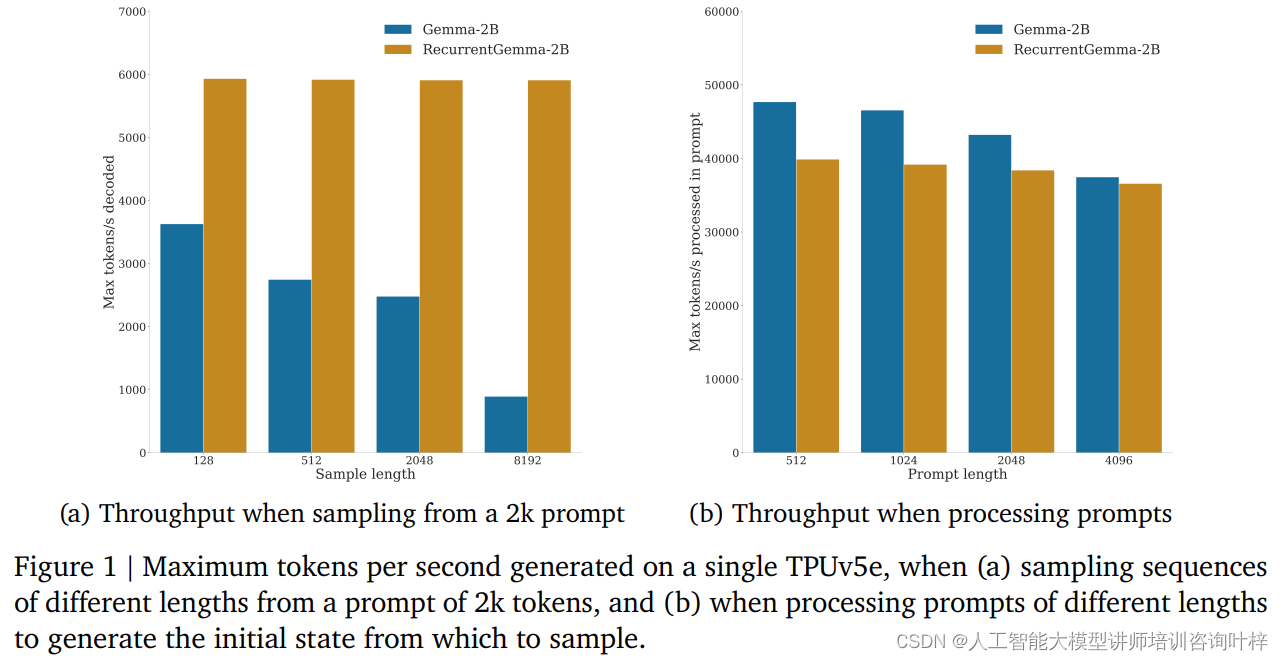
En las pruebas comparativas, RecurrentGemma-2B demostró importantes ventajas de rendimiento. Como se muestra en la Figura 1a, en un solo dispositivo TPUv5e, RecurrentGemma-2B puede lograr un rendimiento de hasta 6k tokens por segundo cuando se muestrean secuencias de diferentes longitudes a partir de una muestra de 2k tokens, mientras que el modelo Gemma crece a medida que crece el caché. El rendimiento disminuye.
El tamaño de estado fijo de RecurrentGemma-2B es clave para su inferencia eficiente. En comparación con el modelo Gemma, el estado de RecurrentGemma-2B no crece con la longitud de la secuencia, lo que significa que puede generar secuencias de cualquier longitud sin estar limitado por el tamaño de la memoria del host. Esto es particularmente importante en el procesamiento de secuencias largas, ya que permite que el modelo procese datos de texto más largos manteniendo un alto rendimiento.
La mejora de la velocidad de razonamiento no sólo es de gran importancia en teoría, sino que también muestra su valor en aplicaciones prácticas. En entornos con recursos limitados, como dispositivos móviles o dispositivos informáticos de vanguardia, el alto rendimiento y el bajo consumo de memoria de RecurrentGemma-2B lo convierten en una opción ideal. Además, la velocidad de inferencia eficiente también permite que el modelo responda a las solicitudes de los usuarios más rápido y proporcione una experiencia interactiva más fluida.
En el campo de la inteligencia artificial, el despliegue de modelos no es sólo la realización de tecnología, sino también la asunción de responsabilidades éticas y de seguridad. La estrategia de despliegue de RecurrentGemma-2B refleja plenamente el énfasis en estos factores clave.
Antes de la implementación del modelo, RecurrentGemma-2B se sometió a una serie de puntos de referencia de seguridad académicos estándar diseñados para evaluar posibles malas conductas o sesgos del modelo. A través de estas pruebas, el equipo de desarrollo puede identificar y mitigar riesgos potenciales, garantizando que el modelo sea seguro para uso público.

Además de la evaluación comparativa de seguridad automatizada, RecurrentGemma-2B se sometió a una evaluación de ética y seguridad por parte de un equipo independiente. Este proceso implica una revisión integral del modelo, que incluye, entre otros, su equidad para grupos específicos, su capacidad para evitar resultados dañinos y su protección de la privacidad del usuario.
A pesar de las pruebas y evaluaciones rigurosas, el equipo de desarrollo enfatiza que es imposible cubrir todos los casos de uso posibles, considerando que RecurrentGemma-2B se puede aplicar en muchos escenarios diferentes. Por lo tanto, recomiendan que todos los usuarios realicen pruebas de seguridad adicionales según sus casos de uso específicos antes de implementar modelos. Esta recomendación refleja un énfasis en la responsabilidad del usuario para garantizar que cada implementación esté bien pensada y personalizada.
La implementación responsable también incluye transparencia sobre el rendimiento y las limitaciones del modelo. El equipo de desarrollo proporciona una arquitectura detallada del modelo y detalles de capacitación para permitir a los usuarios e investigadores comprender cómo funciona el modelo y sus posibles limitaciones. Además, el equipo está comprometido con el seguimiento y la mejora continuos del modelo para abordar los riesgos y desafíos emergentes.
El despliegue responsable también implica la colaboración con la comunidad de IA en general y múltiples partes interesadas. Al compartir los resultados de la investigación, participar en debates abiertos y aceptar comentarios externos, el equipo de desarrollo de RecurrentGemma demuestra su compromiso con la ciencia abierta y la colaboración.
A medida que el campo de la inteligencia artificial continúa expandiéndose, RecurrentGemma sirve como modelo que combina conceptos innovadores de diseño arquitectónico, procesos rigurosos de capacitación y evaluación, lo que demuestra el potencial de ampliar los límites de lo que es posible en la comprensión y generación de lenguajes.
Enlace del artículo: https://arxiv.org/abs/2404.07839

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]