
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'uso di database a grafo o di grafi della conoscenza in applicazioni di modelli di grandi dimensioni è diventato sempre più popolare di recente. I grafici presentano vantaggi naturali nel rappresentare e archiviare informazioni diverse e correlate e possono facilmente catturare relazioni e attributi complessi tra diversi tipi di dati, fornendo così un contesto migliore o un supporto dati per modelli di grandi dimensioni. In questo articolo, diamo un'occhiata a come utilizzare i database a grafo o i grafici della conoscenza in applicazioni di modelli di grandi dimensioni.
Questo articolo è solo una semplice introduzione ed esperienza.Non importa se non conosci il database grafico o neo4j, segui semplicemente i passaggi in questo articolo . Questo articolo può aiutarti a comprendere il metodo di applicazione del Knowledge Graph in RAG. Una volta acquisita l'esperienza, potrai imparare a utilizzare il database a grafo in un secondo momento, se necessario.
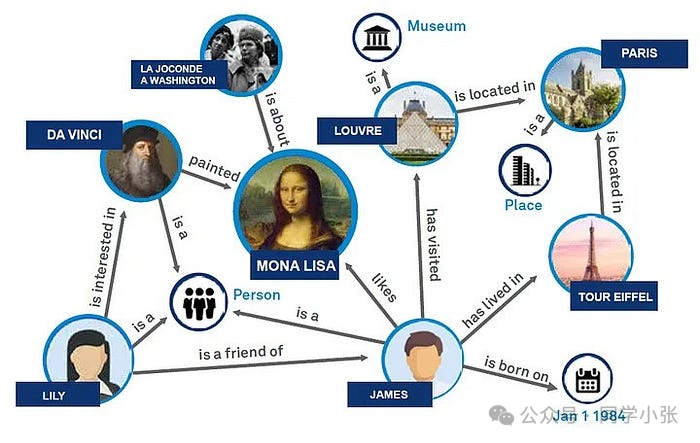
Il grafico della conoscenza è una base di conoscenza semantica strutturata che memorizza e rappresenta entità (come persone, luoghi, organizzazioni, ecc.) e relazioni tra entità (come relazioni tra persone, relazioni di posizione geografica, ecc.) sotto forma di grafici. I grafici della conoscenza vengono spesso utilizzati per migliorare la comprensione semantica dei motori di ricerca, fornendo informazioni più ricche e risultati di ricerca più accurati.
Le caratteristiche principali del grafico della conoscenza includono:
1. Entità : L'unità di base nel grafico della conoscenza, che rappresenta un oggetto o un concetto nel mondo reale.
2. Relazione: La relazione tra entità, come "appartiene a", "si trova in", "creatore", ecc.
3. Attributo: informazioni descrittive possedute dall'entità, come l'età della persona, la longitudine e la latitudine del luogo, ecc.
4. Struttura del grafico: Il grafico della conoscenza organizza i dati sotto forma di grafico, inclusi nodi (entità) e bordi (relazioni).
5. *Rete semantica: Un grafo della conoscenza può essere visto come una rete semantica in cui nodi e spigoli hanno significati semantici.
6. Inferenza: I grafici della conoscenza possono essere utilizzati per il ragionamento, ovvero per ricavare nuove informazioni attraverso entità e relazioni conosciute.
I grafici della conoscenza sono ampiamente utilizzati nell'ottimizzazione dei motori di ricerca (SEO), nei sistemi di raccomandazione, nell'elaborazione del linguaggio naturale (NLP), nel data mining e in altri campi. Ad esempio, il Knowledge Graph di Google, Wikidata, DBpedia, ecc. sono tutti esempi ben noti di grafici della conoscenza.
Come forma di organizzazione dei dati, l'importanza del grafico della conoscenza è quella di fornire un modo efficiente e intuitivo per rappresentare e gestire relazioni complesse di dati. Visualizza i dati in una forma strutturata attraverso i nodi e i bordi della struttura del grafico, migliora la capacità di espressione semantica dei dati e rende chiara e chiara la relazione tra le entità. I grafici della conoscenza migliorano significativamente l’accuratezza del recupero delle informazioni, soprattutto nel campo dell’elaborazione del linguaggio naturale, consentendo alle macchine di comprendere e rispondere meglio alle complesse query degli utenti. I grafici della conoscenza svolgono un ruolo fondamentale nelle applicazioni intelligenti, come i sistemi di raccomandazione, la risposta intelligente alle domande, ecc.
Dopo la noiosa introduzione, diamo un'occhiata al caso del knowledge graph RAG+ e implementiamolo noi stessi.
Il caso seguente proviene dalla documentazione ufficiale di LangChain: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Per prima cosa devi installare un database grafico, qui usiamo neo4j.
comando di installazione Python:
pip install neo4j
(2) Registra un account ufficiale, accedi e crea un'istanza del database. (Se vuoi usarlo per imparare, scegli quello gratuito.)
Dopo aver creato un'istanza del database online, la pagina è la seguente:
Ora puoi utilizzare questo database nel tuo codice.
(1) Dopo aver creato l'istanza del database, dovresti ottenere il collegamento, il nome utente e la password dei dati. La vecchia regola è inserirli nella variabile di ambiente, quindi caricare la variabile di ambiente tramite Python:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Collega la banca dati
LangChain incapsula l'interfaccia neo4j e dobbiamo solo importare la classe Neo4jGraph per usarla.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Interrogare e compilare i dati
È possibile utilizzare l'interfaccia di query per eseguire query e restituire risultati. Il linguaggio dell'istruzione della query è il linguaggio di query Cypher.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
L'output del codice sopra è []。
(4) Aggiorna le informazioni sull'architettura del grafico
graph.refresh_schema()
print(graph.schema)

Dai risultati, lo schema contiene informazioni come tipi di nodo, attributi e relazioni tra tipi ed è l'architettura del grafico.
Possiamo anche accedere alla pagina web neo4j per visualizzare i dati memorizzati nel database dei grafici:
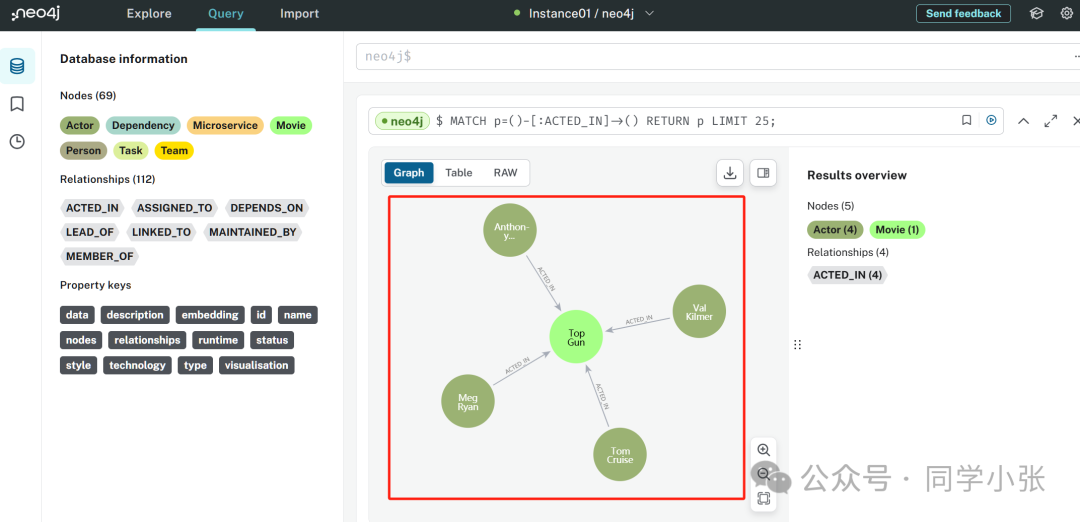
(5) Ora che ci sono dati nel database del grafico, possiamo interrogarli.
La classe GraphCypherQACain è incapsulata in LangChain, che può essere facilmente interrogata utilizzando il database a grafo. Il seguente codice:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Processo di esecuzione e risultati:

Innanzitutto, il linguaggio naturale (Chi ha giocato a Top Gun?) viene convertito in un'istruzione di query grafica attraverso un modello di grandi dimensioni, quindi l'istruzione di query viene eseguita tramite neo4j, vengono restituiti i risultati e infine viene convertita in linguaggio naturale attraverso il grande modello modello e output per l'utente.
Nel codice precedente, utilizziamo la classe GraphCypherQACain di LangChain, che è la query del database grafico e la catena di domande e risposte fornita da LangChain.Ha molti parametri che possono essere impostati, come l'utilizzoexclude_types Per impostare quali tipi di nodo o relazioni vengono ignorati:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
L'output è simile al seguente:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Sono disponibili molti parametri simili, puoi fare riferimento alla documentazione ufficiale: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- generazione di risposte
Quello che segue è il codice sorgente di esecuzione di GraphCypherQAChain. Diamo una breve occhiata al suo processo di esecuzione.
(1)cypher_generation_chain: Conversione del linguaggio naturale in istruzioni di query su grafici.
(2)extract_cypher: elimina l'istruzione della query perché i modelli di grandi dimensioni potrebbero restituire alcune informazioni aggiuntive sulla descrizione e devono essere rimossi.
(3)cypher_query_corrector: correggere l'istruzione della query.
(4)graph.query: eseguire istruzioni di query, interrogare il database del grafico e ottenere contenuto
(5)self.qa_chain: in base al contenuto della domanda e della query originali, il modello di grandi dimensioni viene nuovamente utilizzato per organizzare le risposte e l'output per l'utente in linguaggio naturale.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Essendo un entusiasta veterano di Internet, ho deciso di condividere con tutti le mie preziose conoscenze sull'intelligenza artificiale. Quanto puoi imparare, dipende dalla tua perseveranza e capacità nello studio. Ho condiviso importanti materiali per modelli di grandi dimensioni dell'intelligenza artificiale, tra cui mappe mentali per l'apprendimento introduttivo di modelli di grandi dimensioni dell'intelligenza artificiale, libri e manuali di apprendimento di modelli di grandi dimensioni dell'intelligenza artificiale di alta qualità, tutorial video, apprendimento pratico e altri video registrati gratuitamente.
Questa versione completa dei materiali didattici sull'intelligenza artificiale di grandi dimensioni è stata caricata su CSDN. Se ne hai bisogno, gli amici possono scansionare il codice QR della certificazione ufficiale CSDN di seguito su WeChat per ottenerlo gratuitamente [.保证100%免费】

Il viaggio di apprendimento nell'era dei grandi modelli di intelligenza artificiale: dalle basi all'avanguardia, padroneggia le competenze fondamentali dell'intelligenza artificiale!

Questa raccolta di 640 rapporti copre molti aspetti come la ricerca teorica, l'implementazione tecnica e l'applicazione industriale di grandi modelli di intelligenza artificiale. Che tu sia un ricercatore scientifico, un ingegnere o un appassionato interessato ai grandi modelli di intelligenza artificiale, questa raccolta di rapporti ti fornirà preziose informazioni e ispirazione.

Con il rapido sviluppo della tecnologia dell'intelligenza artificiale, i grandi modelli di intelligenza artificiale sono diventati un tema caldo nel campo scientifico e tecnologico di oggi. Questi modelli pre-addestrati su larga scala, come GPT-3, BERT, XLNet, ecc., stanno cambiando la nostra comprensione dell’intelligenza artificiale con le loro potenti capacità di comprensione e generazione del linguaggio. I seguenti libri PDF sono ottime risorse di apprendimento.


Come persona comune, entrare nell'era dei grandi modelli richiede apprendimento e pratica continui per migliorare continuamente le proprie capacità e il proprio livello cognitivo. Allo stesso tempo, è necessario avere senso di responsabilità e consapevolezza etica per contribuire al sano sviluppo dell'intelligenza artificiale .

Si dedica alla ricerca tecnologica da più di trent'anni, è esperto in vari linguaggi come java, linux, javascript, php, css, ecc., e ha apportato numerosi contributi nel campo dell'open source una stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro. Tutti la controllano

Posta[email protected]