
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
大規模モデル アプリケーションでのグラフ データベースまたはナレッジ グラフの使用は、最近ますます一般的になってきています。グラフには、相互に関連する多様な情報を表現および保存するという自然な利点があり、異なるデータ型間の複雑な関係や属性を簡単に把握できるため、大規模なモデルに対するコンテキストやデータのサポートが向上します。この記事では、大規模モデル アプリケーションでグラフ データベースまたはナレッジ グラフを使用する方法を見てみましょう。
この記事は簡単な紹介と体験談です。グラフ データベースや neo4j について知らなくても問題ありません。この記事の手順に従ってください。 。この記事は、RAG でのナレッジ グラフの適用方法を理解するのに役立ちます。一度経験を積めば、必要に応じて後でグラフ データベースの使用方法を学ぶことができます。
ナレッジ グラフは、エンティティ (人、場所、組織など) とエンティティ間の関係 (人との関係、地理的位置の関係など) をグラフの形式で保存および表現する、構造化された意味論的な知識ベースです。ナレッジ グラフは、検索エンジンの意味論的な理解を強化し、より豊富な情報とより正確な検索結果を提供するためによく使用されます。
ナレッジ グラフの主な機能は次のとおりです。
1. エンティティ : ナレッジ グラフの基本単位。現実世界のオブジェクトまたは概念を表します。
2. 関係性: 「に属する」、「に位置する」、「作成者」などのエンティティ間の関係。
3. 属性: 人物の年齢、場所の経度、緯度など、その実体が持つ記述情報。
4. グラフの構造: ナレッジ グラフは、ノード (エンティティ) とエッジ (関係) を含むデータをグラフの形式で編成します。
5. *セマンティックネットワーク: ナレッジ グラフは、ノードとエッジが意味論的な意味を持つセマンティック ネットワークとして見ることができます。
6. 推論: ナレッジ グラフは推論、つまり既知のエンティティや関係から新しい情報を導き出すために使用できます。
ナレッジ グラフは、検索エンジン最適化 (SEO)、推奨システム、自然言語処理 (NLP)、データ マイニングなどの分野で広く使用されています。たとえば、Google の Knowledge Graph、Wikidata、DBpedia などはすべてナレッジ グラフのよく知られた例です。
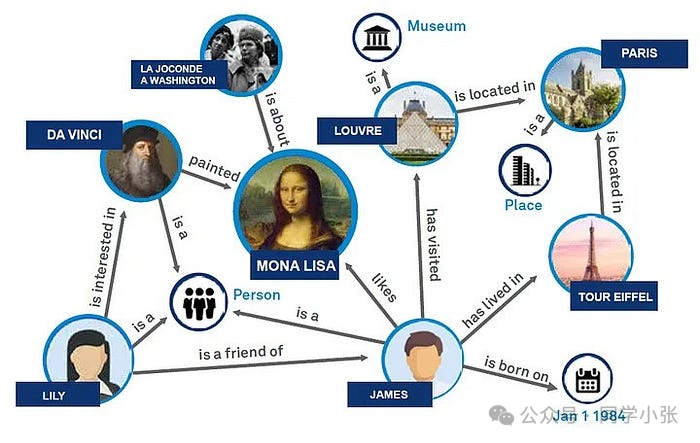
データ編成の一形式としてのナレッジ グラフの重要性は、複雑なデータ関係を表現および管理する効率的かつ直感的な方法を提供することです。グラフ構造のノードとエッジを通じてデータを構造化された形式で表示し、データの意味表現能力を強化し、エンティティ間の関係を明確にします。ナレッジ グラフは、特に自然言語処理の分野での情報検索の精度を大幅に向上させ、マシンが複雑なユーザー クエリをよりよく理解して応答できるようにします。ナレッジ グラフは、推奨システム、インテリジェントな質問応答などのインテリジェント アプリケーションにおいて中心的な役割を果たします。
退屈な前置きが終わったら、RAG+ ナレッジ グラフの事例を見て、自分で実装してみましょう。
次のケースは、LangChain の公式ドキュメントからのものです: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) まずグラフデータベースをインストールする必要があります。ここでは neo4j を使用します。
Pythonのインストールコマンド:
pip install neo4j
(2) 公式アカウントを登録してログインし、データベースインスタンスを作成します。 (学習に使用したい場合は、無料のものを選択してください。)
オンライン データベース インスタンスを作成すると、ページは次のようになります。
これで、このデータベースをコード内で使用できるようになります。
(1) データベース インスタンスを作成した後、データのリンク、ユーザー名、パスワードを取得し、それを環境変数に入れてから、Python を介して環境変数をロードする必要があります。
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) リンクデータベース
LangChain は neo4j インターフェイスをカプセル化しており、それを使用するには Neo4jGraph クラスをインポートするだけで済みます。
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) データのクエリと入力
クエリ インターフェイスを使用してクエリを実行し、結果を返すことができます。クエリ ステートメントの言語は Cypher クエリ言語です。
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
上記のコードの出力は次のとおりです []。
(4) グラフのアーキテクチャ情報を更新する
graph.refresh_schema()
print(graph.schema)

結果から、スキーマにはノード タイプ、属性、タイプ間の関係などの情報が含まれており、グラフのアーキテクチャです。
neo4j Web ページにログインして、グラフ データベースに保存されているデータを表示することもできます。
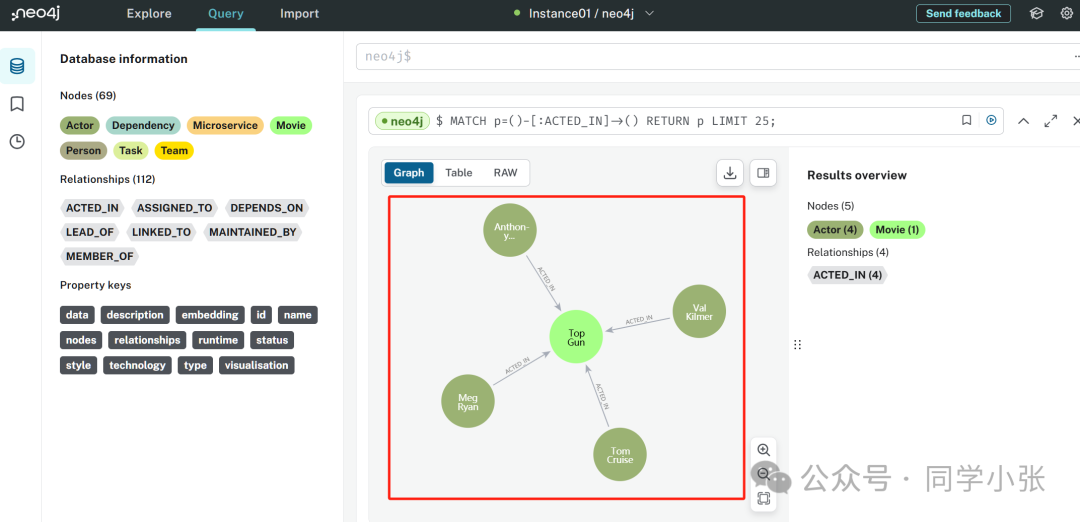
(5) グラフ データベース内のデータを使用して、次にクエリを実行できます。
GraphCypherQAChain クラスは LangChain にカプセル化されており、グラフ データベースを使用して簡単にクエリできます。次のコード:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
実行プロセスと結果:

まず、自然言語 (トップ ガンで誰がプレーしましたか?) が大規模なモデルを通じてグラフ クエリ ステートメントに変換され、次にそのクエリ ステートメントが neo4j を通じて実行され、結果が返され、最後に大規模なモデルを通じて自然言語に変換されます。モデルを作成してユーザーに出力します。
上記のコードでは、LangChain の GraphCypherQAChain クラスを使用します。これは、LangChain が提供するグラフ データベース クエリと質問と回答のチェーンです。設定できるパラメーターが多数あります。 exclude_types どのノード タイプまたは関係を無視するかを設定するには、次の手順を実行します。
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
出力は次のようになります。
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
利用可能な同様のパラメーターが多数あります。公式ドキュメントを参照してください: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use- Separate-llms-for-cypher-and-答えの生成
以下は GraphCypherQAChain の実行ソースコードです。その実行プロセスを簡単に見てみましょう。
(1)cypher_generation_chain: 自然言語からグラフ クエリ ステートメントへの変換。
(2)extract_cypher: クエリ ステートメントを削除します。これは、大規模なモデルが追加の説明情報を返す可能性があるため、削除する必要があるためです。
(3)cypher_query_corrector処置: クエリ文を修正してください。
(4)graph.query: クエリ ステートメントを実行し、グラフ データベースをクエリし、コンテンツを取得します。
(5)self.qa_chain: 元の質問とクエリの内容に基づいて、大規模なモデルを再度使用して回答を整理し、自然言語でユーザーに出力します。
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
熱心なインターネットのベテランとして、私は貴重な AI の知識を皆さんと共有することにしました。 どれだけ学べるかについては、あなたの学習忍耐力と能力によって異なります。 AI 大型モデル入門学習マインド マップ、高品質の AI 大型モデル学習書籍とマニュアル、ビデオ チュートリアル、実践学習、その他の録画ビデオを含む重要な AI 大型モデル資料を無料で共有しました。
この大規模モデル AI 学習教材の完全版は CSDN にアップロードされています。必要な場合は、友人が WeChat で以下の CSDN 公式認定 QR コードをスキャンして無料で入手できます。保证100%免费】

大規模 AI モデル時代の学習の旅: 基礎から最先端まで、人工知能のコアスキルをマスターしましょう!

640 件のレポートからなるこのコレクションは、大規模な AI モデルの理論的研究、技術的実装、業界での応用など、多くの側面をカバーしています。あなたが科学研究者、エンジニア、または大規模な AI モデルに興味のある愛好家であっても、このレポート集は貴重な情報とインスピレーションを提供します。

人工知能技術の急速な発展に伴い、AI大型モデルは今日の科学技術分野で注目を集めています。 GPT-3、BERT、XLNet などの大規模な事前トレーニング済みモデルは、その強力な言語理解および生成機能により、人工知能に対する私たちの理解を変えています。 次の PDF ブックは、非常に優れた学習リソースです。


一般人として、大規模モデルの時代に入ると、自分のスキルと認知レベルを継続的に向上させるために継続的な学習と練習が必要になると同時に、人工知能の健全な発展に貢献するための責任感と倫理意識を持つ必要があります。 。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: