2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Der Einsatz von Graphdatenbanken oder Wissensgraphen in großen Modellanwendungen erfreut sich in letzter Zeit immer größerer Beliebtheit. Diagramme haben natürliche Vorteile bei der Darstellung und Speicherung vielfältiger und miteinander verbundener Informationen und können problemlos komplexe Beziehungen und Attribute zwischen verschiedenen Datentypen erfassen, wodurch Kontext oder Datenunterstützung für große Modelle besser bereitgestellt werden. In diesem Artikel werfen wir einen Blick auf die Verwendung von Graphdatenbanken oder Wissensgraphen in großen Modellanwendungen.
Dieser Artikel ist nur eine einfache Einführung und Erfahrung.Es spielt keine Rolle, ob Sie sich mit Graph Database oder neo4j nicht auskennen. Befolgen Sie einfach die Schritte in diesem Artikel . Dieser Artikel kann Ihnen helfen, die Anwendungsmethode von Wissensgraphen in RAG zu verstehen. Sobald Sie über die nötige Erfahrung verfügen, können Sie später bei Bedarf lernen, wie Sie die Graphdatenbank verwenden.
Ein Wissensgraph ist eine strukturierte semantische Wissensdatenbank, die Entitäten (wie Personen, Orte, Organisationen usw.) und Beziehungen zwischen Entitäten (wie Personenbeziehungen, geografische Standortbeziehungen usw.) in Form von Diagrammen speichert und darstellt. Wissensgraphen werden häufig verwendet, um das semantische Verständnis von Suchmaschinen zu verbessern und umfassendere Informationen und genauere Suchergebnisse bereitzustellen.
Zu den Hauptmerkmalen des Wissensgraphen gehören:
1. Entität : Die Grundeinheit im Wissensgraphen, die ein Objekt oder Konzept in der realen Welt darstellt.
2. Beziehung: Die Beziehung zwischen Entitäten, z. B. „gehört zu“, „befindet sich in“, „Ersteller“ usw.
3. Attribut: Beschreibende Informationen, über die die Entität verfügt, z. B. das Alter der Person, der Längen- und Breitengrad des Standorts usw.
4. Diagrammstruktur: Der Wissensgraph organisiert Daten in Form eines Graphen, einschließlich Knoten (Entitäten) und Kanten (Beziehungen).
5. *Semantisches Netzwerk: Ein Wissensgraph kann als semantisches Netzwerk betrachtet werden, in dem Knoten und Kanten semantische Bedeutungen haben.
6. Schlussfolgerung: Wissensgraphen können zur Schlussfolgerung verwendet werden, d. h. zum Ableiten neuer Informationen aus bekannten Entitäten und Beziehungen.
Wissensgraphen werden häufig in der Suchmaschinenoptimierung (SEO), Empfehlungssystemen, der Verarbeitung natürlicher Sprache (NLP), Data Mining und anderen Bereichen eingesetzt. Bekannte Beispiele für Wissensgraphen sind beispielsweise Googles Knowledge Graph, Wikidata, DBpedia usw.
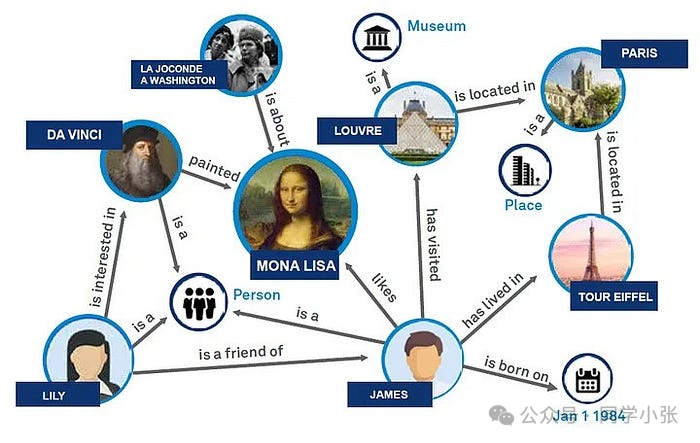
Als eine Form der Datenorganisation besteht die Bedeutung des Wissensgraphen darin, eine effiziente und intuitive Möglichkeit zur Darstellung und Verwaltung komplexer Datenbeziehungen bereitzustellen. Es zeigt Daten in strukturierter Form durch die Knoten und Kanten der Diagrammstruktur an, verbessert die semantische Ausdrucksfähigkeit der Daten und macht die Beziehung zwischen Entitäten klar und deutlich. Wissensgraphen verbessern die Genauigkeit des Informationsabrufs erheblich, insbesondere im Bereich der Verarbeitung natürlicher Sprache, und ermöglichen es Maschinen, komplexe Benutzeranfragen besser zu verstehen und darauf zu reagieren. Wissensgraphen spielen eine zentrale Rolle in intelligenten Anwendungen wie Empfehlungssystemen, intelligenter Fragebeantwortung usw.
Werfen wir nach der langweiligen Einführung einen Blick auf den Fall des RAG+-Wissensgraphen und implementieren ihn selbst.
Der folgende Fall stammt aus der offiziellen Dokumentation von LangChain: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Zuerst müssen Sie eine Diagrammdatenbank installieren, hier verwenden wir neo4j.
Python-Installationsbefehl:
pip install neo4j
(2) Registrieren Sie ein offizielles Konto, melden Sie sich an und erstellen Sie eine Datenbankinstanz. (Wenn Sie es zum Lernen nutzen möchten, wählen Sie einfach die kostenlose Version.)
Nach dem Erstellen einer Online-Datenbankinstanz sieht die Seite wie folgt aus:
Sie können diese Datenbank nun in Ihrem Code verwenden.
(1) Nach dem Erstellen der Datenbankinstanz sollten Sie den Link, den Benutzernamen und das Passwort der Daten abrufen. Die alte Regel besteht darin, sie in die Umgebungsvariable einzufügen und die Umgebungsvariable dann über Python zu laden:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Datenbank verknüpfen
LangChain kapselt die neo4j-Schnittstelle und wir müssen nur die Neo4jGraph-Klasse importieren, um sie zu verwenden.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Daten abfragen und füllen
Mit der Abfrageschnittstelle können Sie Ergebnisse abfragen und zurückgeben. Die Sprache der Abfrageanweisung ist die Cypher-Abfragesprache.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
Die Ausgabe des obigen Codes ist []。
(4) Aktualisieren Sie die Architekturinformationen des Diagramms
graph.refresh_schema()
print(graph.schema)

Aus den Ergebnissen geht hervor, dass das Schema Informationen wie Knotentypen, Attribute und Beziehungen zwischen Typen enthält und die Architektur des Diagramms darstellt.
Wir können uns auch auf der neo4j-Webseite anmelden, um die in der Diagrammdatenbank gespeicherten Daten anzuzeigen:
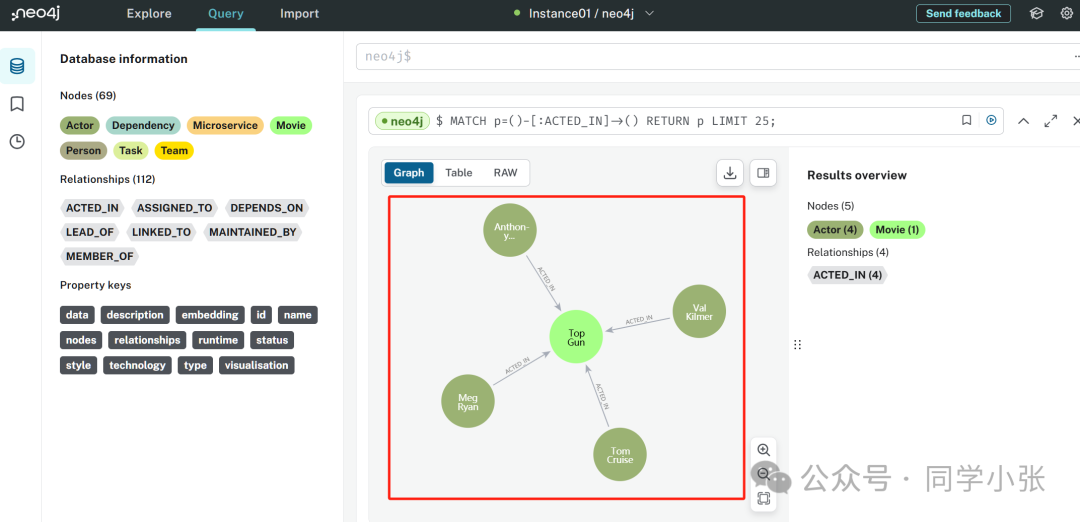
(5) Da nun Daten in der Diagrammdatenbank vorhanden sind, können wir diese abfragen.
Die GraphCypherQACain-Klasse ist in LangChain gekapselt, was mithilfe der Diagrammdatenbank problemlos abgefragt werden kann. Der folgende Code:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Ausführungsprozess und Ergebnisse:

Zuerst wird die natürliche Sprache (Wer hat in Top Gun gespielt?) über ein großes Modell in eine Graph-Abfrageanweisung umgewandelt, dann wird die Abfrageanweisung über neo4j ausgeführt, die Ergebnisse werden zurückgegeben und schließlich wird sie über das große Modell in natürliche Sprache umgewandelt Modell und Ausgabe an den Benutzer.
Im obigen Code verwenden wir die GraphCypherQACain-Klasse von LangChain, bei der es sich um die von LangChain bereitgestellte Graphdatenbankabfrage und Frage- und Antwortkette handelt.Es gibt viele Parameter, die eingestellt werden können, z. B. die Verwendungexclude_types So legen Sie fest, welche Knotentypen oder Beziehungen ignoriert werden:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
Die Ausgabe ähnelt der folgenden:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Es stehen viele ähnliche Parameter zur Verfügung. Weitere Informationen finden Sie in der offiziellen Dokumentation: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- Antwortgenerierung
Das Folgende ist der Ausführungsquellcode von GraphCypherQACain. Werfen wir einen kurzen Blick auf den Ausführungsprozess.
(1)cypher_generation_chain: Konvertierung natürlicher Sprache in Diagrammabfrageanweisungen.
(2)extract_cypher: Entfernen Sie die Abfrageanweisung. Dies liegt daran, dass große Modelle möglicherweise einige zusätzliche Beschreibungsinformationen zurückgeben und entfernt werden müssen.
(3)cypher_query_corrector: Korrigieren Sie die Abfrageanweisung.
(4)graph.query: Abfrageanweisungen ausführen, Diagrammdatenbank abfragen und Inhalte abrufen
(5)self.qa_chain: Basierend auf dem Inhalt der ursprünglichen Frage und Anfrage wird erneut das große Modell verwendet, um die Antworten zu organisieren und in natürlicher Sprache an den Benutzer auszugeben.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Als begeisterter Internet-Veteran habe ich beschlossen, mein wertvolles KI-Wissen mit allen zu teilen. Wie viel Sie lernen können, hängt von Ihrer Lernausdauer und Ihren Fähigkeiten ab. Ich habe wichtige Materialien für KI-Großmodelle geteilt, darunter Mindmaps zum Einführungslernen von KI-Großmodellen, hochwertige Bücher und Handbücher zum Lernen von KI-Großmodellen, Video-Tutorials, praktisches Lernen und andere aufgezeichnete Videos kostenlos.
Diese vollständige Version der KI-Lernmaterialien für große Modelle wurde auf CSDN hochgeladen. Wenn Sie sie benötigen, können Freunde den offiziellen CSDN-Zertifizierungs-QR-Code unten auf WeChat scannen, um ihn kostenlos zu erhalten.保证100%免费】

Die Lernreise im Zeitalter großer KI-Modelle: Von den Grundlagen bis zum neuesten Stand – beherrschen Sie die Kernkompetenzen der künstlichen Intelligenz!

Diese Sammlung von 640 Berichten deckt viele Aspekte wie theoretische Forschung, technische Umsetzung und industrielle Anwendung großer KI-Modelle ab. Ganz gleich, ob Sie ein wissenschaftlicher Forscher, ein Ingenieur oder ein Enthusiast sind, der sich für große KI-Modelle interessiert, diese Sammlung von Berichten wird Ihnen wertvolle Informationen und Inspiration liefern.

Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz sind große KI-Modelle zu einem heißen Thema im heutigen wissenschaftlichen und technologischen Bereich geworden. Diese groß angelegten vorab trainierten Modelle wie GPT-3, BERT, XLNet usw. verändern unser Verständnis von künstlicher Intelligenz mit ihren leistungsstarken Sprachverständnis- und Generierungsfunktionen. Die folgenden PDF-Bücher sind sehr gute Lernressourcen.


Als normaler Mensch erfordert der Eintritt in die Ära der großen Modelle kontinuierliches Lernen und Üben, um seine Fähigkeiten und sein kognitives Niveau kontinuierlich zu verbessern. Gleichzeitig muss er über Verantwortungsbewusstsein und ethisches Bewusstsein verfügen, um zur gesunden Entwicklung der künstlichen Intelligenz beizutragen .

Er widmet sich seit mehr als dreißig Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. und hat viele Beiträge im Open-Source-Bereich geleistet, eine Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

