
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Использование графовых баз данных или графов знаний в приложениях для больших моделей в последнее время становится все более популярным. Графики имеют естественные преимущества в представлении и хранении разнообразной и взаимосвязанной информации и могут легко фиксировать сложные отношения и атрибуты между различными типами данных, тем самым лучше обеспечивая поддержку контекста или данных для больших моделей. В этой статье давайте посмотрим, как использовать графовые базы данных или графы знаний в приложениях с большими моделями.
Эта статья представляет собой простое введение и опыт.Неважно, не знаете ли вы графовую базу данных или neo4j, просто следуйте инструкциям в этой статье. . Эта статья может помочь вам понять метод применения графа знаний в RAG. Когда у вас появится опыт, вы сможете научиться использовать базу данных графов позже, если понадобится.
Граф знаний — это структурированная семантическая база знаний, в которой хранятся и представляются сущности (например, люди, места, организации и т. д.) и отношения между сущностями (например, отношения между людьми, отношения географического местоположения и т. д.) в форме графов. Графы знаний часто используются для улучшения семантического понимания поисковыми системами, обеспечивая более полную информацию и более точные результаты поиска.
К основным особенностям графа знаний относятся:
1. Сущность : базовая единица графа знаний, представляющая объект или концепцию в реальном мире.
2. Отношения: отношения между сущностями, такие как «принадлежит», «находится в», «создатель» и т. д.
3. Атрибут: описательная информация, которой обладает сущность, например возраст человека, долгота и широта местоположения и т. д.
4. Структура графа: Граф знаний организует данные в виде графа, включая узлы (сущности) и ребра (связи).
5. *Семантическая сеть: Граф знаний можно рассматривать как семантическую сеть, в которой узлы и ребра имеют семантические значения.
6. Вывод: Графы знаний можно использовать для рассуждений, то есть получения новой информации через известные сущности и отношения.
Графы знаний широко используются в поисковой оптимизации (SEO), рекомендательных системах, обработке естественного языка (NLP), интеллектуальном анализе данных и других областях. Например, хорошо известными примерами графов знаний являются Google's Knowledge Graph, Wikidata, DBpedia и т. д.
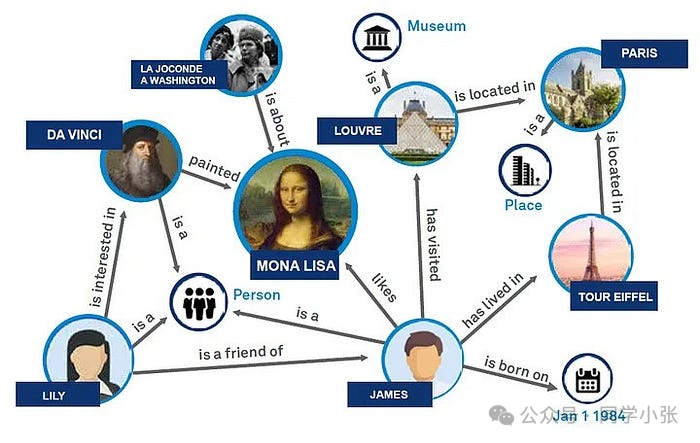
Как форма организации данных, значение графа знаний состоит в том, чтобы обеспечить эффективный и интуитивно понятный способ представления сложных взаимосвязей данных и управления ими. Он отображает данные в структурированной форме через узлы и ребра структуры графа, расширяет возможности семантического выражения данных и делает отношения между сущностями ясными и понятными. Графы знаний значительно повышают точность поиска информации, особенно в области обработки естественного языка, позволяя машинам лучше понимать сложные запросы пользователей и отвечать на них. Графы знаний играют ключевую роль в интеллектуальных приложениях, таких как системы рекомендаций, интеллектуальные ответы на вопросы и т. д.
После скучного вступления давайте рассмотрим случай графа знаний RAG+ и реализуем его самостоятельно.
Следующий случай взят из официальной документации LangChain: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information.
(1) Сначала вам нужно установить графовую базу данных, здесь мы используем neo4j.
команда установки Python:
pip install neo4j
(2) Зарегистрируйте официальную учетную запись, войдите в систему и создайте экземпляр базы данных. (Если вы хотите использовать его для обучения, просто выберите бесплатный.)
После создания онлайн-экземпляра базы данных страница выглядит следующим образом:
Теперь вы можете использовать эту базу данных в своем коде.
(1) После создания экземпляра базы данных вы должны получить ссылку, имя пользователя и пароль данных. Старое правило — поместить их в переменную среды, а затем загрузить переменную среды через Python:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) База данных ссылок
LangChain инкапсулирует интерфейс neo4j, и нам нужно только импортировать класс Neo4jGraph, чтобы использовать его.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Запрос и заполнение данных
Вы можете использовать интерфейс запросов для запроса и возврата результатов. Языком оператора запроса является язык запросов Cypher.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
Вывод приведенного выше кода: []。
(4) Обновите архитектурную информацию графа.
graph.refresh_schema()
print(graph.schema)

По результатам получается, что схема содержит такую информацию, как типы узлов, атрибуты и отношения между типами, и представляет собой архитектуру графа.
Мы также можем войти на веб-страницу neo4j, чтобы просмотреть данные, хранящиеся в базе данных графов:
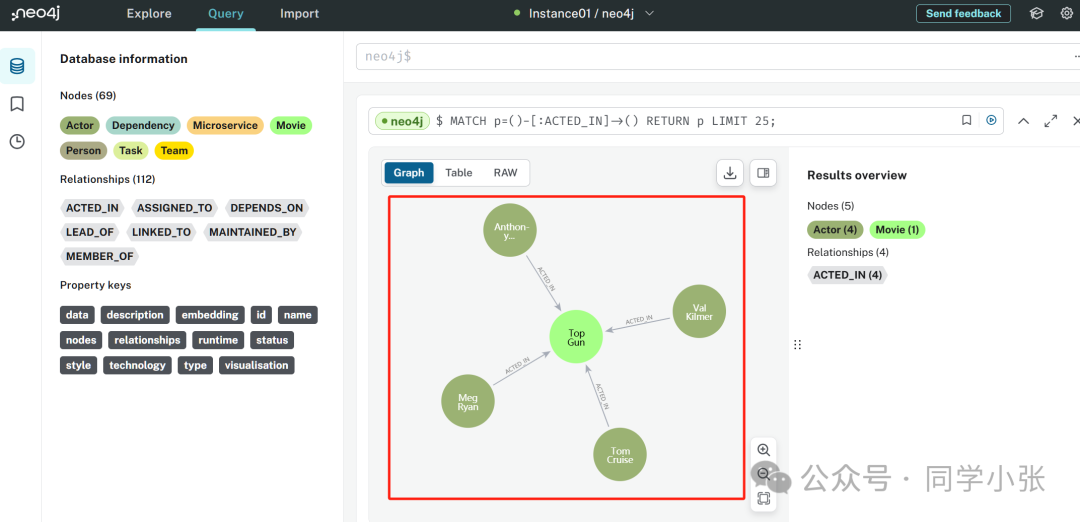
(5) Имея данные в базе данных графов, мы можем затем запросить их.
Класс GraphCypherQAChain инкапсулирован в LangChain, к которому можно легко обращаться с помощью базы данных графов. Следующий код:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Процесс выполнения и результаты:

Сначала естественный язык (Кто играл в Top Gun?) преобразуется в оператор запроса графа с помощью большой модели, затем оператор запроса выполняется с помощью neo4j, возвращаются результаты и, наконец, он преобразуется в естественный язык с помощью большого модель и вывод пользователю.
В приведенном выше коде мы используем класс GraphCypherQAChain от LangChain, который представляет собой запрос к графовой базе данных и цепочку вопросов и ответов, предоставляемую LangChain.Он имеет множество параметров, которые можно установить, например, с помощьюexclude_types Чтобы установить, какие типы узлов или связи игнорируются:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
Вывод аналогичен следующему:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Доступно множество подобных параметров, вы можете обратиться к официальной документации: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- генерация ответов
Ниже приведен исходный код выполнения GraphCypherQAChain. Давайте кратко рассмотрим процесс его выполнения.
(1)cypher_generation_chain: Преобразование естественного языка в операторы запроса в виде графика.
(2)extract_cypher: Удалить оператор запроса. Это связано с тем, что большие модели могут возвращать некоторую дополнительную информацию описания, и их необходимо удалить.
(3)cypher_query_corrector: Исправьте оператор запроса.
(4)graph.query: Выполнение операторов запроса, запрос к базе данных графов и получение контента.
(5)self.qa_chain: на основе содержания исходного вопроса и запроса большая модель снова используется для организации ответов и вывода их пользователю на естественном языке.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Будучи увлеченным ветераном Интернета, я решил поделиться со всеми своими ценными знаниями в области искусственного интеллекта. Что касается того, сколько вы сможете выучить, это зависит от вашей настойчивости и способностей к обучению. Я бесплатно поделился важными материалами по крупным моделям ИИ, в том числе интеллектуальными картами для вводного обучения крупным моделям ИИ, высококачественными книгами и руководствами по обучению крупным моделям ИИ, видеоуроками, практическими занятиями и другими записанными видеороликами.
Эта полная версия учебных материалов по крупномасштабным моделям искусственного интеллекта была загружена на CSDN. Если вам это нужно, друзья могут отсканировать QR-код официальной сертификации CSDN ниже в WeChat, чтобы получить его бесплатно.保证100%免费】

Учебный путь в эпоху больших моделей искусственного интеллекта: от основ к передовым, овладейте основными навыками искусственного интеллекта!

Этот сборник из 640 отчетов охватывает многие аспекты, такие как теоретические исследования, техническая реализация и промышленное применение крупных моделей искусственного интеллекта. Независимо от того, являетесь ли вы научным исследователем, инженером или энтузиастом, интересующимся большими моделями искусственного интеллекта, этот сборник отчетов предоставит вам ценную информацию и вдохновение.

Благодаря быстрому развитию технологий искусственного интеллекта большие модели ИИ стали горячей темой в современной научной и технологической сфере. Эти крупномасштабные предварительно обученные модели, такие как GPT-3, BERT, XLNet и т. д., меняют наше понимание искусственного интеллекта благодаря своим мощным возможностям понимания языка и генерации. Следующие книги в формате PDF являются очень хорошими учебными ресурсами.


Как обычный человек, вступление в эпоху больших моделей требует постоянного обучения и практики для постоянного улучшения своих навыков и когнитивного уровня. В то же время необходимо иметь чувство ответственности и этическую осведомленность, чтобы способствовать здоровому развитию искусственного интеллекта. .

Он посвятил себя исследованию технологий более тридцати лет, владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д., и внес большой вклад в созданную им область открытого исходного кода. станция документации для разработчиков, где можно поделиться некоторыми проблемами разработки технологий для дальнейшего использования.

Почтамезофия@protonmail.com